大促备战中的代码评审困境与破局
双十一大促是系统稳定性的终极"大考"。为规避上线风险,技术侧会启动系统封板管控,主动将非紧急需求的发布窗口前置。这一举措在保障系统稳定性的同时,也必然导致研发需求的前置与集中,使得封板前的代码评审任务量显著增加。我们面临着一个严峻的"量与质"的挑战:
如何在时间紧、任务重的双重压力下,确保代码评审的效率与质量,从而前置发现潜在风险,有效拦截线上BUG?
传统的代码评审模式在此场景下效率低、质量差(风险遗漏的可能性高),而现有的AI辅助工具又因误报率高而陷入尴尬:产生的多数评审意见并无实质帮助,工程师仍需花费大量时间进行判断与筛选。
正是在此背景下,【供应链技术部-商家导入研发组】在AI代码评审方面进行了一些探索,尝试将知识工程代码知识检索能力与AutoBots(已更名为:JoyAgent)知识库检索能力相结合,构建了一套代码评审系统。这套双RAG架构为我们的代码评审工作提供了一些新思路,在此分享出来,希望与各位同行交流探讨,共同进步。
现有技术方案的局限性
技术1:基于流水线的AI代码评审方案
核心技术路径: 在通过公共流程(Webhook触发、解析MR、获取Diff)得到代码变更内容后,该方案的核心处理流程如下:
1.文件类型过滤:仅保留.java、.yaml和.md文件进行后续分析,并明确优先级的处理顺序。
2.上下文截断:为避免触及大模型上下文窗口上限,采用了一种基于固定行数的上下文截断策略。该策略仅截取代码变更处附近预设行数(如10行)的文本内容。
3.Prompt驱动评审:将经过过滤和截断后的代码片段,与预设的评审规则Prompt组合,发送给通用大语言模型。
4.输出评审意见:解析大模型的返回结果,通过coding平台API将评审结果添加到MR中。
核心问题识别:
