论文基本信息
Paper: BrainBERT: Self-Supervised Representation Learning for Intracranial Recordings
机构: MIT
Publication: ICLR
Year: 2023
背景
神经科学领域的神经信号分析长期面临一个根本性困境:强大的非线性解码器 vs. 可解释性之间的权衡。
-
线性解码器:目前神经科学中最流行的方法,具有可解释性优势------如果某个任务能被线性解码,说明该信息确实存在于大脑该区域。但许多有趣的认知任务和特征可能无法被线性解码,原因包括:
- 标注训练数据稀缺(神经科学实验数据收集成本极高)
- 来自邻近神经过程的噪声干扰
- 仪器的时间和空间分辨率限制
-
深度神经网络:虽然表达能力更强,但可解释性降低------存在风险:任务可能不是由大脑完成的,而是由解码器本身完成的。
BrainBERT开辟了"基础模型"(Foundation Model)路线在颅内神经记录中的应用:通过自监督掩码重建学习从海量无标注颅内场电位(SEEG)数据中提取通用表征,再适配特定神经解码任务,实现了"深度网络的性能 + 线性解码器的可解释性"两全其美。
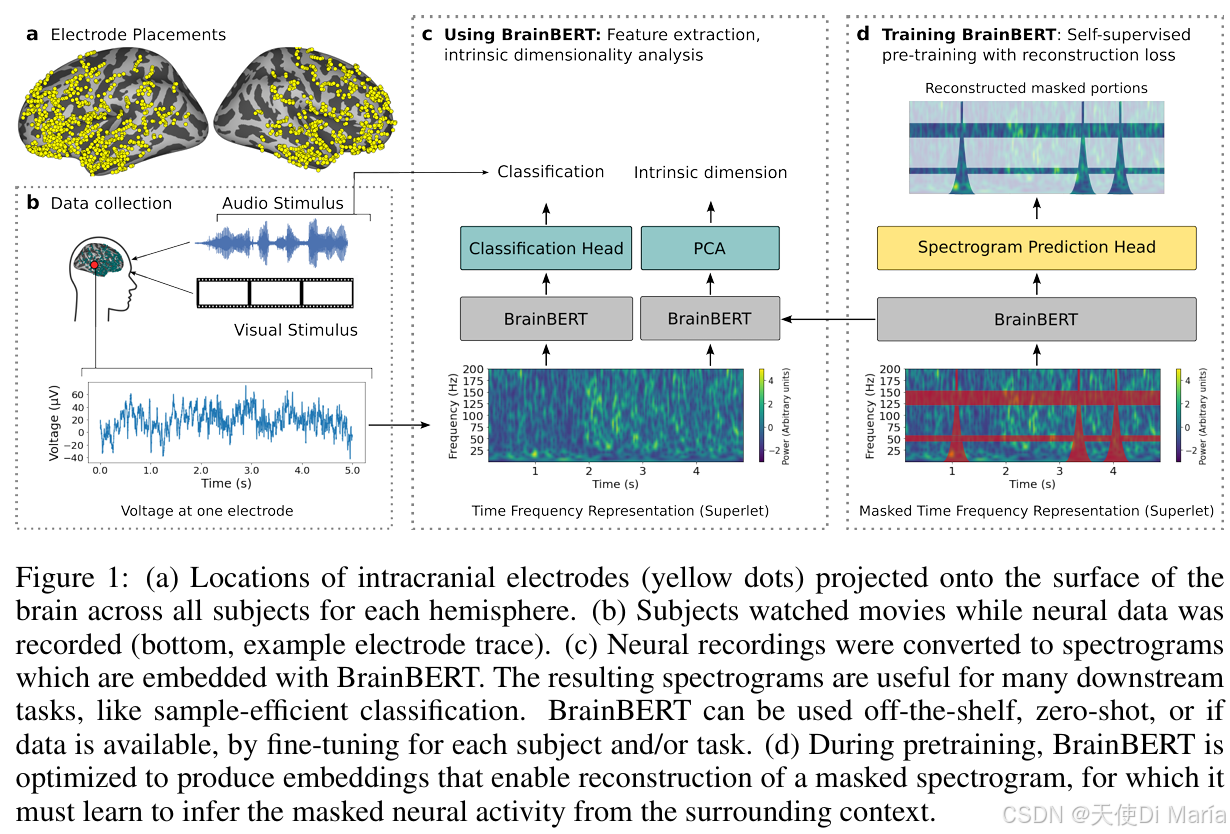
方法
(1)数据集
预训练数据集:SEEG颅内记录👇
- 10名受试者(5男5女,年龄4-19岁,平均11.9岁)
- 药物难治性癫痫患者临床监测期间记录
- 1,688个电极,平均每人167个电极
- 采样率2kHz,总记录时长43.7小时(4,551电极-小时)
- 受试者观看21部不同电影时记录神经活动
- 预训练集:19个session(平均2.3小时/人)
- 测试集:7个session(平均2.55小时/人)
(2)预处理
首先对原始SEEG信号进行高通滤波(0.1Hz)去除基线漂移,然后去除60Hz工频噪声及其谐波干扰。采用Laplacian重参考方法,每个电极减去同一探针上相邻两个电极的平均信号,以降低电极间相关性。仅保留可以进行Laplacian重参考的电极(即具有邻居电极的电极)。最后对所有电极信号进行目视检查,剔除明显损坏的记录。预训练数据最终包含1,249个电极(约74%)的4,551电极-小时数据。
