一、前言
2026 年,大模型的竞争焦点早已从"参数量"转向了"任务达成能力"。简单的 RAG 问答已无法满足企业需求,我们需要的是能思考、能闭环、能调 API 的 Agentic AI。
作为 AWS 生态中处理复杂任务的"中枢神经",Amazon Bedrock AgentCore 配合 Strands SDK,正在定义企业级代理架构的新标准。
二、核心架构:Strands 与 AgentCore 的"内外部循环"
在开发阶段,很多开发者容易混淆两者的关系。作为解决方案工程师,我们的视角是:Strands 是编排逻辑的"笔",而 AgentCore 是运行逻辑的"舞台"****。
核心逻辑:从"模型驱动"到"架构驱动"
传统的 Agent 依赖单一 Prompt,而 Strands + AgentCore 采用的是**"解耦架构"**:
- 开发态(Strands):你用 Python 代码定义 Agent 的节点、转接逻辑(Handoff)和工具包。
- 运行态(AgentCore):代码被推送到云端,AgentCore 接管繁琐的底层工作(如 API 认证、多轮对话的 Token 管理、分布式状态同步)。
三、Strands 的"多代理协作"编排艺术
Strands 是 AWS 推出的模型驱动开发框架。相比于死板的 DAG(有向无环图)流向,Strands 强调**"意图驱动的转接 (Handoff)"**。
示例:多 Agent 协作代码示例 (基于 Strands 风格)
以下代码展示了如何利用 Strands 的 Handoff 机制实现数据采集员(DataScout)与市场分析师(MarketAnalyst)的协同工作 :
python
from strands import Agent, Tool, Toolbelt, Handoff
from strands.runtime.bedrock_agentcore import AgentCoreExecutor
# --- 第一步:定义工具 (Action Groups in AgentCore) ---
def get_sales_data(region: str):
"""从数据库查询特定区域的销售额数据"""
# 实际落地时,这里会调用关联的 Lambda 函数
return {"region": region, "revenue": 500000, "top_product": "Cloud-Native Suite"}
sales_tool = Tool(fn=get_sales_data)
# --- 第二步:定义 Agent A (数据采集员) ---
data_scout = Agent(
name="DataScout",
instructions="你是一个专业的数据查询员。你的任务是根据用户提到的区域准确查询销售数据。",
toolbelt=Toolbelt(tools=[sales_tool])
)
# --- 第三步:定义 Agent B (市场分析师) ---
market_analyst = Agent(
name="MarketAnalyst",
instructions="你是一个资深的商业分析师。根据提供的数据,分析趋势并给出不少于3条的增长建议。"
)
