参考资料
- https://iceberg.apache.org/docs/latest/kafka-connect/#glue-example
- https://aiven.io/docs/products/kafka/kafka-connect/howto/aws-glue-catalog
在构建实时数据湖(Real-time Data Lake)的过程中,如何高效、可靠地将Kafka中的流式数据通过ACID事务特性写入存储层是关键环节。
本文内容为搭建一条从Kafka到S3的数据链路,要求使用Apache Iceberg表格式以支持后续的原子性读写和Time Travel查询,同时使用AWS Glue作为元数据中心(Catalog)以便于Athena或EMR引擎直接分析。
基础环境构建
首先构建本地Kafka集群作为数据源。使用Docker Compose部署Zookeeper与Kafka服务,确保网络与端口配置正确。
docker-compose.yaml 配置:
services:
zookeeper:
image: wurstmeister/zookeeper
container_name: zookeeper
ports:
- "2181:2181"
networks:
- kafka-net
kafka:
image: wurstmeister/kafka
container_name: kafka
ports:
- "9092:9092"
environment:
# 配置监听地址,确保容器内外均可访问
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://127.0.0.1:9092
KAFKA_LISTENERS: PLAINTEXT://0.0.0.0:9092
KAFKA_CREATE_TOPICS: "test:1:0"
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
ALLOW_PLAINTEXT_LISTENER: yes
depends_on:
- zookeeper
networks:
- kafka-net
networks:
kafka-net:
driver: bridge
ipam:
config:
- subnet: 172.20.0.0/16连接器配置
采用 connect-standalone 模式进行验证。需下载 Iceberg Kafka Connect 插件并置于指定目录。
核心配置文件说明:
(1) Worker 全局配置 (connect-standalone.properties) 定义Kafka接入点及默认的数据转换格式。
bootstrap.servers=localhost:9092
# 指定插件加载路径
plugin.path=/home/ec2-user/xxxx/kafka_2.13-2.8.1/plugins
