HashMap面试题总结
这里系统总结一下Java面试过程中HashMap部分常见的面试题。
基本原理
1.数据结构
1.1HashMap数据结构是什么?
-
JDK1.7的数据结构是数组+链表
-
JDK1.8的数据结构是数组+链表+红黑树。
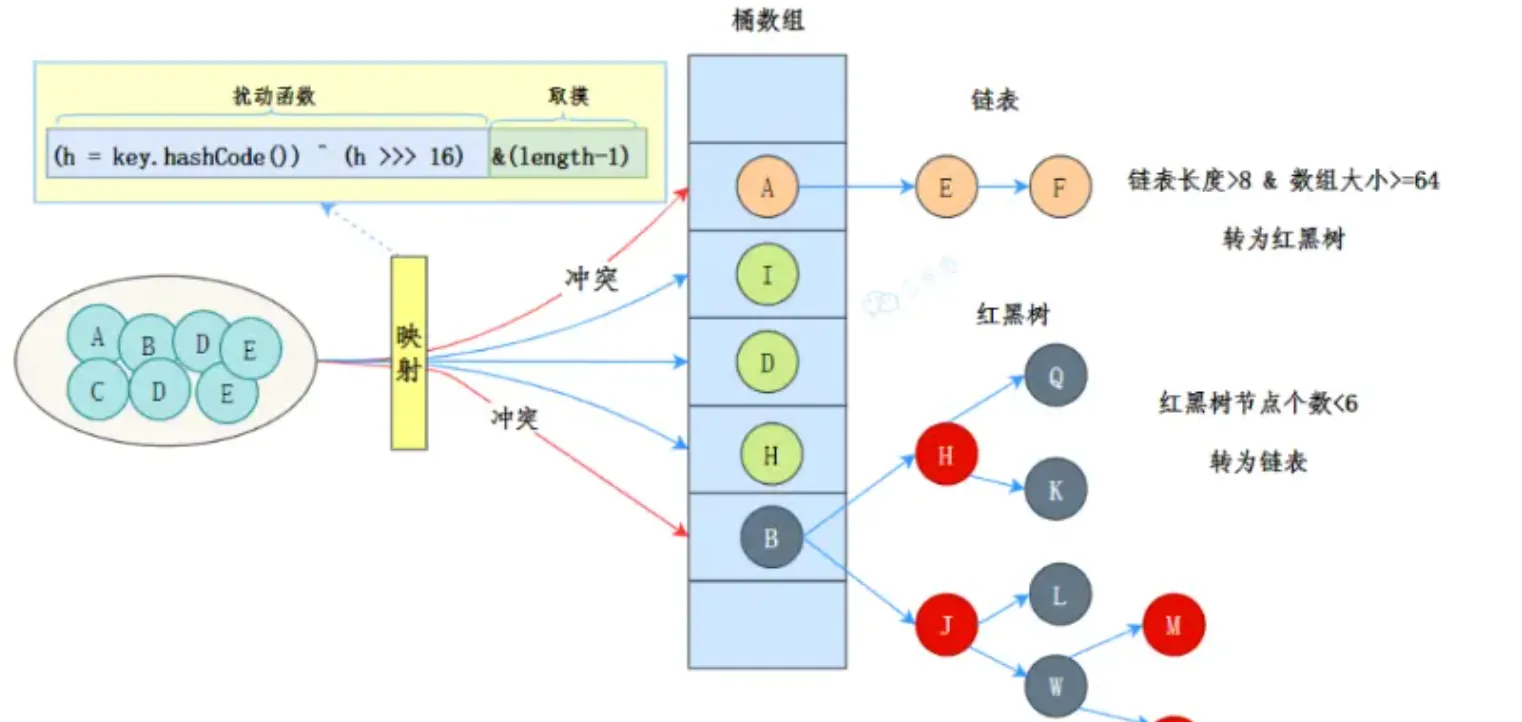
1.2 为什么要使用红黑树?什么时候会转化为红黑树
链表过长导致性能问题
- 在 JDK 1.8 之前,HashMap 使用数组 + 链表的结构。当多个键的哈希值映射到同一个桶时,这些键值对会以链表的形式存储。
- 如果链表过长,查找、插入和删除操作的时间复杂度会从
O(1)退化为O(n),严重影响性能。 - 特别是在哈希冲突严重的情况下,链表的性能问题会非常明显。
红黑树的优势
- 红黑树是一种自平衡的二叉搜索树,它的查找、插入和删除操作的时间复杂度为
O(log n)。 - 当链表长度超过一定阈值(默认是 8)时,HashMap 会将链表转换为红黑树,从而将操作的时间复杂度从
O(n)优化为O(log n)。 - 这种优化在哈希冲突严重的情况下,可以显著提升性能。
- 链表转红黑树的阈值 :默认是 8。
- 当链表的长度超过 8 时,HashMap 会将链表转换为红黑树。
- 红黑树退化为链表的阈值 :默认是 6。
- 当红黑树的节点数减少到 6 时,HashMap 会将红黑树退化为链表。
- 这种设计是为了在性能和空间开销之间找到平衡:
- 链表占用空间较小,但性能较差。
- 红黑树性能较好,但占用空间较大。
2.容量&Hash冲突问题
2.1 什么是负载因子(LoadFactory)
负载因子表示 HashMap 中元素数量与当前容量的比值。它的计算公式为:
负载因子=元素数量当前容量负载因子/当前容量元素数量
- 元素数量:HashMap 中当前存储的键值对数量。
- 当前容量:HashMap 中数组(桶数组)的长度。
负载因子的影响
