引言:从"快"到"稳",架构演进的必然
自 Aloudata CAN 自动化指标平台发布以来,我们始终坚持"NoETL 语义编织"的核心理念:主张企业应在明细数据(DWD)之上直接定义指标,而非依赖层层固化的物理宽表。这种"基于明细数据,定义即开发"的模式,最大程度地保障了指标口径的语义一致性,并赋予了业务人员最大的分析自由度。
为了支撑这一理念,Aloudata CAN 构建了强大的语义解析引擎。在很长一段时间内,我们默认采用 MPP 架构的 OLAP 引擎(如 Apache Doris、StarRocks)作为核心计算与存储载体。在绝大多数高并发、低延迟的交互式分析场景中,这种架构凭借极其优异的查询响应速度,证明了其高效性。
然而,随着企业数字化转型步入深水区,数据运营的颗粒度与深度发生了质变。我们观察到,头部企业的业务需求正在从"看宏观趋势"向"做微观归因"转变。业务部门开始依赖长周期的复杂明细计算来辅助决策,例如,零售企业需要基于过去两到三年的交易明细,计算特定人群的生命周期价值(LTV);金融机构需要回溯海量流水数据,进行跨周期的风险因子归因。
当这种涉及百亿甚至千亿级数据的长周期、高复杂度计算成为常态,单一 OLAP 引擎架构开始面临物理定律的挑战。OLAP 引擎虽然擅长快速查询,但在处理超大规模数据的全量物化构建这种"重吞吐"任务时,往往面临内存资源(OOM)瓶颈。尤其是长耗时任务运行在查询集群上,极易引发资源争抢,影响业务连续性。
在企业真实的技术环境中,通常不会也不应只有一种计算引擎。OLAP 引擎擅长交互式分析,而 Spark 等批处理引擎则在海量数据吞吐与稳定性上具备天然优势。随着客户数量的持续增长和应用场景的深入,我们也应当适时升级底层架构。
因此,Aloudata CAN 正式推出"双引擎物化架构"。这不是对过往的否定,而是 NoETL 理念在工程落地上的成熟------让语义层保持统一,让计算层各司其职:既通过 OLAP 引擎保障前端查询的极致速度,又通过 Spark 引擎承载千亿级数据的批处理计算。
极限场景实测:千亿级明细计算突围
架构设计的优劣,最终需要回到真实的业务熔炉中去检验。为了验证双引擎架构在极端负载下的表现,我们与一家头部零售行业的标杆客户合作,进行了一次"极限压测"。
- 场景背景:
客户要求基于过去两年的全量交易明细数据(规模达千亿级),计算包括"客单价 52 周同环比"、"订单数 52 周同环比"等在内的 28 个核心指标和 17 个复杂维度。
- 遭遇战(OLAP 单引擎):
该任务最初由一套配置豪华的 OLAP 集群承担(数千核 CPU,近 20TB 内存)。然而,面对千亿级数据的大规模 Join 和复杂聚合,OLAP 引擎依然触碰到了内存处理的物理边界,任务因 OOM 反复失败。印证了在超大规模的全量物化场景中,单纯依赖内存密集型的 OLAP 引擎并非最优解。
- 突围战(双引擎切换):
我们将该任务切换至 Aloudata CAN 的双引擎模式,启用 Spark 批处理引擎接管计算,从"全内存依赖"切换为更稳健的"内存+磁盘 Shuffle"的预计算模式。在新的架构下,我们将计算资源整体减半。
实测结果显示:
- 稳定性质变:任务成功率从不确定转变为 100%,彻底消除了 OOM 风险。
- 效率可控:虽然 Spark 采用落盘机制,一个加速场景从明细计算到最终汇总指标产出,端到端跑批计算耗时约 60 分钟。但相比 OLAP 引擎的系统崩溃导致不可用,整体交付时间反而大幅缩短,且资源成本显著降低。
这一实战有力地证明:Aloudata CAN 的双引擎架构具备了在生产环境下,以更稳健的方式驾驭企业核心数据资产的工程能力。
深度解析:系统自动化还是专家经验?
