目录
[2.1 文件存储](#2.1 文件存储)
[2.2 元数据存储](#2.2 元数据存储)
[3.1 写操作](#3.1 写操作)
[3.2 读操作](#3.2 读操作)
[5.1 Federation联邦机制【解决NameNode内存受限问题】](#5.1 Federation联邦机制【解决NameNode内存受限问题】)
[5.2 HA高可用机制【解决NameNode单点故障问题】](#5.2 HA高可用机制【解决NameNode单点故障问题】)
1.系统架构
HDFS 是很典型的主从架构,主节点是NameNode,从节点是DataNode。
主节点NameNode一般用来做管理,他管理整个集群。主节点连接并管理各个从节点。同时也连接客户端,接受客户端发送来的读写请求。再一个是主节点的高可用HA(high available),高可用意味着主节点有一台管理节点,另外一台是备用节点,当前的管理节点状态是active,备用节点状态是standby,当active挂掉之后,standby就会变成active来接替整个集群管理。在实际的生产环境中,可以有多台standby来保证整个集群的可用性。
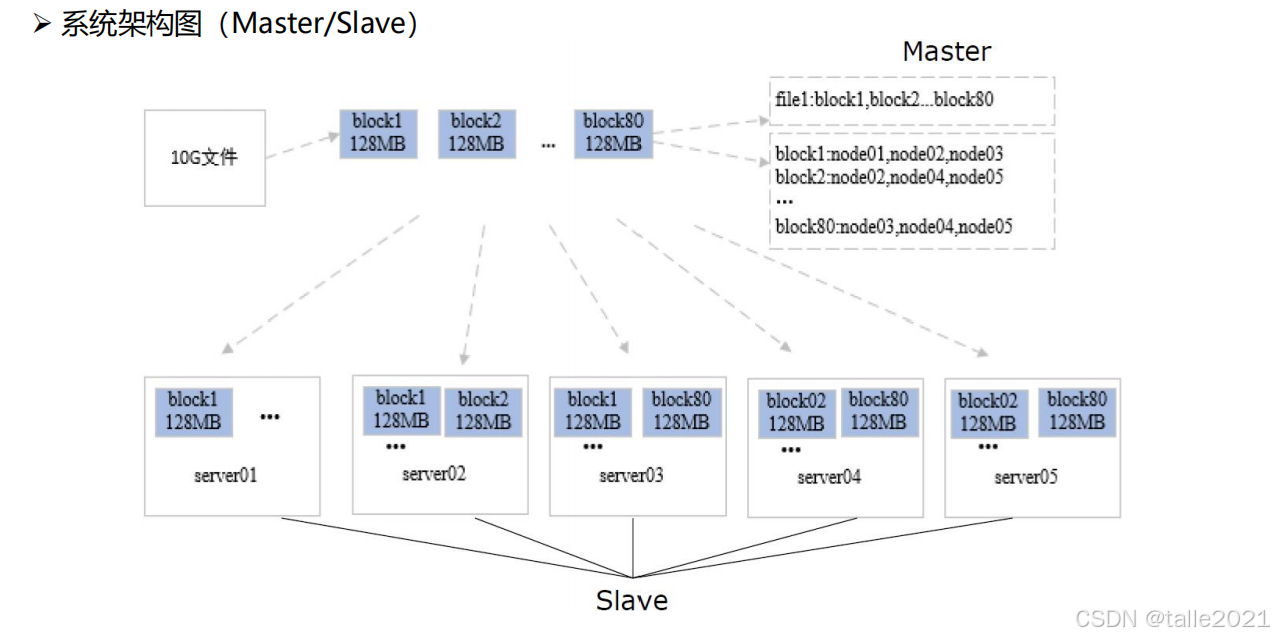
从节点DataNode用来做存储数据,一般一个文件会按照128M进行拆分成多个block块,拆分后的多个block块就存到DataNode节点。在存储的时候,为了保证数据的安全性,会在不同的节点做备份,如下图,不同的颜色就是不同的blcok,同种颜色的block备了三份,默认会有三个备份。万一某个节点挂掉之后,可以从其他节点进行数据恢复。
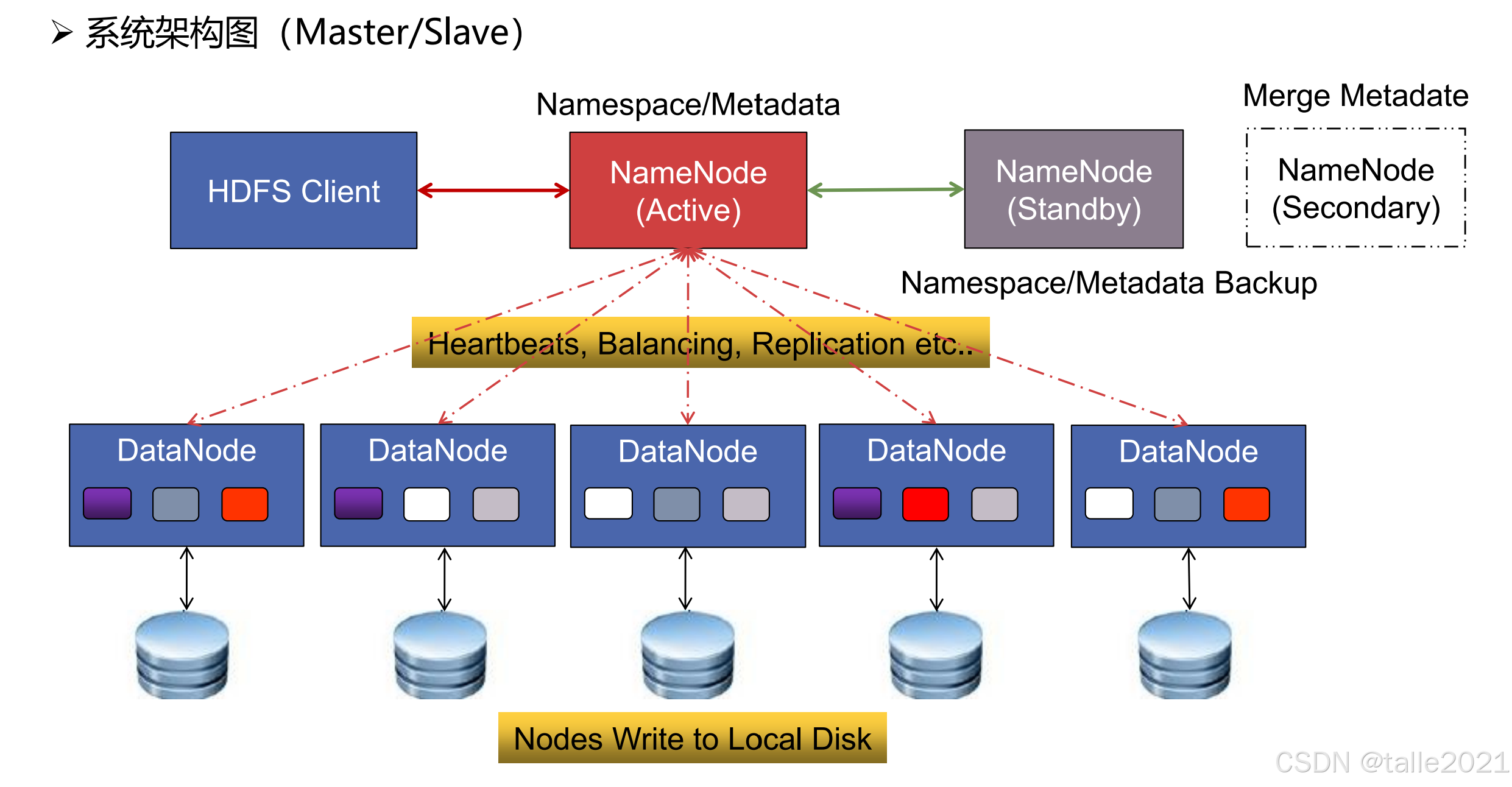
