从 685B 参数的稀疏架构到 IMO 金牌实力的 Speciale
一文看懂中国 AI 的"后训练"革命
2025年12月1日,DeepSeek 扔下了一枚重磅炸弹。继两个月前发布实验性的 DeepSeek-V3.2-Exp 之后,正式版DeepSeek-V3.2及其高算力变体DeepSeek-V3.2-Speciale今日全量上线。这不仅是一次版本号的迭代,更是一场关于 AI 推理范式的"起义"。本文将深度剖析 DeepSeek 如何通过稀疏注意力机制(DSA)打破长文本算力悖论,以及 Speciale 版本如何在数学与代码领域对齐甚至超越 GPT-5 与 Gemini 3.0 Pro。
绪论:通用人工智能的"后训练"时代
在过去的一年里,我们目睹了大模型领域最残酷的"军备竞赛"。当 OpenAI 发布 o1 系列,向世界展示了"系统 2"(System 2)思维链(Chain of Thought, CoT)的威力时,整个行业都在问:开源模型还有机会吗?
Scaling Laws(缩放定律)似乎遇到了边际效应递减的墙,单纯堆砌参数不再是万能药。OpenAI 和 Google 转向了Inference-Time Compute(推理时计算)------即让模型"多想一会儿",用时间换智能。
今天,DeepSeek 给出了中国开源社区的答案。
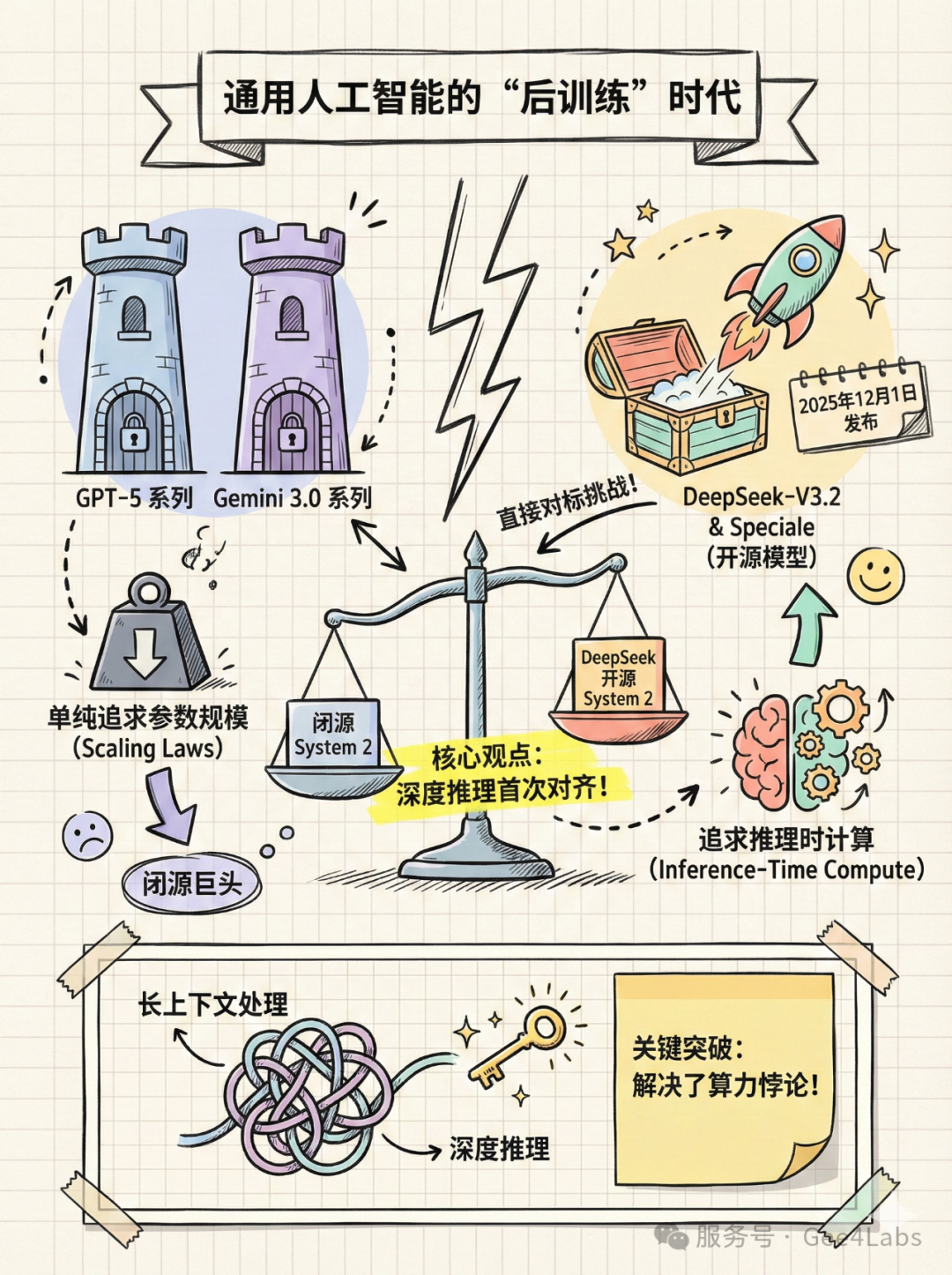
DeepSeek-V3.2 系列的发布,标志着开源模型正式进入了"后训练"(Post-Training)时代。它不再仅仅满足于做一个"读过万卷书"的知识库,而是进化为了一个"能解奥数题"的推理机。DeepSeek-V3.2(通用版)和 DeepSeek-V3.2-Speciale(高算力版)的组合拳,不仅在技术架构上实现了长上下文与深推理的平衡,更在商业格局上,首次让开源模型在逻辑推理这一传统短板上,站到了与西方闭源巨头平视的位置。