面对如此庞大的计算量,资深 ETL 工程师往往会质疑:"如果我手动写 SQL 进行精细化分层和调优,肯定比系统自动生成的跑得快。"
是的,针对单一特定任务,一位精通业务与集群特性的顶尖专家,确实能通过 Case by Case 的"手工艺"实现比自动化系统更高的效率。但当我们把视角拉升至企业级工程时,账就不能这么算了。
- 并非"暴力计算"
Aloudata CAN 的计算引擎不是简单的 SELECT *。系统内置了复杂的任务编排逻辑,自动进行任务拆分、推导中间层依赖,并根据集群负载控制并行度。它寻求的是一种基于规则抽象的、整体效率最高的自动化路径。
- 规模效应与维护成本
顶尖专家是稀缺资源,他们或许能完美优化 Top 10 的核心任务,但剩余 90% 的长尾指标谁来维护?更重要的是,当业务口径发生微调时(例如修改了一个中间层的过滤条件),人类专家可能需要排查数十个脚本的血缘影响并重写代码,而自动化系统只需修改语义定义,即可自动重新编排最优执行路径。
维护成本的归零,才是自动化最大的红利。
这就是 Aloudata CAN 双引擎架构的核心价值------它追求的不是单点极致性能,而是企业级整体数据开发的最高投入产出比(ROI)。机器以 100% 的准确率和极高的性价比完成海量计算,将宝贵的人类专家从繁琐代码和运维任务中解放出来,专注于数据建模与业务价值挖掘。
硬核技术拆解:在异构架构之上重构统一语义
增加一个计算引擎并非简单的"功能挂载",而是一次伤筋动骨的架构重构。核心挑战在于:如何在物理执行层分化(MPP vs Batch)的情况下,依然向上层用户屏蔽复杂性,维持"定义即开发"的体验。
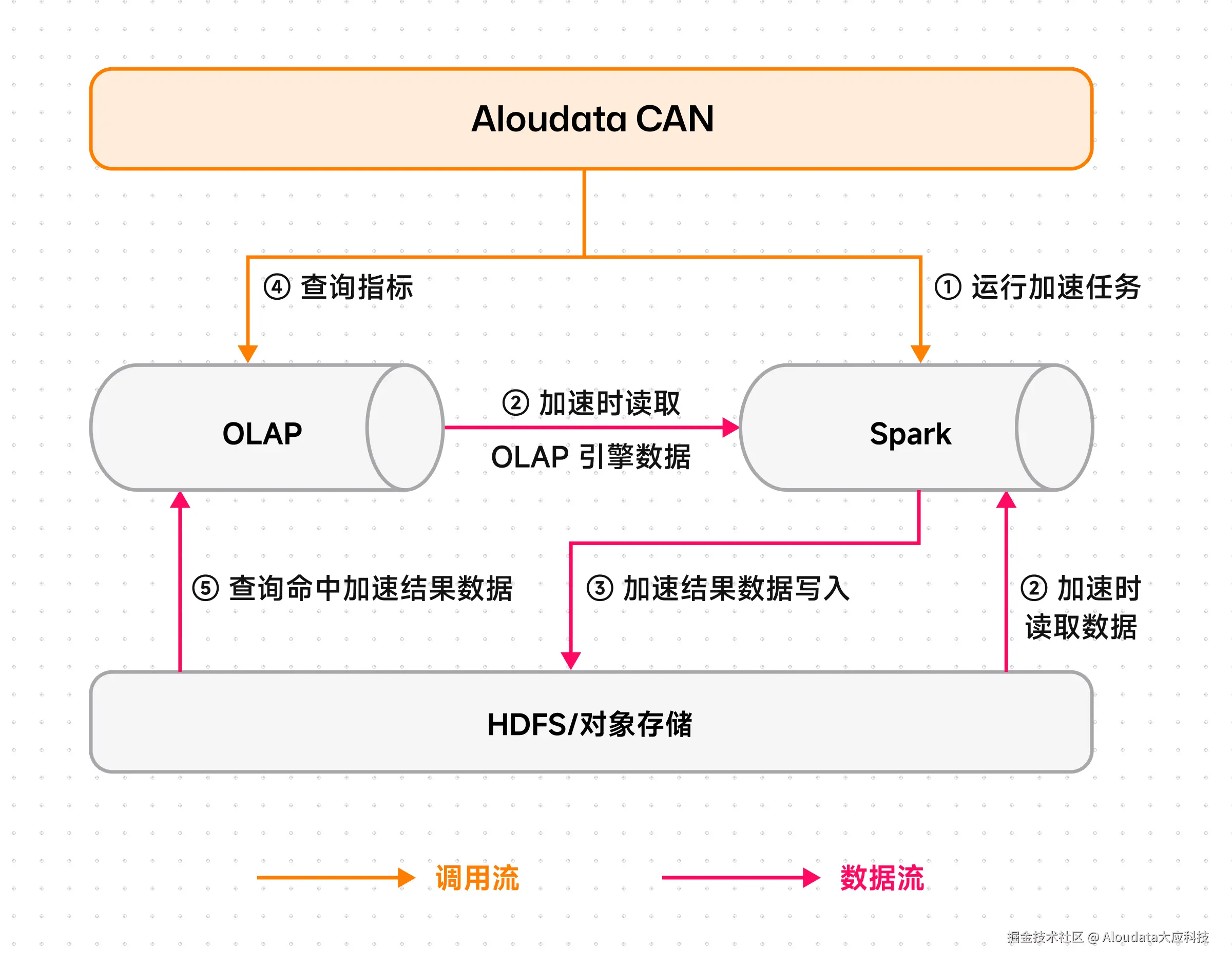
图:双引擎架构下,当用户选择通过 Spark 进行加速任务构建的系统架构图
- 无感知的方言翻译:构建语义层的"通用编译器"
系统在语义层构建了一套高精度的"方言编译器"。当用户发起加速请求时,系统会自动将统一的语义模型(Semantic Model)"编译"为针对 Spark 优化的物理 SQL。无论是窗口函数还是日期处理,系统自动抹平了 Spark 与 OLAP 的语法差异,确保计算结果在数学上的绝对一致。
- 异构存储的无缝吞吐:基于 Arrow Flight 的高速总线
