二 HTTP 概述
2.1 概述
http请求或响应都有一个头部和一个可选的payload组成。头部包含URL或响应码,后跟一个头部字段列表。
2.2 示例
netcat命令
bash
nc baidu.com 80nc(netcat)命令会创建一个到目标主机和端口的 TCP 连接,然后将该连接附加到标准输入和标准输出。
然后输入
bash
@111 ~ % nc example.com 80
GET / HTTP/1.0
Host:example.com
(空行)会看到输出:
bash
HTTP/1.0 200 OK
Accept-Ranges: bytes
Content-Type: text/html
ETag: "bc2473a18e003bdb249eba5ce893033f:1760028122.592274"
Last-Modified: Thu, 09 Oct 2025 16:42:02 GMT
Content-Length: 513
Cache-Control: max-age=86000
Date: Sun, 07 Dec 2025 10:24:34 GMT
Connection: close
<!doctype html><html lang="en"><head><title>Example Domain</title><meta name="viewport" content="width=device-width, initial-scale=1"><style>body{background:#eee;width:60vw;margin:15vh auto;font-family:system-ui,sans-serif}h1{font-size:1.5em}div{opacity:0.8}a:link,a:visited{color:#348}</style><body><div><h1>Example Domain</h1><p>This domain is for use in documentation examples without needing permission. Avoid use in operations.<p><a href="https://iana.org/domains/example">Learn more</a></div></body></html>解释
1.请求的第一行 GET / HTTP/1.0 包含 HTTP 方法 GET 、URI是 ' / ' 和 HTTP 版本 1.0 。
2.第一行之后是头部字段列表,格式如下: Key: value 。请求只有一个头部字段 Host,他包含着域名。
3.响应头之后是payload,在本例中是一个 HTML 文档。payload和响应头之间用空行分隔。GET 请求没有payload,因此以空行结尾。
2.3 http版本
- HTTP/1.0:原型
HTTP/1.0 完全不支持通过单个连接发送多个请求,每个请求都需要一个新的连接。然后HTTP/1.1 解决了这个问题。 - HTTP/1.1:可用于生产环境且易于理解
HTTP 为何如此流行?一个可能的原因是它可以作为通用的请求-响应协议;开发者可以依赖 HTTP,而无需自行开发协议。 - HTTP/2:新特性
(1)服务器推送 ,即在客户端请求资源之前就将资源发送给客户端。
(2)通过单个 TCP 连接复用多个请求,这是为了解决队头阻塞问题 。 - HTTP/3:更大的雄心
HTTP/3 比 HTTP/2 大得多。它取代了 TCP,转而使用 UDP。因此,它需要复制 TCP 的大部分功能,这种 TCP 替代方案被称为 QUIC。QUIC 的设计初衷是为了实现用户空间拥塞控制、多路复用和队头阻塞。
2.4 命令行工具
1.将请求数据存储在文件中,再发送请求。
bash
nc example.com 80 <request.txt2.当遇到 nc 命令的一些特殊情况,例如不发送 EOF,或多个版本 nc 使用了不兼容的标志。可以改用现代的socat。
bash
socat tcp:example.com:80 -3.telnet 命令在教程中也很常见。
bash
telnet example.com 804.也可以使用现有的 HTTP 客户端,而不是手动构建请求数据。试试 curl 命令
bash
curl -vvv http://example.com/三.编写 TCP 服务器
3.1 TCP 快速回顾
协议层

IP数据包包括:
- 发件人地址
- 收件人地址
- 消息数据
tcp层字节流:
字节流是有序的字节序列。协议用于理解这些字节。协议类似于文件格式,不同之处在于总长度未知,且数据一次性读取完毕。
TCP 字节流与 UDP 数据包
udp和tcp处于同一层,但仍然像底层一样基于数据包。udp只是在数据包上添加了端口号。
两者关键区别:boundaries(界限)
udp:每次从套接字读取数据,都对应一个从对等节点写入。
tcp:不存在这种对应关系!数据是连续的字节流。
tcp没有保留界限的机制。
1.tcp发送缓冲区:数据在传输前存储于此。多次写入操作与单次写入操作无法区分。
2.数据被封装成一个或多个IP数据包,IP边界与原始写入边界无关。
3.tcp接收缓冲区:数据到达后即可供应用程序使用。
注:初学者最易犯的错误是"连接和拆分tcp数据包",因为根本不存在所谓的"tcp packets"。协议需要通过在字节流中设置边界来解释tcp数据。
字节流与数据包:以DNS为例
DNS协议:域名到IP地址查找。
DNS服务基于UDP协议运行。客户端发送单个请求,服务器以单个响应消息进行响应。DNS消息封装在UDP数据包中。

由于基于数据包的协议存在一些缺陷,例如无法使用大量消息,所以DNS也被设计成在TCP上运行。
但TCP本身并不理解"消息"的概念,因此在通过TCP传输DNS消息时,会在每条DNS消息前添加一个2字节的长度字段,以便服务器或客户端识别字节流中各消息的所属部分。这个2字节长度字段正是TCP之上应用协议的最简单示例。该协议允许在单个TCP字节流中承载多条应用消息(如DNS消息)。
| len1 | msg1 | len2 | msg2 | ...
TCP 以握手开始
建立TCP连接时,需要存在客户端和服务器端(忽略同时存在的情况)。服务器在特定地址(IP+端口)等待客户端连接,此步骤称为绑定与监听。随后客户端可连接至该地址。连接操作涉及三步握手(SYN、SYN-ACK、ACK),但这不属于我们的关注范围,因为操作系统会透明地完成该过程。待操作系统完成握手后,服务器即可接受连接。
TCP 是双向全双工的
TCP 连接一旦建立,即可作为双向字节流使用,每个方向拥有两个通道。许多协议采用请求-响应模式,如HTTP/1.1,此时对等方要么发送请求/响应,要么接收响应/请求。但TCP并不局限于此种通信模式。每个对等方可同时发送和接收数据(例如WebSocket),这种模式称为全双工通信。
TCP 以两次握手结束
对等方通过 FIN 标志告知另一方将停止发送数据,另一方随后确认 FIN 标志。远程应用程序在从通道读取数据时会收到终止通知。
通道的每个方向都可以独立终止,因此另一方也执行相同的握手以完全关闭连接。
3.2 套接字原语
不同语言和库中,Socket API 的形式各不相同。
应用程序通过不透明的操作系统句柄引用套接字
创建 TCP 连接时,连接由操作系统管理,您可以使用套接字句柄在套接字 API 中引用该连接。在 Linux 系统中,套接字句柄就是一个文件描述符 (fd)。在 Node.js 中,套接字句柄被封装成带有方法的 JavaScript 对象。
任何操作系统句柄都必须由应用程序关闭,才能终止底层资源并回收该句柄。
监听套接字 & 连接套接字
TCP 服务器监听特定的地址(IP 地址 + 端口),并接受来自该地址的客户端连接。监听地址也用套接字句柄表示。当接受新的客户端连接时,您将获得该 TCP 连接的套接字句柄。
套接字句柄有两种类型:
- 监听套接字。通过监听地址获得。
- 连接套接字。通过接受来自监听套接字的客户端连接而获得。
传输结束
发送和接收也称为读取和写入 。对于写入操作,可以通过一些方法告知对端不再发送任何数据。
- 关闭套接字会终止连接并发送 TCP FIN 消息。关闭任何类型的句柄也会回收该句柄本身。(句柄一旦被回收,就无法再对其进行任何操作。)
- 你也可以关闭自身传输端(同时发送FIN),但仍能接收来自对等方的数据;这种状态称为半开连接,后续将对此进行详细说明。
对于读取端,存在多种方式可知晓对等方何时结束传输(收到FIN)。传输结束通常被称为 文件结束 (EOF)。
套接字原语列表
-
Listening socket:
bind & listen
accept
close -
Connection socket:
read
write
close
3.3 Node.js 中的 Socket API
通过一个简单的练习来介绍套接字 API:实现一个从客户端读取数据并原样写回的TCP服务器,即"回显服务器"。
步骤 1:创建监听套接字(Create A Listening Socket)
javascript
// 所有网络相关功能都在 net 中
import * as net from "net";不同类型的套接字都用 JS 对象表示。 net.createServer() 函数创建一个监听套接字,其类型为 net.Server 。
net.Server 具有一个 listen() 方法用于绑定并监听地址。
javascript
let server = net.createServer();
server.listen({host:'127.0.0.1', port: 1234});步骤二:接受新连接(Accept New Connections)
接下来是用于获取新连接的accept原语。遗憾的是,没有一个简单的accept()函数能直接返回连接。
这里需要了解JS中IO处理的背景知识:JS有两种IO处理方式,第一种是使用回调函数;你请求执行某项操作并向运行时注册回调函数,当操作完成时回调函数就会被调用。
javascript
function newConn(socket: net.Socket): void{
console.log('new connection', socket.remoteAddress, socket.remotePort);
// ...