# 全局默认使用JSON且包含Schema(注意:Sink端可覆盖此配置)
key.converter=org.apache.kafka.connect.json.JsonConverter
value.converter=org.apache.kafka.connect.json.JsonConverter
key.converter.schemas.enable=true
value.converter.schemas.enable=true
# Offset存储路径
offset.storage.file.filename=/tmp/connect.offsets(2) Source 端配置 (connect-file-source.properties) 使用 FileStreamSource 模拟流数据生产,实时读取本地文件写入Kafka Topic。
name=local-file-source
connector.class=FileStreamSource
tasks.max=1
file=test.txt
topic=test(3) Sink 端配置 (iceberg-sink-connector.properties) 这是集成的关键部分,负责将Kafka数据解析并提交至Glue/S3。
name=iceberg-sink-connector
connector.class=org.apache.iceberg.connect.IcebergSinkConnector
tasks.max=1
topics=test
# AWS Glue Catalog配置
iceberg.catalog.client.region=cn-north-1
iceberg.catalog.catalog-impl=org.apache.iceberg.aws.glue.GlueCatalog
iceberg.catalog.glue.region=cn-north-1
iceberg.catalog.glue.database=tmpiam
# S3 存储路径配置
iceberg.catalog.warehouse=s3a://zhaojiew-tmp/176154575009224
iceberg.catalog.io-impl=org.apache.iceberg.aws.s3.S3FileIO
# 表配置:目标表名及自动建表开关
iceberg.tables=tmpiam.testkafkaconnect2iceberg
iceberg.tables.auto-create-enabled=true
# 覆盖Converter配置:源数据为无Schema的纯JSON,故此处设为false
key.converter=org.apache.kafka.connect.json.JsonConverter
value.converter=org.apache.kafka.connect.json.JsonConverter
key.converter.schemas.enable=false
value.converter.schemas.enable=false备注