当客户端发起文件上传时,在上传之前,文件按照128M拆分成多个block块,再放到各个DataNode存储并备份,备份好之后NameNode就存储了一份元数据,元数据记录了上传的文件被分成多少个block块以及每个block小文件存在哪个DataNode。有了元数据信息,客户端可以通过元数据信息从各个DataNode找回每个block小文件并做合并。
在元数据信息中,重要的是上传的文件被分成多少个block块,而每个block小文件存在哪个DataNode并不重要,因为这部分信息会由DataNode定期向NameNode上报,除此之外,DataNode还会上报前的节点状态(繁忙/空闲状态)。如果NameNode发现某一个DataNode长时间没有上报,那么NameNode就默认这个DataNode挂掉了,然后触发容灾,即把这个DataNode之前存储的block小文件从其它DataNode拷贝出来再备份到其他DataNode,保证每个block小文件有三份备份,同时更新元数据信息。
2.存储机制
Block和元数据分开存储:Block存储于DataNode,元数据存储于NameNode。
2.1 文件存储
1)block多副本
block默认有3个副本 ,block以DataNode为存储单元,即一个DataNode只能存放block的·一个副本。在存储的过程中,尽量将副本存储到不同的机架上,提升数据的容错能力。DataNode的block副本数和访问负荷要比较接近,以实现负载均衡。
2)block大小
默认128M,block大小调整目标:①最小化寻址开销,降到1%以下;②任务并发度和集群负载比较适中,作业运行速度较快。块太大:Map任务太少,并发度太低,导致集群负载过低,作业变慢。块太小:①寻址时间占比过高;②Map任务太多,任务数太多,并发度太高,集群负载过高,作业调度时间长。