负载因子的值直接影响 HashMap 的性能和行为:
负载因子过小(例如 0.5)
- 优点:哈希冲突的概率较低,查找、插入和删除操作的性能较好。
- 缺点:会频繁触发扩容,导致空间利用率低,内存开销较大。
负载因子过大(例如 1.0)
- 优点:减少了扩容次数,空间利用率较高。
- 缺点:哈希冲突的概率增加,链表或红黑树的长度可能变长,导致查找、插入和删除操作的性能下降
2.2 什么时候会扩容
HashMap 的扩容条件是:
当前存储的键值对数量(size)超过了负载因子(load factor)与当前容量(capacity)的乘积。
扩容条件:size>load factor×capacity
- size:HashMap 中当前存储的键值对数量。
- load factor:负载因子,默认值是 0.75。
- capacity:HashMap 中数组(桶数组)的长度。
例如:
如果当前容量是 16,负载因子是 0.75,那么当键值对数量超过 16×0.75=1216×0.75=12 时,HashMap 会触发扩容。
2.3 扩容步骤
当满足扩容条件时,HashMap 会执行以下操作:
- 创建一个新的数组 :
- 新数组的容量是原数组的两倍(即 2×capacity2×capacity)。
- 例如,原数组容量是 16,新数组容量是 32。
- 重新哈希(rehash) :
- 遍历原数组中的所有键值对,重新计算每个键的哈希值,并根据新数组的长度确定其在新数组中的位置。
- 这个过程称为重新哈希(rehashing)。
- 迁移数据 :
- 将原数组中的键值对迁移到新数组中。
3.数值问题
3.1 size为什么是2的n次方
高效计算索引
HashMap 需要通过哈希值来确定键值对存储的数组索引。计算公式为:
index=hash&(length−1)
其中:
hash是键的哈希值。length是数组的长度。&是按位与操作。
为什么使用 length - 1?