(3)时频表示
BrainBERT支持两种时频输入表示:
STFT(短时傅里叶变换):窗口大小400样本(约200ms),重叠350样本(约175ms),频率通道0-200Hz均匀分布。
Superlet变换:复合Morlet小波变换,基频c₁=1,阶数o=3-30自适应,频率范围0.1-200Hz。与STFT固定时频分辨率不同,Superlet在高频具有更高时间分辨率,更适合捕捉神经信号中高频振荡的短时爆发特性。
两种表示均沿时间轴进行z-score归一化,使各频率带处于同等地位,确保BrainBERT嵌入对各类任务具有通用性。
(4)掩码策略
BrainBERT采用自适应掩码策略处理时频表示:
STFT掩码:随机选择时间和频率区间进行掩码,时间掩码宽度1,5,频率掩码宽度1,2。
Superlet自适应掩码:考虑到Superlet时频分辨率随频率变化的特性,时间掩码宽度随频率增加而减小(反比关系),频率掩码宽度随频率增加而增加。这种自适应策略更好地匹配了神经信号的物理特性。
掩码位置有三种处理方式(概率分别为0.1保持不变、0.1替换为随机片段、0.8置零),以防止模型学习恒等映射。
(5)预训练损失
BrainBERT的预训练损失由L1重建损失和内容感知损失两部分组成:
L1重建损失:对掩码位置的频谱图元素计算L1重建误差。
内容感知损失:针对神经信号的稀疏性特点(约68%的z-score频谱图为0或<1),额外增加对远离0的信号元素(>阈值γ)的重建激励,防止模型倾向于预测0。
总损失: L = L L + α L C \mathcal{L} = \mathcal{L}_L + \alpha\mathcal{L}_C L=LL+αLC
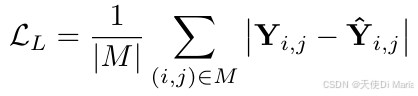
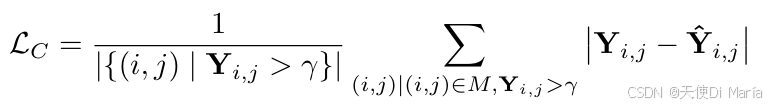
模型架构:6层Transformer编码器,隐藏维度768,12个注意力头,dropout率0.1。使用LAMB优化器,学习率1e-4,批量大小256,训练500k步。
实验
在未见过的新受试者、新电极位置上,作者在4个不同层次的解码任务上验证BrainBERT性能:
| 任务 | 层次 | 描述 |
|---|---|---|
| 句子起始检测 | 高级认知 | 判断受试者是否听到新句子开始 |
| 语音/非语音分类 | 中级认知 | 判断受试者是否在听语音 |
| 音高分类 | 低级感知 | 判断听到单词的音高高低 |
| 音量分类 | 低级感知 | 判断听到音频的音量大小 |
主要结果
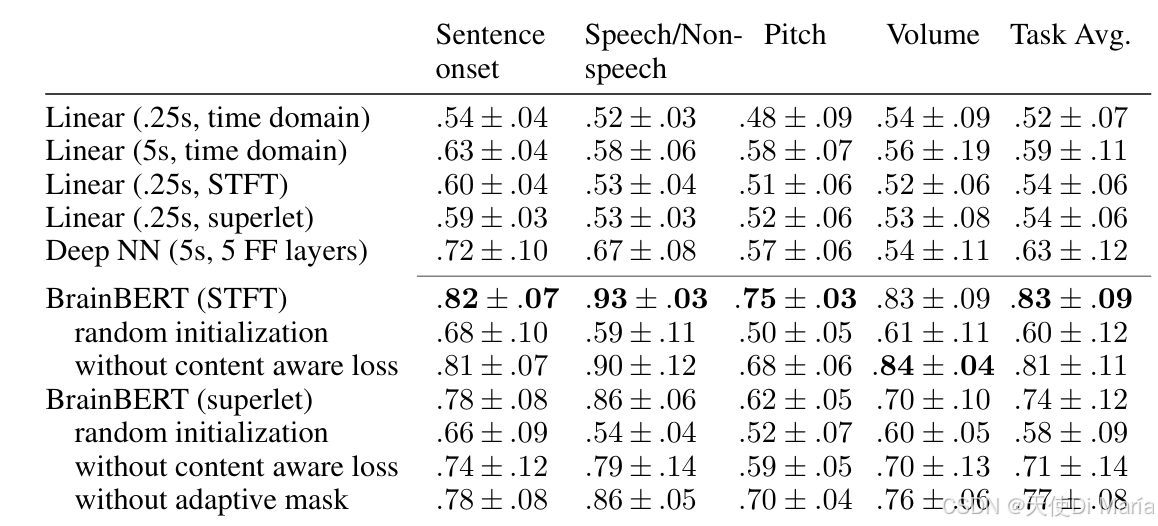
解码准确率提升:
- 线性解码器(5s时域)平均AUC:0.59
- 深度神经网络平均AUC:0.63
- BrainBERT(STFT)平均AUC:0.83(提升41%)
- BrainBERT(Superlet)平均AUC:0.74(提升25%)
BrainBERT将"边缘结果"转变为"明确成功",在句子起始检测任务上达到0.82 AUC,语音/非语音分类达到0.93 AUC。
无需微调的BrainBERT :
冻结BrainBERT权重,仅训练线性分类头,平均AUC达0.63,与深度NN持平。实现了深度网络的性能 + 线性解码器的可解释性两全其美。
泛化到新受试者 :
对每位受试者进行留一法分析,包含该受试者 vs. 排除该受试者的预训练,性能差异可忽略。证明BrainBERT可即插即用于新实验和新电极位置。
数据效率 :
BrainBERT仅需150个样本 即可达到深度NN需要1000个样本的性能,数据效率提升5倍以上。
内在维度分析 :
利用BrainBERT嵌入计算每个电极的内在维度(ID),发现高ID电极主要集中在额叶和颞叶,最高ID区域为缘上回(语音处理)、外侧眶额皮层(感觉整合)、杏仁核(情绪)。这是首次实现任务无关的大脑功能区域识别。
总结
BrainBERT证明,通过借鉴NLP的BERT掩码语言建模技术,用自监督重建学习从大规模无标注颅内神经记录数据中学习通用神经表示,可以有效解决神经科学中的数据稀缺和跨受试者泛化难题。它不仅在多个解码任务上取得了显著性能提升,更重要的是保持了线性解码器的可解释性,并能泛化到新受试者和新电极位置。
这项工作为神经科学研究和脑机接口应用提供了一个强大的新工具,有望像语言模型改变NLP一样,改变我们对大脑的理解方式------通过研究模型学习的内容来研究大脑本身。