这不仅仅是 DeepSeek 的胜利,这是整个 Open-Weights 生态的里程碑。
技术架构深度解析:极致效率的暴力美学
DeepSeek 之所以能成为"价格屠夫"与"性能怪兽"的结合体,核心在于其底层架构的激进创新。不同于 Llama 系列坚持的稠密模型(Dense)路线,DeepSeek 在混合专家模型(MoE)的道路上越走越远,也越走越通。
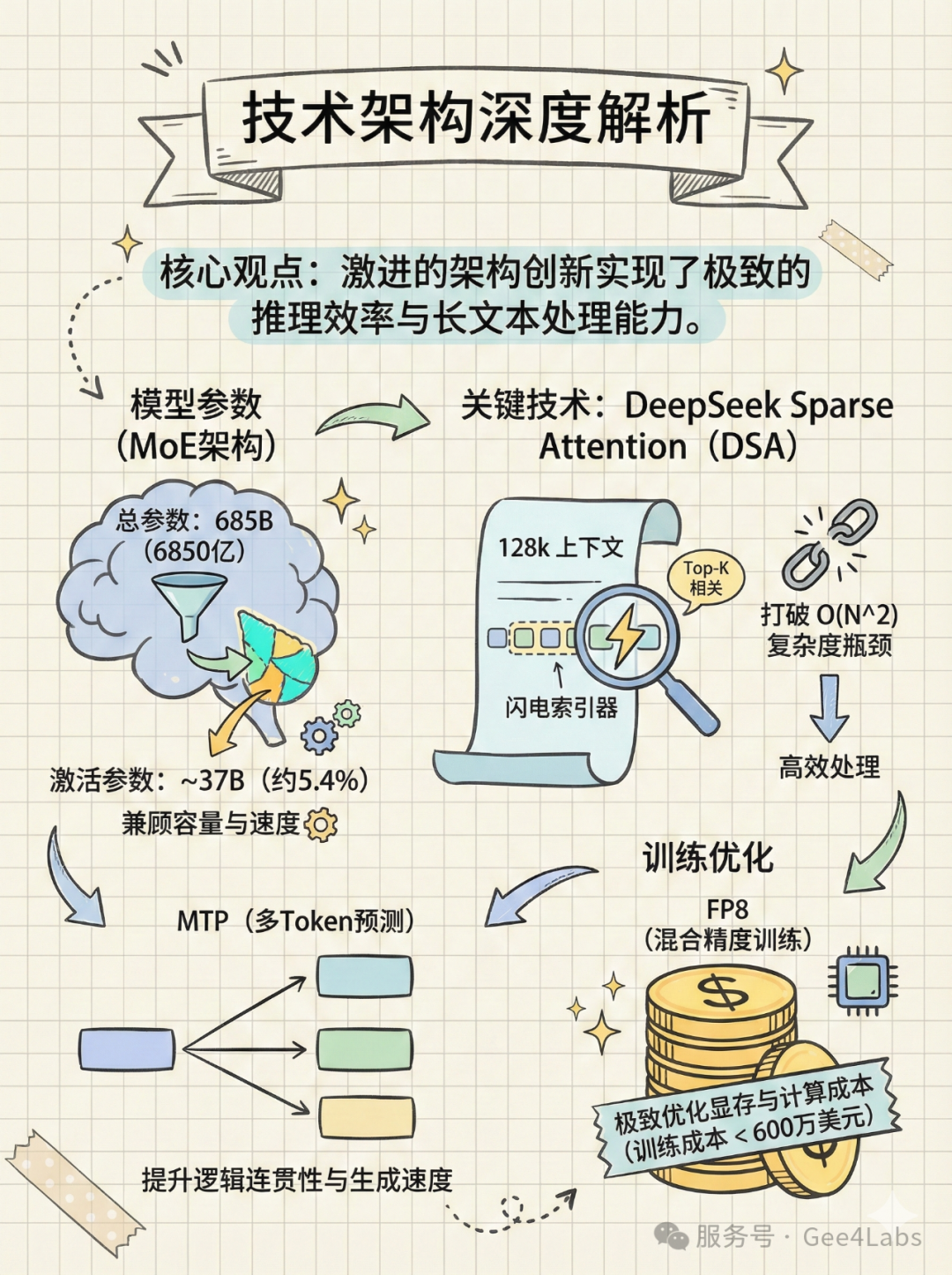
🔷 2.1 685B 参数的"大象"与 37B 的"舞者"
DeepSeek-V3.2 的参数量达到了惊人的6850 亿(685B)。在开源界,这是一个令人望而生畏的数字。通常,如此巨大的模型意味着高不可攀的推理成本和慢如蜗牛的生成速度。
但 DeepSeek 用 MoE 架构解决了这个问题。
📊 核心参数对比
•总参数量:685B(包含主模型与多 Token 预测模块)
•激活参数量:~37B
这意味着,当你向 DeepSeek-V3.2 提问时,尽管它背后有 6850 亿个参数在"待命",但真正参与计算的只有 370 亿个参数,约占总量的 5.4%。这种设计让它拥有了 GPT-4 级别的知识储备(由 685B 参数承载),却只需要消耗接近 Llama-3-70B 的推理算力。
此外,DeepSeek 在训练基础设施上展现了极高的工程造诣。采用了FP8(F8_E4M3)混合精度训练,完全压榨了 NVIDIA H800 集群的性能。据披露,其基础模型的训练仅消耗了不到 300 万 GPU 小时,成本控制在 600 万美元以内。这种极致的成本控制,是 DeepSeek 敢于通过低价策略冲击市场的底气。
🔷 2.2. 核心突破:DeepSeek Sparse Attention (DSA)
在 V3.2 版本中,最大的技术飞跃莫过于DeepSeek Sparse Attention (DSA)的引入。