3)block副本存放机制
-
副本1:随机选择,优先空闲的DataNode节点
-对于Client在DataNode节点的,直接放置在当前节点
-
副本2:放在不同的机架节点上
-
副本3:放在与第二个副本同一机架的不同节点上
-
副本N:在遵循相关原则的前提下,随机选择
-节点选择原则:1.避免选择访问负荷太重的节点;2.避免选择存储太满的节点;3.避免将block的所有副本都放在同一机架上;4.同等条件下优先选择空闲节点。
4)block文件
Block文件是DataNode本地磁盘中名为"blk_blockId"的Linux文件,DataNode在启动时自动创建存储目录,无需格式化;DataNode的current目录下的文件名都以"blk_"为前缀。Block元数据文件(*.meta)由一个包含版本、类型信息的头文件和一系列校验值组成。
2.2 元数据存储
元数据(Metadata)存放在NameNode内存中,包含HDFS中文件及目录的基本属性信息(如所有者、权限信息创建时间等)、block相关信息(如文件包含哪些block、block存放在哪些节点等)、DataNode相关信息。其中"文件被拆分成多少个block块"这部分信息会持久化到磁盘并形成两个文件,分别是fsimage和edits。
在最开始的时候,元数据从内存持久化到磁盘,之后内存中元数据的修改变更都以日志的形式追加到edits,当NameNode挂掉之后,fsimage直接加载到内存,再把edits拉出来一条一条去执行,当所有edits执行完之后,元数据也就恢复成最新的。注意edits不能特别大,若edits太大在恢复元数据的过程中会导致NameNode假死,所以要定期对edits进行瘦身,即把edits定期合并到fsimage,让edits保持一个比较小的大小,这样恢复数据就很快。