}
let server = net.createServer();
server.on('connection', newConn);
server.listen({host:'127.0.00.1', port: 1234});在上面的代码清单中, server.on('connection', newConn) 注册回调函数 newConn 。运行时会自动执行 accept 操作,并将新连接作为 net.Socket 类型的参数传递给回调函数。此回调函数只需注册一次,但每次建立新连接时都会被调用。
步骤 3:错误处理
'connection'参数称为事件,可用于注册回调。监听套接字还存在其他事件,例如发生错误时触发的'error'事件。
javascript
server.on('error', (err: Error) => { throw err; });这里我们直接抛出异常并终止程序。你可以通过在相同的地址和端口上运行两台服务器来测试这一点,第二台服务器将会失败。
步骤 4: Read and Write
通过连接接收的数据也会通过回调函数传递。 从套接字读取数据的相关事件是: 'data' 事件和 'end' 事件。 当从对等方收到数据时,会触发 'data' 事件;当对等方结束传输时,会触发 'end' 事件。
javascript
socket.on('end', () => {
// FIN received. The connection will be closed automatically.
console.log('EOF.');
});
socket.on('data', (data: Buffer) => {
console.log('data:', data);
socket.write(data); // echo back the data.
});socket.write() 方法将数据发送回对端。
步骤 5:关闭连接
socket.end() 方法会结束传输并关闭套接字。这里,当数据包含字母"q"时,我们会调用 socket.end() ,以便轻松测试这种情况。
javascript
socket.on('data', (data: Buffer) => {
console.log('data:', data);
socket.write(data); // echo back the data.
// actively closed the connection if the data contains 'q'
if (data.includes('q')) {
console.log('closing.');
socket.end(); // this will send FIN and close the connection.
}
});当任一端终止传输时,运行时会自动关闭套接字。net.Socket还存在报告IO错误的'error'事件,该事件同样会触发运行时关闭套接字。
第六步:测试
回声服务器的完整代码:
javascript
import * as net from "net";
function newConn(socket: net.Socket): void {
console.log('new connection', socket.remoteAddress, socket.remotePort);
socket.on('end', () => {
// FIN received. The connection will be closed automatically.
console.log('EOF.');
});
socket.on('data', (data: Buffer) => {
console.log('data:', data);
socket.write(data); // echo back the data.
// actively closed the connection if the data contains 'q'
if (data.includes('q')) {
console.log('closing.');
socket.end(); // this will send FIN and close the connection.
}
});
}
let server = net.createServer();
server.on('error', (err: Error) => { throw err; });
server.on('connection', newConn);
server.listen({host: '127.0.0.1', port: 1234});通过运行以下命令启动回显服务器 node --enable-source-maps echo_server.js 。然后使用 nc 或 socat 命令进行测试。
3.4 讨论:半开放式连接(Half-Open Connections)
TCP 连接的每个方向都是独立结束的,因此可以利用一个方向已关闭而另一个方向仍然打开的状态;这种 TCP 的单向使用方式称为 TCP 半开。
例如,如果对等方 A 半关闭与对等方 B 的连接:
- A 无法再发送任何数据,但仍然可以从 B 接收数据。
- B 收到 EOF,但仍然可以向 A 发送邮件。
很少有应用程序会利用这一点。大多数应用程序将文件结束符 (EOF) 视为被对端完全关闭,也会立即关闭套接字。
用于此操作的套接字原语是 shutdown。
Node.js 中的套接字默认不支持半开模式,当任何一方发送或接收到文件结束符 (EOF) 时都会自动关闭。要支持 TCP 半开模式,需要一个额外的标志。
javascript
let server = net.createServer({ allowHalfOpen: true});当启用 allowHalfOpen 标志时,您将负责关闭连接,因为 socket.end() 将不再关闭连接,而只会发送 EOF。
请使用 socket.destroy() 手动关闭套接字。
3.5 讨论:事件循环与并发
JS 代码在事件循环内运行
运行时会轮询操作系统发送的 I/O 事件,例如新连接到达、套接字准备就绪或定时器到期。然后,运行时会对这些事件做出响应,并调用程序员之前注册的回调函数。所有事件处理完毕后,这个过程会重复进行,因此被称为事件循环 。
JS 代码和运行时(Runtime)共享同一个操作系统线程
事件循环是单线程的 ;执行要么在运行时代码上进行,要么在 JavaScript 代码上进行(回调或主程序)。这是因为当回调返回或 await 时,控制权会返回到运行时,因此运行时可以发出事件并调度其他任务。这意味着任何 JavaScript 代码都应该在短时间内完成, 因为执行 JavaScript 代码时事件循环会暂停。
Node.js 中的并发是基于事件的
一个服务器可以同时拥有多个连接,每个连接都可以发出事件。
事件处理程序运行时,单线程运行时无法处理其他连接,直到处理程序返回为止。处理事件的时间越长,其他所有操作的延迟时间就越长。
3.6 讨论:异步与同步
阻塞式和非阻塞式 I/O
避免在事件循环中停留过久至关重要。运行 CPU 密集型代码是导致这种情况发生的一个原因。这个问题可以通过以下方式解决:
- 主动让步于运行时环境。
- 通过多线程或多进程将 CPU 密集型代码移出事件循环
这些主题超出了本书的范围,我们主要关注的是 IO。
操作系统为网络 I/O 提供阻塞模式和非阻塞模式:
- 在阻塞模式下,调用操作系统的线程会阻塞,直到结果准备就绪。
- 在非阻塞模式下,如果结果尚未准备就绪(或已准备就绪),操作系统会立即返回,并且有一种方法可以收到准备就绪的通知(对于事件循环)。
Node.js 运行时使用非阻塞模式,因为阻塞模式与基于事件的并发不兼容。事件循环中唯一的阻塞操作是在没有事件可做时轮询操作系统以获取更多事件。
Node.js 中的 I/O 是异步的
大多数与 I/O 相关的 Node.js 库函数都是基于回调或 Promise 的。Promise 可以看作是管理回调的另一种方式。它们也被称为异步函数 ,这意味着结果通过回调函数传递。这些 API 不会阻塞事件循环,因为 JS 代码不会等待结果;相反,JS 代码会返回到运行时,当结果准备就绪时,运行时会调用回调函数来继续执行程序。
与此相反的是同步 API,它会阻塞调用操作系统的线程以等待结果。例如,我们来看一下 fs 模块的文档,文件 API 提供了所有这三种类型 。
javascript
// promise
filehandle.read([options]);
// callback
fs.read(fd[, options], callback);
// synchronous, do not use!
fs.readSync(fd, buffer[, options]);同步 API 不适用于网络应用程序,因为它会阻塞事件循环。它仅用于一些完全不依赖事件循环的简单用例(例如脚本编写)。
超越网络通信的事件驱动编程
I/O 不仅仅是磁盘文件和网络通信。在图形用户界面 (GUI) 系统中,用户通过鼠标和键盘输入的内容也属于 I/O。事件循环并非 Node.js 运行时独有;Web 浏览器和所有其他 GUI 应用程序底层也都使用了事件循环。您可以将 GUI 编程经验应用到网络编程中,反之亦然。
3.7 讨论:Promise-Based IO
正如我们之前提到的,还有另一种编写IO代码的风格。替代方案采用Promise替代回调函数。基于Promise的API优势在于,你可以通过await等待结果,从而避免将程序拆解成散落各处的微小回调函数。
假设基于Promise的accept原语API如下所示:
javascript
// pseudo code!
while (running) {
let socket = await server.accept();
newConn(socket); // no `await` on this
}而读写原语的假设API则如下所示:
javascript
// pseudo code!
async function newConn(socket) {
while (true) {
let data = await socket.read();
if (!data) {
break; // EOF
}
await socket.write(data);
}
}上述伪代码看似是同步的,但并没有阻塞事件循环。虽然目前来看,由于我们的程序非常简单,这种做法的优势可能并不明显。
部分 Node.js API(但并非全部)同时提供基于回调和基于 Promise 的实现方式。不过,通过一些努力,基于回调的 API 可以转换为基于 Promise 的实现方式,我们将在下一章中看到这一点。
04. Promises and Events
4.1 async 和 await 简介
使用回调函数
基于回调的 API 示例。应用程序逻辑在回调函数中继续执行。
javascript
function my_app() {
do_something_cb((err, result) => {
if (err) {
// fail.
} else {
// success, use the result.
}
});
}使用 Promise 和 await
在 Promise 上使用 await 的示例。应用程序逻辑在同一个 async 函数中继续执行
javascript
function do_something_promise(): Promise<T>;
async function my_app() {
try {
const result: T = await do_something_promise();
} catch (err) {
// fail.
