推荐直接网站在线阅读:aicoting AI算法面试学习在线网站
树模型与集成模型是机器学习中非常重要的一类方法。树模型(如决策树)通过逐层划分特征空间,把复杂的预测问题转化为一系列"如果-那么"的规则,具有直观、可解释性强的特点。
单棵决策树往往容易过拟合,但当多个树结合在一起,就能形成更强大的 集成模型。常见的集成方法包括 Bagging(如随机森林),它通过多棵树投票减少方差;Boosting(如 AdaBoost、GBDT、XGBoost、LightGBM、CatBoost),它通过迭代训练不断纠正错误,提高精度;还有 Stacking,通过多层模型组合提升泛化能力。集成模型通常比单一模型更稳定、更准确,是工业界大规模应用的主力方法之一。
决策树
基本原理
决策树(Decision Tree) 是一种常用的监督学习方法,可用于分类和回归任务。它通过不断地"提问"并"分裂",把复杂问题分解成一系列简单的判断。
例如,在分类问题中,决策树会根据某个特征是否满足条件,把数据划分成不同的子集,直到最终得到叶节点的分类结果。整个过程像是一连串的 "如果...那么..." 规则。 数学上,决策树的学习过程就是 选择最优特征和最优切分点,使得数据划分后"不确定性"最小。
划分准则
决策树的核心问题是 如何选择最佳特征来划分数据。常见的准则包括:
- 信息增益(ID3)
信息增益通过衡量数据集在某一特征上划分后熵的减少量,来选择最优划分特征。它直观地表示划分前后不确定性的下降程度。信息增益越大,说明该特征能更好地区分样本。但它偏向于选择取值较多的特征。
公式为:
Gain(D,A)=Entropy(D)−∑v∈Values(A)∣D∣∣Dv∣Entropy(Dv)
其中:

- 信息增益率(C4.5)
信息增益率是对信息增益的改进,它在计算信息增益的同时,引入特征自身取值分布的"固有值"进行归一化,从而削弱了取值过多特征的优势。它能够在保证区分度的同时,避免偏向高取值特征。
Gain_ratio(D,A)=IV(A)Gain(D,A)
IV(A) :信息增益的归一化因子(固有值,Intrinsic Value),
IV(A)=−∑v∈Values(A)∣D∣∣Dv∣log2∣D∣∣Dv∣
表示按照特征 A 进行划分本身带来的信息量大小。
- 基尼指数(CART)
基尼指数用来衡量数据集的不纯度,其值越小表示数据越"纯",即大部分样本集中在同一类别中。在分类任务中,CART 决策树通过选择能使基尼指数最小的特征和划分点来生成树结构,因此常用于二叉树的构建。
Gini(D)=1−∑k=1Kpk2
其中:

- 最小方差(回归树)
在回归问题中,决策树不再使用熵或基尼指数,而是通过最小化均方误差(MSE)来选择划分点。这样划分后,叶节点内的数据点与其均值的偏差最小,从而保证预测值尽量接近真实值。
决策树的构建与剪枝
- 构建阶段
- 从根节点开始,选择最优特征进行划分
- 重复划分,直到满足停止条件(如叶子节点纯度足够高,或树的深度达到限制)
- 剪枝阶段
决策树容易过拟合,因此需要 剪枝(Pruning):
- 预剪枝(Pre-pruning):在构建过程中提前停止划分(如设置最大深度、最小样本数)。
- 后剪枝(Post-pruning):先生成一棵完整的树,再通过交叉验证剪去效果不佳的分支。
常见决策树算法
- ID3:使用信息增益作为划分准则。
- C4.5:改进 ID3,使用信息增益率。
- CART(Classification and Regression Tree):既可用于分类(基尼指数),也可用于回归(最小方差)。
在实际应用中,CART 是最常用的算法,也是随机森林和梯度提升树的基础。
下面我们用 scikit-learn 构建一个决策树分类器,处理鸢尾花(Iris)数据集:
python
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier, export_text
from sklearn.metrics import accuracy_score
# 1. 加载数据
iris = load_iris()
X, y = iris.data, iris.target
# 2. 划分训练/测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 3. 构建决策树(CART算法,使用基尼指数)
clf = DecisionTreeClassifier(criterion="gini", max_depth=3, random_state=42)
clf.fit(X_train, y_train)
# 4. 预测
y_pred = clf.predict(X_test)
# 5. 评估
print("Accuracy:", accuracy_score(y_test, y_pred))
# 6. 打印规则
tree_rules = export_text(clf, feature_names=iris.feature_names)
print(tree_rules)输出如下,在 Iris(鸢尾花)数据集中,每朵花有 sepal length(萼片长度)、sepal width(萼片宽度)、petal length(花瓣长度)、petal width(花瓣宽度) 四个特征,用于分类不同种类的鸢尾花。
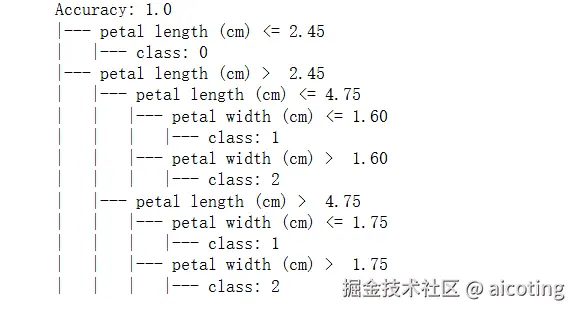
可以看到,决策树非常直观,直接给出了分类规则。
决策树模型直观、可解释性强,不需要特征缩放或归一化,既能做分类,也能做回归。适合处理非线性关系。
但是缺点就是容易过拟合(需要剪枝或结合集成方法),对噪声数据和小变动敏感,单棵树的预测能力有限。
简单总结一下就是决策树是一种简单而强大的模型,通过分而治之的思想,把复杂问题转化为一系列简单判断。虽然单棵树存在一定的局限性,但它作为 集成学习(随机森林、GBDT 等) 的基础,仍然是机器学习中不可或缺的重要方法。
最新的文章都在公众号aicoting更新,别忘记关注哦!!!