ArenaRL:用"锦标赛相对排序"把开放式智能体的 RL 拉出噪声泥潭
一句话结论
这篇论文提出 ArenaRL ,把开放式任务里"点式标量打分"的奖励范式改成 组内相对排序 + 锦标赛机制 ,用线性复杂度实现接近全对比的优势估计精度,并配套构建了 Open-Travel 与 Open-DeepResearch 两个完整训练-评测基准。
1. 问题背景:开放式任务为何难训?
在旅行规划、深度研究这类开放式任务里,没有客观标准答案,主流做法是用 LLM-as-a-Judge 对单条轨迹打一个分数。但作者指出一个关键问题: 判别塌缩(discriminative collapse) 。
当模型逐渐变强时,轨迹之间质量差距缩小,评分集中在狭窄区间,评分噪声反而成为主导,导致 RL 信号极不稳定。
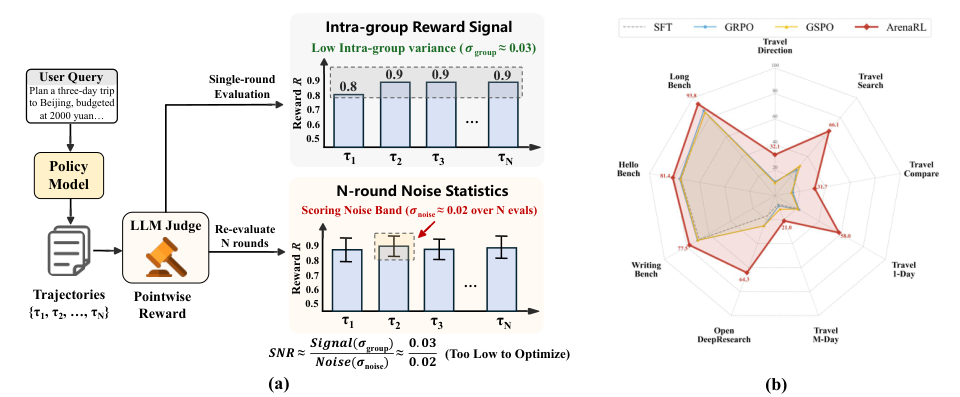
图解:左侧展示点式评分出现"评分集中 + 噪声不低"的现象,信噪比极差;右侧对比显示 ArenaRL 在多个开放式任务上显著优于 SFT/GRPO/GSPO。
2. ArenaRL 核心思想:从"标量打分"转向"组内排序"
ArenaRL 把奖励建模改成 组内相对排序 。流程是:
- 对同一输入生成一组轨迹 G = { τ 1 , ... , τ N } \mathcal{G}=\{\tau_1,\dots,\tau_N\} G={τ1,...,τN}
- 用 成对比较的裁判 给出相对胜负
- 用 锦标赛拓扑 高效地得到排序
- 用排序映射为可优化的优势值
核心公式如下:
排序奖励映射
r i = 1 − Rank ( τ i ) N − 1 r_i = 1 - \frac{\text{Rank}(\tau_i)}{N-1} ri=1−N−1Rank(τi)
标准化优势
A i = r i − μ r σ r + ϵ A_i = \frac{r_i - \mu_r}{\sigma_r + \epsilon} Ai=σr+ϵri−μr
优化目标(带 KL 约束)
