kubectl top nodes 或 kubectl top pods 返回 metrics not available yet 的排查、解决
Metrics Server 是 Kubernetes 集群中用于收集和聚合节点、Pod 的资源使用指标(Metrics) 的核心组件,主要提供 CPU、内存等基础资源的实时使用率数据。这些数据是 Kubernetes 自动扩缩容(HPA)、调度优化以及资源监控的基础。
Metrics Server 的核心作用:
- 收集指标:从集群中所有节点的
kubelet服务(通过kubelet的 Metrics API,默认端口10250)收集节点和 Pod 的资源使用数据(CPU 使用率、内存使用量等)。 - 聚合数据:将分散的指标数据聚合后,通过 Kubernetes API(
metrics.k8s.io群组)提供统一访问接口。 - 支撑功能:为
kubectl top命令(查看资源使用)和HorizontalPodAutoscaler(HPA,自动扩缩容)提供数据支持。
安装部署 metrics-server 后,使用 kubectl top nodes 或 kubectl top pods 查看资源使用时,显示异常:
bash
metrics not available yet初步简单排查
先做一个简单的排查,获得一个初步的判断:
-
kubectl logs来查看对应的metrics-server容器日志,确认是否有异常信息。bashkubectl logs -n kube-system deployment/metrics-server -
检查
metrics-server对应的Deployment中对应容器的args配置,最小化修改来解决问题:--kubelet-insecure-tls,确认 TLS 配置是对应的,可以先跳过 kubelet 的 TLS 证书验证(测试环境常用,生产环境不建议),这个是否配置。--kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname,指定 kubelet 连接时优先使用的地址类型(默认是InternalIP)。
-
对照官方 issues 文档
https://github.com/kubernetes-sigs/metrics-server/blob/master/KNOWN_ISSUES.md排查是否有类似问题。
详细排查流程
metrics-server 获得 nodes 和 pods 的 metrics 数据的大致流程:

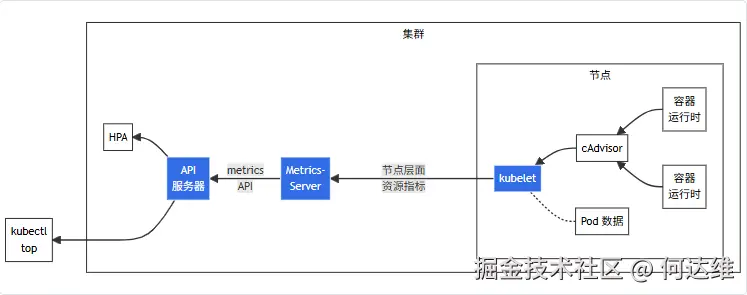
- cAdvisor: 用于收集、聚合和公开 Kubelet 中包含的容器指标的守护程序。
- kubelet: 用于管理容器资源的节点代理。可以使用
/metrics/resource和/statskubelet API 端点访问资源指标。/api/v1/nodes/<节点名>/proxy/metrics/cadvisor:由 cadvisor 组件提供,专注于容器和节点的细粒度资源使用指标。/api/v1/nodes/<节点名>/proxy/metrics/resource:提供 节点和 Pod 的资源请求(request)、限制(limit)及实际使用的汇总数据,数据更贴近 k8s 资源模型(与requests/limits直接关联)。/api/v1/nodes/<节点名>/proxy/healthz:提供 kubelet 健康状态指标。/api/v1/nodes/<节点名>/proxy/metrics/probes:专门记录容器探针(liveness、readiness、startup)的执行状态,用于监控探针是否正常工作。/api/v1/nodes/<节点名>/proxy/stats/summary:提供节点级别的资源指标,包括 CPU、内存、网络和磁盘 IO。
- 节点层面资源指标: kubelet 提供的 API,用于发现和检索可通过
/metrics/resource端点获得的每个节点的汇总统计信息。 - metrics-server: 集群插件组件,用于收集和聚合从每个 kubelet 中提取的资源指标。API 服务器提供 Metrics API 以供 HPA、VPA 和
kubectl top命令使用。Metrics Server 是 Metrics API 的参考实现。 - Metrics API: Kubernetes API 支持访问用于工作负载自动缩放的 CPU 和内存。要在你的集群中进行这项工作,你需要一个提供 Metrics API 的 API 扩展服务器。
围绕 "指标收集链路"(容器 -> cadvisor -> metrics-server -> kubectl/HPA)展开,逐步定位断裂点:
- 确认 metrics-server 已正确注册
metrics.k8s.io/v1beta1API 服务。 - 检查 RBAC 权限:确保 metrics-server 有足够权限读取节点指标。
- 确认指标来源:cadvisor 是否生成容器指标。