}
}优点:应用程序逻辑没有被拆分成多个函数。
创造 Promises
创建 Promise 的示例:将基于回调的 API 转换为基于 Promise 的 API
javascript
function do_something_promise() {
return new Promise<T>((resolve, reject) => {
do_something_cb((err, result) => {
if (err) {
reject(err);
} else {
resolve(result);
}
});
});
}在 JavaScript 中,回调是不可避免的。创建 Promise 对象时, 执行器回调函数作为参数传递,以接收另外两个回调函数:
- resolve() 函数会使 await 语句返回一个值。
- reject() 会导致 await 语句抛出异常。
当结果可用或操作失败时,您必须调用其中一个回调函数。这可能发生在执行器函数之外,因此您可能需要将这些回调函数存储在某个地方。
promises术语
Fulfilled: 调用了 resolve()
Rejected: 调用了 reject()
Settled: 要么已执行,要么已拒绝
Pending: 尚未解决
4.2 理解 async 和 await
普通函数通过 return 将结果交给运行时。
JavaScript 函数分为两种类型:普通函数和异步函数。
普通函数从开始执行直至返回(无论是显式还是隐式返回)。由于 JavaScript 运行时是单线程且基于事件的,因此无法在 JavaScript 中执行阻塞式 I/O 操作。取而代之的是,你需要注册回调函数来处理 I/O 操作的完成,随后 JavaScript 代码便会结束执行。当代码返回运行时环境后,运行时会轮询事件并调用回调函数------这正是我们之前提到的事件循环!
async 函数通过 await 将结果交给运行时。
最初, Promise 类型只是管理回调函数的一种方式。它允许链式调用多个回调函数,而无需嵌套过多的函数。然而,由于 async 函数的引入,我们将不再讨论 Promise 的这种用法。
不同于普通函数,异步函数可在执行中途返回运行时------当你对 Promise 使用 await 语句时就会发生这种情况。当 Promise 结算时,async 函数会带着 Promise 的结果继续执行。这种编码体验更优越,因为你可以在同一个函数中编写顺序 I/O 代码,而不会被回调中断。
调用 async 函数会启动新任务
调用 async 函数会生成一个 Promise,该 Promise 在async函数返回或抛出异常时自动完成。你可以像处理普通 Promise 那样使用 await 等待其完成,但即使不等待,运行时仍会将异步函数排入执行队列。这类似于多线程编程中启动线程的行为。但所有 JavaScript 代码共享单个操作系统线程,因此更准确的说法是任务(task)。
在不同环境下启动任务(task)的方法列表:
- 在 JavaScript 中,启动后台任务不需要等待 Promise 完成。
- 在 Go 语言中,您可以使用 go 语句。
- 在 Python 中, async/await 与 JS 类似,只是你需要自己运行事件循环,因为它不是语言内置的功能。
- 在没有事件循环的环境中,您可以启动操作系统线程而不是用户级任务。
4.3 从Events到Promises
net 模块没有提供基于 Promise 的 API,所以我们必须实现上一章中假设的 API。
javascript
function soRead(conn: TCPConn): Promise<Buffer>;
function soWrite(conn: TCPConn, data: Buffer): Promise<void>;第一步:分析解决方案
soRead 函数返回一个 Promise,该 Promise 会使用套接字数据进行解析。它依赖于 3 个事件。
- 'data' 事件会触发 Promise 的完成。
- 读取套接字时,我们还需检测是否到达文件末尾(EOF)。因此'end'事件同样会完成该Promise。常见的EOF指示方式是返回零长度数据。
- 此外还存在'error'事件,此时必须拒绝Promise,否则该Promise将永远处于悬挂状态。
为了解决或拒绝这些事件中的 Promise,必须将 Promise 存储在某个地方。为此,我们将创建 TCPConn 包装对象。
javascript
// A promise-based API for TCP sockets.
type TCPConn = {
// the JS socket object
socket: net.Socket;
// the callbacks of the promise of the current read
reader: null|{
resolve: (value: Buffer) => void,
reject: (reason: Error) => void,
};
};promise 的 resolve 和 reject 回调存储在 TCPConn.reader 字段中。
步骤 2:处理"data"事件
这里存在一个问题:'data'事件会在每次有数据时触发,但 promise 仅在程序读取套接字时存在。因此必须存在控制'data'事件触发时机的方法。
javascript
socket.pause(); // pause the 'data' event
socket.resume(); // resume the 'data' event有了这些知识,我们现在可以实现 soRead 功能。
javascript
// create a wrapper from net.Socket
function soInit(socket: net.Socket): TCPConn {
const conn: TCPConn = {
socket: socket, reader: null,
};
socket.on('data', (data: Buffer) => {
console.assert(conn.reader);
// pause the 'data' event until the next read.
conn.socket.pause();
// fulfill the promise of the current read.
conn.reader!.resolve(data);
conn.reader = null;
});
return conn;
}
function soRead(conn: TCPConn): Promise<Buffer> {
console.assert(!conn.reader); // no concurrent calls
return new Promise((resolve, reject) => {
// save the promise callbacks
conn.reader = {resolve: resolve, reject: reject};
// and resume the 'data' event to fulfill the promise later.
conn.socket.resume();
});
}由于 'data' 事件会在读取套接字之前暂停,因此套接字在创建后默认应该暂停。有一个标志可以实现这一点。
javascript
const server = net.createServer({
pauseOnConnect: true, // required by `TCPConn`
});通过 pause() / resume() 控制 data 事件,
把"自动连续推送的数据流",
转换成"按需、一次一块的 Promis读取模型",
从而让 TCP 套接字可以像同步 I/O 一样顺序读取。
---chagpt
步骤 3:处理"end"和"error"事件
与 'data' 事件不同, 'end' 事件 'error' 事件无法暂停,它们会在发生时立即发出。我们可以将它们存储在包装对象中,并在 soRead 中检查它们来处理这种情况。
javascript
// A promise-based API for TCP sockets.
type TCPConn = {
// the JS socket object
socket: net.Socket;
// from the 'error' event
err: null|Error;
// EOF, from the 'end' event
ended: boolean;
// the callbacks of the promise of the current read
reader: null|{
resolve: (value: Buffer) => void,
reject: (reason: Error) => void,
};
};如果存在reader promise,请resolve或reject它
javascript
// create a wrapper from net.Socket
function soInit(socket: net.Socket): TCPConn {
const conn: TCPConn = {
socket: socket, err: null, ended: false, reader: null,
};
socket.on('data', (data: Buffer) => {
// omitted ...
});
socket.on('end', () => {
// this also fulfills the current read.
conn.ended = true;
if (conn.reader) {
conn.reader.resolve(Buffer.from('')); // EOF
conn.reader = null;
}
});
socket.on('error', (err: Error) => {
// errors are also delivered to the current read.
conn.err = err;
if (conn.reader) {
conn.reader.reject(err);
conn.reader = null;
}
});
return conn;
}soRead 之前发生的事件会被存储并检查。这块不懂
javascript
// returns an empty `Buffer` after EOF.
function soRead(conn: TCPConn): Promise<Buffer> {
console.assert(!conn.reader); // no concurrent calls
return new Promise((resolve, reject) => {
// if the connection is not readable, complete the promise now.
if (conn.err) {
reject(conn.err);
return;
}
if (conn.ended) {
resolve(Buffer.from('')); // EOF
return;
}
// save the promise callbacks
conn.reader = {resolve: resolve, reject: reject};
// and resume the 'data' event to fulfill the promise later.
conn.socket.resume();
});
}步骤 4:写入套接字
socket.write 方法接受一个回调函数来通知写入完成,因此转换为 promise 非常简单。这块不懂
javascript
function soWrite(conn: TCPConn, data: Buffer): Promise<void> {
console.assert(data.length > 0);
return new Promise((resolve, reject) => {
if (conn.err) {
reject(conn.err);
return;
}
conn.socket.write(data, (err?: Error) => {
if (err) {
reject(err);
} else {
resolve();
}
});
});
}Node.js 文档中还提到了 'drain' 事件 ,也可以用于此任务。Node.js 库通常会提供多种实现同一功能的方法,您可以选择其中一种而忽略其他方法。
4.4 使用 async 和 await
为了在基于Promise的API上使用await,新连接处理程序(newConn)变成了一个async函数。
javascript
async function newConn(socket: net.Socket): Promise<void> {
console.log('new connection', socket.remoteAddress, socket.remotePort);
try {
await serveClient(socket);
} catch (exc) {
console.error('exception:', exc);
} finally {
socket.destroy();
}
}我们还用 try-catch 块包裹了代码,因为 await 语句在被拒绝时可能会抛出异常。不过,在生产代码中,你可能更希望实际处理错误,而不是使用捕获所有异常的处理程序。
javascript
// echo server
async function serveClient(socket: net.Socket): Promise<void> {
const conn: TCPConn = soInit(socket);
while (true) {
const data = await soRead(conn);
if (data.length === 0) {
console.log('end connection');
break;
}
console.log('data', data);
await soWrite(conn, data);
}
}现在使用套接字的代码变得非常简单。没有回调函数会中断应用程序逻辑。
请注意, newConn 异步函数并非 可以在任何地方 await 。它只是作为监听套接字的回调函数被调用。这意味着可以并发处理多个连接。这块不懂
4.5 讨论:反压(Backpressure)
正在等待套接字写入完成?
新的回声服务器有一个重大区别------我们现在需要等待socket.write() 完成。但是"写入完成"是什么意思?为什么我们需要等待它完成?