L ArenaRL ( θ ) = E 1 N ∑ i = 1 N ( PPO-clip ( A i ) − β D K L ) \mathcal{L}_{\text{ArenaRL}}(\theta) = \mathbb{E}\Bigg\\frac{1}{N}\\sum_{i=1}\^N\\big( \\text{PPO-clip}(A_i) - \\beta D_{KL}\\big)\\Bigg LArenaRL(θ)=EN1i=1∑N(PPO-clip(Ai)−βDKL)
3. 过程感知的成对评价(Process-Aware Pairwise Evaluation)
作者不是只比较最终答案,而是让裁判 对整个推理轨迹进行对比 :链式推理、工具调用是否合理、最终答案是否靠谱。
为了减少裁判位置偏置,采用双向比较:
( s i , s j ) = J ( x , τ i , τ j ) + J ( x , τ j , τ i ) (s_i, s_j) = \mathcal{J}(x,\tau_i,\tau_j) + \mathcal{J}(x,\tau_j,\tau_i) (si,sj)=J(x,τi,τj)+J(x,τj,τi)
4. 锦标赛拓扑:线性复杂度里的"高精度排序"
论文测试了 5 种拓扑,最终发现 带种子单淘汰(Seeded Single-Elimination) 是最优折中。
核心思路:
- 用 "anchor"(贪心解码轨迹)进行预排序
- 采用种子顺序构建淘汰赛
- 结合晋级轮次与累计得分做分层排序
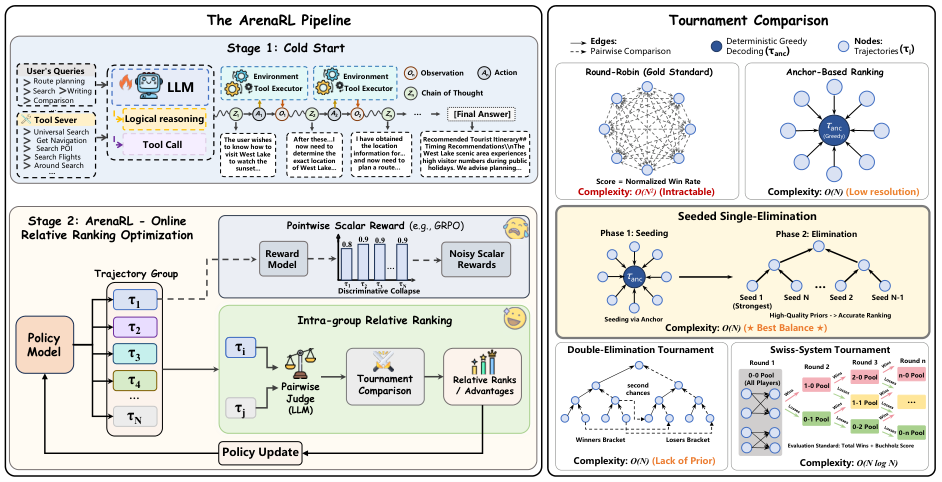
图解:ArenaRL 先用锚点排名,再进行单淘汰锦标赛,最终按晋级层级 + 累积分数完成排序,从而高效得到稳定优势信号。
5. ArenaRL 的完整训练闭环
ArenaRL 不仅提出算法,还给出 训练-评测一体化基准 :
- Open-Travel :多约束旅行规划
- Open-DeepResearch :开放式调研、检索、报告生成
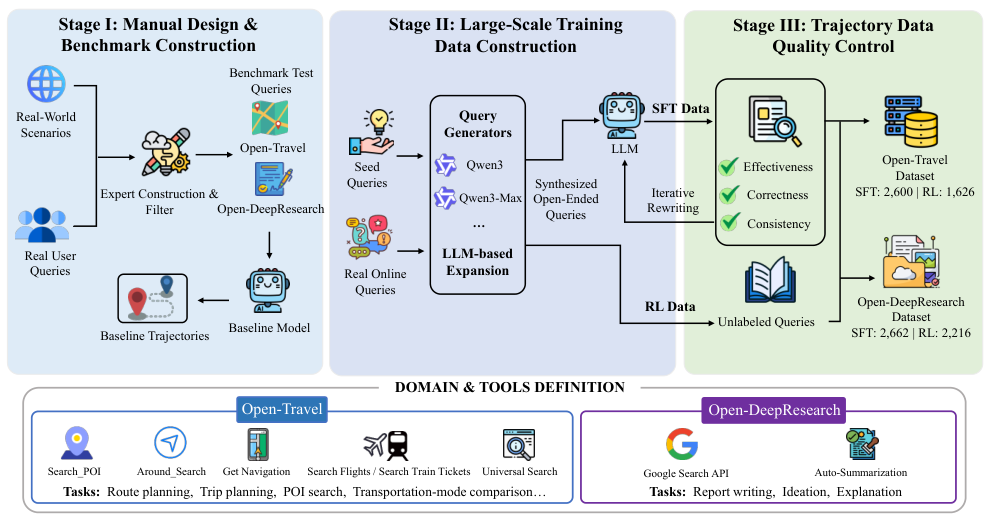
