一、实验室的算力困局:GPU 再强,缺 HBM 也是 "摆设"
某顶尖高校 AI 实验室曾陷入尴尬:耗资千万搭建的 8 卡 H100 服务器,训练 70B 参数大模型时 GPU 利用率竟跌至 12%。问题的答案藏在集邦咨询的刺眼数据里 ------2025 年四季度部分内存价格暴涨 300%,而 GPU 的 "性能引擎" HBM(高带宽存储器)正处于全球短缺的核心。

二、HBM 与 GPU 服务器:不是配件,是 "性能共同体"
多数人将内存等同于 "存储 U 盘",但 HBM 与 GPU 的关系堪比飞机引擎与燃油系统,其技术特性直接决定服务器的算力上限,这正是科研服务器的核心技术逻辑:
- 带宽定义算力天花板:GPU 的数千个计算核心如同高速运转的精密机床,HBM 则是输送原料的 "超宽高速路"。传统 GDDR6 总线宽度仅 32 位,而 SK 海力士 HBM3E 通过 3D 堆叠与 TSV 硅通孔技术,实现 1024-2048 位超宽总线,带宽高达 1.23TB/s,是前者的 19 倍。带宽不足时,数据搬运耗时 9 毫秒,计算仅需 0.01 毫秒,昂贵的 GPU 相当于在 "空转"。