要回答这个问题, socket.write() 会在数据提交到操作系统时完成,但又引出了一个新的问题:为什么数据不能立即提交到操作系统?这个问题实际上比网络编程本身更为复杂。
生产者受制于消费者
凡是有异步通信的地方,都会有队列或缓冲区连接生产者和消费者。物理世界中的队列和缓冲区容量有限,无法容纳无限量的数据。异步通信的一个问题是, 当生产者生产速度快于消费者消费速度时会发生什么 ?必须有一种机制来防止队列或缓冲区崩溃。 这种机制通常被称为 网络应用中的反压问题 。
TCP 中的反压:流量控制
- 消费者的 TCP 协议栈将传入的数据存储在接收缓冲区中,供应用程序使用。
- 生产者TCP协议栈可发送的数据量受其已知的窗口大小限制,当窗口已满时,它将暂停发送数据。
- 消费者的 TCP 协议栈管理窗口;当应用程序从接收缓冲区清空时,它会将窗口向前移动 ,并通知生产者的 TCP 协议栈恢复发送。
流量控制的作用:TCP 可以暂停和恢复传输,从而限制消费者的接收缓冲区大小。

TCP 流量控制不应与 TCP 拥塞控制混淆,后者也控制窗口大小。
应用程序与操作系统之间的反压
这种巧妙的机制不仅需要在 TCP 中实现,也需要在应用程序中实现。我们先来看看生产者端。应用程序生成数据并将其提交给操作系统,数据进入发送缓冲区,TCP 协议栈从发送缓冲区中取出数据并发送出去。

操作系统如何防止发送缓冲区溢出?很简单,当缓冲区满时,应用程序就无法写入更多数据。现在,应用程序需要自行控制数据输出,避免过度写入,因为数据必须存储在某个地方,而内存是有限的。
如果应用程序执行的是阻塞式 I/O,那么当发送缓冲区满时,调用就会阻塞,因此很容易实现反压。但是,在使用事件循环的 JavaScript 代码中,情况就并非如此。
无界队列(Unbounded Queues)是致命的陷阱
现在我们可以回答这个问题:为什么要等待写入完成? 因为应用程序在等待期间,无法进行生产! 即使由于发送缓冲区已满而运行时无法向操作系统提交更多数据, socket.write() 也总是会成功,但数据必须去某个地方,它会进入运行时的无界内部队列,这是一个可能导致无界内存使用量的隐患。

以我们之前的回显服务器为例,服务器和客户端一样,既是生产者又是消费者。如果客户端生成数据的速度快于其消费回显数据的速度(或者客户端根本不消费任何数据),那么如果服务器不等待写入操作完成,其内存就会无限增长。
任何连接生产者和消费者的系统中都应该存在反压机制。一条经验法则是检查软件系统中是否存在无界队列,因为无界队列是缺乏反压机制的标志。
4.6 讨论:事件与有序执行
与旧版本的另一个区别在于使用了 socket.pause() 。现在你应该明白为什么这很重要了,因为它用于实现反压。
暂停 'data' 事件还有另一个原因。在基于回调的代码中,如果事件处理程序没有被暂停,当它返回时,运行时可能会触发下一个 'data' 事件。问题在于, 事件回调的完成并不意味着事件处理的完成 ------处理过程可能会通过后续的回调继续进行。考虑到数据是一个有序的字节序列,这种交错处理可能会导致问题!
这种情况被称为竞态条件(race condition),是一类与并发相关的问题。在这种情况下,会引入不必要的并发。
4.7 结论:Promise vs. Callback
综上所述,我们现在可以解释为什么我们改用基于 Promise 的 API,因为它有诸多优势。
- 如果你坚持使用 Promise 和 async/await ,就很难产生上面描述的那种竞态条件,因为事情是按顺序发生的。
- 使用回调函数编写代码,不仅更难确定代码执行顺序,也更难控制执行顺序。简而言之,回调函数更难读懂,也更容易出错。
- 使用回调函数编写代码,不仅更难确定代码执行顺序,也更难控制执行顺序。简而言之,回调函数更难读懂,也更容易出错。
05. 简单网络协议
5.1 消息回显服务器(Message Echo Server)
解析 HTTP 协议并非易事,所以我们先从小处着手。我们将实现一个更简单的协议,以演示协议最重要的功能:将字节流拆分成消息。
我们的协议由以换行符 '\n' 分隔的消息组成。服务器读取消息并使用相同的协议发送回复。
- 如果客户端发送 'quit' ,则回复 'Bye.' ,然后关闭连接。
- 否则,将消息以'Echo: '为前缀进行回显。

5.2 动态缓冲区
Dynamic Buffers的必要性
消息不会自动从套接字发送,我们需要将传入的数据存储在缓冲区中,然后才能尝试从中拆分消息。
在 Node.js 中, Buffer 对象是固定大小的二进制数据块。它不能通过追加数据来增长。我们可以做的是将两个缓冲区连接成一个新的缓冲区。
javascript
buf = Buffer.concat([buf, data]);然而,这是一种反模式,会导致算法复杂度为 O(n 2 )。
javascript
// pseudo code! bad example!
while (need_more_data()) {
buf = Buffer.concat([buf, get_some_data()]);
}每次通过连接操作添加新数据时,都会复制旧数据。为了分摊复制成本,通常使用动态数组 :
C++: std::vector and std::string.
Python: bytearray.
Go: slice.
动态缓冲区的编码
缓冲区必须大于所需大小,以便附加数据能利用额外容量来摊销复制操作。DynBuf类型存储实际数据长度。
javascript
// A dynamic-sized buffer
type DynBuf = {
data: Buffer,
length: number,
};copy() 方法的语法是 src.copy(dst, dst_offset, src_offset) 这是用于追加数据的。
javascript
// append data to DynBuf
function bufPush(buf: DynBuf, data: Buffer): void {
const newLen = buf.length + data.length;
if (buf.data.length < newLen) {
// grow the capacity ...
}
data.copy(buf.data, buf.length, 0);
buf.length = newLen;
}Buffer.alloc(cap) 创建一个指定大小的新缓冲区。 这是为了调整缓冲区大小。新缓冲区需呈指数级增长,以确保摊销时间复杂度为 O(1)。缓冲容量我们将采用 2 的幂级数。
javascript
// append data to DynBuf
function bufPush(buf: DynBuf, data: Buffer): void {
const newLen = buf.length + data.length;
if (buf.data.length < newLen) {
// grow the capacity by the power of two
let cap = Math.max(buf.data.length, 32);
while (cap < newLen) {
cap *= 2;
}
const grown = Buffer.alloc(cap);
buf.data.copy(grown, 0, 0);
buf.data = grown;
}
data.copy(buf.data, buf.length, 0);
buf.length = newLen;
}5.3 实现消息协议
步骤 1:服务器循环
从宏观层面来看,服务器应该是一个循环。
1.从传入的字节流中解析并移除完整消息
- 向缓冲区追加一些数据。
- 如果消息不完整,则继续循环。
2.处理消息
3.发送响应
javascript
async function serveClient(socket: net.Socket): Promise<void> {
const conn: TCPConn = soInit(socket);
const buf: DynBuf = {data: Buffer.alloc(0), length: 0};
while (true) {
// try to get 1 message from the buffer
const msg: null|Buffer = cutMessage(buf);
if (!msg) {
// need more data
const data: Buffer = await soRead(conn);
bufPush(buf, data);
// EOF?
if (data.length === 0) {
// omitted ...
return;
}
// got some data, try it again.
continue;
}
// omitted. process the message and send the response ...
} // loop for messages
}套接字读取操作与任何消息边界无关。我们所做的就是将数据追加到缓冲区,直到缓冲区包含完整的消息为止。
cutMessage() 函数用于判断消息是否已完成。
- 如果没有则返回 null 。
- 否则,它会删除该消息并将其返回。
步骤二:拆分消息
cutMessage() 函数使用分隔符 '\n' 测试消息是否完整。
javascript
function cutMessage(buf: DynBuf): null|Buffer {
// messages are separated by '\n'
const idx = buf.data.subarray(0, buf.length).indexOf('\n');
if (idx < 0) {
return null; // not complete
}
// make a copy of the message and move the remaining data to the front
const msg = Buffer.from(buf.data.subarray(0, idx + 1));
bufPop(buf, idx + 1);
return msg;
}然后它会复制消息数据,因为它将从缓冲区中删除。
- buf.subarray() 返回子数组的引用,而不进行复制。
- Buffer.from() 通过复制源数据来创建一个新的缓冲区
通过将剩余数据移到前面来删除该消息。
javascript
// remove data from the front
function bufPop(buf: DynBuf, len: number): void {
buf.data.copyWithin(0, len, buf.length);
buf.length -= len;
}buf.copyWithin(dst, src_start, src_end) 在缓冲区内部复制数据,源区和目标区可以重叠,类似于C语言中的memmove()。这种处理缓冲区的方式并非最优解,后续将详细说明。
步骤三:处理请求
服务器循环中处理请求并发送响应。
javascript
while (true) {
// try to get 1 message from the buffer
const msg = cutMessage(buf);
if (!msg) {
// omitted ...