- 访问节点的 cadvisor 指标端点:
curl http://<控制平面IP>:8001/api/v1/nodes/<节点名>/proxy/metrics/cadvisor。- 若仅包含
machine_*等机器级指标,无container_*(带pod_name、namespace标签)指标,说明 cadvisor 未收集到容器数据,问题聚焦于 cadvisor 与容器的交互。
- 若仅包含
- 访问节点的 cadvisor 指标端点:
- cadvisor 依赖 kubelet 从容器运行时(如 containerd)获取容器元数据(如容器 ID),需确认 kubelet 能正常识别容器:
- 访问节点的 pods 端点:
curl http://<控制平面IP>:8001/api/v1/nodes/<节点名>/proxy/pods | jq '.items[].status.containerStatuses[].containerID'。- 若输出
containerd://<容器ID>格式的字符串,说明 kubelet 能从容器运行时获取容器 ID,排除基础通信故障。 - 若为空,需修复 kubelet 与容器运行时的连接(如检查
containerRuntimeEndpoint配置)。
- 若输出
- 访问节点的 pods 端点:
- 排查 cgroup 配置与兼容性,cadvisor 通过容器的 cgroup 路径(如
/sys/fs/cgroup)获取资源数据,cgroup 驱动或版本不兼容会导致路径匹配失败:- cgroup 驱动一致性:确保 kubelet(
cgroupDriver: systemd)与容器运行时(如 containerd 的SystemdCgroup: true)使用相同驱动,尤其是 cgroup2 环境必须搭配systemd驱动。 - cgroup2 适配:若使用 cgroup2,需确认 cadvisor(v0.43+)、kubelet(v1.25+)、容器运行时(containerd v1.6+)版本支持 cgroup2,并验证容器的 cgroup 路径(如
/sys/fs/cgroup/kubepods.slice/.../<容器ID>.scope)存在且可访问。
- cgroup 驱动一致性:确保 kubelet(
- 检查 kubelet 配置对 cadvisor 的影响,kubelet 配置可能绕过 cadvisor 导致指标缺失:
PodAndContainerStatsFromCRI特性开关:若开启(true),kubelet 会从容器运行时直接获取指标,可能导致 cadvisor 不生成数据,需关闭(false)让 cadvisor 接管。- cadvisor 初始化日志:查看 kubelet 日志(
journalctl -u kubelet),确认cadvisor initialization complete日志存在,排除 cadvisor 未启动的问题。
- 验证 metrics-server 能否拉取指标,若 cadvisor 有容器指标,但
kubectl top pods仍无数据,需检查 metrics-server 是否正常拉取:- 查看 metrics-server 配置:确保
--cadvisor-url-prefix指向正确的 cadvisor 端点(内置 cadvisor 为http://{{.NodeInternalIP}}:10255/metrics/cadvisor,独立部署为http://{{.NodeInternalIP}}:8080/)。 - 查看 metrics-server 日志:排查是否有
no metrics known for pod等拉取失败错误,修复网络或权限问题(如--kubelet-insecure-tls临时绕过 TLS 验证)。
- 查看 metrics-server 配置:确保
- 若内置 cadvisor 因版本或环境限制无法修复,可独立部署 cadvisor:
- 通过 DaemonSet 部署支持 cgroup2 的 cadvisor(v0.47+),挂载
--volume=/sys/fs/cgroup确保访问 cgroup 路径。 - 配置 metrics-server 指向独立 cadvisor 的端点,绕开内置组件的兼容性问题。
- 通过 DaemonSet 部署支持 cgroup2 的 cadvisor(v0.47+),挂载
核心逻辑是 "从指标生成端(cadvisor)到消费端(kubectl)逐步验证链路",重点排查:
- cadvisor 能否通过 cgroup 路径获取容器数据(依赖 cgroup 驱动、版本兼容)。
- 容器运行时与 kubelet 的通信是否正常(确保容器元数据可获取)。
- metrics-server 能否正确拉取并提供指标(配置正确的 cadvisor 端点)。
上面的排查思路不一定是串行有着严格的先后顺序,可以参考以下操作来进行。
若节点存在多个集群内部 IP,检查是否所有节点的 InternalIP 是否正确:
bash
