在分布式式架构中,我们尽量要保证其高可用性,比如一个查询商品的服务,从nginx->tomcat->redis->mysql,其中往往性能瓶颈就是tomcat,其次就是mysql。
为了尽可能的减少tomcat或者mysql的压力,我们引入了多级缓存,其核心思想就是在每一级都添加缓存,尽可能减少调用的链路,比如nignx中添加缓存,nginx直接访问redis(这样能跳过tomcat了),nginx访问tomcat的进程缓存(一般就是java的本地缓存了),最后才是访问数据库。
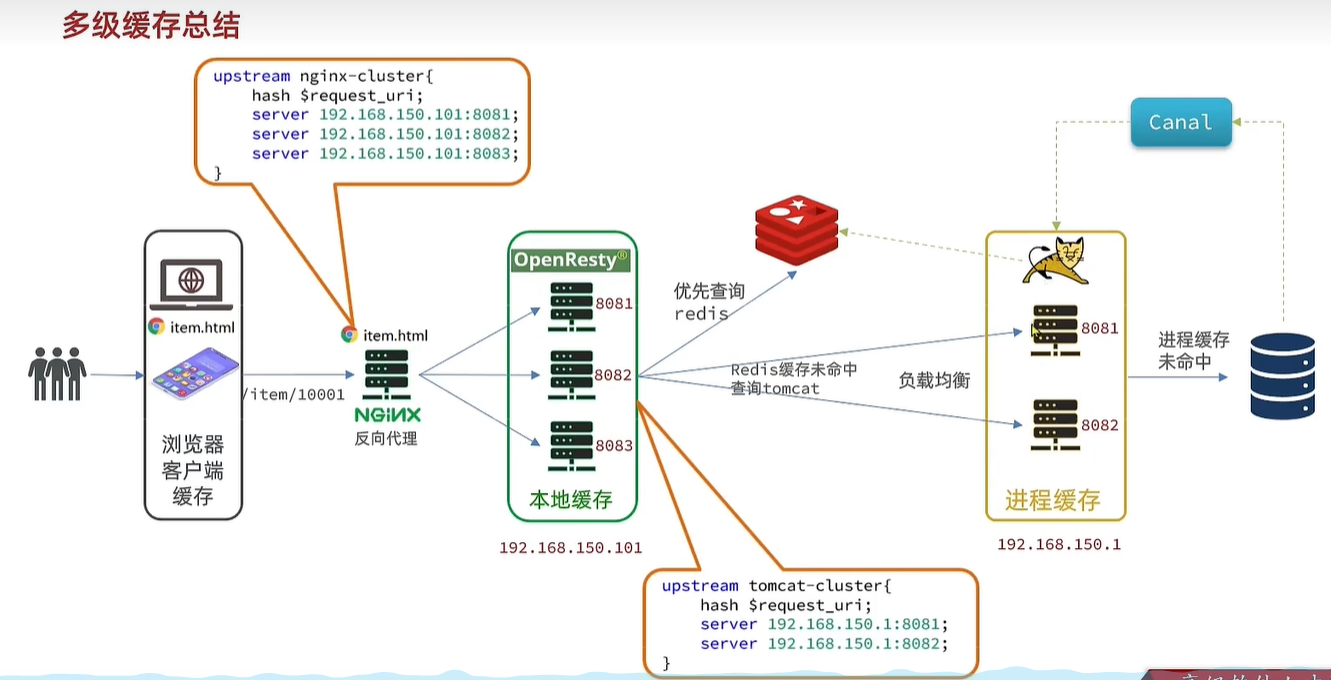
首先nginx本身是不带缓存的,也没有判断缓存是否存在的手段,这就需要引入OpenResty,可以理解为nginx+lua脚本。有了OpenResty就可以使用nginx的本地缓存功能,如果是一台nginx服务器,性能肯定受影响的,所有可以组成集群,前面再加一台nginx服务器,作为反向代理用。这样就会有新的问题,每次访问不同nginx服务器,那是不是每台都要存一遍数据,所以这里需要配置hash $requestUri的轮询方式,保证每次商品查询都访问到一台服务器上去(这里访问路径就包含了商品id的前提);
如果nginx本地缓存没有命中,就去查询Redis,Redis没有命中再去发http请求到tomcat(这里也需要配置hash $requestUri的轮询方式),tomcat又是查本地缓存(比如caffeine),没有命中再查数据库,查到数据写回进程缓存(tomcat的本地缓存就是caffeine),然后回到OpenResty再回填nginx的本地缓存。
但是如果数据修改了怎么办?方案是用Cannal技术,大概就是监听mysql的master的binlog的写事件,然后回填数据到Redis和进程缓存。(这里没有同步nginx的本地缓存)。
上面就是多级缓存查询的流程和数据同步的方案。
思考:
但是好像少了回填nginx的本地缓存的机制,看弹幕说通过设置过期时间自己过期的,没数据触发后面数据的时候回填,但是这样修改数据肯定会有延时。那么是否可以设置很短的时间,这样即使延时了,时间也很短,但是个人感觉用到nginx缓存的应该是热点数据了这样触发redis查是否合适;还有一种是OpenResty里写一个接口(路由规则),里面写更新nginx本地缓存的逻辑,修改的同步方案中增加一步调这个接口,感觉这个靠谱。如果有知道的,有好的解决方案麻烦告知。