一、了解工具
1.1 什么是工具
工具是为了给model增加功能使用的,比如问大模型现在是什么时间,大模型本身并不知道,它的数据只截止到训练日期,只会给出不及时的时间信息。
工具扩展了代理的功能------让他们能够实时获取数据、执行代码、查询外部数据库
在底层,工具是可调用的函数,输入和输出定义清晰,传递给聊天模型 。模型根据对话上下文决定何时调用工具,以及提供哪些输入论证。
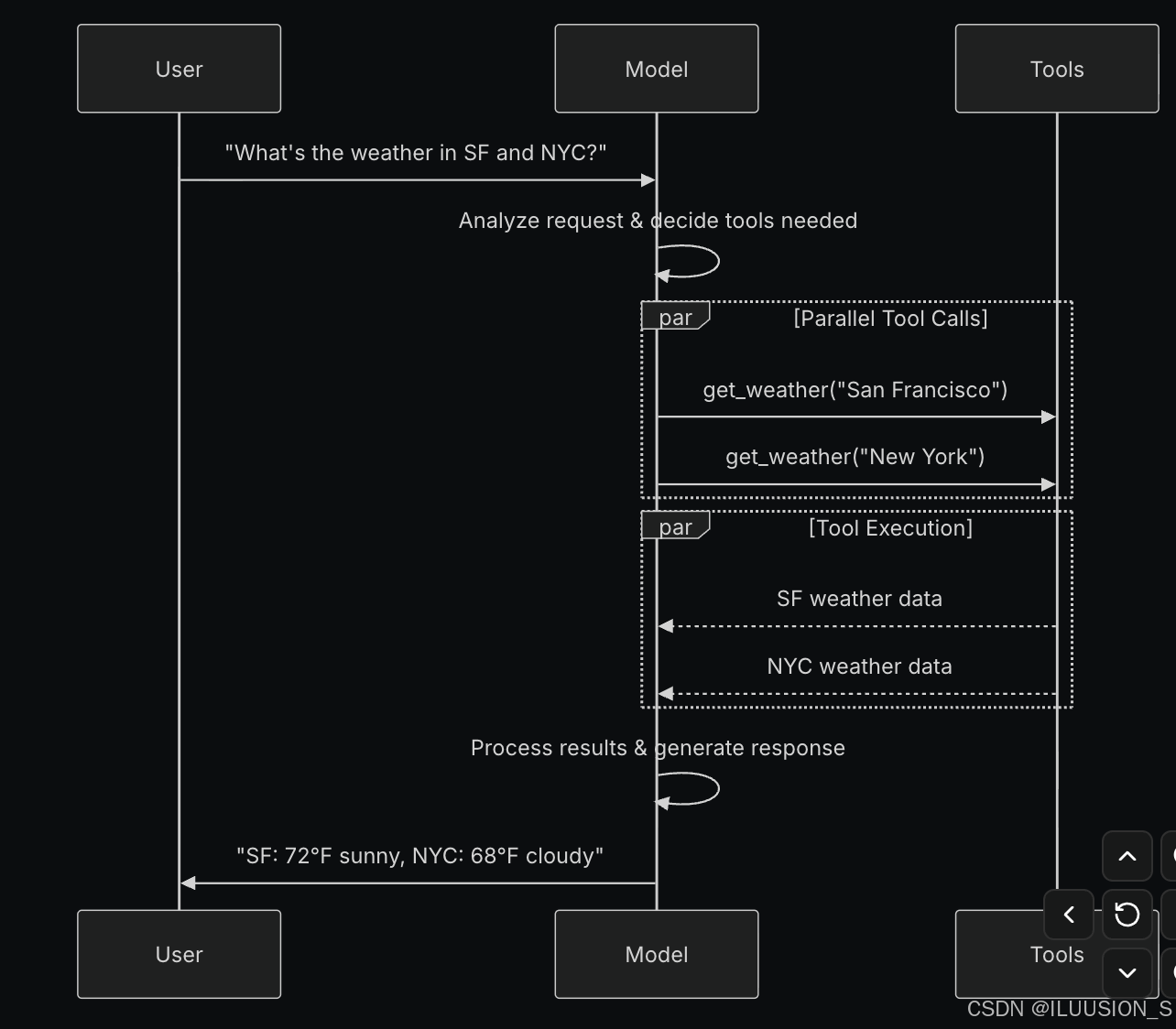
1.2 工具调用流程
用户输入 → 模型决策 → 工具调用 → 执行动作 → 返回结果
二、创建工具(函数)
2.1 创建基本工具
python
from langchain.tools import tool
@tool()
def get_weather(city:str) -> str:
"""
获取某个城市的天气信息
:param city: 城市名
:return: 天气信息
"""
return f"{city}的天气是阴天"使用tool装饰器装饰的函数,就是一个工具。
工具本身也可以像大模型一样,直接被invoke调用
python
res = get_weather.invoke('成都')
print(res)
"""
成都的天气是阴天
"""注意:
- 指定参数类型,以便模型理解使用。
- 文档说明,帮助模型理解工具的用途
- tool的description说明信息优先级 > 函数的文档描述信息 > args_schema
- 以下参数名称是保留的,不能用作工具参数:
| 参数名 | 目的 |
|---|---|
| config | 保留给内部工具 RunnableConfig |
| runtime | 保留给参数 ToolRuntime (访问状态、上下文、存储) |
2.2 通过model调用
通过bind_tools将模型与工具进行绑定。
python
model_with_tool = model.bind_tools([get_weather])
response = model_with_tool.invoke('获取成都的天气')
print(response)
"""
content='' additional_kwargs={'refusal': None} response_metadata={'token_usage': {'completion_tokens': 19, 'prompt_tokens': 97, 'total_tokens': 116, 'completion_tokens_details': {'accepted_prediction_tokens': None, 'audio_tokens': None, 'reasoning_tokens': 0, 'rejected_prediction_tokens': None}, 'prompt_tokens_details': None}, 'model_provider': 'openai', 'model_name': 'deepseek-ai/DeepSeek-V3', 'system_fingerprint': '', 'id': '019b96f2d49ee53d50563c7fd3068d23', 'finish_reason': 'tool_calls', 'logprobs': None} id='lc_run--019b96f2-cbfc-7d53-8a07-923539ec1990-0' tool_calls=[{'name': 'get_weather', 'args': {'city': '成都'}, 'id': '019b96f2dd095cb73042fe63a1784be1', 'type': 'tool_call'}] invalid_tool_calls=[] usage_metadata={'input_tokens': 97, 'output_tokens': 19, 'total_tokens': 116, 'input_token_details': {}, 'output_token_details': {'reasoning': 0}}