而把edits定期合并到fsimage是由Standby Namenode完成的,Standby Namenode除了充当热备节点之外,还充当了合并元数据的功能。当只有一台Namenode,没有热备节点时,把edits定期合并到fsimage就由Secondary Namenode来完成。
下图是元数据在本地磁盘的存储形式,在目录下有fsimage和edits,faimage有两个版本(最早和最新的),edits也有两版本0001-0019和inprogress(最新的),由于edits定期合并到fsimage,最终最新的元数据就是【faimage_0019】+【edits_progress_0020】
下图是edits合并到fsimage的流程图,集群中有多台Namenode,最开始的时候,所有Namenode的fsimage都是一致的,都是空的,而edits是不一致的,因此fsimage可以放在本地,edits不能放在本地,因为当NameNode挂掉之后就没办法获取edits。在HA高可用这种方案里,edits文件被放到一个三方集群JournalNode,JournalNode这个集群一般是奇数台组成,一般部署奇数(2n+1)个节点,最多容忍n个节点宕机,当过半(n+1)节点写入成功,即代表写操作完成。Active NameNode会随时把edits信息写到JournalNode进行保存,保证edits的可靠性。Standby Namenode也会随时起线程,在JournalNode把edits信息同步到本地并执行,再和fsimage做合并,形成新的fsimage,新的fsimage会定期把元数据写到磁盘里,同时推到Active NameNode,替换掉Active NameNode的fsimage,实现Standby Namenode与Active NameNode的元数据保持一致。