在此之前,长文本(Long Context)是所有 Transformer 模型的噩梦。随着输入长度的增加,注意力机制的计算量呈二次方(O(N\^2))爆炸式增长。处理 100k tokens 的成本并不是处理 10k tokens 的 10 倍,而是 100 倍。
⚡ DSA 工作原理
•动态路由:在进行昂贵的注意力计算前,模型先快速扫描上下文,识别出与当前 Query 最相关的 Key-Value 对
•Top-K 计算:仅对筛选出的 Top-K 个 Token 进行高精度计算,忽略无关的噪音
•结果:将长文本处理的复杂度从二次方降低到了接近线性
这使得 DeepSeek-V3.2 能够轻松驾驭128k Token的上下文窗口。无论是分析几百页的财报,还是检索整个项目的代码库,V3.2 都能在保持速度的同时,不丢失关键细节。
🔷 2.3 多 Token 预测 (MTP) 的双重收益
DeepSeek-V3.2 延续了 V3 引入的Multi-Token Prediction (MTP)。简单来说,模型在训练时不仅预测下一个字,而是同时预测未来的一串字。
•训练端:迫使模型学习更长远的语言结构和逻辑规划能力
•推理端:支持"投机采样"(Speculative Decoding),模型可以一次性草拟出多个 Token,再进行验证。这直接提升了 Token 的生成速度(TPS),让用户在体感上觉得"更快了"
System 2 推理的新纪元:Speciale 的"深思"
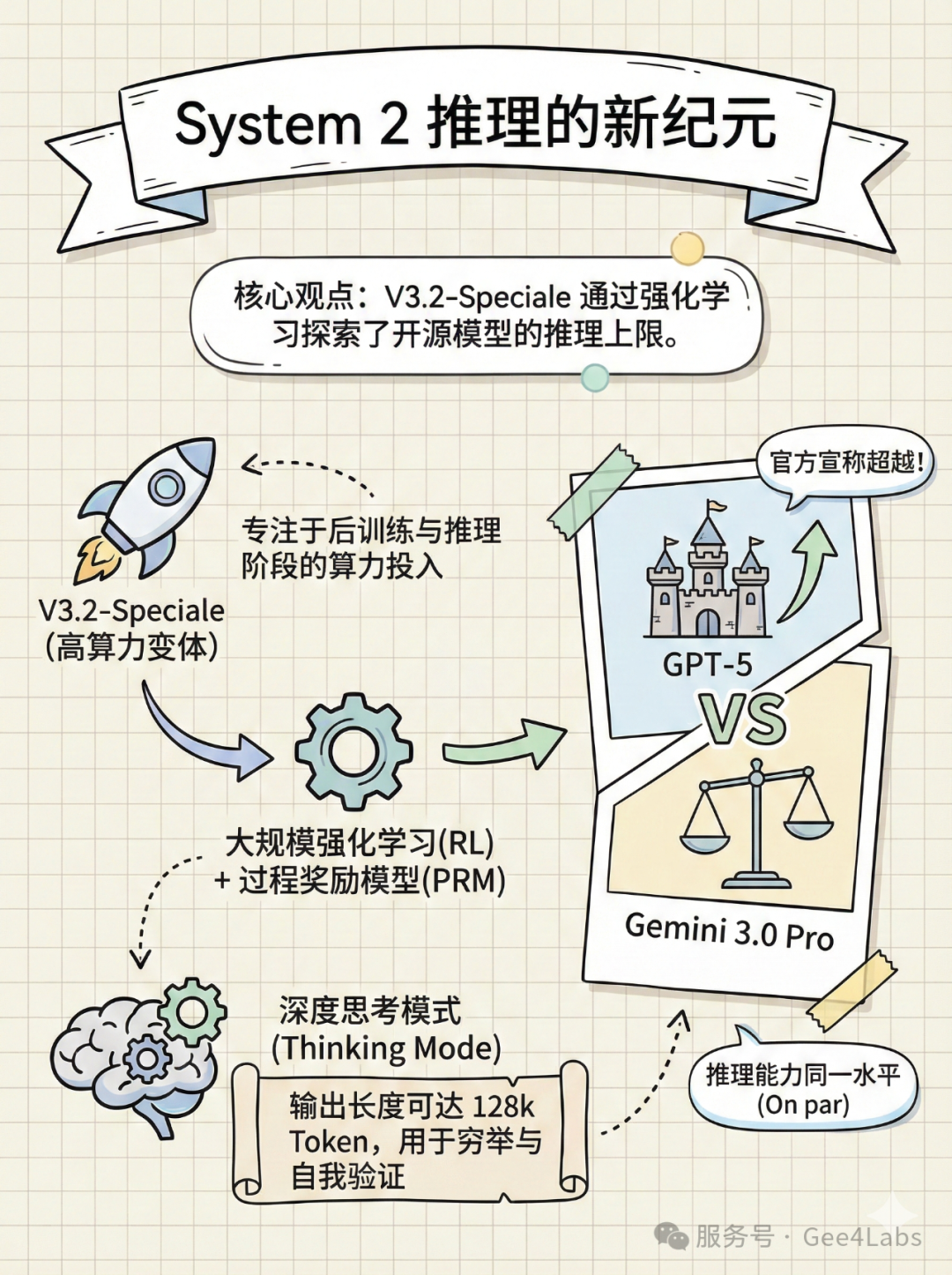
如果说 DeepSeek-V3.2 是全能选手,那么DeepSeek-V3.2-Speciale就是为了解决人类顶尖难题而生的特种兵。
🔷 3.1. 什么是 "Speciale"?
DeepSeek 官方将其定义为"高算力变体"(High-Compute Variant)。这里的"高算力"不是指模型更大了,而是指它在推理过程(Inference)中投入了更多的计算资源。