- AI 科研的刚需配置:32B 参数的大模型仅权重、梯度数据就需 600GB 内存,推理时的 KV 缓存更依赖低延迟传输。SK 海力士即将量产的 HBM4 更是实现性能飞跃:容量达 24-48GB,带宽突破 2.8TB/s,能效提升 40%,可使 AI 服务性能最高提升 69%,这正是突破科研 "内存墙" 的关键。
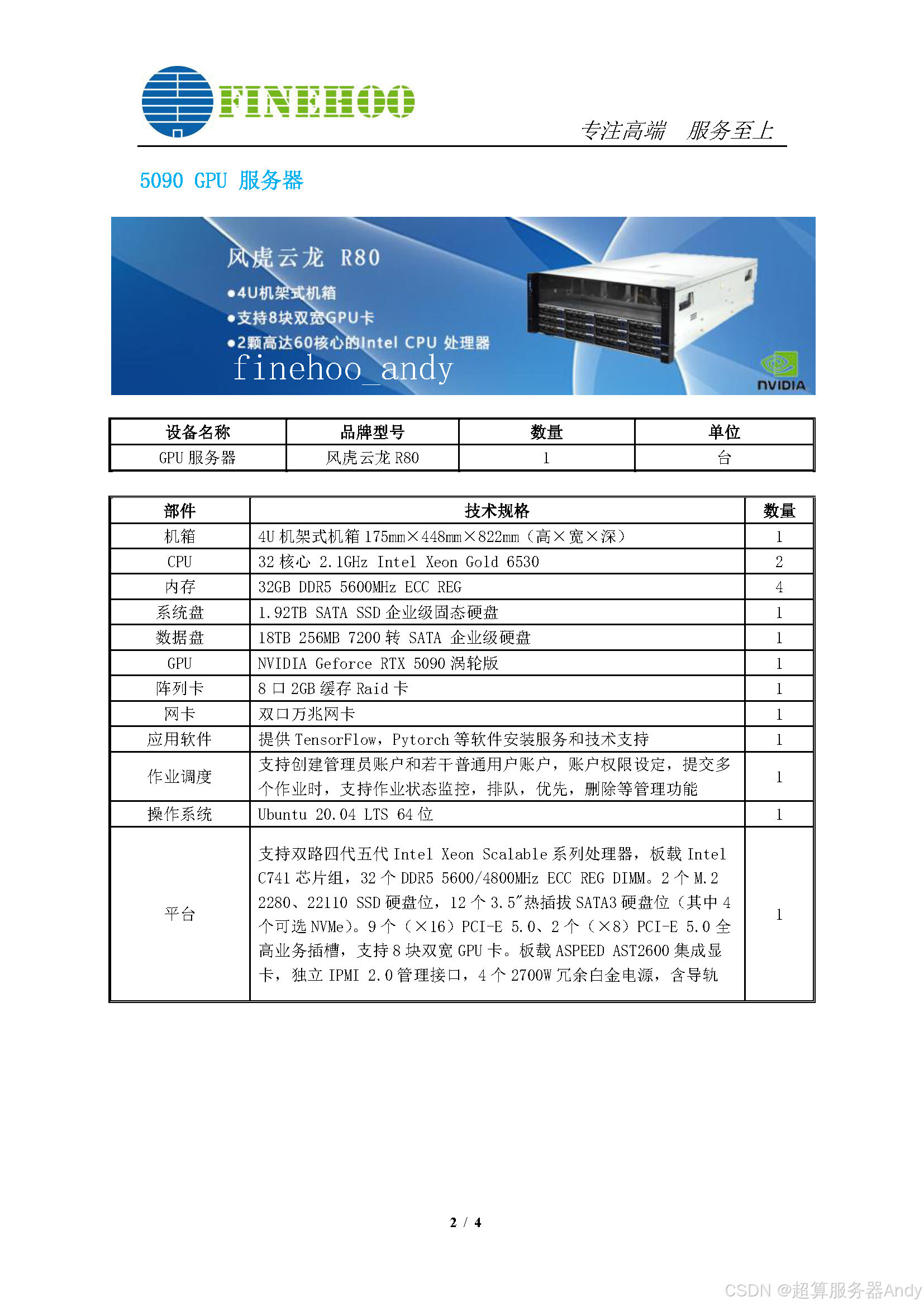
三、科研服务器的 3 大不可替代性:为什么非它不可?
科研场景的特殊性与 HBM 产能释放形成精准契合,这是消费级设备永远无法企及的核心价值,也是 SK 海力士加急扩产的深层逻辑:
- 大模型训练的 "算力解放器":基因测序的碱基配对分析、气候模拟的流体动力学计算,均需万亿级参数模型支撑。SK 海力士龙仁工厂投产后,单厂产能堪比利川园区 ------ 后者经改造后 HBM 月产能达 13 万片晶圆,可轻松满足科研服务器 TB 级内存需求,无需将模型拆分至多个节点。英特尔至强 Max 服务器的实测数据显示,内置 HBM2e 内存使 CFD 计算效率提升近 5 倍,这就是最直接的科研价值。
