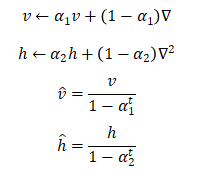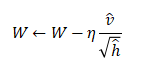目录
摘要
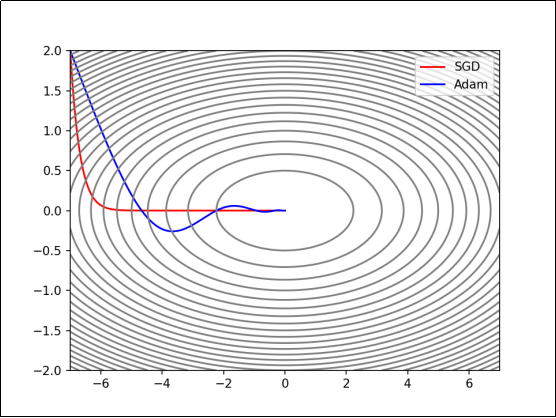
本篇文章继续学习尚硅谷深度学习教程,学习内容是AdaGrad,RMSProp**,**Adam
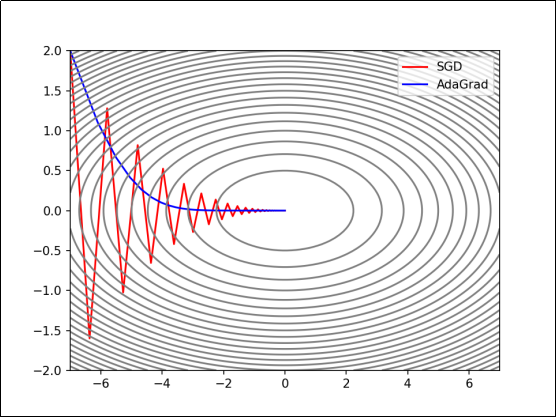
1.AdaGrad
AdaGrad(Adaptive Gradient,自适应梯度)会为每个参数适当地调整学习率,并且随着学习的进行,学习率会逐渐减小。
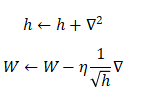
- h:历史梯度的平方和
这里就表示了梯度的平方和,即
,这里的
表示对应矩阵元素的乘法。
使用AdaGrad时,学习越深入,更新的幅度就越小。如果无止境地学习,更新量就会变为0,完全不再更新。
AdaGrad的代码实现如下:
python
class AdaGrad:
def __init__(self, lr=0.01):
self.lr = lr
self.h = None
def update(self, params, grads):
if self.h is None:
self.h = {}
for key, val in params.items():
self.h[key] = np.zeros_like(val)
for key in params.keys():
self.h[key] += grads[key] * grads[key]
params[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7)2.RMSProp
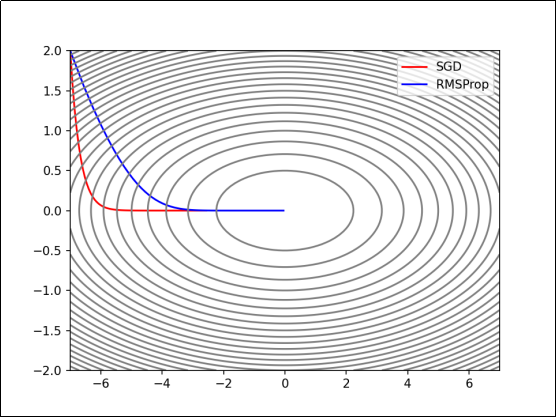
RMSProp(Root Mean Square Propagation,均方根传播)是在AdaGrad基础上的改进,它并非将过去所有梯度一视同仁的相加,而是逐渐遗忘过去的梯度,采用指数移动加权平均,呈指数地减小过去梯度的尺度。
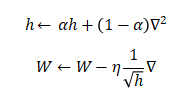
- h:历史梯度平方和的指数移动加权平均
:权重
3.Adam
Adam(Adaptive Moment Estimation,自适应矩估计)融合了Momentum和AdaGrad的方法。