"""为什么返回内容是空?
- :bind_tools() 只是将工具与模型关联
- model_with_tool.invoke() 返回的是工具调用信息,不是工具执行结果
绑定用户自定义工具时,模型响应包含执行工具的请求 。当模型与智能体分离使用时,你需要执行请求的工具并将结果返回模型以供后续推理使用。使用代理时,代理循环会帮你处理工具的执行循环。
2.3 自定义工具属性
默认情况下,工具名称来源于函数名称。需要更具体描述时可以优先覆盖
例如之前直接调用时,tool_calls=[{'name': 'get_weather',...
自定义工具名称和描述
python
@tool('获取天气',description='获取城市的天气')
def get_weather(city:str) -> str:
"""
获取天气
:param city: 城市名
:return: 天气信息
"""
return f"{city}的天气是阴天"
model_with_tool = model.bind_tools([get_weather])
response = model_with_tool.invoke('获取成都的天气')
print(response)
"""
content='' additional_kwargs={'refusal': None} response_metadata={'token_usage': {'completion_tokens': 18, 'prompt_tokens': 85, 'total_tokens': 103, 'completion_tokens_details': {'accepted_prediction_tokens': None, 'audio_tokens': None, 'reasoning_tokens': 0, 'rejected_prediction_tokens': None}, 'prompt_tokens_details': None}, 'model_provider': 'openai', 'model_name': 'deepseek-ai/DeepSeek-V3', 'system_fingerprint': '', 'id': '019b96208576e3cd499071412fe88aef', 'finish_reason': 'tool_calls', 'logprobs': None} id='lc_run--019b9620-6f4f-76b0-b308-6bdcc889c84d-0'
tool_calls=[{'name': '获取天气', 'args': {'city': '成都'}, 'id': '019b96208a979f2ad4b4d75aad71bc4c', 'type': 'tool_call'}] invalid_tool_calls=[] usage_metadata={'input_tokens': 85, 'output_tokens': 18, 'total_tokens': 103, 'input_token_details': {}, 'output_token_details': {'reasoning': 0}}
"""tool_calls=[{'name': '获取天气'...