- 长期实验的 "稳定压舱石":科研项目往往持续数月甚至数年,数据中断可能导致数年心血付诸东流。SK 海力士按月调整的生产计划与客户的多年期供货协议,能形成稳定的内存供应链。香港某大学的量子化学模拟服务器,正是凭借 512GB 高规格 HBM 内存,实现了连续 180 天的分子结构运算无中断,这在消费级设备上根本无法想象。
- 成本与能效的 "平衡方案":HBM 虽初期成本较高,但 3D 堆叠技术使存储密度提升 4 倍,配合清州工厂的封装测试一体化布局,长期运维成本可降低 30%。更关键的是,像英特尔至强 Max 这样的科研服务器,在仅 HBM 模式下可直接节省 DDR5 内存的额外开支,进一步帮实验室控制预算。
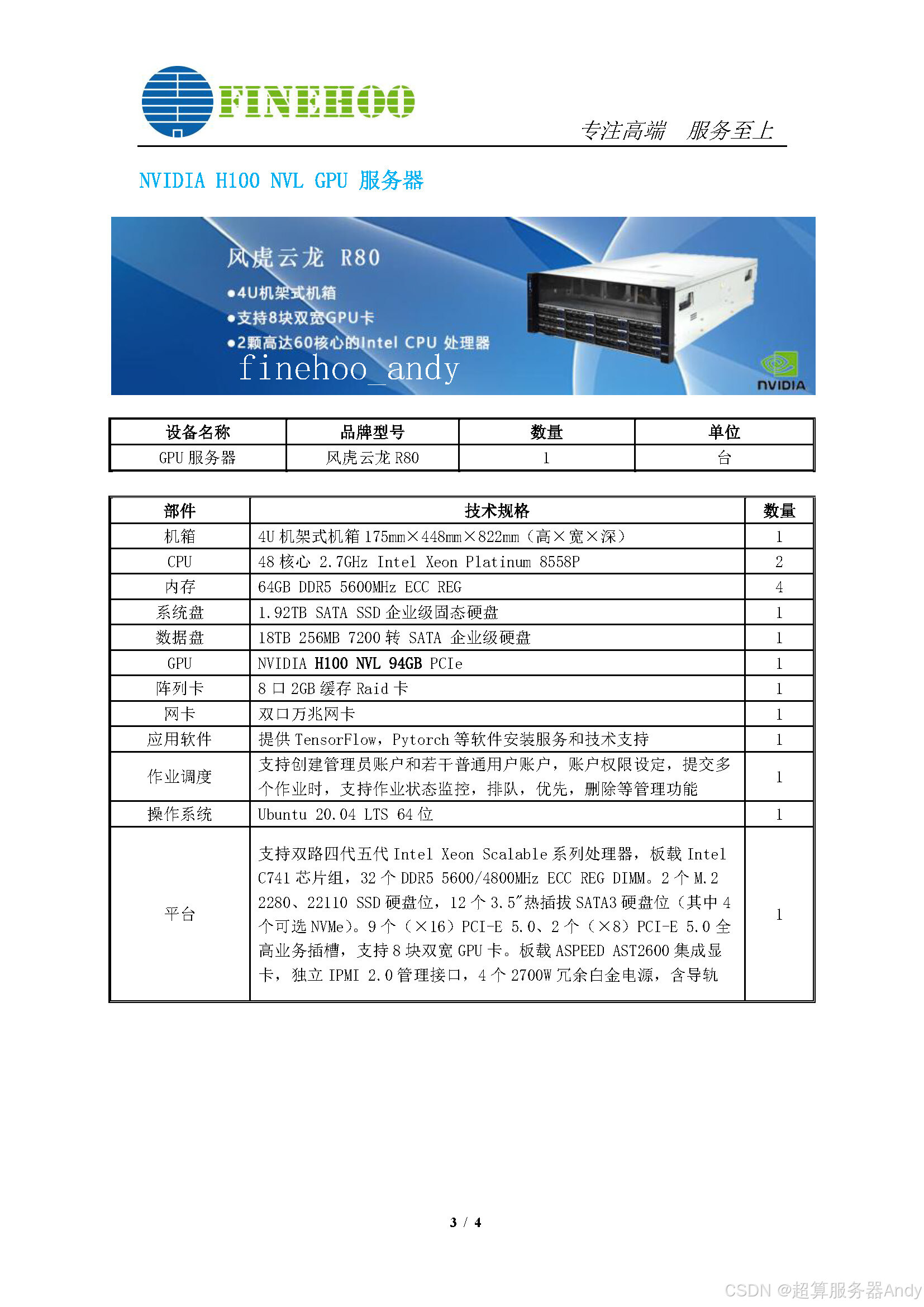
四、选科研服务器的 3 个黄金指标:看懂行业信号再出手