- 当
length是 2 的 n 次方时,length - 1的二进制表示是一串连续的 1。- 例如,
length = 16,则length - 1 = 15,二进制为1111。
- 例如,
- 通过
hash & (length - 1),可以快速将哈希值映射到[0, length - 1]的范围内。 - 这种方式比取模运算(
hash % length)更高效,因为位运算的速度远快于取模运算。
均匀分布索引
- 当
length是 2 的 n 次方时,hash & (length - 1)的结果能够均匀分布在[0, length - 1]的范围内。 - 这样可以减少哈希冲突,提高 HashMap 的性能。
反例:如果 length 不是 2 的 n 次方
- 例如,
length = 15,则length - 1 = 14,二进制为1110。 - 在这种情况下,
hash & (length - 1)的结果会丢失最低位的 1,导致某些索引永远不会被使用(例如索引 1、3、5 等)。 - 这会增加哈希冲突的概率,降低 HashMap 的性能。
扩容时的优化
- HashMap 在扩容时,新数组的长度是原数组的两倍(即仍然是 2 的 n 次方)。
- 扩容后,键值对的索引要么保持不变,要么增加原数组的长度。
- 例如,原数组长度是 16,扩容后长度是 32。
- 如果原索引是 5,扩容后索引可能是 5 或 21(即
5 + 16)。
例子:
0101 &(0111)=0101(5)
变成32之后
0101&(1111)=0101(5)
- 这种特性使得扩容时只需要重新计算部分键值对的索引,而不需要重新计算所有键值对的索引,从而提高了扩容的效率。
哈希函数的优化
- HashMap 的哈希函数会对键的
hashCode()进行二次哈希,以减少哈希冲突。 - 当数组长度是 2 的 n 次方时,二次哈希的结果能够更好地分散在数组中,进一步减少哈希冲突。
3.2 LoadFactor为什么是0.75
这个回答比较简单,直接可以说这是一个经验值。
3.3 树化的条件为什么是8
这也是一个经验值
3.4 Hash值是如何计算的
- HashMap 使用以下公式对初始哈希值进行二次哈希计算:
Java
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}h >>> 16:将哈希值右移 16 位,相当于将高 16 位移动到低 16 位。h ^ (h >>> 16):将原始哈希值的高 16 位与低 16 位进行异或运算。
举个例子:
假如 hashCode : 10001101_11010001_10001001_10101001
hashCode>>> 16= 00000000_00000000_10001101_11010001
长度=16时,只有后四位参与了运算。1111
索引计算:
通过二次哈希计算得到的哈希值,HashMap 会进一步计算键值对存储的桶索引。计算公式为:
index=hash&(length−1)
- 二次哈希的目的是将哈希值的高位信息混合到低位中,从而增加哈希值的随机性。
- 这样可以减少哈希冲突,特别是在 HashMap 的数组长度较小时。
4.流程问题
4.1 put流程
计算键的哈希值
- 调用键的
hashCode()方法,获取初始哈希值。 - 对初始哈希值进行二次哈希计算,以增加哈希值的随机性。
计算桶索引
- 通过哈希值和数组长度计算键值对存储的桶索引。
index=hash&(length−1)
hash:二次哈希计算得到的哈希值。length:HashMap 中数组的长度(总是 2 的 n 次方)。&:按位与操作。
查找桶中的节点
- 根据计算出的桶索引,找到对应的桶(数组中的位置)。
- 如果桶为空,则直接插入键值对。
- 如果桶不为空,则遍历链表或红黑树,查找是否已经存在相同的键。
处理键冲突
- 如果键已存在 :
- 更新该键对应的值。
- 返回旧值。
- 如果键不存在 :
- 将键值对插入链表或红黑树中。
- 如果链表长度超过阈值(默认是 8),则将链表转换为红黑树。
检查是否需要扩容
- 插入键值对后,检查当前元素数量是否超过负载因子与容量的乘积。
- 如果超过,则触发扩容操作。
扩容操作
- 创建一个新的数组,容量是原数组的两倍。
- 重新计算所有键值对的存储位置(重新哈希)。
- 将键值对从旧数组迁移到新数组。
返回结果
- 如果键已存在,返回旧值。
- 如果键不存在,返回
null。
4.2 扩容
关于这一部分,重点关注下resize函数。
Java
final Node<K, V>[] resize() {
Node<K, V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
// 计算新容量和新阈值
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
} else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY) {
newThr = oldThr << 1; // 双倍扩容
}
} else if (oldThr > 0) {
newCap = oldThr;
} else {
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
// 创建新数组
Node<K, V>[] newTab = (Node<K, V>[])new Node[newCap];
table = newTab;
// 重新分配键值对