1.全局上下文缺失:其采用的"固定行数截断"策略是导致问题的根本原因之一。这使得评审完全丧失了项目架构、模块依赖和完整业务逻辑的视野,如同"管中窥豹",评审深度和准确性受到严重制约。
2.提示词天花板:所有评审规则与知识硬编码于Prompt中,规则膨胀后极易触及模型上下文长度上限,可维护性与扩展性差。
3.知识无法沉淀:效果提升完全依赖于"更换更强的基础模型"与"调整Prompt",自身缺乏可持续积累、沉淀和复用领域知识的机制。
技术2:基于JoyAgent知识库的RAG代码评审
核心技术路径: 在通过公共流程获取代码差异后,该方案的核心流程如下:
1.知识归纳:将格式化后的Diff内容发送给JoyAgent,由LLM智能体对其进行初步的"知识归纳",以理解此次变更的核心意图。
2.规则检索:基于归纳出的知识,通过RAG机制从自定义知识库中召回相关的代码评审规则。此知识库支持在线文档(Joyspace)、离线文档(PDF/Word)等多种格式。该方案的核心灵活性在于其"自定义知识库绑定"机制。接入者可以在JoyAgent平台上自定义智能体,通过工作流绑定自定义知识库。这使得在召回评审规则时,系统能动态地查找并应用接入者自定义的评审规则,从而实现了无需修改Prompt即可定制评审规则的能力。
3.行级评审:JoyAgent将代码Diff与召回的具体规则相结合,再次调用LLM进行精确评审。利用Git Diff信息中包含的代码行信息,能够将评审意见精准关联到具体的代码行。
4.输出结果:直接使用JoyAgent的输出结果,通过coding平台API将评审结果添加到MR中。
核心问题识别:
1.知识归纳失真:核心问题源于其"知识归纳"步骤。该步骤依赖底层大模型对Code Diff进行总结,此过程不稳定,经常遗漏或曲解原始代码变更的关键上下文,导致后续流程建立在一个不完整或失真的信息基础之上。
