TL;DR
- 场景:用 NumPy/Pandas 手写 K-Means,对 Iris.txt 做 3 类聚类并输出质心与分簇结果
- 结论:实现可跑通,但需补齐"空簇处理 / 最大迭代 / 版本与数据类型约束 / 特征尺度"才能工程化稳定
- 产出:distEclud + randCent + kMeans 完整链路、结果表 result_set、常见错误定位与修复速查
Python实现
导入依赖
python
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = "all"
# 解决坐标轴刻度负号乱码
plt.rcParams['axes.unicode_minus'] = False
# 解决中文乱码问题
plt.rcParams['font.sans-serif'] = ['Simhei']导入数据集
此处使用鸢尾花数据集为例:
python
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
%matplotlib inline
#导入数据集
iris = pd.read_csv("iris.txt",header = None)
iris.head()
iris.shape执行结果如下图所示: 
编写距离计算函数
我们需要定义一个两个长度相等的数组之间欧式距离计算函数,在不直接应用计算结果,只比较距离远近的情况下,我们可以用距离平方和代替距离进行比较,化简开平方运算,从而减少函数计算量。此外需要说明的是,涉及到距离计算的,一定要注意量纲的统一。 如果量纲不统一的话,模型极易偏向量纲大的那一方。
- 函数功能:计算两个数据集之间的欧式距离
- 输入:两个 array 数据集
- 返回:两个数据集之间的欧式距离(此处用距离平方和代替距离)
python
def distEclud(arrA, arrB):
d = arrA - arrB
dist = np.sum(np.power(d, 2), axis=1)
return dist编写随机函数生成质心函数
在定义随机质心生成函数时,需要按照以下步骤进行操作:
-
数据范围计算:
- 首先遍历数据集中的每一列(特征),计算该列的最小值(min)和最大值(max)
- 对于数值型特征,直接计算其数值范围
- 对于类别型特征,需要先进行编码转换(如one-hot编码)后再计算范围
- 示例:假设某列数值范围为5.1, 7.9,则该列的随机值应在此区间内生成
-
随机质心生成:
- 根据用户指定的簇个数k,生成k个质心
- 对每个质心的每个特征维度,在其对应列的取值范围内随机取值
- 使用均匀分布或高斯分布等概率分布进行随机采样
- 注意保持各特征维度的独立性
-
参数说明:
- 输入参数:
- dataSet:包含标签的完整数据集,应为n×m矩阵(n个样本,m个特征)
- k:需要生成的质心数量,应为正整数
- 输出参数:
- data_cent:生成的k个质心,维度为k×m矩阵
- 输入参数:
-
实现细节:
- 需要考虑数据标准化问题,建议先对数据进行归一化处理
- 应设置随机种子以保证实验可重复性
- 可添加参数校验逻辑,如检查k值是否大于0且小于样本数
-
应用场景:
- 常用于K-means等聚类算法的初始化阶段
- 适用于数值型数据集
- 在图像分割、客户分群等场景中都有应用
-
扩展功能:
- 可添加异常处理机制
- 支持多种随机分布选择
- 可集成到机器学习pipeline中
python
def randCent(dataSet, k):
# n为列数,假设dataSet是一个DataFrame
n = dataSet.shape[1] # 获取数据集的列数(例如 iris 数据集有 5 列)