图解:基准构建流程分三阶段:数据收集、训练数据扩展、质量控制,形成可用于 SFT + RL + 评测的完整闭环。
6. 核心实验结果
6.1 不同锦标赛拓扑比较
Seeded Single-Elimination 的表现几乎追平 Round-Robin,但成本从 O ( N 2 ) \mathcal{O}(N^2) O(N2) 降为 O ( N ) \mathcal{O}(N) O(N)。
6.2 与主流 RL 基线对比
- 在 Open-Travel 上,ArenaRL 平均胜率 41.8% ,远高于 GRPO/GSPO
- 在 Open-DeepResearch 上,ArenaRL 胜率 64.3% ,有效生成率 99%
这说明 ArenaRL 不仅效果更好,而且更稳定。
6.3 开放式写作任务
在 WritingBench / HelloBench / LongBench 上整体领先,证明该范式能泛化到非工具任务。
7. 关键可视化分析
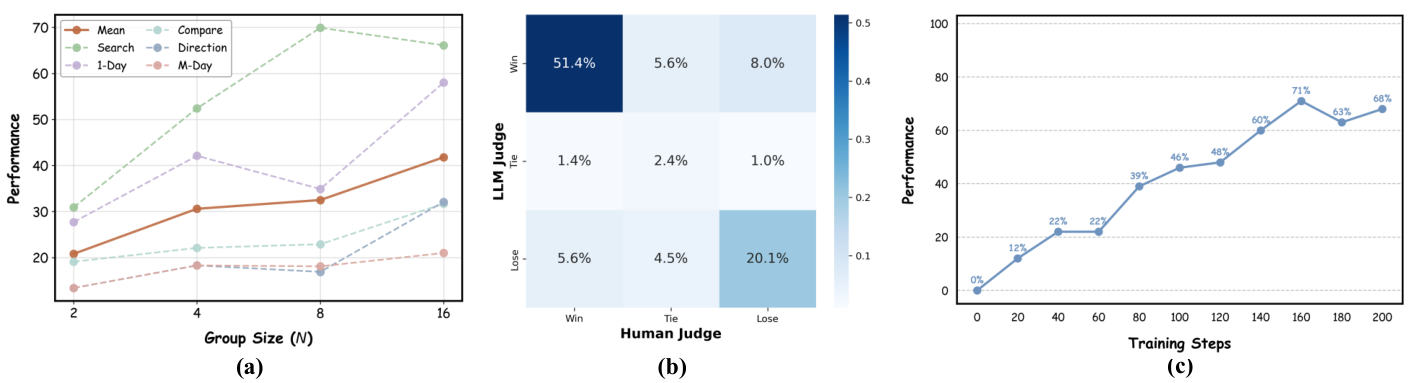
图解:
(a) 组大小 N 越大性能越好,表明更大候选池能提升探索质量。
(b) LLM 评估与人类评估的一致性达 73.9%,说明提升不是"对裁判过拟合"。
© 即使没有冷启动,ArenaRL 仍能稳定提升,说明其奖励信号鲁棒。
8. 方法亮点与创新点总结
- 痛点切得准 :抓住开放式 RL 的核心问题"判别塌缩"
- 奖励建模升级 :从点式打分转向相对排序,鲁棒性显著提升
- 效率友好 :线性比较复杂度却接近全对比精度
- 完整闭环 :不仅提出算法,还搭建基准和训练流程
9. 结论与展望
ArenaRL 用 相对排序 + 锦标赛机制 打破开放式任务的奖励噪声瓶颈,在效率与精度之间取得高质量平衡。未来方向包括:
- 推广到多模态智能体
- 更复杂工具链场景
- 结合人类偏好引导更细粒度排序
本文参考自 ArenaRL: Scaling RL for Open-Ended Agents via Tournament-based Relative Ranking