continue;
}
// process the message and send the response
if (msg.equals(Buffer.from('quit\n'))) {
await soWrite(conn, Buffer.from('Bye.\n'));
socket.destroy();
return;
} else {
const reply = Buffer.concat([Buffer.from('Echo: '), msg]);
await soWrite(conn, reply);
}
} // loop for messages我们的消息回显服务器现已完成。请使用以下命令进行测试: socat 命令。
5.4 讨论:流水线请求
从缓冲区移除消息时,我们将剩余数据移到了缓冲区前端。您可能会疑惑,既然在请求-响应机制中,客户端会在发送更多请求之前等待响应,那么缓冲区中怎么还会残留数据呢?这是为了优化性能。
通过流水线请求(Pipelining Requests)降低延迟
设想一个典型的现代网页,它包含许多脚本和样式表。加载该网页需要多次 HTTP 请求,而每次请求都会使加载时间至少增加一个往返时间 (RTT)。如果我们能够同时发送多个请求,而无需逐个等待响应,加载时间就能大幅缩短。在服务器端,服务器无需感知到任何差异,因为 TCP 连接本质上就是一个字节流。
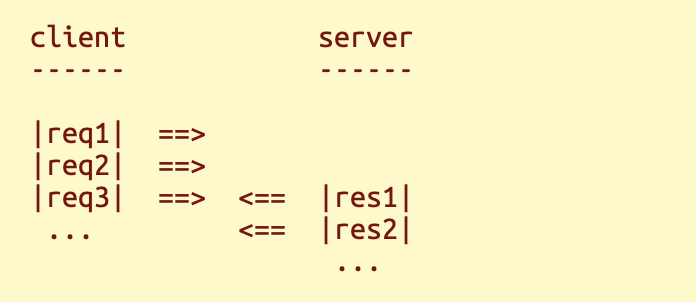
这被称为流水线式请求。它是请求-响应协议中减少往返时间 (RTT) 的常用方法。
这就是我们保留剩余缓冲区数据的原因,因为其中可能包含多条消息。
支持管道请求(Pipelined Requests)
虽然你可以向许多实现良好的网络服务器(如Redis、NGINX)发送流水线请求,但某些较少见的实现却存在问题!由于存在漏洞的服务器,Web浏览器不会使用流水线HTTP请求,而是可能改用多个并发连接。
但是,如果您将 TCP 数据严格视为连续的字节流,则流水线消息应该是无法区分的,因为解析器不依赖于缓冲数据的大小,它只是逐个消耗元素。
因此,流水线消息是一种检验协议解析器正确性的方法。如果服务器将读取的套接字视为"TCP 数据包",则很容易失败。
您可以使用以下命令行测试流水线场景。
javascript
echo -e 'asdf\n1234' | socat tcp:127.0.0.1:1234 -服务器很可能在一次data' 事件操作中收到两条消息 ',我们的服务器已正确处理。
管道式死锁
关于流水线式请求的一个注意事项:流水线式处理过多的请求可能会导致死锁;因为服务器和客户端可能同时发送请求,如果它们的发送缓冲区都已满,就会发生死锁,因为它们都卡在发送状态而无法清空缓冲区。
5.5 讨论:更智能的缓冲器
从前端移除数据
当前缓冲区代码仍存在O(n²)行为:每次从缓冲区移除消息时,都会将剩余数据向前移动。当管道传输大量小量消息时,这种情况就会被触发。
为了解决这个问题,需要分摊数据移动成本。这可以通过延迟数据移动来实现。我们可以暂时保留剩余数据,直到前端浪费的空间达到某个阈值(例如容量的一半)。
这个修复需要我们跟踪数据的起始位置,所以你需要一个新的方法来获取实际数据。
使用固定大小的缓冲区而不进行重新分配
如果协议中的消息大小限制在一个合理的较小值,有时可以使用足够大的缓冲区而无需调整大小。
例如,许多 HTTP 实现对头部大小都有较小的限制,因为没有合理的用例需要在头部放置大量数据。对于这些实现,每个连接分配一个缓冲区就足够了,而且如果不需要将整个有效负载存储在内存中,该缓冲区也足以读取有效负载。
这样做的好处是:
- 没有动态内存管理(初始缓冲区除外)。
- 内存使用情况很容易预测。
这对于 Node.js 应用程序来说不太相关,但在需要手动内存管理或硬件受限的环境中,这些优势就显得尤为重要。
5.6 结论:网络编程基础
目前所学到的知识总结如下:
- socket API:监听、接受、读取、写入等。
- 事件循环及其影响。
- 回调函数与 Promise 。使用 async 和 await 。
- 反压、队列和缓冲区。
- TCP 字节流、协议解析器、流水线消息。
06. HTTP 语义和语法
HTTP 协议非常易于阅读,这意味着你可以通过查看示例而不是规范来构建服务器。然而,这种方法会导致代码漏洞百出,而且你也学不到什么东西。因此,你需要参考规范------一系列 RFC 文档。
6.1 高层结构
让我们回顾一下你从引言章节中已经学到的内容:
HTTP 请求消息包含以下内容:
- 该方法是一个动词,例如 GET , POST 。
- URI。
- 标头字段列表,即键值对列表。
- 请求头之后是有效负载主体。特殊情况: GET 和 HEAD 没有有效载荷。
HTTP 响应包含以下内容:
- 状态码,主要用于指示请求是否成功。
- 标题字段列表。
- 可选的有效载荷体。
从 HTTP/1.0 到 HTTP/3,这些方面基本相同。
6.2 内容长度
HTTP 语义主要涉及对头部字段的解释,这在 RFC 9110 中有详细描述。建议您自己阅读一下。
最重要的标头字段是 Content-Length 和 Transfer-Encoding ,因为它们决定了 HTTP 消息的长度,这是协议最重要的功能。
HTTP 标头的长度
请求和响应都由两部分组成:头部和主体。它们之间用空行分隔。每行以换行符 '\r\n' 结尾。因此,头部以 '\r\n\r\n' 结尾,包括空行在内。这就是我们确定头部长度的方法。
HTTP 请求体的长度
请求体的计算较为复杂,因为存在三种确定方法。第一种方法是使用Content-Length字段,该字段包含请求体的长度。
某些古老的HTTP/1.0软件不使用Content-Length,此时请求体即为连接数据的剩余部分------解析器读取套接字至文件末尾(EOF)的位置即为请求体长度。这是第二种确定正文长度的方法。但该方法存在问题:无法判断连接是否提前终止。
6.3 分块传输编码
动态生成并发送数据
第三种方法是使用 Transfer-Encoding: chunked 而不是 Content-Length 。这被称为分块传输编码 。它可以在无需预先知道有效载荷大小的情况下标记有效载荷的结束。
这样服务器就可以在动态生成响应的同时发送响应。这种用例称为流式传输 。例如,无需等待进程完成即可向客户端显示实时日志。
协议的另一层
分块编码如何工作?作为发送方,我们虽不知晓总负载长度,但清楚当前持有的负载部分。因此可采用名为"分块"的迷你消息格式发送数据。而特殊分块则标记数据流的终结点。
接收方将字节流解析为块并处理数据,直至接收到特殊块。具体示例如下:
4\r\nHTTP\r\n5\r\nserver\r\n0\r\n\r\n
它被解析成 3 个部分:
- 4\r\nHTTP\r\n
- 5\r\nserver\r\n
- 0\r\n\r\n
你很容易就能猜到它的工作原理。数据块从数据大小开始,大小为 0 的数据块标志着数据流的结束。
数据块并非消息
需注意数据块边界仅是副作用。这些数据块不会作为单独的消息呈现给应用程序;应用程序仍将有效负载视为字节流。
6.4 HTTP 中的歧义
请求体长度的快乐案例
总之,这是确定有效负载体长度的方法(前提是HTTP方法允许携带有效负载主体,即POST或PUT请求)。
- 如果存在 Transfer-Encoding: chunked,则解析分块。
- 如果 Content-Length: number 有效,则长度已知。
- 如果这两个字段都不存在,则使用连接数据的其余部分作为有效负载。
此外还存在特殊情况,例如 GET 和 HEAD 请求、304(未修改)状态码等,这些都使得 HTTP 的实现较为复杂。
注意棘手的案例
您可能会疑惑:当两个头部字段同时存在时该如何处理?因为此时无法明确解释其含义。这种模糊性正是安全漏洞的根源,即所谓的"HTTP请求走私"攻击。
另一处模糊点在于GET请求中不存在的有效负载主体:若请求包含Content-Length字段,服务器应忽略该字段还是禁止该字段?若Content-Length: 0又该如何处理?