# 获取每一列的最小值和最大值(仅使用前 n-1 列,最后一列是标签或类别)
data_min = dataSet.iloc[:, :n-1].min() # 前4列的最小值
data_max = dataSet.iloc[:, :n-1].max() # 前4列的最大值
# 在最小值和最大值之间生成 k 个随机中心点,形状为 (k, n-1)
data_cent = np.random.uniform(data_min, data_max, (k, n-1))
return data_cent经过上述定义,在 iris 中随机生成了三个质心: 执行对应的代码:
python
iris_cent = randCent(iris, 3)
iris_cent执行结果如下图所示: 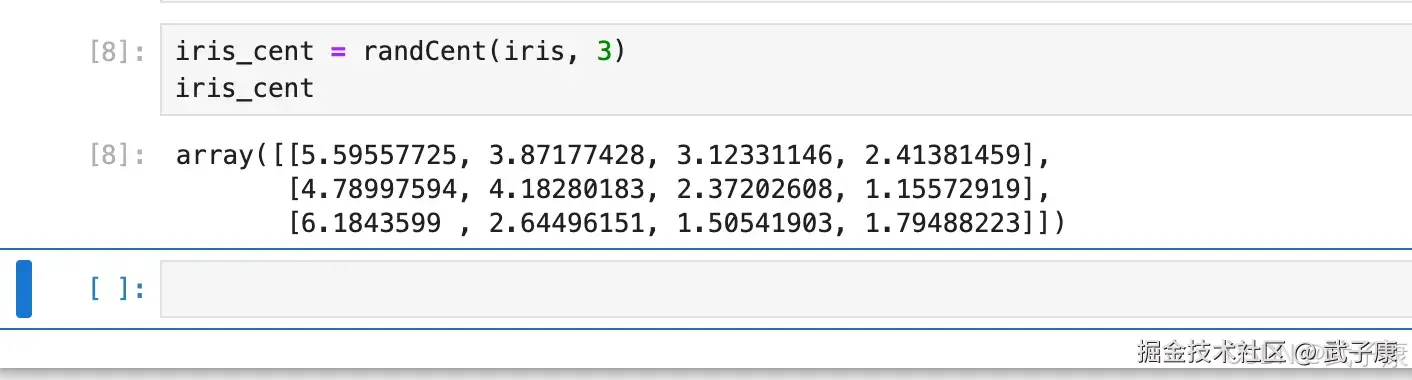
编写 K-Means 聚类函数
在执行 K-Means 聚类算法时,迭代更新质心是关键步骤,这需要两个设计良好的数据结构来高效完成整个过程:
- 质心存储容器(centroids):
- 推荐使用 Python 的 list 结构实现,因为:
- list 是可迭代对象,便于循环遍历所有质心
- 通过 list 索引可以自然地为每个质心分配唯一标识(如索引0对应簇0)
- 支持动态更新,每次迭代后可以直接替换对应位置的质心坐标
- 示例:centroids = \[1.2, 3.4, 5.6, 7.8] 表示两个二维质心
- 距离记录容器:
- 建议使用三列的二维数组结构(如 numpy 数组),每行包含:
- 第一列:数据点到最近质心的距离
- 第二列:该点所属簇的编号(对应centroids的索引)
- 第三列:标记该点是否改变了所属簇(布尔值)
- 优势在于:
- 可以向量化计算,提高性能
- 方便进行距离比较和簇分配
- 示例结构: \[0.5, 0, True, 1.2, 1, False, 0.8, 0, True]
在实际应用中,这两个容器会协同工作:
- 初始化阶段随机选择K个点作为初始质心存入centroids
- 每次迭代时: a) 计算所有点到当前质心的距离,更新距离容器 b) 根据最小距离重新分配簇归属 c) 计算新簇的均值,更新centroids中的质心位置
- 直到距离容器中的簇归属不再变化(收敛)或达到最大迭代次数
这种设计既保证了算法逻辑的清晰性,又能充分利用Python数据结构的特性来提高计算效率。
第二个容器中:
- 第一列用于存放最近一次计算完成后某点到各质心的最短距离
- 第二列用于记录最近一次计算完成后根据最短距离得到的代表对应质心的数值索引,即所述簇,即质心编号。
- 第三列用于存放上一次某点对应质心编号(某点所属簇),后两列用于比较质心发生变化后某点所属簇的情况是否发生变化。
函数功能:K-均值聚类算法 参数说明:
- dataSet 带标签数据集
- k 簇的个数
- distMeas 距离计算函数
- createCent 随机质心生成函数
返回:
- centroids 质心
- result_set 所有数据划分结果
python
# 假设 distEclud 和 randCent 是你定义的距离测量函数和随机生成质心函数
def kMeans(dataSet, k, distMeas=distEclud, createCent=randCent):
# 获取数据集的维度,m 是行数,n 是列数
m, n = dataSet.shape # m是行数(数据量),n是列数(例如 iris 为 150*5)
# 初始化质心 centroids,生成 k 个随机质心
centroids = createCent(dataSet, k) # centroids 为 k*n 的矩阵(随机生成)