# --- 第四步:定义转接逻辑 (Orchestration) ---
# 当 DataScout 完成数据采集后,自动转交给 MarketAnalyst
data_scout.add_handoff(
Handoff(target=market_analyst, condition="当数据查询完毕并准备好进行分析时")
)
# --- 第五步:在 AgentCore 运行时中执行 ---
# AgentCoreExecutor 负责处理底层的会话持久化和推理循环
executor = AgentCoreExecutor(starting_agent=data_scout)
response = executor.invoke("帮我查一下华东区的销售情况,并告诉我明年该怎么做。")
print(response.output_text)价值点:模型会根据上下文自动判断:"现在该我查数了"还是"我该把球传给分析师了"
四、 工程化实践:助力项目快速落地的"三板斧"
1. 复杂工具栈的"即插即用"与准入规范
在企业内部,工具可能是一个 SQL 数据库或 ERP 接口 。
- Strands 的灵活性 :支持 MCP (Model Context Protocol) 协议,将现有服务快速封装为 Agent 的"工具带" 。
- Action Group 落地清单:(checklist见文末)
- 描述先行 (Description-First):API 的 description 必须使用业务化语言,因为模型是根据描述而非函数名决定调用时机的 。
- 身份代理 (Identity Proxy) :通过 Action Group Gateway 利用 IAM 角色实现鉴权,严禁在代码中硬编码密钥 。
2. 调试的"透明化"与逻辑纠偏 (The Trace Power)
Agent 逻辑跑通容易,调优难 。
- 深度观测 :利用 AgentCore 提供的 Trace Events 观察推理的每一个切片 。
- 实战经验 :如果 Agent 陷入死循环,通过 Trace 可以精准判定是 Prompt 指令冲突 (大脑问题)还是 Lambda 返回格式不规范(手脚问题) 。
3. 动态护栏:给 AI 穿上红线
项目落地最怕"合规风险",尤其是敏感财务数据的泄露 。
- 场景与方案 :分析师 Agent 可以输出行业趋势,但严禁泄露原始数据 。在 AgentCore 中配置 Guardrails,即使 Strands 逻辑未定义,护栏也会在输出层强制拦截,确保逻辑开发与安全策略解耦 。
五、深度解析:Oktank Insurance 案例背后的"工程哲学"
从 AWS 最新的 Claim Genie 演示站 中,我们可以梳理出企业级 Agent 构建的四个阶段:
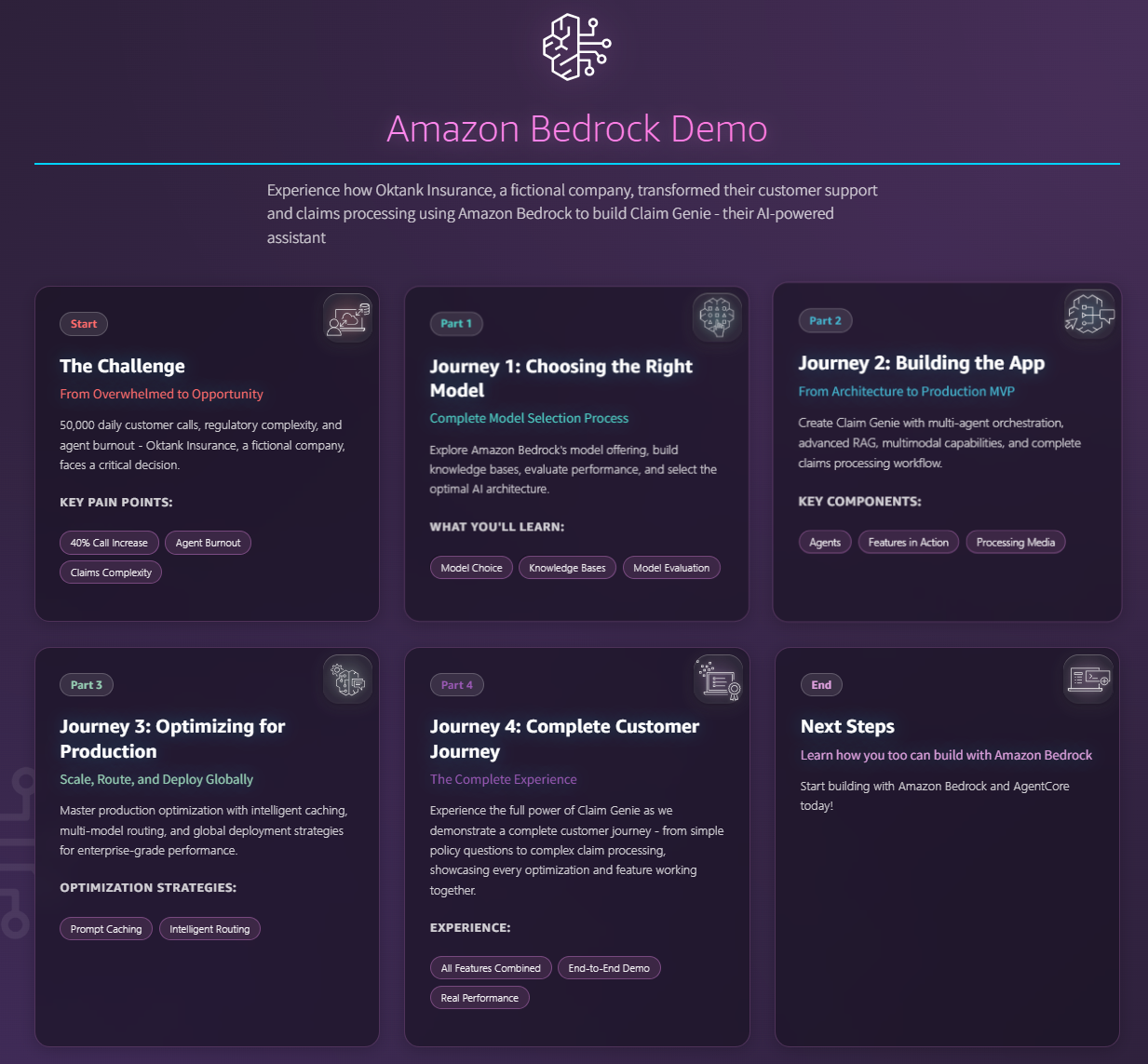
| 阶段 | 关键任务 | 工程师视角建议 |
|---|---|---|
| P1: 基础建设 | 模型评估与 RAG 初始化 | 优先选择长上下文模型,利用 Prompt Caching 降低成本。 |
| P2: 逻辑编排 | 多 Agent 协作与 Action Group 开发 | 保持工具职责单一化,API 描述 (Description) 比代码逻辑更重要。 |
| P3: 性能优化 | 引入智能路由 (Intelligent Routing) | 简单问题路由至低成本模型,复杂推理调用 Sonnet。 |