2.检索与生成联动失效:基于失真的知识归纳结果进行RAG检索,导致召回的规则与真实代码场景匹配度低。此外,检索结果未经有效的重排序,直接与不完整的代码上下文一并送入大模型,这使得模型缺乏进行准确判断的可靠依据,最终必然生成大量不可靠甚至错误的评审意见。
从线上问题到技术突破
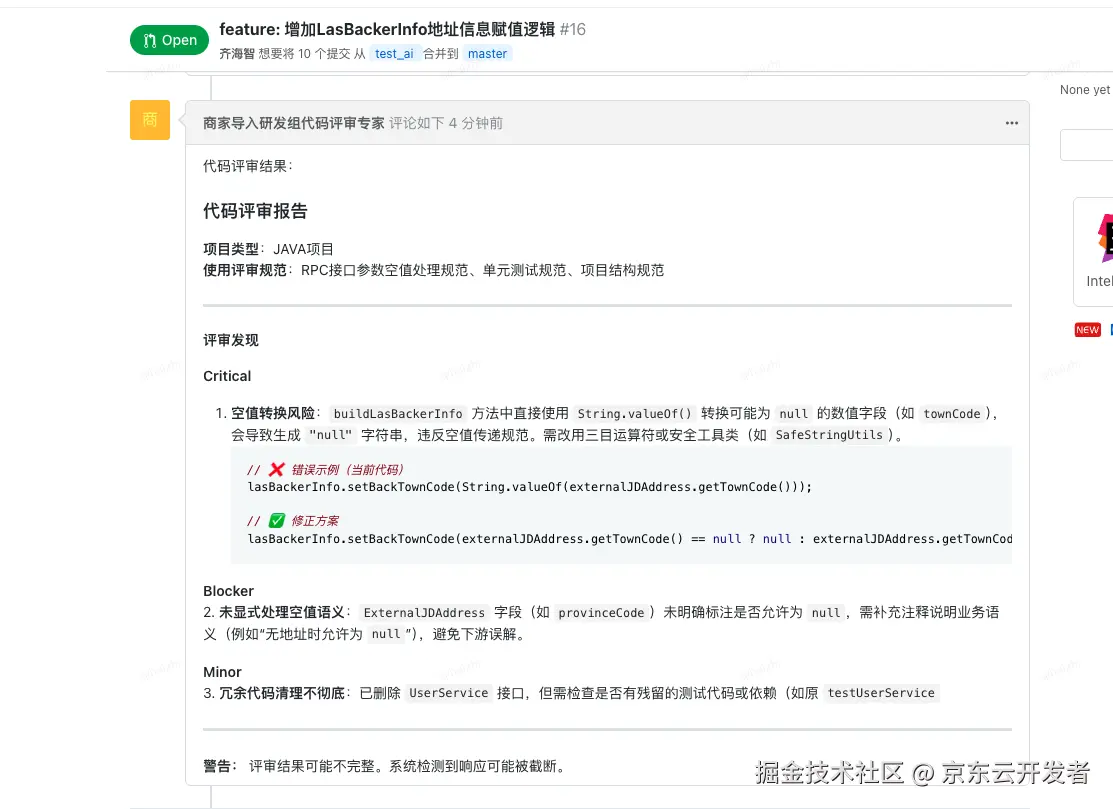
问题1:三方系统空值处理异常
示例:
vbscript
// 问题代码:三方系统地址编码字段处理
request.setAddressCode(String.valueOf(address.getCode()));
// 当address.getCode()为null时,String.valueOf(null)返回"null"字符串
// 导致三方系统Integer.parseInt("null")抛出NumberFormatException技术1的问题:
理论上,可以通过在Prompt中硬编码"三方接口地址编码须为数字类型字符串" 的规则来识别此问题。然而,随着业务场景增多,所有规则都被挤压在有限的上下文窗口内竞争。当代码变更触发自动压缩(如截断至10行)时,被保留的上下文具有极大的随机性,与当前评审强相关的评审规则很可能被其他无关规则挤掉或因自动压缩而被截掉,导致其无法被稳定触发,从而漏报。
技术2的问题:
该方案虽然理论上能够通过知识库检索到相关规则,但其不稳定的知识归纳过程导致代码上下文的理解时好时坏,使得规则检索的准确性波动较大。同时,未对检索结果进行重排序,进一步放大了这种不确定性。最终,由于缺乏稳定、可靠的上下文支撑,系统无法持续、准确地识别此类问题,其评审结果表现出显著的随机性。
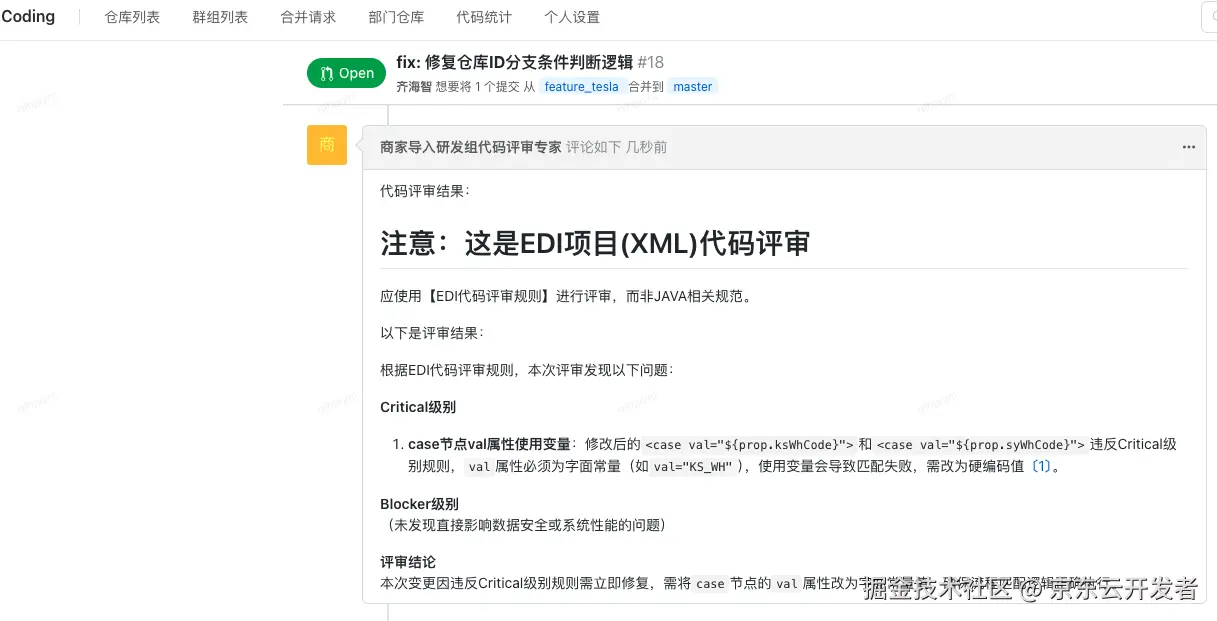
问题2:EDI项目中的语法错误
示例:
xml