注意:
description 会覆盖自动生成的工具描述。
用 Pydantic 模型或 JSON 模式定义复杂输入
python
from pydantic import BaseModel, Field
from typing import Literal
class WeatherInput(BaseModel):
"""天气查询的输入。"""
location: str = Field(description="城市名称或坐标")
units: Literal["celsius", "fahrenheit"] = Field(
default="celsius",
description="温度单位偏好"
)
include_forecast: bool = Field(
default=False,
description="包含5天预报"
)
@tool(args_schema=WeatherInput)
def get_weather(location: str, units: str = "celsius", include_forecast: bool = False) -> str:
"""获取当前天气和可选预报。"""
temp = 22 if units == "celsius" else 72
result = f"{location}的当前天气: {temp} 度 {units[0].upper()}"
if include_forecast:
result += "\n未来5天: 晴朗"
return result三、ToolRuntime
LangChain 的 create_agent 在底层运行于 LangGraph 的运行时。LangGraph 会暴露一个包含以下信息的runtime对象:
- Context:静态信息,如用户 ID、数据库连接或其他代理调用的依赖关系
- Store:用于长期记忆的 BaseStore 实例
- Stream writer:通过 "自定义" 流模式用于流式信息流的对象
运行时上下文(runtime context)提供了一种方式,可以在运行时将依赖关系(如数据库连接、用户 ID 或配置)注入到工具中,使其更易测试和可复用。
在工具内部,可以通过 ToolRuntime 参数访问运行时信息
3.1 Context (上下文)
通过 runtime.context 访问不可变的配置和上下文数据,如用户 ID、会话细节或应用特定配置。
python
from dataclasses import dataclass
@dataclass
class City:
name: str
description: str
agent = create_agent(
model=model,
tools=[get_weather],
system_prompt="你是一位专业的天气预报员",
context_schema= City
)本来按照官网使用dataclass 来定义上下文模型,但是一直有波浪线,强迫症看着真不爽。可以改Pydantic的 BaseModel
- 原因 create_agent函数的context_schema参数期望接收TypedDict、BaseModel或None类型的值,但传入了dataclass类型的City类,类型不匹配导致报错。
- 修复建议 将dataclass类型的City改为Pydantic BaseModel类型,因为langchain的agent函数更兼容Pydantic模型作为上下文模式。
python
@tool('获取天气',description='获取城市的天气')
def get_weather(runtime:ToolRuntime) -> str:
print(runtime)
city = runtime.context.name
return f"{city}的天气是阴天"
response = agent.invoke(
{"messages":[
HumanMessage("今天天气如何")
]},
context=City(name="上海",description="描述信息")
)打个断点,可以查看runtime具体包含的内容,运行时传递的context内容,就在runtime.context中,state包含了messages消息列表,store存储,暂未用到
所以获取参数可以用 city = runtime.context.name 来获取,再得到结果

第二个完整例子:
python
import os
import dotenv
from dataclasses import dataclass
from langchain.tools import tool, ToolRuntime
from langchain.chat_models import init_chat_model
from langchain.agents import create_agent
dotenv.load_dotenv()
# 创建一个大模型交互对象
model = init_chat_model(
model=os.getenv("MODEL_NAME"),
model_provider="openai",
base_url=os.getenv("BASE_URL"),
api_key=os.getenv("API_KEY"),
)
USER_DATABASE = {
"user123": {
"name": "John",
"account_type": "SVIP",
"balance": 5000,
"email": "John@example.com"
}
}
# 定义上下文类型
@dataclass
class UserContext:
user_id: str
@tool
def get_account_info(runtime: ToolRuntime[UserContext]) -> str:
"""获取当前用户的账户信息。"""
# 从上下文中获取用户id
user_id = runtime.context.user_id
# 查找用户信息
if user_id in USER_DATABASE:
user = USER_DATABASE[user_id]