Speciale 是 DeepSeek 在后训练(Post-Training)阶段,通过大规模强化学习(RL)"炼"出来的。它不仅仅是模仿人类的文本,更是通过数以亿计的自我博弈和过程奖励模型(PRM),学会了如何"思考"。
🔷 3.2. 深度思考模式 (Thinking Mode)
DeepSeek-V3.2 系列引入了显式的<think>标签。
•DeepSeek-V3.2 (Chat):默认非思考模式,反应快,适合闲聊和简单任务
•DeepSeek-V3.2-Speciale:强制开启深度思考,输出长度上限达到了惊人的128k Token
请注意,这里的 128k 不是输入,是输出。这意味着面对一道复杂的奥数题或一个庞大的代码重构任务,Speciale 可以生成数万字的中间推理步骤。它会穷举各种可能性,自我反思,发现错误后回溯修正,直到找到最优解。这种"用时间换智能"的策略,正是 System 2 AI 的核心特征。
🔷 3.3 对标 GPT-5 与 Gemini 3.0
DeepSeek 在技术报告中极其自信地指出:
• Speciale 在推理基准上"Surpasses GPT-5"(此处指 GPT-5-High 版本)
• 与 Google DeepMind 的Gemini-3.0-Pro处于"On par"(同一水平)
这不仅是跑分上的对齐,更是在处理逻辑陷阱、多步推理等"智商题"上的实质性对齐。
智能体与工具使用:思维与行动的融合
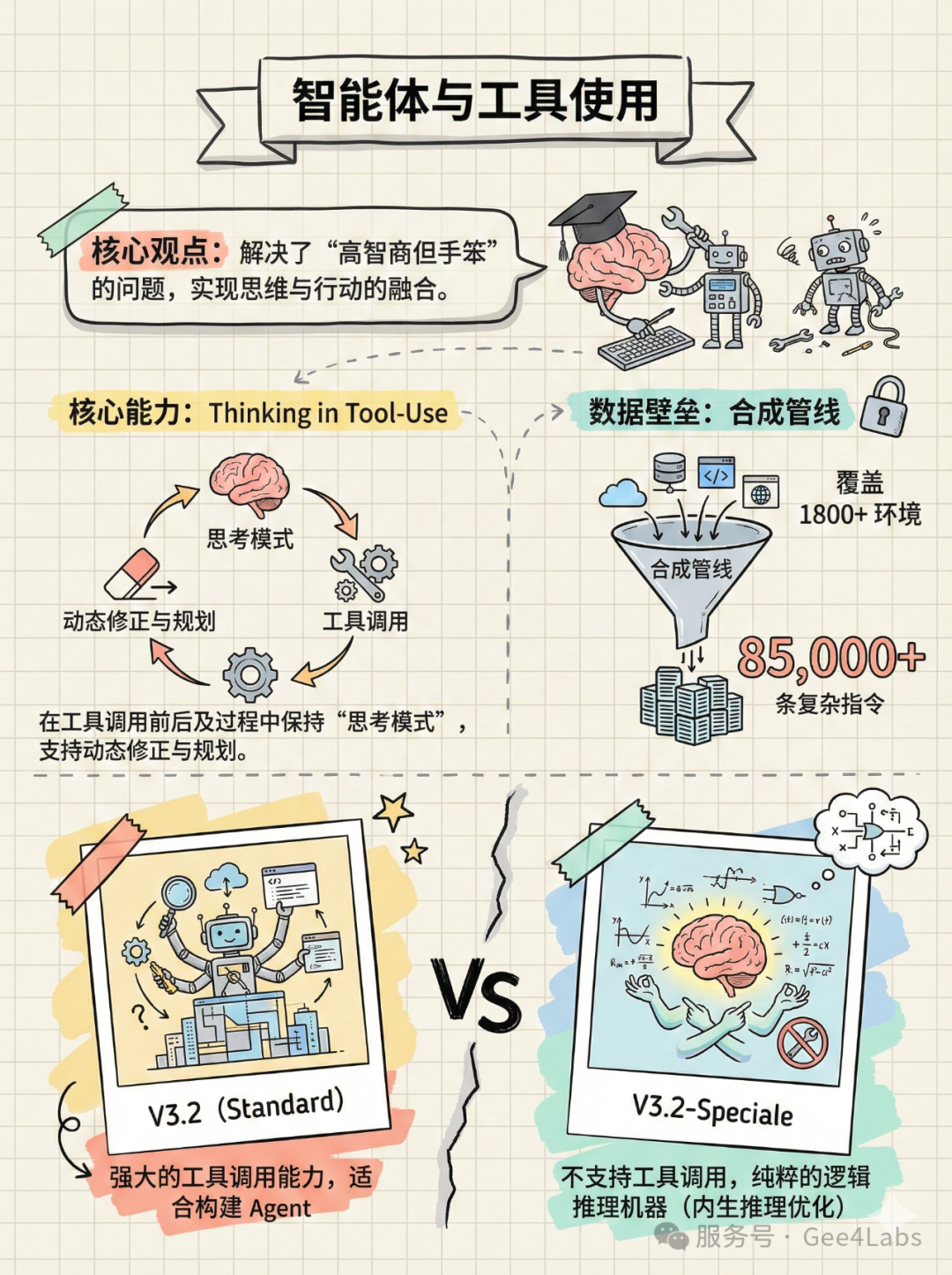
只有大脑没有手是不行的。DeepSeek-V3.2 在智能体(Agent)能力上做了巨大的补强。
🔷 4.1 Thinking in Tool-Use(在工具使用中思考)
这是 V3.2 最具创新性的特性之一。