为了解决 Spark 读取 OLAP 内表数据的性能瓶颈,我们利用 Spark Connector 结合 Apache Arrow Flight 技术,实现了数据的向量化传输与并行读取。系统能够自动切分 Tablet 并行拉取,极大降低了序列化开销,确保海量明细数据的秒级吞吐。
- 智能分区管理:大规模数据的一致性保障
在处理长周期历史回刷时,Aloudata CAN 深度集成了 Spark 的动态分区覆写(Dynamic Partition Overwrite)机制。系统精确识别受影响的时间分区,仅对特定分区进行重算与覆写,配合事务机制,确保无论任务耗时多久,对外呈现的数据始终一致且可用。
架构红利:更稳的 SLA 与更优的 ROI
引入双引擎架构,更为企业带来了隐性的架构红利。
- 资源隔离:终结"跑批拖垮看数"
双引擎实现了物理层面的资源隔离:OLAP 引擎回归"极速查询"本位,服务 BI 与 AI;Spark 接管重负载的全量构建。这种分工彻底解决了"构建负载"挤占"分析负载"的难题,确保前台 CEO 看板在任何时刻都流畅如初。
- FinOps 视角下的最优解
企业不再需要为了应对偶尔的计算峰值而按"最高水位"配置昂贵的 OLAP 集群。通过将低频、高吞吐的重型计算转移至单位成本更低的 Spark 集群,企业可以在不牺牲性能的前提下,显著降低 TCO。
- 开放与兼容
系统默认支持将结果写回 Doris 内表以提供最佳查询性能,但我们同样支持 Hive Metastore 和 Iceberg。意味着 Aloudata CAN 能无缝融入企业已有的湖仓生态,保护既有 IT 投资。
结语:让数据团队回归业务价值
技术的进步,是为了将人类从重复劳动中解放出来。
Aloudata CAN 双引擎架构的推出和生产级验证,标志着 NoETL 指标平台这一自动化数据开发与治理的新品类已经具备了处理企业级核心、极端负载的成熟能力。面对千亿级数据,企业无需再为"算不动"而焦虑,也无需在"灵活性"与"稳定性"之间做艰难取舍。
当机器已经能以 100% 的准确率和最优成本完成海量计算时,数据专家的智慧,应当聚焦于定义那些真正驱动增长的业务指标,而非纠结于底层的 SQL 写法。
这正是我们构建双引擎架构的初衷:用最硬核的工程底座,支撑最自由的业务探索。