Active NameNode替换掉fsimage之后,之前的edits就没有用了,Active NameNode会推送新的edits到JournalNode,如此循环......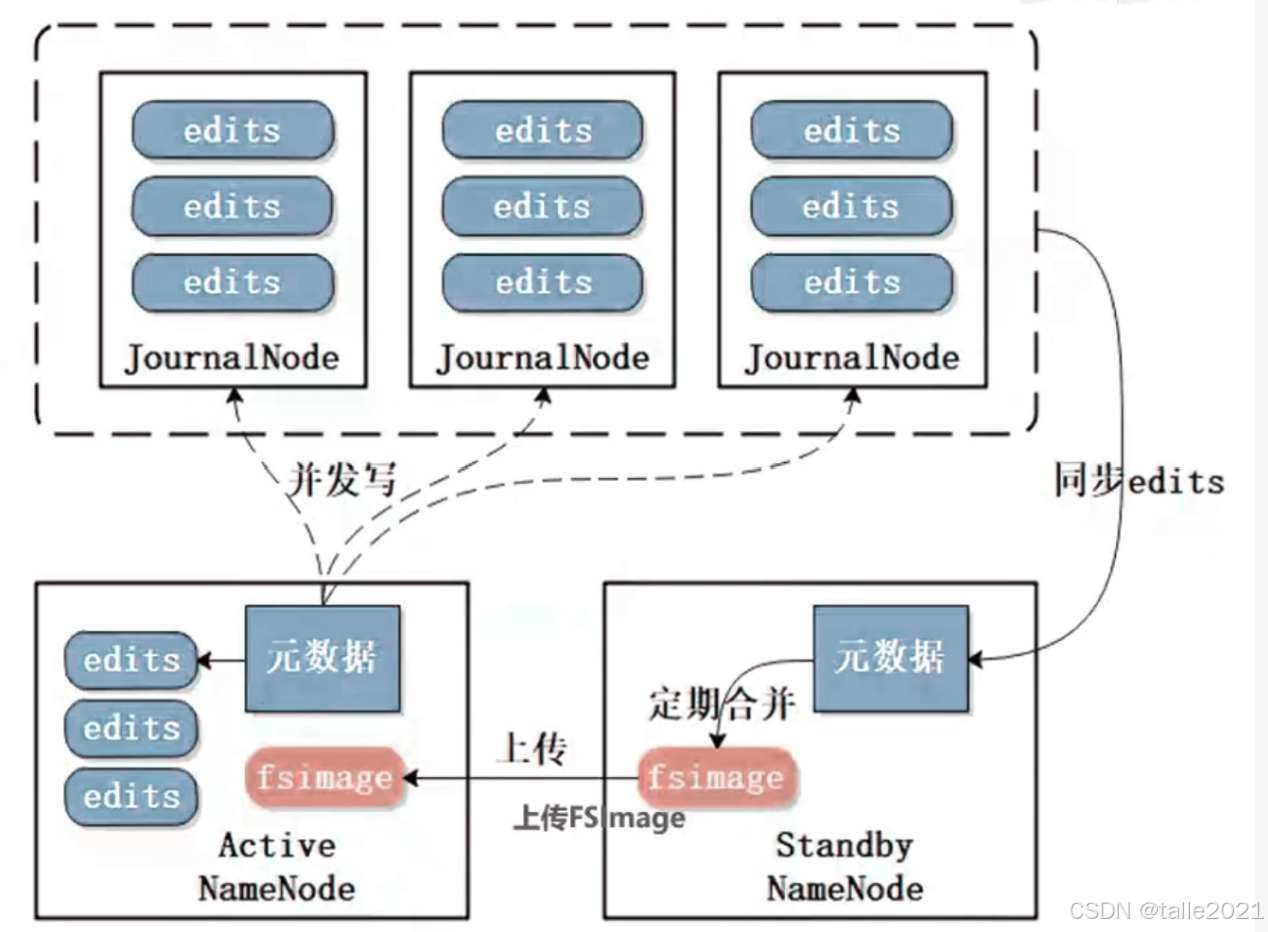
3.读写操作
3.1 写操作
下图是文件如何写到hdfs的流程图:
1)拆分数据:首先是客户端发起数据上传请求,请求就会发送到Namenote节点,Namenote就开始进行目录检查并鉴权,检查客户端对目录是否有权限,如果有权限就返回什么允许上传。客户端接到允许上传命令后就开始把文件按照128兆一块进行拆分。注意block块的拆分是在客户端进行的,它与HDFS的主节点没有任何关系。
2)建立通道:数据文件拆分后,首先上传第一个block,Namenote按照副本分配策略:第一个副本找最近的节点,如果没有最近的就找最空闲的节点。第二个副本会找其他机架的最空闲的一个节点啊,第三个副本找与第二个副本相同机架的最空闲节点,当三个DataNode找到之后,就把这三个DataNode信息返回给客户端,客户端就与这3个DataNode以pipeline的形式建立一个通道连接的。它先与第一个DataNode建立连接,之后又连接到第二个DataNode上,然后再通过通道连接到第三个DataNode上,这样三个DataNode就以一个通道的形式全部串成了一条。