传统的 Agent 往往是:思考 ->生成工具调用代码 ->执行 ->观察结果 ->再思考。这个过程是割裂的。DeepSeek-V3.2 支持在工具调用的过程中保持思考。
💡 动态修正示例
• 模型先思考:"我需要读取这个 CSV 文件,但我不确定编码格式,我应该先尝试 UTF-8。"
• 执行代码
• 观察报错
• 继续思考:"报错显示解码失败,这可能是 GBK 编码,我需要修改参数重试。"
• 再次执行
这种动态修正的能力,让 Agent 不再是死板的执行脚本,而是一个会根据环境反馈实时调整策略的"智慧体"。
🔷 4.2 1800+ 环境的合成数据管线
为了训练这种能力,DeepSeek 构建了一个庞大的"大规模智能体任务合成管线"。他们合成了超过 85,000 条复杂指令,覆盖了 1800 多个真实与虚拟环境(包括 Jupyter Notebook、各种 API 接口、Web 浏览环境等)。这使得 V3.2 在面对从未见过的工具时,也能凭借强大的泛化能力迅速上手。
🔷 4.3 Speciale 的"高冷"设定
值得注意的是,DeepSeek-V3.2-Speciale 目前不支持工具调用。
这是一种设计上的权衡。Speciale 被定位为一个纯粹的逻辑推理机器,像是一个被关在房间里的数学教授。引入外部工具可能会干扰其强化学习得来的精密思维链。如果你需要一个能联网搜索、能跑代码的助手,请使用标准版 V3.2;如果你需要解开黎曼猜想,请使用 Speciale。
性能基准评测:金牌级实力的验证

数据不会说谎。DeepSeek-V3.2-Speciale 的成绩单足够让竞争对手汗流浃背。
🏅 5.1 数学:IMO 2025 金牌
在数学领域,Speciale 展现了统治力。
📈 数学竞赛成绩
•AIME 2025(美国数学邀请赛):Pass@1 准确率达到93.1%(部分测试甚至高达 99.2%)。相比之下,GPT-5-High 为 90.8%,Gemini-3.0-Pro 为 90.2%