# 初始化 clusterAssment 矩阵,用来存储每个点的簇分配结果
# clusterAssment: [该行到最近质心的距离, 本次迭代中最近质心编号, 上次迭代中最近质心编号]
clusterAssment = np.zeros((m, 3)) # 初始化为 m*3 的矩阵
clusterAssment[:, 0] = np.inf # 设置初始距离为无穷大
clusterAssment[:, 1:3] = -1 # 质心编号初始化为 -1
# 将数据集和 clusterAssment 合并,形成 result_set
result_set = pd.concat([dataSet, pd.DataFrame(clusterAssment)], axis=1, ignore_index=True)
# 标记簇是否发生变化
clusterChanged = True
while clusterChanged:
clusterChanged = False
# 遍历每个样本点,计算它与每个质心的距离,并更新簇分配信息
for i in range(m):
# 计算当前数据点到所有质心的距离
dist = distMeas(dataSet.iloc[i, :n-1].values, centroids) # 计算距离,dist 是 k*1 的矩阵
# 记录最小距离和对应质心的索引
result_set.iloc[i, n] = dist.min() # 记录最小距离
result_set.iloc[i, n+1] = np.where(dist == dist.min())[0][0] # 记录最近质心的索引
# 检查当前簇分配与上次是否完全一致
clusterChanged = not (result_set.iloc[:, -1] == result_set.iloc[:, -2]).all()
# 如果簇分配发生变化,则更新质心和 result_set
if clusterChanged:
# 根据新的簇分配,计算新的质心位置
cent_df = result_set.groupby(n+1).mean() # 根据最新簇分配,分组计算新的质心
centroids = cent_df.iloc[:, :n-1].values # 更新质心,使用新的均值作为质心
# 更新簇分配编码,将当前簇分配替换为上次的簇分配
result_set.iloc[:, -1] = result_set.iloc[:, -2]
return centroids, result_set将鸢尾花数据带进去,查看模型的效果:
python
iris_cent,iris_result = kMeans(iris, 3)
iris_cent
iris_result.head()执行结果若下所示: 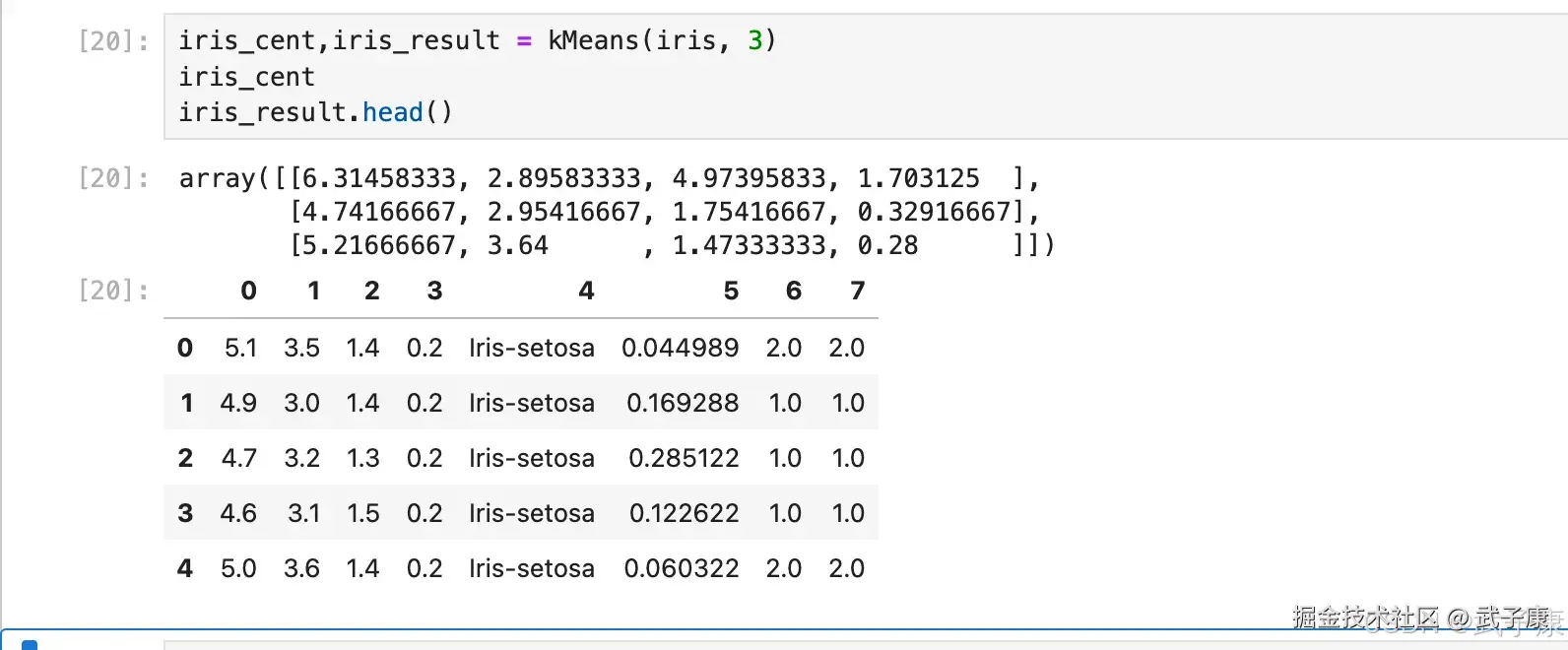 有几点需要特别注意:
有几点需要特别注意:
- 设置统一的操作对象 result_set,为了调用和使用的方便,这里将 clusterAssment 转换为了 DataFrame 并与输入 DataFrame 合并,组成的对象作为后续调用的统一对象,该对象内即保存了原始数据,也保存了迭代运算的中间结果,包括数据所属簇标记和数据质心距离等,该对象同时也作为最终函数的返回结果
- 判断质心是否发生改变条件,在K-Means 中判断质心是否发生改变,即判断是否继续进行下一步迭代的依据并不是某点距离新的质心距离变短,而是某点新的距离向量(到各质心的距离)中最短的分量位置是否发生变化,即质心变化后某点是否应归属另外的簇,在质心变化导致各点所属簇发生变化的过程中,点到质心的距离不一定会变短,即判断条件不能用下述语句表示