3)数据发送:接下来就以package数据包进行发送,数据先发送到第一个DataNode上,第一个DataNode接收到数据之后,先是放到内存里面,内存接收到block数据后,再往磁盘里面写,同时把这个block数据通过pipeline通道发送到第二个DataNode里。第二个DataNode也是内存先接收再往磁盘里面写,同时发送到第三个DataNode里,当第三个DataNode把内存中的这个block数据持久化到磁盘里之后,就会向第二个DataNode返回已经写入成功了,那当第二个DataNode接收到上一个DataNode返回的成功信息,而且它本身的这个block数据也写到本地的磁盘里后,它又向第一个DataNode返回success成功信息。第一个DataNode接收到成功信息后,本地的文件也写到磁盘里了,就向客户端返回第一个block写入成功,且3个副本都备份好了。
4)元数据生成:接下来就要开始上传第二个block数据,第二个block也是以相同的一个规则,当所有block数据全部上传,客户端就向Namenote返回全部写入成功了,Namenote把原数据记录起来,最后它才在内存里面生成元数据,元数据包括文件名、被拆分成了多少个block块、每个block存在哪些节点,这个时候原数据才真正的生成。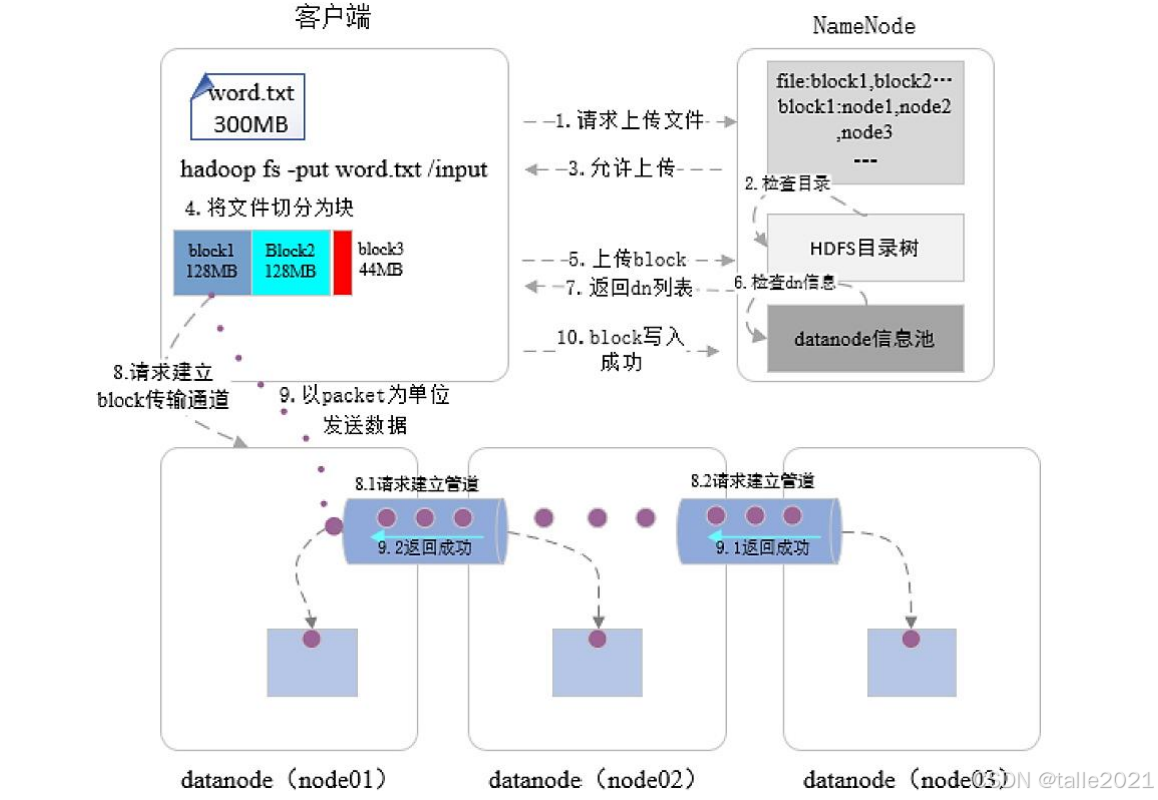
3.2 读操作
首先客户端发起一个读文件的请求,Namenote接收到请求,先检查目录并鉴权,如果有权限就返回元数据信息,元数据返回的时候,会对每个block块所在的这3个DataNode进行了排序,与客户端网络拓扑是最近的放在第一个,比较远的依次往后排,这样的开销是最小的。客户端拿到元数据信息之后就与每一个block块所在的DataNode进行连接,建立连接之后就把我各个block块读回来,全部读回来之后再进行一个block块数据的合并,合并成最终的文件并返回。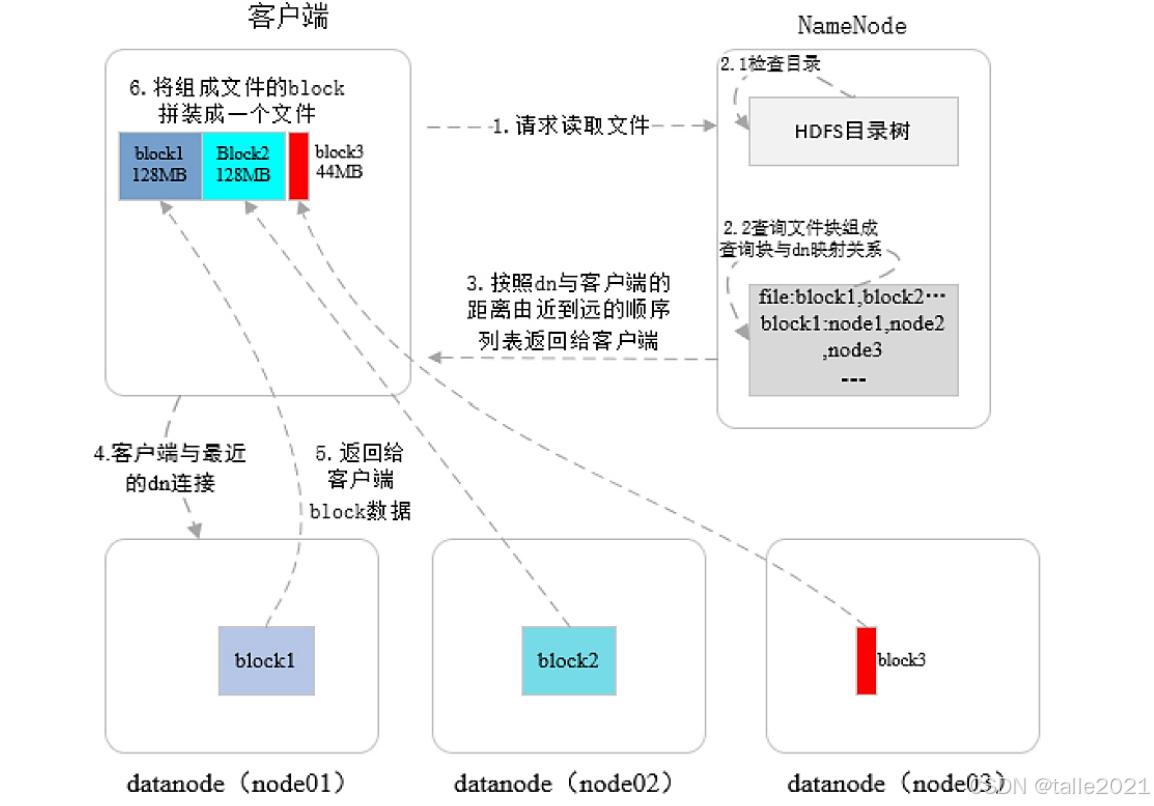