•IMO 2025(国际数学奥林匹克):官方宣布 Speciale 达到了金牌级表现。这意味着它不仅能做题,还能构造出严密的数学证明
💻 5.2 编程:Codeforces Grandmaster
在编程竞赛平台 Codeforces 上,Speciale 的模拟评级达到了2708分。
• 这相当于"红名"(Grandmaster)级别
• 作为对比,Gemini-3.0-Pro 的评分约为 2537
• 这意味着 DeepSeek 在算法设计、数据结构运用上,已经超越了绝大多数人类顶尖程序员
🔧 5.3 工程能力
在衡量解决真实软件工程 Bug 能力的SWE-Verified榜单上,Speciale 达到了73.1%的解决率。考虑到它是在不支持工具调用的情况下(仅生成补丁代码)达成的,这一成绩尤为恐怖,证明了其代码生成的准确性极高。
经济学分析:定价策略与智能的商品化
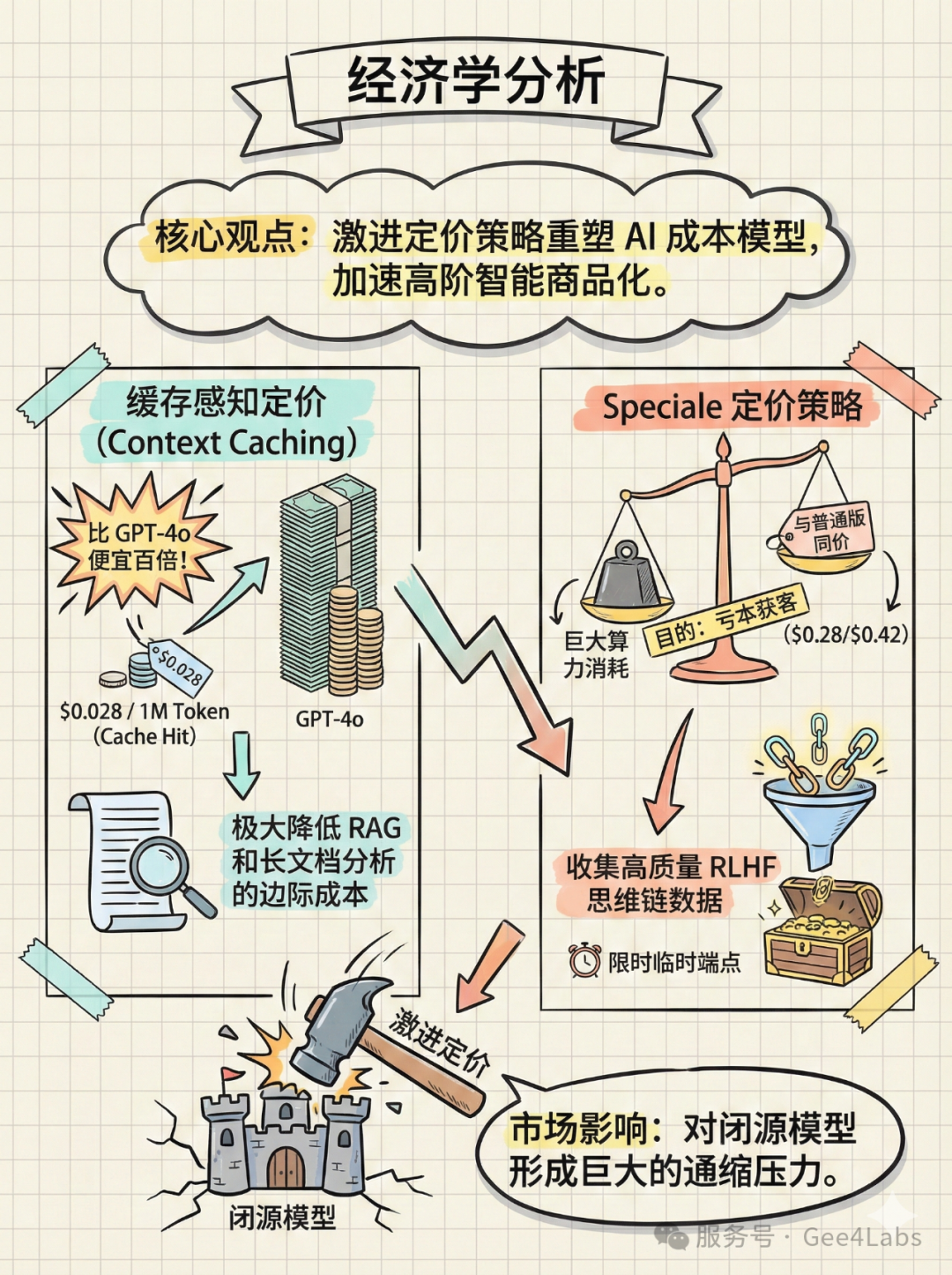
DeepSeek 最可怕的不是它的技术,而是它想把 AI 变成"白菜价"的决心。
💰 6.1 缓存感知定价 (Cache-Aware Pricing)
DeepSeek-V3.2 引入了Context Caching机制,并给出了极具攻击性的定价:
💵 定价明细
•Cache Hit(缓存命中):$0.028 / 1M Token(约 ¥0.20 / 百万词)
•Cache Miss(未命中):$0.28 / 1M Token
•Output(输出):$0.42 / 1M Token
这是什么概念?如果你的企业有一个巨大的知识库需要频繁查询(RAG 场景),只要这部分背景知识被缓存,每次查询的输入成本仅为 GPT-4o 的百分之一甚至千分之一。这直接将大规模 RAG 应用的边际成本打到了忽略不计的程度。
💰 6.2 Speciale 的"亏本赚吆喝"?