kubectl get nodes -o wide确认 metrics-server 已正确注册 metrics.k8s.io/v1beta1 API 服务:
bash
kubectl get apiservices v1beta1.metrics.k8s.io -o yaml检查 RBAC 权限:
-
使用
kubectl get --raw "/apis/metrics.k8s.io/v1beta1/nodes" | jq的方式查看节点指标,若是类似的返回:json{ "kind": "NodeMetricsList", "apiVersion": "metrics.k8s.io/v1beta1", "metadata": {}, "items": [] }- 若看到
items数组为空,说明 metrics-server 已成功注册 API,但未采集到任何节点指标数据。
- 若看到
-
查看 metrics-server 使用的 ServiceAccount。
-
检查 metrics-server 的 ClusterRole(包含节点指标必需的权限)和 ClusterRoleBinding(将权限绑定到 metrics-server 的 ServiceAccount),检查权限是否足够。
先确保 cgroup 能工作(不代表一切正常):
- 检查异常节点的 cgroup 的版本。
- 确保 Linux 内核版本为 5.8 或更高版本。
cgroup v1 和 cgroup v2 是 Linux 内核中两套不同的控制组(cgroup)实现,核心目标都是对进程进行资源(CPU、内存、IO 等)的限制、隔离和监控,但在架构设计、功能特性和使用方式上有显著区别:
-
cgroup v1
-
采用 "每个控制器独立层次结构" 设计,每个资源控制器(如 CPU、内存、IO 等)有自己独立的挂载点和目录结构。
bash/sys/fs/cgroup/cpu/ # CPU 控制器 /sys/fs/cgroup/memory/ # 内存控制器 /sys/fs/cgroup/blkio/ # IO 控制器 -
各控制器的资源限制是独立的,可能出现逻辑冲突,进程可跨多个层级,比如为一个进程组设置了 CPU 限制(
cpu.cfs_quota_us)和内存限制(memory.limit_in_bytes),但两者的限制逻辑不互通,可能导致 "内存耗尽但 CPU 仍有剩余" 的不合理状态。 -
权限控制宽松,非特权进程(如容器内的进程)可能通过修改 cgroup 配置突破资源限制(例如修改
memory.limit_in_bytes扩大内存配额),存在安全风险。
-
-
cgroup v2
-
采用 "统一层次结构" 设计,所有资源控制器共享一个根目录(
/sys/fs/cgroup/),进程组在单一层次结构中管理,统一接口(cgroup.controllers管理),所有资源配置集中在同一目录下。bash/sys/fs/cgroup/ # 所有控制器共享的根目录 /sys/fs/cgroup/xxx-pod-xxx/ # 某 Pod 的所有资源配置(CPU、内存等) -
资源限制是协同的,进程仅能属于单一层级的叶子节点,支持 "资源间依赖控制",比如当进程组触发内存限制时,v2 会自动调整 CPU 调度,避免因内存不足导致的 CPU 空转,同时引入 "压力反馈机制"(如内存压力触发 IO 限制),更符合实际应用的资源使用规律。
-
只有根 cgroup(
/sys/fs/cgroup/)可配置全局资源限制,子 cgroup(如容器的 cgroup)的权限被严格限制,非特权进程无法修改父 cgroup 的配置,防止权限逃逸,更适合多租户环境(如 Kubernetes 集群)。
-
查看当前 cgroups 的文件系统类型:
bash
stat -fc %T /sys/fs/cgroup/- 若输出
cgroup2fs,则已启用 cgroups v2。 - 若输出
tmpfs或cgroup,则当前使用 cgroups v1。 - 需要注意的是,按照 k8s 的官方文档说明,从 Kubernetes 1.31 开始对 cgroup v1 的支持转为维护模式,推荐使用 cgroup v2。
使用 cgroup v2 的要求:
- Linux 发行版本身支持 cgroup v2
- Ubuntu(从 21.10 开始,推荐 22.04+)
- Fedora(从 31 开始)
- RHEL 和类似 RHEL 的发行版(从 9 开始)
- Linux 内核为 5.8 或更高版本
- 容器运行时支持 cgroup v2
- containerd v1.4 和更高版本
- cri-o v1.20 和更高版本
- kubelet 和容器运行时被配置为使用 systemd cgroup 驱动
-
将
systemd设置为 cgroup 驱动,编辑kubelet配置(比如/etc/kubernetes/kubelet/kubelet.conf)中KubeletConfiguration的 cgroupDriver 选项设置为systemd:yamlapiVersion: kubelet.config.k8s.io/v1beta1 kind: KubeletConfiguration ... cgroupDriver: systemd -