| P4: 生产加固 | 配置 Guardrails 与持续监控 | 利用 Trace Events 解析模型思考过程,定位逻辑卡点。 |
六、总结
Amazon Bedrock AgentCore 提供了强大的云原生基座,而 Strands Agent 赋予了它灵活的灵魂。两者的结合,标志着 Agent 开发从"玄学调优"进入了"工程化构建"的新时代。
附加:
Action Group 设计与 Lambda 对接实战检查清单(Checklist):
- OpenAPI Schema 设计(Agent 的"说明书")
*描述的准确性(Description-First):API 和每个参数的 description 是否使用了业务化语言?在 AgentCore 中,模型是根据描述而非函数名来决定调用哪个工具的 。
*参数类型严格定义:所有参数是否明确了类型(string, integer, boolean)?复杂的嵌套对象建议简化,以提高模型的解析成功率。
*必填项标注:是否通过 required 字段明确告知 Agent 哪些参数是必须提供的,避免因缺少关键信息导致 API 调用失败。
- Lambda 函数逻辑(Agent 的"执行器")
*输入格式校验:Lambda 是否能正确解析 AgentCore 传来的 inputText 以及从 OpenAPI 定义中提取的参数 ?
*响应结构规范:Lambda 返回的 JSON 必须严格符合 OpenAPI 的定义 。如果返回了非预期的格式,AgentCore 将无法解析并报错 。
*超时管理:Lambda 执行时间是否控制在 Agent 的等待阈值内?复杂的后端查询建议增加重试逻辑或进度反馈。
*异常捕获:当后端系统报错时,Lambda 是否返回了"业务友好"的错误描述?清晰的错误信息可以帮助模型决定是否重试或向用户解释。
- 安全与身份管理(Identity & Security)
*IAM 最小权限原则:Lambda 关联的角色是否仅具备访问特定资源(如 DynamoDB、S3)的权限?
*身份代理(Identity Proxy):是否利用了 AgentCore 的 Action Group Gateway 通过 IAM 角色处理权限,而不是在 Prompt 或代码中硬编码 Key ?
*跨账号调用:如果 Lambda 在另一个 AWS 账号中,是否配置了正确的 Resource-based Policy 允许 Bedrock 跨账号触发。
- 协作与状态(Handoff & Session)
*多 Agent 转接适配:在多代理场景下,当前 Action Group 的返回结果是否包含后续 Agent 节点(如市场分析师)所需的上下文数据 ?
*状态连续性检查:通过 Session State 传递的数据是否在 Lambda 中得到了正确处理,以确保长流程业务的体验 。
- 调试与观测(Trace & Debug)
*开启 Trace Events:在开发阶段,是否启用了 enableTrace=True 以观察模型在调用 Action Group 时的思考切片 ?
*日志关联:Lambda 的日志是否记录了 requestId,以便在 CloudWatch 中将其与 AgentCore 的调用轨迹关联起来,精准定位逻辑卡点 。