此外,服务器或客户端是否应允许用户随意修改Content-Length和Transfer-Encoding字段?网络上对此存在诸多讨论,尽管RFC尝试列举了各种情况,但不同实现方式仍存在差异。
6.5 HTTP 消息格式
RFC 9112 详细描述了比特如何在网络上传输。
阅读 BNF 语言
HTTP消息格式采用一种名为BNF的语言进行描述。查阅RFC 9112标准中的"2. 消息"章节,你会看到类似以下内容:

其含义为:HTTP消息分为请求消息与响应消息两类。消息以请求行或状态行开头,随后是多个头字段,接着是一个空行,最后可选地跟随有效负载主体。各行通过CRLF分隔,即ASCII字符串'\r\n'。BNF语言相较于英语更为简洁且不易产生歧义。
HTTP 标头字段
field-line = field-name ":" OWS field-value OWS
标头字段名与值以冒号分隔,但字段名和值的规则在RFC 9110中另行定义。
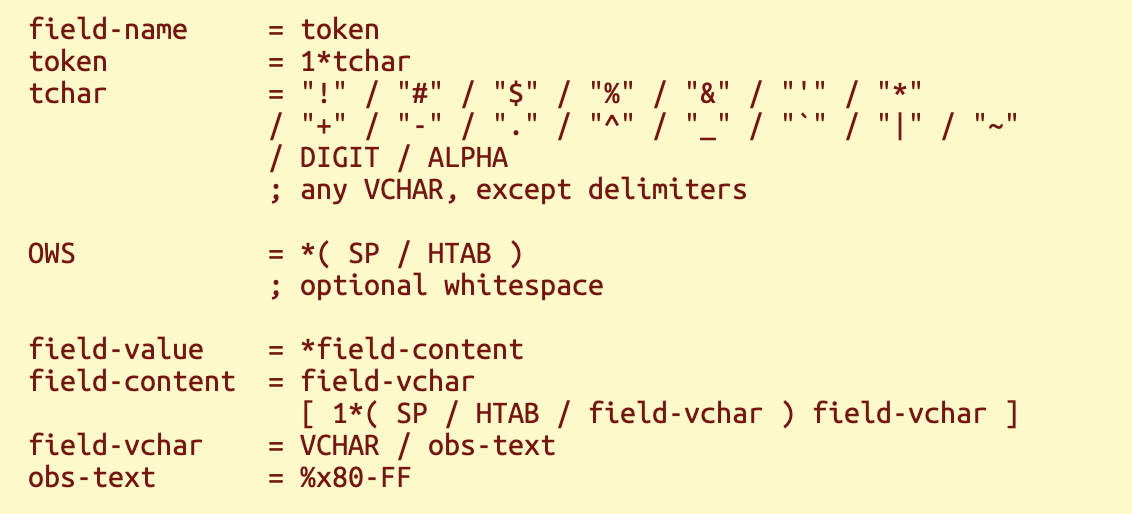
这是字段名与值的一般规则。SP、HTAB和VCHAR分别代表空格、制表符和可打印ASCII字符。某些字符在头部字段中被禁止使用,尤其是回车符(CR)和换行符(LF)。
部分标头字段存在特殊解析规则,例如逗号分隔值或带引号的字符串。目前可暂不处理,待后续需要时再行处理。
HTTP规范内容庞杂,本章仅涵盖实现HTTP服务器时最关键的部分,具体实现将在下一章展开。
6.6 常用标头字段
许多头部字段要么由应用程序解析,要么用于可选的HTTP功能,与我们的实现并不直接相关。您可通过浏览器开发工具检查HTTP头部来熟悉这些字段。

6.7 HTTP 方法
只读方法
最重要的两个HTTP方法是GET和POST。为什么需要不同的HTTP方法?除了POST请求能携带有效负载而GET不能这一显而易见的原因外,将只读操作与写入操作分离也是明智之举。您可以使用GET进行只读操作,而将其他操作交给POST处理。
只读方法被称为"安全"方法。共有 3 种安全方法:
- GET
- HEAD ,类似于 GET ,但不包含响应体。
- OPTIONS,很少使用,用于识别允许的请求方法和 CORS 相关事项。
可缓存性(Cacheability)
将只读操作与写操作分开的原因之一是只读操作通常可以缓存。另一方面,由于写操作会改变系统状态,因此缓存写操作是没有意义的。
然而,缓存规则的复杂程度远超不同HTTP方法的差异。
- GET 和 HEAD 被认为是可缓存的方法,但 OPTIONS 则不是,因为它有特殊用途。
- 状态码也会影响缓存性。
- Cache-Control 标头会影响缓存性。
- POST请求通常不可缓存,除非使用了罕见的Content-Location头字段并配置特定缓存指令。
- 不同的实现方式有不同的缓存规则。
CRUD 和资源
你或许曾疑惑为何HTTP方法如此繁多。仅用GET和POST难道不够吗?事实上许多应用确实如此。HTTP增加更多方法是因为人们将其视为管理"资源"的协议。例如,论坛用户可以像管理资源一样管理自己的帖子:
-
通过 PUT 创建帖子。
-
通过 GET 读取帖子。
-
通过 PATCH 更新帖子。
-
使用 DELETE 删除帖子。
这 4 个动词通常被称为 CRUD 。
Idempotence(幂等性)
但为何要将CRUD操作作为HTTP方法?论坛用户可能还会将帖子移动到另一个论坛,HTTP 是否也应该包含 MOVE 方法呢?仅仅为了照搬英语动词而定义 HTTP 方法并不是一个好理由。更优的动机在于定义操作的幂等性。
幂等操作是指重复执行时效果相同的操作。这意味着您可以安全地重试该操作,直到成功为止。例如,如果您通过 SSH rm 一个文件,但在看到结果之前连接断开,因此您不知道该文件的状态,但您可以随时再次盲目地 rm 它(如果它确实是同一个文件):
- 如果你第一次失败了,你很可能会再次失败。
- 如果之前的 rm 操作失败,而这次操作成功,那么你的意图就实现了。
- 如果之前的 rm 成功了,再做一次也无妨。
通过 HTTP 进行的幂等操作仍然可能产生不同的状态码,就像 rm 的返回码一样。
HTTP 中的幂等性:
- 只读方法( GET 和 HEAD )显然是幂等的。
- PUT 和 DELETE 是幂等的,覆盖和删除文件也是如此。
- POST 和 PATCH 并未被定义为幂等操作。它们可能是幂等的,也可能不是。
浏览器中的幂等性:
- 若通过POST提交后刷新页面,浏览器会警告你避免重复提交可能具有非幂等性的表单。
- HTML表单仅支持GET和POST。要使用这些幂等方法,必须借助AJAX技术。
但这仍然无法解答为什么会有这么多动词,因为 HTTP 完全可以只添加一个幂等写入方法,而不是三个( PATCH 、 PUT 、 DELETE )。事实上,应用程序可能没有充分的理由使用所有这些参数。
HTTP 方法比较
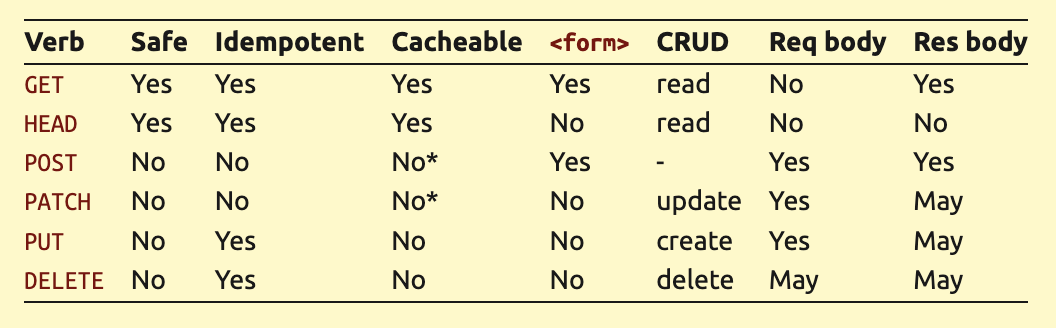
注意:虽然可以缓存 POST 或 PATCH 请求,但很少得到支持。
6.8 讨论:文本与二进制
HTTP的设计初衷是支持通过telnet发送请求,因此可通过探索学习。然而文本协议存在局限性。
文本常常含糊不清
其弊端在于:可读性强的格式往往降低机器可读性,因其灵活性超出必要需求。以HTTP有效负载长度的确定方式为例:
- 常见情况是 Content-Length 和 Transfer-Encoding 。
- 某些 HTTP 方法和状态码有特殊情况。
- 有些情况会导致不同的解读,例如,请求走私。
HTTP 协议本身很简单,简单指的是它易于理解。但编写 HTTP 代码却并不简单,因为它的解释规则太多,而且这些规则仍然存在歧义。
文本更费时费力且更容易出错
另一个缺点是处理文本要费力得多。要正确处理文本字符串,首先需要知道它们的长度,而长度通常由分隔符决定。查找分隔符的额外工作量就是实现人类可读格式的代价。
它也容易出错;在 C 语言编程中,以空字符结尾的字符串(0 分隔符)已经导致了许多安全漏洞。
HTTP/2 是二进制的,比 HTTP/1.1 更复杂,但解析该协议仍然更容易,因为你不必处理未知长度的元素。
6.9 讨论:分隔符
分隔符数据中的序列化错误
分隔符在文本协议中无处不在。例如,在 HTTP 协议中......