4.安全模式
安全模式是HDFS的一种特殊状态,在这种状态下,HDFS只接收读数据请求,而不接收写入、删除、修改等变更请求。安全模式是HDFS确保Block数据安全的一种保护机制,当Active NameNode启动时,HDFS会进入安全模式,DataNode主动向NameNode汇报可用Block列表等信息,在系统达到安全标准前,HDFS一直处于"只读"状态。当Block上报率(Block上报率=DataNode上报的可用Block个数/NameNode元数据记录的Block个数)>=阈值时,HDFS才能离开安全模式,默认阈值为0.999。
触发安全模式的原因:
-
NameNode重启
-
NameNode磁盘空间不足
-
Block上报率低于阈值
-
DataNode无法正常启动
-
日志中出现严重异常
-
用户操作不当,如:强制关机
5.高可用
5.1 Federation联邦机制【解决NameNode内存受限问题】
联邦机制是Hadoop 2.x中提出的解决NameNode内存受限问题的的水平横向扩展方案。联邦机制是一台NameNode有内存受限上限这个问题,那就使用多台NameNode组成联邦共同进行集群的管理。假设有30个目录,3台NameNode,那么一台NameNode管理10个数据目录,这样就可以组成联邦共同管理集群,降低NameNode内存占满的几率。
5.2 HA高可用机制【解决NameNode单点故障问题】
High Availability高可用机制是Hadoop 2.x中提出的解决NameNode单节点故障问题的方案,即集群至少提供两台NameNode做热备:Active、Standby,当一台NameNode宕机,另外一台NameNode需要保持元数据一致(fsimage、edits),并且完成状态切换。其中journal集群保证元数据一致,ZooKeeper集群负责状态切换。