最令人震惊的是,高算力版 Speciale 的定价与普通版 V3.2 完全一致。
考虑到 Speciale 在推理时需要进行大量的 CoT 计算,消耗的 GPU 资源远超普通版,这显然是亏本的。DeepSeek 设置了一个"临时端点"(2025年12月15日过期),这实际上是一场"限时公测"。DeepSeek 意在通过极其低廉的价格,吸引全球开发者来测试其推理极限,从而收集极其宝贵的、高质量的复杂任务 Prompt 和人类反馈数据。这些数据将成为训练下一代模型(V4)的核心燃料。
部署与生态:开源精神的坚守
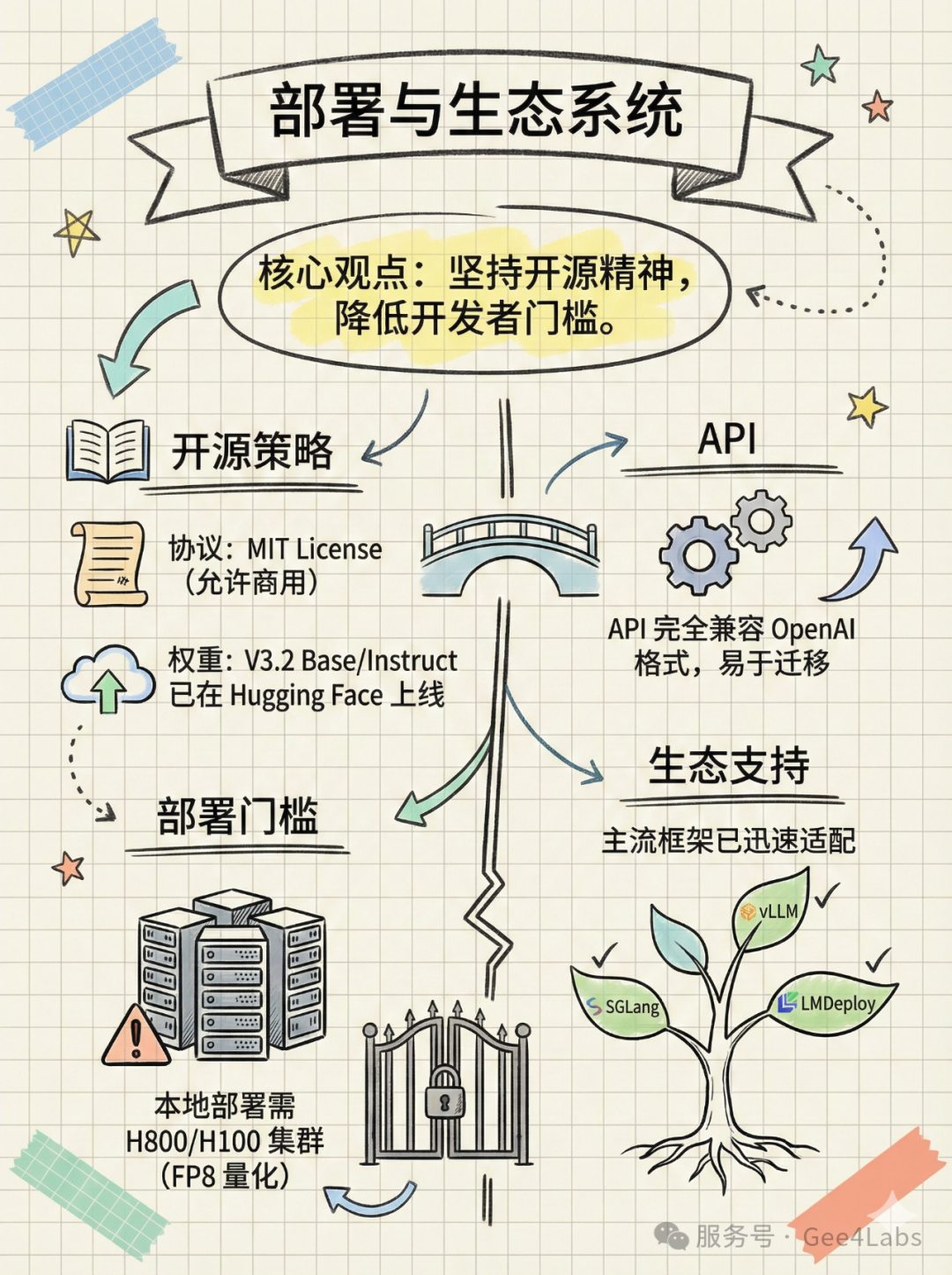
在闭源模型大行其道的今天,DeepSeek 依然坚持开源。
📦 开源信息
•协议:MIT License。这意味着你可以免费商用,甚至可以基于它修改、微调,而无需担心法律风险
•权重下载:DeepSeek-V3.2 Base 和 Instruct 权重已在 Hugging Face 上线