SK 海力士股价年涨 280% 的背后,是 HBM 市场的爆发式增长 ------ 预计 2028 年市场规模将达 1000 亿美元,复合年增长率 40%。对科研工作者而言,选型需紧盯这三个核心指标:
- 内存规格优先:认准 HBM3E 及以上标准,HBM4 将在 2026 年三季度快速承接需求,2025 年营收占比已达 55%,选对规格可适配未来 3 年的模型升级。
- 算力匹配度:遵循 "每 1PFlops 算力配 2TB/s 带宽" 的黄金比例,例如 8 颗 H100 需搭配总带宽 9.6TB/s 的 HBM 内存,避免 "高端 GPU 配低端内存" 的资源浪费。
- 供应链稳定性:优先选择与 SK 海力士、美光等头部厂商深度合作的品牌 ------ 要知道美光 2026 年的 HBM 供应量已全部售罄,稳定供应链直接决定服务器交付周期。
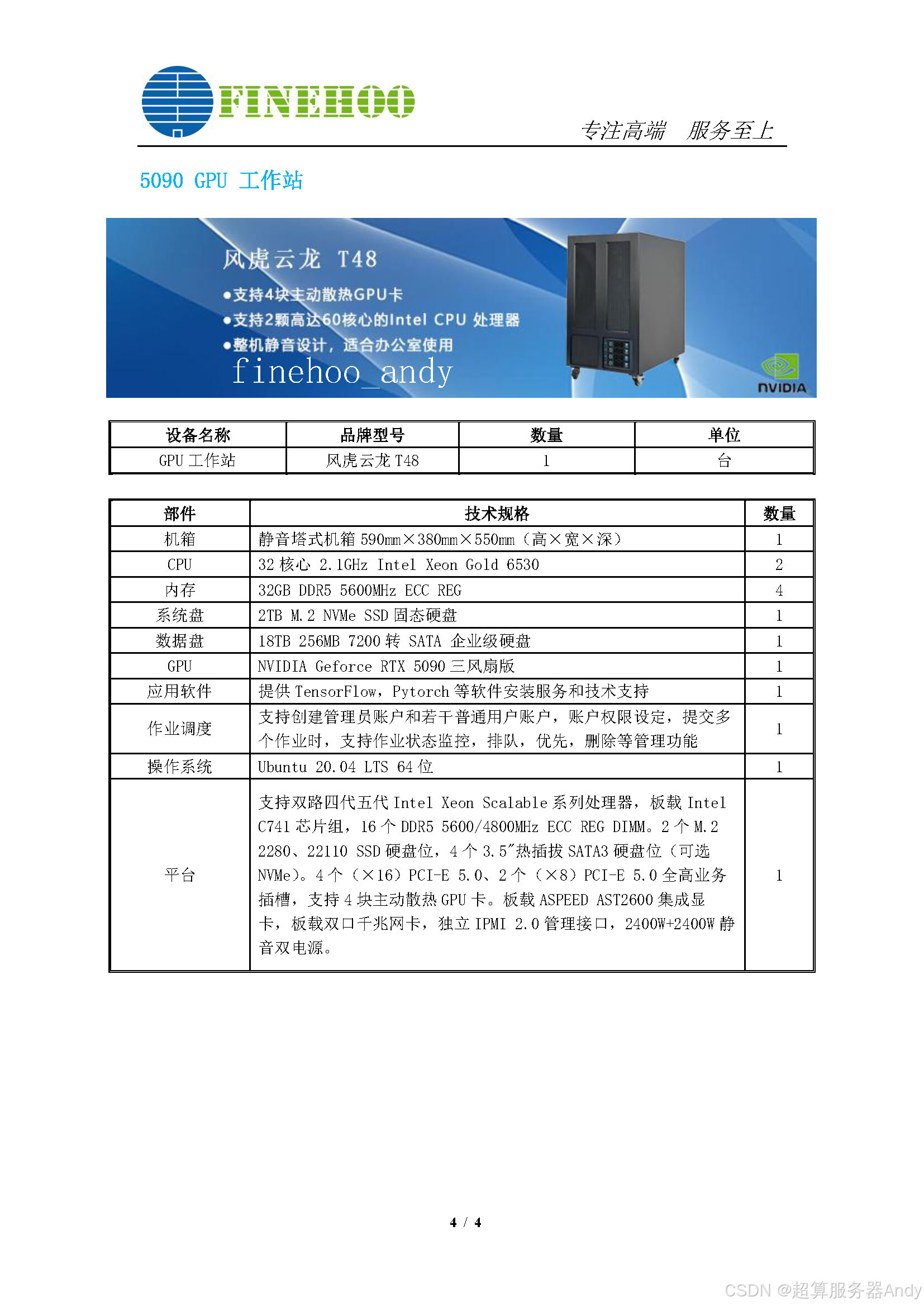
当 SK 海力士的晶圆在清州工厂启动量产,科研服务器终于要迎来 "内存自由"。对实验室而言,这不仅是设备性能的提升,更是学术突破的加速剂 ------ 毕竟在 AI 驱动的科研时代,算力自由的前提,永远是内存自由。