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K, V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null) {
newTab[e.hash & (newCap - 1)] = e;
} else if (e instanceof TreeNode) {
((TreeNode<K, V>)e).split(this, newTab, j, oldCap);
} else {
// 链表拆分
Node<K, V> loHead = null, loTail = null;
Node<K, V> hiHead = null, hiTail = null;
Node<K, V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null) {
loHead = e;
} else {
loTail.next = e;
}
loTail = e;
} else {
if (hiTail == null) {
hiHead = e;
} else {
hiTail.next = e;
}
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
// 更新阈值
threshold = newThr;
return newTab;
}相关步骤注释了,可以阅读一遍。
线程安全
HashMap和HashTable的区别
- 线程安全性
- HashTable :是线程安全的,所有方法都用
synchronized修饰,适合多线程环境,但性能较低。 - HashMap :非线程安全,性能更高,适合单线程环境。多线程时需手动同步或使用
Collections.synchronizedMap或ConcurrentHashMap。
- 是否允许 null 键和值
- HashTable :不允许
null键或值,否则会抛出NullPointerException。 - HashMap :允许一个
null键和多个null值。
- 继承关系
- HashTable :继承自
Dictionary类。 - HashMap :继承自
AbstractMap类。
- 迭代器
- HashTable :使用
Enumeration进行迭代,不支持快速失败机制。 - HashMap :使用
Iterator,支持快速失败机制,迭代时若结构被修改会抛出ConcurrentModificationException。
- 性能
- HashTable:由于同步开销,性能较差。
- HashMap:无同步开销,性能更好。
- 初始容量和扩容
- HashTable :默认初始容量为 11,扩容为
2n + 1。 - HashMap :默认初始容量为 16,扩容为
2n。
7.哈希算法
- HashTable :直接使用对象的
hashCode。 - HashMap :对
hashCode进行二次哈希以减少冲突。
2. 线程安全的Map有哪些
| 实现方式 | 线程安全机制 | 是否允许 null 键值 | 性能 | 有序性 |
|---|---|---|---|---|
| Hashtable | 全表锁 | 不允许 | 较低 | 无序 |
| Collections.synchronizedMap | 全表锁 | 允许 | 中等 | 无序 |
| ConcurrentHashMap | 分段锁/CAS | 不允许 | 高 | 无序 |
| ConcurrentSkipListMap | 跳表 | 不允许 | 较高 | 有序 |
| ImmutableMap | 不可变 | 允许 | 最高 | 无序 |
常用的有这些,对比如上
3. ConcurrentHashMap在1.7和1.8的区别
| 特性 | JDK 7 | JDK 8 |
|---|---|---|
| 数据结构 | 分段锁(Segment 数组 + HashEntry 链表) | Node 数组 + 链表/红黑树 |
| 锁机制 | 分段锁(每个 Segment 继承 ReentrantLock) | CAS + synchronized(锁单个 Node) |
| 锁粒度 | 锁住整个 Segment | 锁住单个 Node |
| 并发性能 | 较低(锁粒度较大) | 较高(锁粒度更小,减少锁竞争) |
| 内存占用 | 较高(每个 Segment 独立维护哈希表) | 较低(去除了 Segment,结构更紧凑) |
| 扩容机制 | 分段扩容(每个 Segment 独立扩容) | 整体扩容(动态调整 Node 数组大小) |
| 哈希冲突处理 | 链表 | 链表 + 红黑树(链表过长时转换为红黑树) |
| 红黑树支持 | 不支持 | 支持(链表长度超过阈值时转换为红黑树) |
| 迭代器一致性 | 弱一致性 | 弱一致性 |
| null 键值支持 | 不允许 null 键或值 | 不允许 null 键或值 |
| 动态调整 | 不支持动态调整 Segment 数量 | 支持动态调整 Node 数组大小 |
| 实现复杂度 | 较高(分段锁机制复杂) | 较低(CAS + synchronized 实现更简洁) |
| 适用场景 | 中等并发场景 | 高并发场景 |
Map工具类
Maps
Maps是Guava中常用的map工具类,具体如下:
| 方法 | 功能描述 | 示例 |
|---|---|---|
| Maps.newHashMap() | 创建一个空的 HashMap。 | Map<String, Integer> map = Maps.newHashMap(); |