•部署门槛:虽然是开源,但 685B 的参数量决定了它不是普通显卡能跑得动的。本地部署建议至少拥有 8 卡 H100 或 H800 集群,并配合 vLLM 或 SGLang 等推理框架进行 FP8 量化部署。对于大多数中小开发者,使用 API 依然是最佳选择
结论与展望:AI 的新游戏规则
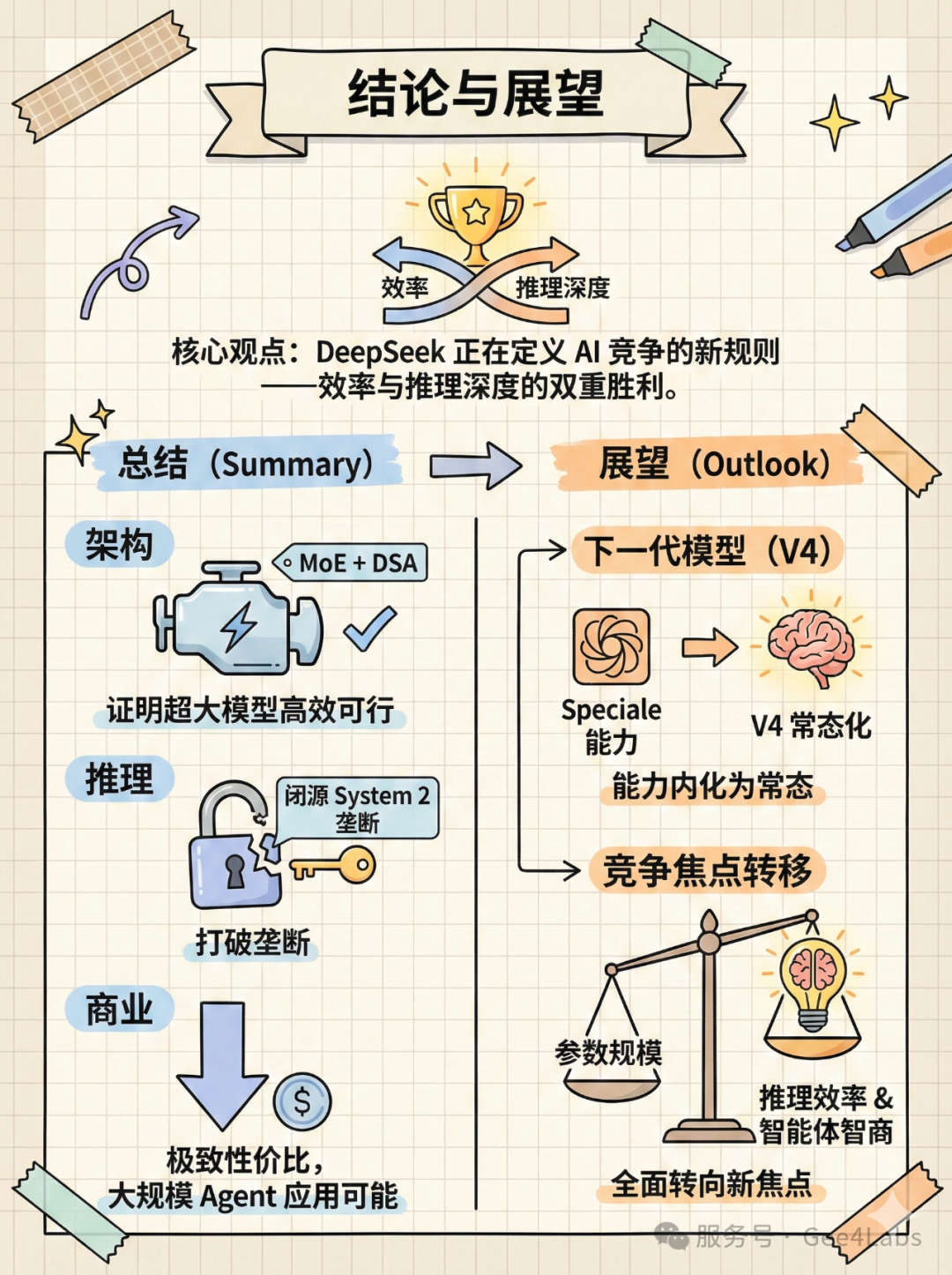
DeepSeek-V3.2 和 V3.2-Speciale 的发布,是中国 AI 产业在 2025 年末交出的一份满分答卷。
它证明了三件事:
①架构创新(MoE + DSA)可以让超大模型在效率上跑赢 Scaling Laws
②开源模型通过强化学习,完全可以在逻辑推理这一 System 2 领域追平甚至反超闭源 SOTA
③极致性价比正在重塑 AI 应用的成本模型,让"万物智能"不再是一句空话
Speciale 现在的"深度思考"能力,未来注定会内化为标准模型的本能。当 GPT-5 还在云端高不可攀时,DeepSeek 已经把同等水平的智能,以几毛钱的价格通过 API 发送到了全世界开发者的手中。
这不仅是技术的胜利,更是开放精神的胜利。