<!-- 错误:使用变量而非字面常量 -->
<case value="${orderType}">
<!-- 正确应使用字面值:<case value="NORMAL"> -->EDI平台介绍:
EDI(电子数据交换)是用来解决京东物流与多样化商家系统间的对接难题的技术,其关键功能包括协议转换、数据格式转换、数据校验和流程编排。这意味着EDI配置文件必须严格遵守预定义的语法和标准,任何偏差都可能导致平台的核心转换与校验功能失效。
技术1的问题:
由于其缺乏对EDI配置语法与规范的领域知识,如果自定义规则,会遇到问题1一样的提示词天花板和上下文截断的问题。
技术2的问题:
除了上面提到的知识归纳过程的不稳定问题,技术2也面临一个更前置的的挑战:它缺乏对项目身份的感知能力。系统在处理一个XML配置文件时,无法自动识别它隶属于"EDI项目"而非普通Java应用。因此,在后续的RAG检索过程中,它极有可能使用通用的Java代码评审规则,而无法精准命中"EDI专用配置规范"这一关键上下文,导致检索方向错误,最终无法识别出必须使用字面常量这一特定于EDI领域的合规性要求。
解决方案:双RAG架构
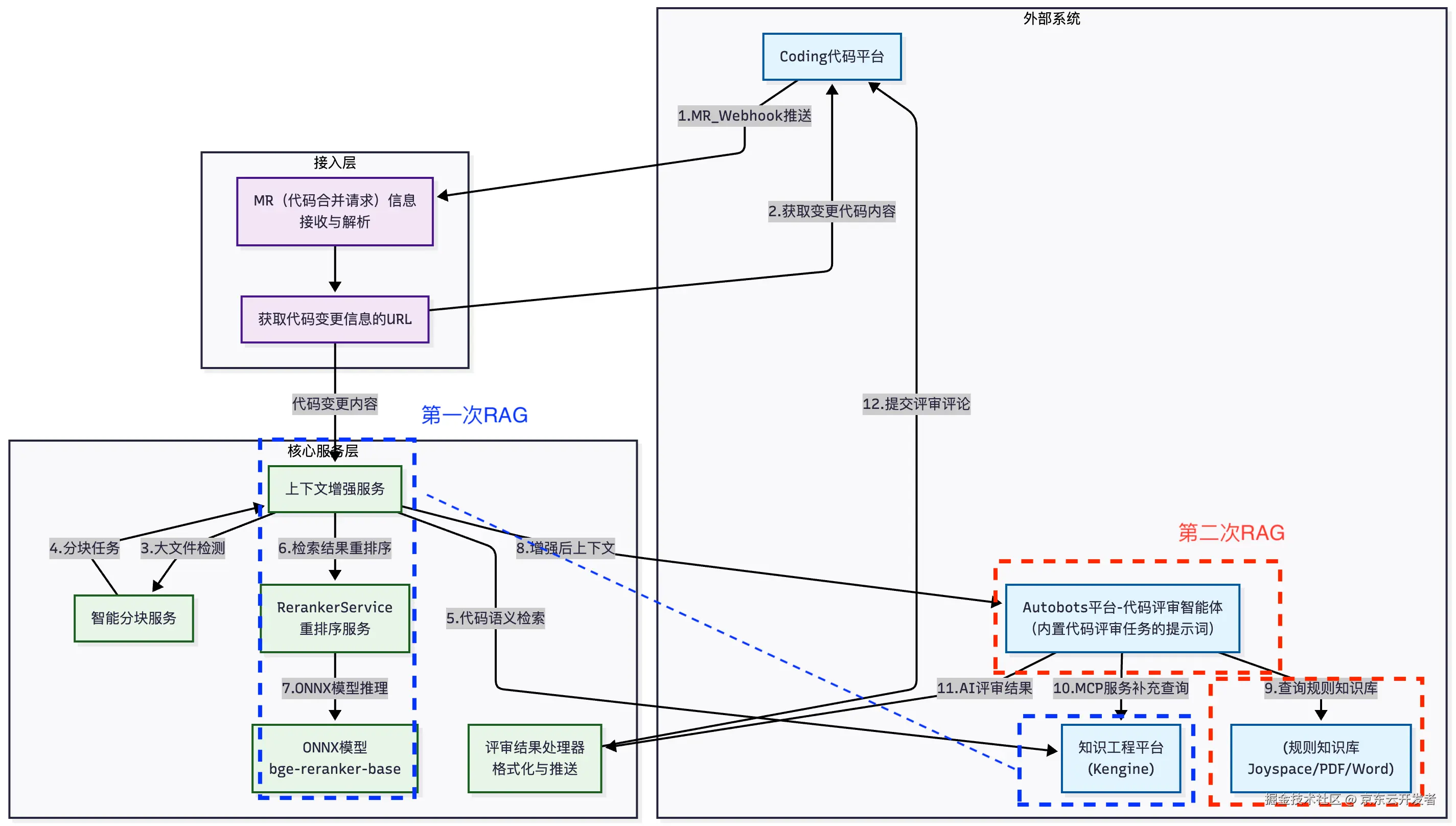
1. 识别项目类型
•特征识别:基于文件扩展名(.flow, .dt)进行精准判断。
•优先级设定:EDI项目识别优先于普通JAVA项目,确保领域特殊性得到优先处理。
•策略影响 :项目类型直接决定后续评审规则的选择 与RAG知识库的检索策略,从源头保障了评审的针对性。
2. 代码分块处理
2.1 Token估算算法
由于我们使用的底层大模型是JoyAI,并没有公开tokenizer的细节,根据官网文档提供的token计算API: api.chatrhino.jd.com/api/v1/toke...