- 头部中的行以 CRLF 分隔。
- 标题和正文之间用空行分隔。
分隔符的一个问题是数据本身不能包含分隔符。如果不强制执行此规则,可能会导致一些注入攻击。
若恶意客户端能诱使存在漏洞的服务器返回包含CRLF的头部字段值,且该字段位于末尾,则有效负载正文将以攻击者控制的字段值开头。此现象称为"HTTP响应拆分"。
一个合格的 HTTP服务器/客户端必须禁止在头部字段中使用CRLF,因为无法对其进行编码。然而,对于许多通用数据格式来说,情况并非如此。例如,JSON 使用 {} \[\] , : 来分隔元素,但 JSON 字符串可以包含任意字符,因此字符串会被引号括起来以避免与分隔符产生歧义。但是,引号本身也是分隔符,因此需要转义序列来对引号进行编码。
这就是为什么你需要一个 JSON 库来生成 JSON 数据,而不是简单地拼接字符串。而且 HTTP 的定义不如 JSON 完善,也更复杂,所以一定要仔细阅读规范。
二进制协议中的长度前缀数据
文本中的分隔符用于区分元素。在二进制协议和格式中,更优雅简洁的替代方案是采用长度前缀数据------即在元素数据前指定其长度。例如:
- 分块传输编码。尽管长度本身仍然是限定的。
- WebSocket 帧格式。完全没有分隔符。
- HTTP/2. 基于帧。
- 消息包 序列化格式。某种二进制 JSON 格式。
07. 编写一个基本的 HTTP 服务器
我们的 HTTP 服务器基于上一章的消息回显服务器,只是将"消息"替换成了 HTTP 消息。
7.1 开始编码
代码被分解成许多小步骤,并遵循自顶向下的方法。
第一步:类型和结构
第一步是根据我们对 HTTP 语义的理解来定义 HTTP 消息的结构。
javascript
// a parsed HTTP request header
type HTTPReq = {
method: string,
uri: Buffer,
version: string,
headers: Buffer[],
};
// an HTTP response
type HTTPRes = {
code: number,
headers: Buffer[],
body: BodyReader,
};我们使用Buffer而非字符串存储URI和头部字段。尽管HTTP 协议大部分内容都是纯文本,但无法保证URI和头部字段必须是ASCII或UTF-8字符串。因此在解析前,我们将其保留为原始字节流。
BodyReader类型是用于读取请求体有效负载数据的接口。
javascript
// an interface for reading/writing data from/to the HTTP body.
type BodyReader = {
// the "Content-Length", -1 if unknown.
length: number,
// read data. returns an empty buffer after EOF.
read: () => Promise<Buffer>,
};有效负载正文长度可能无限,甚至超出内存容量,因此必须使用read()函数进行读取而非使用简单的buffer。read()函数遵循soRead()函数的约定------空buffer表示数据结束。
当使用分块编码时,正文的长度是未知的,这也是需要此接口的另一个原因。
步骤 2:服务器循环
服务器循环延续了前章的模式。区别在于 cutMessage() 函数仅解析 HTTP 头部;负载主体需在处理请求时读取,或在处理请求后丢弃。通过这种方式,我们避免将整个负载主体存储在内存中。
javascript
async function serveClient(conn: TCPConn): Promise<void> {
const buf: DynBuf = {data: Buffer.alloc(0), length: 0};
while (true) {
// try to get 1 request header from the buffer
const msg: null|HTTPReq = cutMessage(buf);
if (!msg) {
// need more data
const data = await soRead(conn);
bufPush(buf, data);
// EOF?
if (data.length === 0 && buf.length === 0) {
return; // no more requests
}
if (data.length === 0) {
throw new HTTPError(400, 'Unexpected EOF.');
}
// got some data, try it again.
continue;
}
// process the message and send the response
const reqBody: BodyReader = readerFromReq(conn, buf, msg);
const res: HTTPRes = await handleReq(msg, reqBody);
await writeHTTPResp(conn, res);
// close the connection for HTTP/1.0
if (msg.version === '1.0') {
return;
}
// make sure that the request body is consumed completely
while ((await reqBody.read()).length > 0) { /* empty */ }
} // loop for IO
}HTTPError是我们自定义的异常类型,用于生成错误响应并关闭连接。需注意该机制仅为简化代码而存在,延迟处理错误这种不理想的情况。生产环境中不建议如此随意抛掷异常。
javascript
async function newConn(socket: net.Socket): Promise<void> {
const conn: TCPConn = soInit(socket);
try {
await serveClient(conn);
} catch (exc) {
console.error('exception:', exc);
if (exc instanceof HTTPError) {
// intended to send an error response
const resp: HTTPRes = {
code: exc.code,
headers: [],
body: readerFromMemory(Buffer.from(exc.message + '\n')),
};
try {
await writeHTTPResp(conn, resp);
} catch (exc) { /* ignore */ }
}
} finally {
socket.destroy();
}
}步骤 3:拆分标题
HTTP 标头以 '\r\n\r\n' 结尾,我们通过这个符号来确定其长度。
理论上,头部的大小没有限制,但实际上是有限制的。因为我们需要解析头部并将其存储在内存中,而内存是有限的。
javascript
// the maximum length of an HTTP header
const kMaxHeaderLen = 1024 * 8;
// parse & remove a header from the beginning of the buffer if possible
function cutMessage(buf: DynBuf): null|HTTPReq {
// the end of the header is marked by '\r\n\r\n'
const idx = buf.data.subarray(0, buf.length).indexOf('\r\n\r\n');
if (idx < 0) {
if (buf.length >= kMaxHeaderLen) {
throw new HTTPError(413, 'header is too large');
}
return null; // need more data
}
// parse & remove the header
const msg = parseHTTPReq(buf.data.subarray(0, idx + 4));
bufPop(buf, idx + 4);
return msg;
}有了完整的数据,解析也更容易。这也是我们等待完整的 HTTP 头部信息后再进行解析的另一个原因。
步骤四:解析头部信息
要解析 HTTP 头部,我们可以先用 CRLF 将数据分割成行,因为缓冲区中已经有了完整的头部信息。然后我们可以逐行处理。
javascript
// parse an HTTP request header
function parseHTTPReq(data: Buffer): HTTPReq {
// split the data into lines
const lines: Buffer[] = splitLines(data);
// the first line is `METHOD URI VERSION`
const [method, uri, version] = parseRequestLine(lines[0]);
// followed by header fields in the format of `Name: value`
const headers: Buffer[] = [];
for (let i = 1; i < lines.length - 1; i++) {
const h = Buffer.from(lines[i]); // copy
if (!validateHeader(h)) {
throw new HTTPError(400, 'bad field');
}
headers.push(h);
}
// the header ends by an empty line
console.assert(lines[lines.length - 1].length === 0);
return {
method: method, uri: uri, version: version, headers: headers,
};
}第一行只是由空格分隔的三个部分。其余行是标头字段。虽然我们这里并不打算解析标头字段,但对它们进行一些验证仍然是个好主意。
splitLines() 、 parseRequestLine() 和 validateHeader() 函数本身并不十分有趣,因此我们在此不再赘述。您可以根据 RFC 规范自行编写相应的代码。
第五步:阅读正文
在处理请求前,必须先构造BodyReader对象并将其传递给处理函数。如前所述,读取请求体有效负载有三种方式:
javascript
// BodyReader from an HTTP request
function readerFromReq(
conn: TCPConn, buf: DynBuf, req: HTTPReq): BodyReader
{
let bodyLen = -1;
const contentLen = fieldGet(req.headers, 'Content-Length');
if (contentLen) {
bodyLen = parseDec(contentLen.toString('latin1'));
if (isNaN(bodyLen)) {
throw new HTTPError(400, 'bad Content-Length.');
}
}
const bodyAllowed = !(req.method === 'GET' || req.method === 'HEAD');
const chunked = fieldGet(req.headers, 'Transfer-Encoding')
?.equals(Buffer.from('chunked')) || false;
if (!bodyAllowed && (bodyLen > 0 || chunked)) {
throw new HTTPError(400, 'HTTP body not allowed.');
}
if (!bodyAllowed) {
bodyLen = 0;
}
if (bodyLen >= 0) {
// "Content-Length" is present
return readerFromConnLength(conn, buf, bodyLen);
} else if (chunked) {
// chunked encoding
throw new HTTPError(501, 'TODO');
} else {
// read the rest of the connection
throw new HTTPError(501, 'TODO');
}
}此处需关注Content-Length字段与Transfer-Encoding字段。fieldGet()函数用于按名称查询字段值,需注意字段名称不区分大小写。具体实现方式留待读者自行完成。
javascript
function fieldGet(headers: Buffer[], key: string): null|Buffer;我们仅实现Content-Length字段存在的情况,其余情形将在后续章节处理。
javascript
// BodyReader from a socket with a known length
function readerFromConnLength(
conn: TCPConn, buf: DynBuf, remain: number): BodyReader
{
return {
length: remain,
read: async (): Promise<Buffer> => {
if (remain === 0) {
return Buffer.from(''); // done
}
if (buf.length === 0) {
// try to get some data if there is none
const data = await soRead(conn);
bufPush(buf, data);
if (data.length === 0) {
// expect more data!