| Maps.newLinkedHashMap() | 创建一个空的 LinkedHashMap。 | Map<String, Integer> map = Maps.newLinkedHashMap(); |
| Maps.newTreeMap() | 创建一个空的 TreeMap。 | Map<String, Integer> map = Maps.newTreeMap(); |
| Maps.newConcurrentMap() | 创建一个空的 ConcurrentHashMap。 | Map<String, Integer> map = Maps.newConcurrentMap(); |
| Maps.newHashMapWithExpectedSize(int expectedSize) | 创建一个 HashMap,并根据预期大小优化初始容量。 | Map<String, Integer> map = Maps.newHashMapWithExpectedSize(10); |
| Maps.newLinkedHashMapWithExpectedSize(int expectedSize) | 创建一个 LinkedHashMap,并根据预期大小优化初始容量。 | Map<String, Integer> map = Maps.newLinkedHashMapWithExpectedSize(10); |
| Maps.uniqueIndex(Iterable values, Function<V, K> keyFunction) | 根据 keyFunction 从 Iterable 中提取键,创建一个 Map。 | Map<String, Person> map = Maps.uniqueIndex(persons, Person::getId); |
| Maps.asMap(Set keys, Function<K, V> valueFunction) | 根据 keys 和 valueFunction 创建一个 Map,值为 valueFunction 的计算结果。 | Map<String, Integer> map = Maps.asMap(keys, k -> k.length()); |
| Maps.filterKeys(Map<K, V> map, Predicate keyPredicate) | 过滤 Map,保留满足 keyPredicate 的键值对。 | Map<String, Integer> filtered = Maps.filterKeys(map, k -> k.startsWith("a")); |
2. ImmutableMap
ImmutableMap 是 Guava(Google 提供的 Java 工具库)中的一个不可变 Map 实现。它表示一个不可修改的键值对集合,线程安全且性能优异。
Java 9 引入了 Map.of() 方法,用于创建不可变 Map。与 ImmutableMap 的区别如下:
| 特性 | Guava ImmutableMap | Java 9+ Map.of() |
|---|---|---|
| 最大容量 | 无限制 | 最多 10 个键值对 |
| null 键值支持 | 不允许 | 不允许 |
| 有序性 | 保持插入顺序 | 无序 |
| 依赖库 | 需要引入 Guava | 无需额外依赖 |
与HashMap的区别
| 特性 | ImmutableMap | HashMap |
|---|---|---|
| 可变性 | 不可变(创建后不能添加、删除或修改键值对) | 可变(支持添加、删除和修改键值对) |
| 线程安全 | 线程安全(由于不可变性) | 非线程安全(需要额外同步机制) |
| null 键值支持 | 不允许 null 键或值 | 允许一个 null 键和多个 null 值 |
| 性能 | 读取性能高(无需同步,数据结构优化) | 读写性能高,但多线程环境下需要额外同步 |
| 有序性 | 保持插入顺序 | 无序 |
| 创建方式 | 使用 of()、builder() 或 copyOf() 方法创建 | 直接通过构造函数创建 |
| 内存占用 | 较低(数据结构优化) | 较高(需要支持动态修改) |
| 适用场景 | 存储不可变数据(如配置、常量)、线程安全共享数据 | 存储动态数据、单线程环境或需要修改的场景 |
| 依赖库 | 需要引入 Guava | Java 标准库,无需额外依赖 |
| 示例代码 | ImmutableMap.of("a", 1, "b", 2) | HashMap<String, Integer> map = new HashMap<>(); |
HashSet
对于HashSet首先需要知道的一点是,HashSet是基于HashMap实现的。

| 较高(需要支持动态修改) |
| 适用场景 | 存储不可变数据(如配置、常量)、线程安全共享数据 | 存储动态数据、单线程环境或需要修改的场景 |
| 依赖库 | 需要引入 Guava | Java 标准库,无需额外依赖 |
| 示例代码 | ImmutableMap.of("a", 1, "b", 2) | HashMap<String, Integer> map = new HashMap<>(); |
HashSet
对于HashSet首先需要知道的一点是,HashSet是基于HashMap实现的。
外链图片转存中...(img-QztUYjl9-1768403310699)
知道了这一点,其他的问题基本就全部转化为HashMap的问题了。