return f"账户持有人: {user['name']}\n类型: {user['account_type']}\n余额: ${user['balance']}"
return "用户未找到"
agent = create_agent(
model,
tools=[get_account_info],
context_schema=UserContext,
system_prompt="您是一个金融助手"
)
result = agent.stream(
{"messages": [{"role": "user", "content": "我现在的余额是多少?"}]},
# 通过上下文传递参数
context=UserContext(user_id="user123")
)
for item in result:
for key, value in item.items():
if key == "model":
print(f"执行步骤:调用大模型")
if value['messages'][0].content:
print(f"大模型分析的结果:{value["messages"][0].content}")
elif value['messages'][0].tool_calls:
print("大模型分析的结果为调用以下工具:")
for tool_ in value['messages'][0].tool_calls:
print(f"工具名称:{tool_['name']},调用用具的入参:{tool_['args']}")
elif key == "tools":
print(f"智能体执行工具:{value['messages'][0].name}")
print(f"工具执行结果:{value['messages'][0].content}")
"""
执行步骤:调用大模型
大模型分析的结果:我来帮您查询当前账户的余额信息。
智能体执行工具:get_account_info
工具执行结果:账户持有人: John
类型: SVIP
余额: $5000
执行步骤:调用大模型
大模型分析的结果:根据查询结果,您当前的账户信息如下:
- **账户持有人**: John
- **账户类型**: SVIP(超级VIP账户)
- **当前余额**: $5000
您的账户余额是5000美元。这个余额适用于您的SVIP账户类型。
"""3.2 Store(存储)
简单了解使用store,后面核心组件memery再介绍store
通过store访问跨对话的持久数据。该存储通过 runtime.store 访问,允许你保存和检索用户特定或应用特定的数据。工具可以通过 ToolRuntime 访问和更新存储
python
# 官网例子
from typing import Any
from langgraph.store.memory import InMemoryStore
# 访问内存
@tool
def get_user_info(user_id: str, runtime: ToolRuntime) -> str:
"""查找用户信息。"""
store = runtime.store
user_info = store.get(("users",), user_id)
return str(user_info.value) if user_info else "未知用户"
# 更新内存
@tool
def save_user_info(user_id: str, user_info: dict[str, Any], runtime: ToolRuntime) -> str:
"""保存用户信息。"""
store = runtime.store
store.put(("users",), user_id, user_info)
return "成功保存用户信息"
store = InMemoryStore()
agent = create_agent(
model,
tools=[get_user_info, save_user_info],
store=store
)
# 第一次会话:保存用户信息
res1 = agent.invoke({
"messages": [
HumanMessage("保存用户信息: 用户ID: abc123, 姓名: John, 年龄: 18")
]
})
print(res1)
# 第二次会话:获取用户信息
res2 = agent.invoke({
"messages": [{"role": "user", "content": "获取用户ID为'abc123'的用户信息"}]
})
print(res2)3.3 Stream Writer(流式写入)
用于自定义工具运行中输出的信息,实时反馈了解工具执行情况。
python
@tool
def get_account_info(runtime: ToolRuntime[UserContext]) -> str:
"""获取当前用户的账户信息。"""
writer=runtime.stream_writer
# 从上下文中获取用户id
user_id = runtime.context.user_id
writer(f"获取用户{user_id}的信息...")
# 查找用户信息
writer(f"正在查找用户{user_id}的信息...")
if user_id in USER_DATABASE:
user = USER_DATABASE[user_id]
writer(f"已找到用户{user_id}的信息")
return f"账户持有人: {user['name']}\n类型: {user['account_type']}\n余额: ${user['balance']}"
return "用户未找到"
......
result = agent.stream(
{"messages": [{"role": "user", "content": "我现在的余额是多少?"}]},
stream_mode='custom',
# 通过上下文传递参数
context=UserContext(user_id="user123")
)
for chunk in result:
print(chunk)想要获取自定义的内容,需要修改输出模式stream_mode为custom才行。
更多流式输出的内容,可以参考之前的文章流式输出部分