throw new Error('Unexpected EOF from HTTP body');
}
}
// consume data from the buffer
const consume = Math.min(buf.length, remain);
remain -= consume;
const data = Buffer.from(buf.data.subarray(0, consume));
bufPop(buf, consume);
return data;
}
};
}readerFromConnLength()函数返回一个BodyReader对象,该对象精确读取Content-Length字段指定的字节数。需注意:来自套接字的数据会先进入缓冲区,然后再从缓冲区中取出数据。这是因为:
- 在从套接字读取数据之前,缓冲区中可能存在额外的数据。
- 最后一次读取可能会返回比我们需要的更多的数据,因此我们需要将多余的数据放回缓冲区。
remain变量是read()函数捕获的状态变量,用于追踪剩余请求体的长度。
步骤 6:请求处理程序
现在我们可以根据请求的 URI 和方法来处理请求。这里我们将展示两个示例响应。
javascript
// a sample request handler
async function handleReq(req: HTTPReq, body: BodyReader): Promise<HTTPRes> {
// act on the request URI
let resp: BodyReader;
switch (req.uri.toString('latin1')) {
case '/echo':
// http echo server
resp = body;
break;
default:
resp = readerFromMemory(Buffer.from('hello world.\n'));
break;
}
return {
code: 200,
headers: [Buffer.from('Server: my_first_http_server')],
body: resp,
};
}若URI为'/echo',则直接将响应负载设置为请求负载。这实质上创建了一个HTTP回显服务器。您可通过curl命令发送POST请求进行测试。
javascript
curl -s --data-binary 'hello' http://127.0.0.1:1234/echo另一示例响应为固定字符串'hello world.\n'。实现此功能需先创建BodyReader对象。
javascript
// BodyReader from in-memory data
function readerFromMemory(data: Buffer): BodyReader {
let done = false;
return {
length: data.length,
read: async (): Promise<Buffer> => {
if (done) {
return Buffer.from(''); // no more data
} else {
done = true;
return data;
}
},
};
}read() 函数首次调用返回完整数据,后续调用返回 EOF。此特性适用于返回小规模且可完全存入内存的数据。
步骤 7:发送回复
处理请求后,若存在响应头和响应正文即可发送。本章仅处理已知长度的有效负载体,分块编码将在后续章节讨论。我们只需添加Content-Length字段即可。
javascript
// send an HTTP response through the socket
async function writeHTTPResp(conn: TCPConn, resp: HTTPRes): Promise<void> {
if (resp.body.length < 0) {
throw new Error('TODO: chunked encoding');
}
// set the "Content-Length" field
console.assert(!fieldGet(resp.headers, 'Content-Length'));
resp.headers.push(Buffer.from(`Content-Length: ${resp.body.length}`));
// write the header
await soWrite(conn, encodeHTTPResp(resp));
// write the body
while (true) {
const data = await resp.body.read();
if (data.length === 0) {
break;
}
await soWrite(conn, data);
}
}encodeHTTPResp() 函数将响应头编码到字节缓冲区中。消息格式与请求消息几乎完全相同,只是第一行不同。

编码比解析容易得多,因此实现方式留给读者自行决定。
步骤 8:检查服务器循环
发送响应后还有一些工作要做。由于连接无法重用,我们可以通过立即关闭连接来为 HTTP/1.0 客户端提供一定的兼容性。
最关键的是,在循环处理下一个请求前,必须确保请求正文已被完全读取。因为处理函数可能忽略了请求正文,导致解析器停留在错误位置。
javascript
async function serveClient(conn: TCPConn): Promise<void> {
const buf: DynBuf = {data: Buffer.alloc(0), length: 0};
while (true) {
// try to get 1 request header from the buffer
const msg: null|HTTPReq = cutMessage(buf);
if (!msg) {
// omitted ...
continue;
}
// process the message and send the response
const reqBody: BodyReader = readerFromReq(conn, buf, msg);
const res: HTTPRes = await handleReq(msg, reqBody);
await writeHTTPResp(conn, res);
// close the connection for HTTP/1.0
if (msg.version === '1.0') {
return;
}
// make sure that the request body is consumed completely
while ((await reqBody.read()).length > 0) { /* empty */ }
} // loop for IO
}我们的第一个 HTTP 服务器已经搭建完成。
7.2 测试
最简单的测试用例是使用curl发起请求。服务器应返回"hello world"作为响应。您也可向'/echo'路径发送POST数据,服务器应该会将数据回显给你。
javascript
curl -s --data-binary 'hello' http://127.0.0.1:1234/echo大型 HTTP 主体
curl 命令还可以从文件中上传数据。我们可以上传一个非常大的文件来验证服务器是否仅使用恒定内存,而不会触发内存溢出 (OOM)。
javascript
curl -s --data-binary @a_big_file http://127.0.0.1:1234/echo | sha1sum连接重用和管道
另一项关键测试是验证单连接处理多请求的能力。可通过socat交互式方式进行测试,或借助shell脚本实现自动化测试。
javascript
(cat req1.txt; sleep 1; cat req2.txt) | socat tcp:127.0.0.1:1234,crnl -请注意 socat 命令中的 crnl 选项,这是为了确保行以 CRLF 而不是 LF 结尾。
如果移除上述脚本中的 sleep 1 ,则还可以测试流水线请求。
7.3 讨论:纳格尔算法
优化:合并小写入
在发送响应时,我们使用encodeHTTPResp()函数创建了头部的字节缓冲区,然后才将响应写入套接字。有些人可能会跳过这一步,直接逐行写入套接字。
javascript
// Bad example!
await soWrite(conn, Buffer.from(`HTTP/1.1 ${msg.code} ${status}\r\n`));
for (const h of msg.headers) {
await soWrite(conn, h);
await soWrite(conn, Buffer.from('\r\n'));
}
await soWrite(conn, Buffer.from('\r\n'));问题在于这种方式会产生大量小的写入操作,导致TCP发送大量小数据包。每个数据包不仅存在相对较大的空间开销,处理更多数据包还需消耗更多计算资源。人们发现了这种优化机会,在TCP协议栈中添加了名为"Nagle算法"的功能------该算法通过延迟传输来使发送缓冲区积累数据,从而将多个连续的小写操作合并处理。
过早优化
然而,这并非有效的优化方案。许多新型网络协议设计(如TLS)都致力于减少往返时间(RTT),因为多数性能问题本质上是延迟问题。在TCP中添加延迟以合并写入操作,如今反而显得像是反优化。而且,原本的优化目标完全可以在应用层轻松实现;应用程序可以自行合并小数据,而无需延迟。
编写良好的应用程序应该妥善管理缓冲区,可以通过显式地将数据序列化到缓冲区,或者使用一些带缓冲的 I/O 接口来实现,这样就不需要 Nagle 算法了。而高性能应用程序则会尽量减少系统调用次数,这使得 Nagle 算法更加无用。
人们在实践中实际的做法
开发网络应用程序时:
- 避免每次写入数据量过小,应在写入前合并少量数据。
- 禁用纳格尔算法。
Nagle 算法通常默认启用。可以使用 Node.js 中的 noDelay 标志禁用它。
javascript
const server = net.createServer({
noDelay: true, // TCP_NODELAY
});7.4 讨论:缓冲写入器
替代方案:使缓冲机制半透明化
与其像处理响应头那样显式将数据串行化至缓冲区,我们也可在TCPConn类型中添加缓冲区并改变其工作方式。
javascript
// append data to an internal buffer
function soWrite(conn: TCPConn, data: Buffer): Promise<void>;
// flush the buffer to the runtime
function soFlush(conn: TCPConn): Promise<void>;在新方案中, soWrite() 函数被修改为将数据追加到 TCPConn 中的内部缓冲区,并且新的 soFlush() 函数用于实际写入数据。缓冲区大小有限, soWrite() 函数也可以在缓冲区满时将其刷新。
这种IO风格非常流行,你可能在其他编程语言中见过类似实现。例如C语言的stdio库内置了默认启用的缓冲区,必须在适当时候使用fflush()进行刷新。
替代方案:添加缓冲包装器
或者,您可以保留 TCPConn 不变,并添加一个单独的包装器类型,如下所示:
javascript
type BufferedWriter = {
write: (data: Buffer) => Promise<void>,
flush: () => Promise<void>,
// ...
};
function createBufferedWriter(conn: TCPConn): BufferedWriter;这类似于Go语言中的bufio.Writer。相较于在套接字代码中添加缓冲,此方案更具灵活性------因为缓冲封装器同样适用于其他IO形式。而且 Go 标准库在设计时就定义了完善的接口( io.Writer ),使缓冲写入器能直接替代非缓冲写入器。
Go标准库中还有许多值得借鉴的优秀设计。例如bufio.Writer,它不仅是io.Writer的实现,更暴露了其内部缓冲区,因此您可以直接向其中写入数据!这能消除序列化数据时产生的临时缓冲区和额外数据复制。