当Active NameNode挂掉之后,他的状态由Active变成Standby是是由ZooKeeper集群来完成的。ZooKeeper是做分布式协调服务的,它会启动多个进程(FailoverController),FailoverController Active的监控Active节点,FailoverController Standby的监控Standby节点。FailoverController这个进程也会通过心跳机制定期与ZooKeeper汇报。当Active NameNode挂掉之后,FailoverController Active进程的通信就断掉了,FailoverController发现Active进程挂掉之后向ZooKeeper汇报,于是ZooKeeper就会把Active这个状态切换成Standby,再从其他的Standby节点里选一个作为Active主节点即Standby状态切换成Active, 实现同步元数据后的集群接管。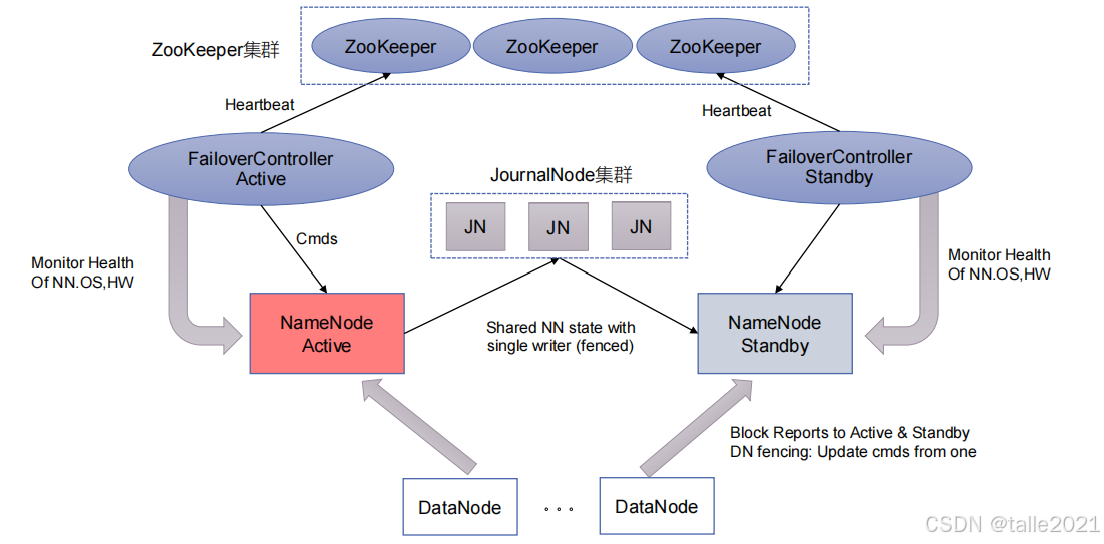
6.HDFS优缺点
优点:
-
海量数据存储(典型文件大小GB~TB,百万以上文件数量, PB以上数据规模)
-
高容错(多副本策略)、高可用(HA,安全模式)、高扩展(10K节点规模)
-
构建成本低、安全可靠(构建在廉价商用机器上,提供容错机制)
-
适合大规模离线批处理(流式数据访问,数据位置暴露给计算框架)
缺点:
-
不适合低延迟数据访问
-
不适合大量小文件存储(元数据占用NameNode大量空间,移动计算时任务数量增加)
-
不支持并发写入
-
不支持文件随机修改(仅支持追加写入)