修改
containerd配置文件/etc/containerd/config.toml,配置systemdcgroup 驱动:-
Containerd 1.x 版本:
toml[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc] ... [plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc.options] SystemdCgroup = true -
Containerd 2.x 版本:
toml[plugins.'io.containerd.cri.v1.runtime'.containerd.runtimes.runc] ... [plugins.'io.containerd.cri.v1.runtime'.containerd.runtimes.runc.options] SystemdCgroup = true
-
-
若使用 CRI-O,确保
/etc/crio/crio.conf或/etc/crio/crio.conf.d/02-cgroup-manager.conf包含配置: crio.runtime conmon_cgroup = "pod" cgroup_manager = "cgroupfs"
-
异常节点让 cgroup 工作正常:
-
切换至 cgroup v1 模式。
-
修改
/etc/default/grub关闭 cgroup v2,在GRUB_CMDLINE_LINUX中去掉systemd.unified_cgroup_hierarchy=1:bash# 在 GRUB_CMDLINE_LINUX 去掉 systemd.unified_cgroup_hierarchy=1 GRUB_CMDLINE_LINUX="numa=off transparent_hugepage=never systemd.unified_cgroup_hierarchy=1" -
更新 GRUB 配置并重启:
bashsudo update-grub sudo reboot # 检查节点是否已切换至 cgroup v1 模式 stat -fc %T /sys/fs/cgroup/ # 预期输出:tmpfs # 检查 v1 控制器目录是否存在 ls -d /sys/fs/cgroup/cpu /sys/fs/cgroup/memory /sys/fs/cgroup/pids # 预期输出:/sys/fs/cgroup/cpu /sys/fs/cgroup/memory /sys/fs/cgroup/pids -
修改节点的
/etc/kubernetes/kubelet/kubelet.conf配置文件:yamlcgroupDriver: cgroupfs -
编辑
containerd配置文件/etc/containerd/config.toml:-
找到
[plugins."io.containerd.grpc.v1.cri"]部分,添加或修改:toml[plugins."io.containerd.grpc.v1.cri"] cgroup_driver = "cgroupfs" -
在
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc.options]下添加:toml[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc.options] SystemdCgroup = false -
重启
containerd服务:bashsudo systemctl restart containerd
-
-
修改节点的
/etc/kubernetes/kubelet/kubelet.conf配置文件,修改:yamlcgroupDriver: cgroupfs-
重启 kubelet 服务:
bashsudo systemctl restart kubelet
-
-
-
升级内核(推荐)。
-
升级系统(不推荐)。
经过上述排查、操作后,执行 kubectl top nodes 大概率能正常返回节点指标,但是执行 kubectl top pods 可能依旧会提示 error: metrics not available yet,可能是部分节点或者全部节点表现异常。
在控制平面节点访问异常节点的 kubelet 指标接口(<node-name> 为异常节点的名称如 worker-node-1):
bash
kubectl get --raw /api/v1/nodes/<node-name>/proxy/stats/summary- 若返回包含 pods 列表及每个 Pod 的
cpu/memory数据,说明 kubelet 指标生成正常,问题在 Metrics Server 与该节点的通信。 - 若返回空或 500 Internal Server Error:说明 kubelet 自身无法生成指标,需要重点排查 kubelet 日志中的 cadvisor 或 stats 错误)。