iceberg.catalog.catalog-impl: 指定使用GlueCatalog,这意味着Iceberg的元数据指针(metadata location)将存储在Glue Data Catalog中,而非仅在文件系统上维护。auto-create-enabled: 开启后,Connector会根据首批数据推断Schema并自动在Glue中创建表,极大简化初始化流程。schemas.enable=false: 针对Sink端,如果上游写入的是纯JSON数据(payload中不包含schema定义),必须关闭此选项,否则会报解析错误。
数据模拟与写入
编写Python脚本模拟业务系统持续产生日志数据。脚本以Append模式向 test.txt 写入JSON行,触发 FileStreamSource 读取。
脚本逻辑简述: 生成包含递增ID、随机名称和值的JSON记录,每秒写入一条。
with open('/home/ec2-user/case/.../test.txt', 'w') as f:
for i in range(1000):
message = { "id": current_id, "name": generate_random_string(), ... }
f.write(json.dumps(message) + '\n')
f.flush()
time.sleep(1)执行和验证
启动Kafka Connect Standalone进程:
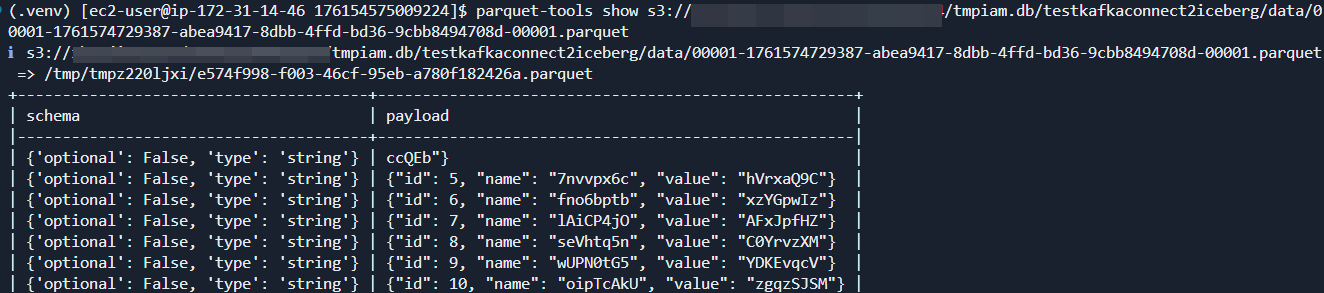
kafka_2.13-2.8.1/bin/connect-standalone.sh config/connect-standalone.properties config/connect-file-source.properties config/iceberg-sink-connector.properties日志显示Sink Connector成功启动,并周期性提交Iceberg Commit。
元数据验证 (Glue Console) ,在AWS Glue控制台 tmpiam 库下自动创建了名为 testkafkaconnect2iceberg 的表,Schema结构与Python脚本生成的JSON一致。
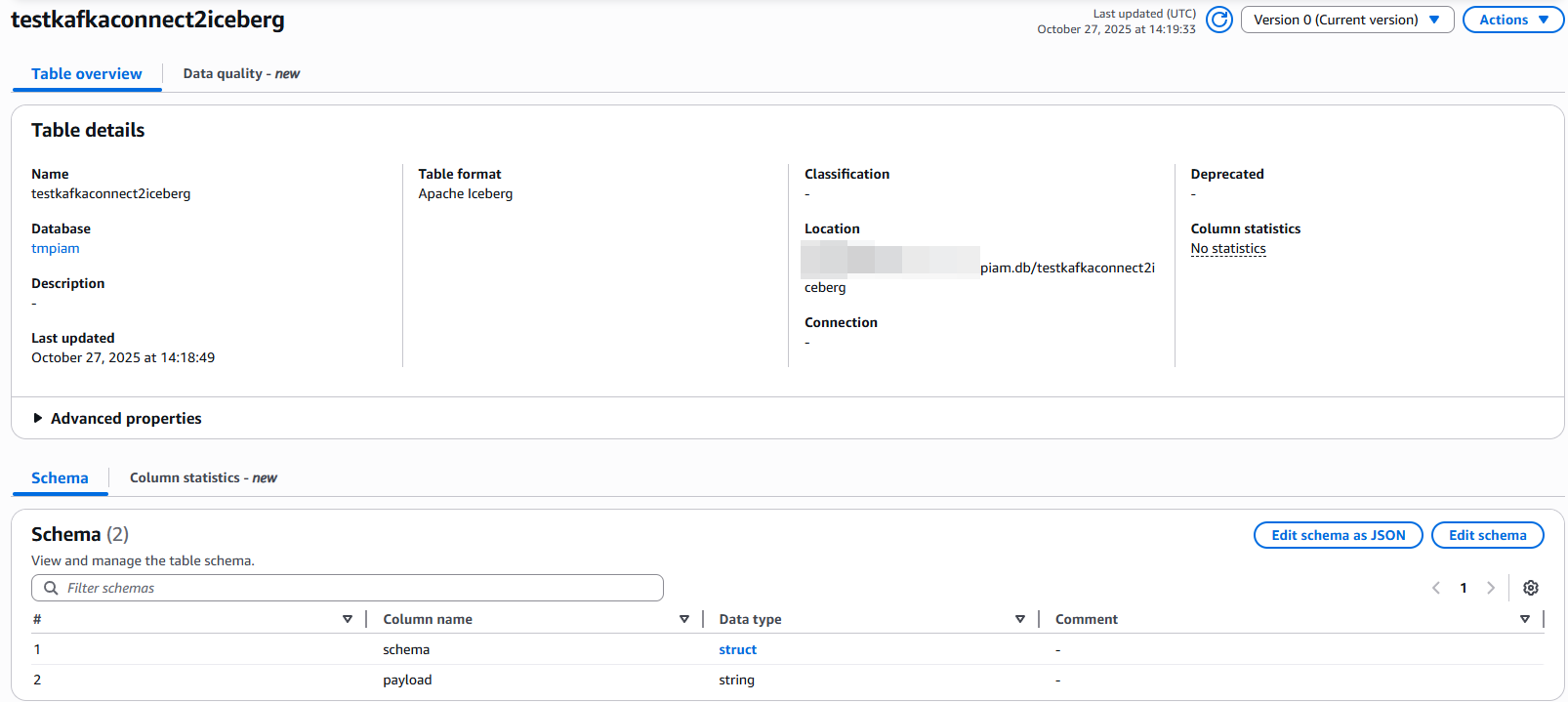
S3指定路径下生成了数据目录,其中包含 .parquet 格式的数据文件,以及 metadata/ 目录下的Iceberg元数据文件。
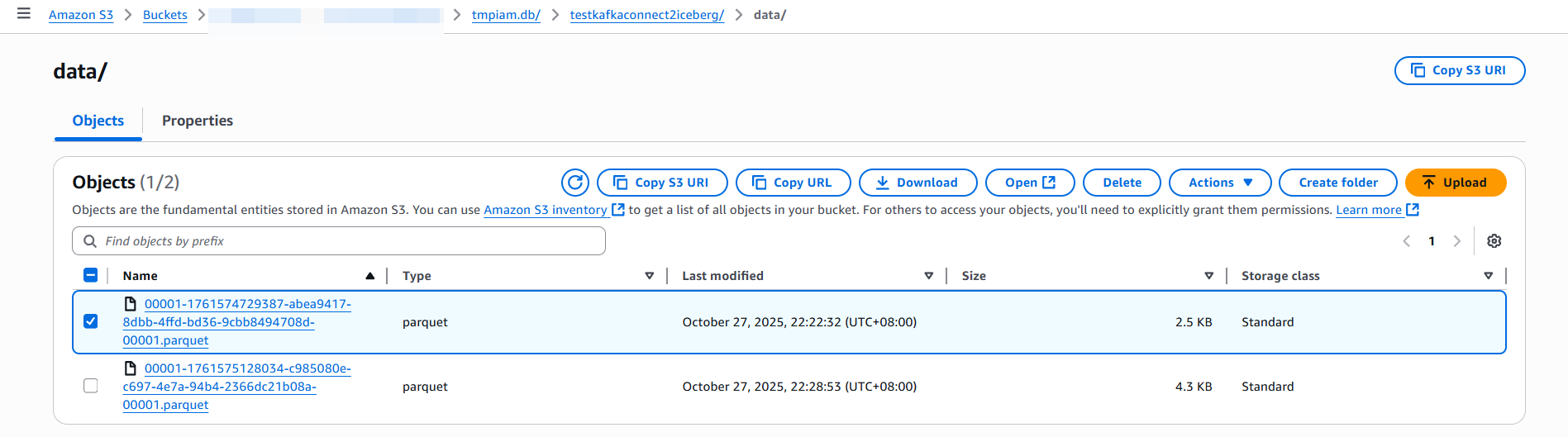
使用工具parquet-tools读取生成的Parquet文件,数据显示完整,字段解析正确,无乱码或丢失。
在生产环境中部署时,可以进一步配置 iceberg.control.commit.interval-ms 以平衡写入延迟与小文件数量,并启用压缩算法(如Snappy或Zstd)以优化存储成本。