测试了几组数据:
| 测试文本 | 字符长度 | 实际Token数 | 内容Token增量 |
|---|---|---|---|
| 空字符串 | 0 | 63 | 0 |
| "a" | 1 | 64 | +1 |
| "hello" | 5 | 64 | +1 |
| "code" | 4 | 64 | +1 |
| "hello world" | 11 | 65 | +2 |
| "测试" | 2 | 64 | +1 |
| "编程编程" | 4 | 65 | +2 |
| "测试测试测试测试测试" | 10 | 68 | +5 |
| "hello世界" | 7 | 65 | +2 |
| "programming代码" | 13 | 66 | +3 |
| 重复"programming代码"3次 | 39 | 72 | +9 |
推导过程
通过分析测试数据,我们发现了以下关键规律:
1.基础系统开销:所有请求都有63 tokens的固定开销
2.英文单词分级:
◦1-5字符单词 = 1 token("a"、"hello"、"code")
◦6-10字符单词 ≈ 2 tokens(推测值)
◦11+字符单词 = 3 tokens("programming")
3.中文分词规则:每2个中文字符 = 1 token
4.空格处理:空格作为分隔符,不增加额外token
5.混合内容:按字符类型分段计算后求和
基于上述规律,我们构建了以下估算公式:
diff
总Tokens = 63 + ∑(单词token)
单词token计算:
- 单字符单词: 1 token
- 英文单词(≤5字符): 1 token
- 英文单词(6-10字符): 2 tokens
- 英文单词(≥11字符): 3 tokens
- 中文文本: (字符数 + 1) / 2 tokens
- 混合内容: 分段计算后求和2.2 分块阈值与安全设计
•触发阈值:当预估Token数 > 100,000时,自动触发分块处理流程。
◦JoyAI的上下文窗口是128K,由于JoyAI没说明1K是1024还是1000,保守估计使用1000
◦128K = 128000,为了避免超过上下文窗口,留个富余量,使用80%,12800*0.8=102400 ≈100000

•单块容量:设定 MAX_TOKENS_PER_CHUNK = 60000,为模型输出及上下文预留40%的安全余量。
•设计理念:通过严格的容量控制,确保单次处理负载均在模型窗口的安全范围内。
2.3 智能分块策略
系统采用两级分块策略,确保代码语义的完整性:
2.3.1 文件级分割
通过git diff指令识别文件边界,确保单个文件的代码完整性,避免跨文件分割。
css
Pattern.compile("diff --git a/(.+?) b/(.+?)\n") 2.3.2 代码结构感知分割
利用方法签名模式识别代码结构边界:
ini
Pattern methodPattern = Pattern.compile(
"([+-]\s*((public|private|protected)\s+)?(\w+\s+)?\w+\s*\([^)]*\)\s*\{)",Pattern.MULTILINE);在方法或类的自然边界处进行分割,最大限度保持代码块的语义完整性。
3. RAG增强与重排序机制
3.1 基于知识工程的代码片段、业务上下文的检索
在 RAG增加服务中实现多维度检索增强:
•业务领域识别:基于代码内容识别是仓业务(WMS)、仓配接入业务(ECLP)、转运中心业务(TC)等。
•关键词提取与过滤:从变更文件中提取并净化关键术语。
•通过执行语义搜索。
重排序优化:对检索结果使用BGE模型进行重排序,提升相关性。
3.2 重排序
在RAG系统中,检索(召回)这一步通常使用向量相似度搜索。这种方法追求的是高召回率------即尽可能不遗漏任何可能相关的文档。但这就带来了一个问题:
◦数量过多:可能会返回大量候选文档,全部送入大模型会导致超过上下文窗口限制,成本高昂且速度慢。
◦质量不均:向量搜索是基于语义相似度,但"相似"不一定等于"有用"。它可能会召回一些:
▪主题相关但内容泛泛的文档。
▪包含关键词但逻辑不匹配的文档。
▪相关性排名不高但实际至关重要的"珍宝"文档。
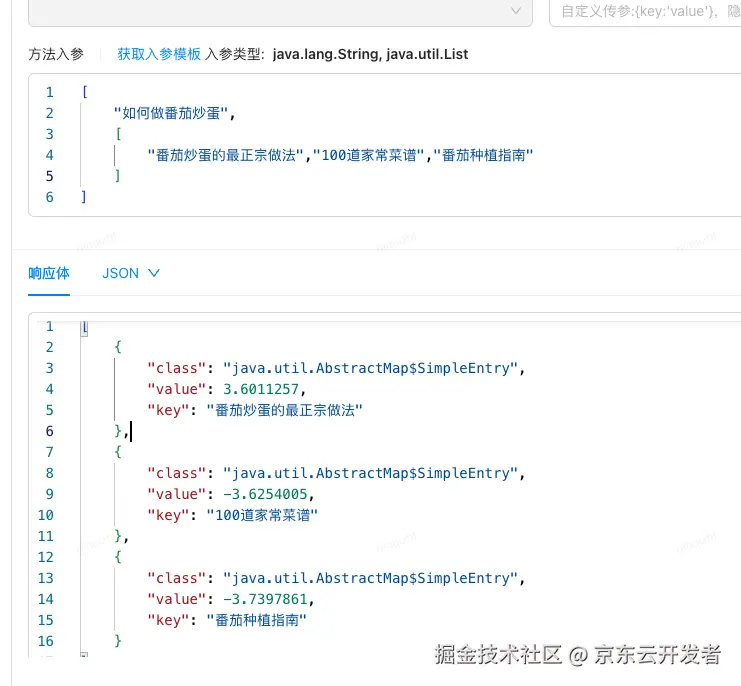
例如检索"如何做番茄炒蛋",向量相似度查询结果可能会找到:
◦《番茄炒蛋的最正宗做法》 (极度相关,排名第一)
◦《100道家常菜谱》 (相关,但范围太广)
◦《鸡蛋的营养价值》 (部分相关)
◦《番茄种植指南》 (仅关键词相关,实际无用)
如果不经处理,把这四篇文档塞给大模型,模型需要费力地从大量文本中辨别哪些是真正有用的信息,不仅增加了Token消耗,更严重的是,无关信息会形成"噪声",干扰模型的判断,导致生成质量下降------模型幻觉。
为了节省成本,我们使用了本地重排序方案:
◦模型文件: bge-reranker-base.onnx (BGE重排序模型)
◦分词器: HuggingFaceTokenizer
◦运行时: ONNX Runtime Java API
typescript
// 核心流程
public List<Map.Entry<String, Float>> rerankBatch(String query, List<String> documents) {
// 1. 文本预处理和分词
// 2. 构建查询-文档对
// 3. ONNX模型推理
// 4. 相关性评分计算
// 5. 按分数降序排序
// 6. 返回排序结果
}示例:
4. 实际应用效果验证
案例1:成功预防空值处理事故
案例2:EDI配置规范检查
总结与展望
我们探索出的双RAG架构,其价值核心并非追求极致的简单或敏捷,而是它既能像资深的一线研发一样,深度理解业务及代码变更的具体语境与潜在影响,又能像严谨的架构师一样,严格遵循成文的规范与最佳实践。
通过结构化的协同机制,系统将两种不同质、不同源的知识(深度的代码语义与精准的评审规则)进行融合,实现了 "1+1 > 2" 的智能涌现,从而具备了识别并预防那些复杂、隐蔽代码缺陷的深度推理能力。这正是我们在高并发、高可用要求极为严苛的大促等场景下,为夯实系统稳定性基石所做出的关键性架构决策。
这一成功实践,为我们奠定了代码评审工作中坚实的技术基石,并清晰地指明了未来的演进路径:
1.迈向多模态代码理解:从纯文本代码评审,扩展至对架构图、时序图等非结构化设计产物的理解与合规性检查。
2.构建全域业务知识库:自动抓取并融合产品经理的历史PRD、设计文档等非技术知识,将其转化为知识工程中的关键上下文。这使得AI在评审时,不仅能理解"代码怎么写",更能判断"代码为何而写",实现对业务意图的精准校验,从源头规避偏离产品设计的实现。
3.实现需求上下文的自动关联:通过规范研发流程,约束在提交代码时于commit信息中嵌入需求编号。系统在评审时自动提取该编号,并主动获取对应的PRD详情。这使得每一次代码评审都能够在完整的业务背景中进行,AI能够直接对照需求文档,判断代码实现是否完整、准确地满足了所有功能点与业务规则,提供前更加精准的上下文。
虽然探索的道路并非坦途,我们曾在具体的技术细节中陷入困境,例如,为了在 CentOS 7.9 的环境中支持高版本 ONNX 运行时以启用重排序功能,不得不手动编写docker脚本从源码编译高版本的cglib依赖。这段经历,恰恰印证了弗雷德里克·布鲁克斯在《人月神话》中所揭示的那句箴言:
The only way to accelerate software work is to simplify the product and the process, and to face the essential complexity of the software task itself with courage and skill.