- 质心和类别一一对应,在最后生成的结果中,centroids的行标为 result_set 中各点所属类别
错误速查
| 症状 | 根因 | 修复 |
|---|---|---|
| 读入 iris.txt 报错或为空 | 路径不对/文件不在工作目录 | 使用 os.getcwd()、pd.read_csv 报错栈;使用绝对路径或把数据放到工作目录;明确分隔符 sep |
iris.shape 显示列数不符合预期 |
分隔符/编码问题导致整行进一列 | iris.head() 检查列是否被挤到一列;指定 sep=',' 或空白分隔;必要时指定 engine='python' |
K-Means 迭代报 TypeError/could not convert string to float |
标签列是字符串,但参与了数值运算或聚合 | 检查 dataSet.dtypes;result_set.groupby(...).mean() 只对数值特征列计算距离与均值 |
质心数量变少(k=3 变成 2)或出现 NaN |
空簇:某簇没有样本被分配,groupby 后该簇消失 |
检查 result_set.iloc[:, n+1].value_counts()、centroids.shape;检测缺失簇并重置该簇质心;保持 k 不变 |
| 程序长时间不结束或"看似卡住" | 仅用簇编号变化作停止条件,缺少 max_iter;异常情况下难收敛 |
为 while 循环增加 max_iter 与容差阈值(质心移动距离/目标函数下降);记录迭代日志 |
| 每次运行结果差异大,难复现 | 未设置随机种子 | 在 randCent 前设置 np.random.seed(...) 或传入 RNG;在文中注明 seed |
| 聚类结果偏向某一维度,分簇不合理 | 特征量纲不统一,距离被大尺度特征主导 | 对比各列范围 min/max;先做标准化/归一化(z-score / min-max),再聚类 |
| Matplotlib 中文乱码/方块字 | Simhei 不存在或字体未安装 |
使用系统可用字体回退列表或安装字体;按操作系统提供替代方案 |
| 坐标轴负号显示成方块/乱码 | 字体不支持 unicode minus | 设置 plt.rcParams['axes.unicode_minus']=False;必要时更换字体 |
在 .py 里运行 %matplotlib inline 报错 |
魔法命令仅 Notebook 有效 | Notebook 保留;脚本改为 plt.show() 并移除魔法命令 |
运行出现 Pandas FutureWarning(聚合非数值列) |
groupby().mean() 行为在不同版本调整 |
显式选择数值列聚合,避免未来版本不兼容 |
其他系列
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究 ,持续打造实用AI工具指南! AI研究-132 Java 生态前沿 2025:Spring、Quarkus、GraalVM、CRaC 与云原生落地
💻 Java篇持续更新中(长期更新)
Java-218 RocketMQ Java API 实战:同步/异步 Producer 与 Pull/Push Consumer MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务已完结,Dubbo已完结,MySQL已完结,MongoDB已完结,Neo4j已完结,FastDFS 已完结,OSS已完结,GuavaCache已完结,EVCache已完结,RabbitMQ已完结,RocketMQ正在更新... 深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解