目录:
一、加载tokenizer
python
import torch
from transformers import AutoTokenizer
#加载tokenizer
tokenizer = AutoTokenizer.from_pretrained('google-bert/bert-base-chinese')
tokenizer
二、加载数据集和编码
python
from datasets import load_dataset
#加载数据集
dataset = load_dataset(path='lansinuote/ChnSentiCorp')
#编码
f = lambda x: tokenizer(x['text'], truncation=True, max_length=500)
dataset = dataset.map(f, remove_columns=['text'])
#设置数据类型
dataset.set_format('pt')
dataset, dataset['train'][0]
三、加载模型
python
#定义模型
from transformers import BertConfig, BertForSequenceClassification
#在线加载一个语句分类模型
model = BertForSequenceClassification.from_pretrained(
'google-bert/bert-base-chinese', num_labels=2)
model.config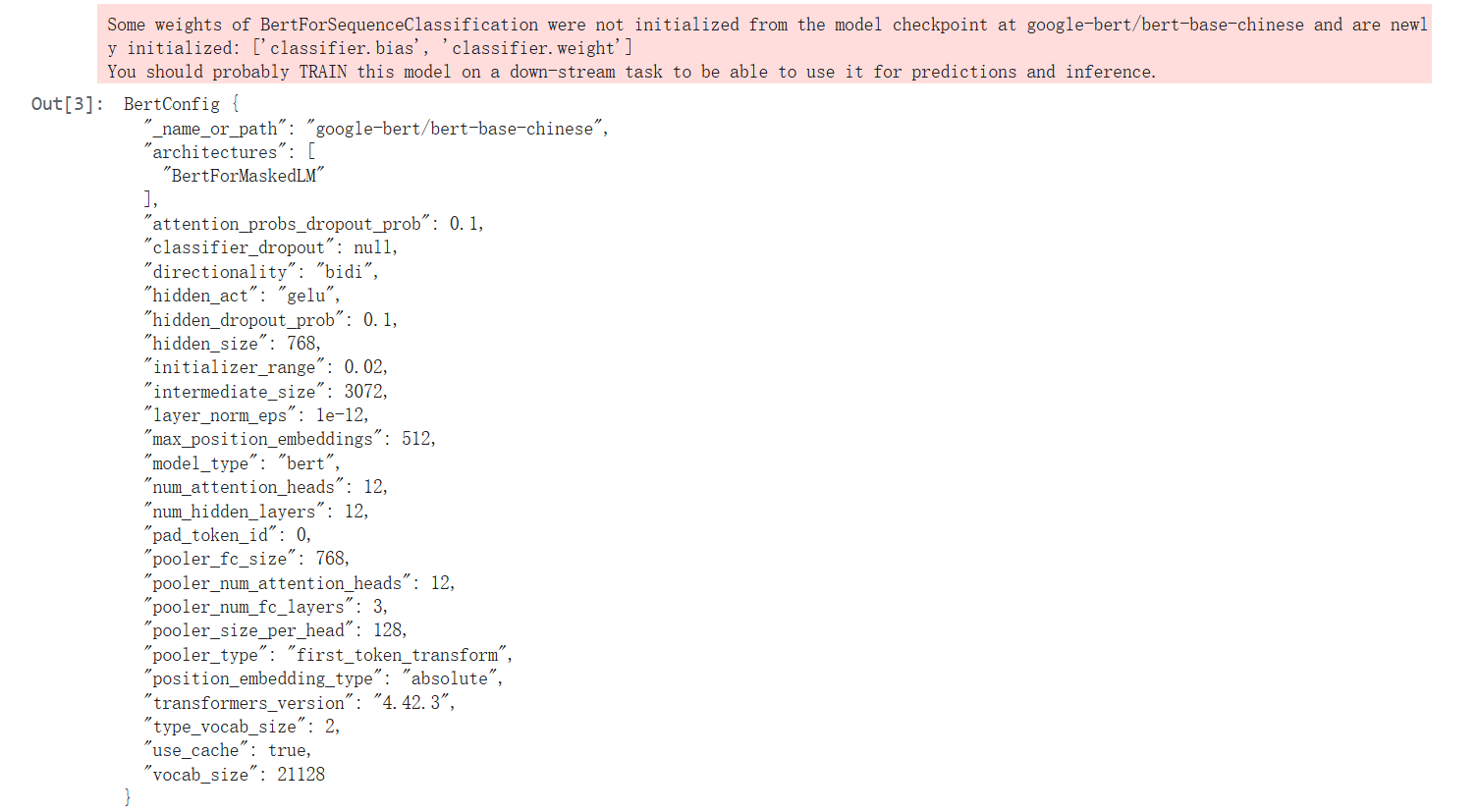
四、执行训练
python
from transformers import TrainingArguments, Trainer, DataCollatorWithPadding
#配置训练参数
args = TrainingArguments(output_dir='output_dir',
use_cpu=True,
num_train_epochs=1,
max_steps=300,
eval_strategy='no',
per_device_train_batch_size=8)
#创建trainer
trainer = Trainer(model=model,
args=args,
train_dataset=dataset['train'],
data_collator=DataCollatorWithPadding(tokenizer))
#执行训练
trainer.train()
五、执行测试
python
#执行测试
def test():
loader_test = torch.utils.data.DataLoader(
dataset['test'],
batch_size=8,
shuffle=True,
drop_last=True,
collate_fn=DataCollatorWithPadding(tokenizer))
correct = 0
total = 0
for i, data in enumerate(loader_test):
with torch.no_grad():
out = model(**data).logits
out = out.argmax(dim=1)
correct += (out == data.labels).sum().item()
total += len(data.labels)
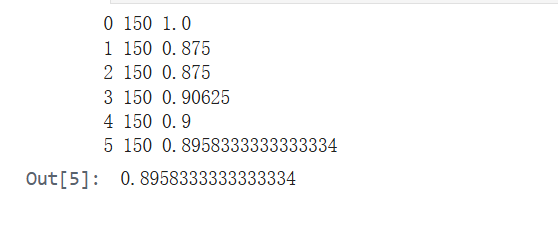
print(i, len(loader_test), correct / total)
if i == 5:
break
return correct / total
test()