查看节点的 cadvisor 指标:
bash
kubectl get --raw /api/v1/nodes/<node-name>/proxy/metrics/cadvisor若看到当前 metrics/cadvisor 只有机器级指标,却无任何容器/Pod 指标,需要进一步确认。
查看目标节点上的 Pod 及容器信息(cadvisor 依赖此数据关联容器),确认 kubelet 是否能从 containerd 获取容器 ID:
bash
kubectl get --raw /api/v1/nodes/<node-name>/proxy/pods | jq '.items[].status.containerStatuses[].containerID'-
若返回类似的结果,说明 kubelet 与 containerd 的通信是正常的:
bash"containerd://b7fde5066a7ff44ee03e7a7d9e8dd0c2c228d6999691c9d22c551737498707f9" "containerd://2fb7393157b064e4dcc0d3f9bd2675c546b5762db0f8b8924e891bb773ec3133" "containerd://171a73a37482e107ede2f51c95670ecd769ec0a4c1dc0c025a4f2988bc116cc1" "containerd://f1bbb1da3a69eeddd6fafeb60f7680fa21f2afa7f8169eae4049d0e1ffd89582" "containerd://cc9dc5100015d55610995c2b73df6d8f116ed25314beb0b0a6d4ed48e7a1093e" "containerd://ad1bafd1975205ac7d76c188aa4ee574ae89cb4af07e3479b5524fe7a6e349e8" ...
或者直接调用指标 API 验证对应的 pods 是否返回结果:
bash
kubectl get --raw "/apis/metrics.k8s.io/v1beta1/namespaces/web-nginx-prod/pods?labelSelector=app%3Dnginx-v1"要明白cadvisor 收集容器指标的逻辑:
rust
容器 ID -> 对应 cgroup 路径(如 /sys/fs/cgroup/cpu/<容器ID>)-> 读取 cgroup 文件(如 cpuacct.usage)获取资源数据- cgroup v1 的容器路径通常是
/sys/fs/cgroup/cpu/kubepods/.../<容器ID>(每个子系统单独路径)。 - cgroup v2 的容器路径统一为
/sys/fs/cgroup/kubepods.slice/.../<容器ID>.scope(单一层级,所有资源数据在同一目录下)。
若使用 cgroup v2,查找该容器在 cgroup2 中的路径:
bash
find /sys/fs/cgroup -name "*$CONTAINER_ID*.scope"若返回类似:
python
/sys/fs/cgroup/kubepods.slice/kubepods-besteffort.slice/kubepods-besteffort-poda5175edd_e7fc_4e68_870c_5b1befd652ac.slice/cri-containerd-b7fde5066a7ff44ee03e7a7d9e8dd0c2c228d6999691c9d22c551737498707f9.scope说明 containerd 已正确为容器创建 cgroup2 目录,cgroup v2 工作正常,那么问题大概在 cadvisor 与 kubelet 配置的匹配上。
还有一个干扰因素,检查 kubelet 配置是否启用了 CRI 容器统计:
yaml
featureGates:
PodAndContainerStatsFromCRI: true # 启用了 CRI 容器统计
KubeletCgroupDriverFromCRI: true特性开关 PodAndContainerStatsFromCRI 启用后,kubelet 会直接从容器运行时(CRI,即 containerd)获取容器/Pod 的统计数据,而非依赖内置的 cadvisor,这会导致 cadvisor 虽然仍在运行,但可能不再主动收集容器指标(因为 kubelet 已通过 CRI 拿到数据,无需 cadvisor 重复工作),通常的表现是执行 kubectl top nodes 能正常返回节点状态,但是执行 kubectl top pods 无法返回节点的 Pod 状态。
把 PodAndContainerStatsFromCRI: true 注释掉或者设置为 false,重启 kubelet 服务,恢复正常。