依赖
- Python 3.6+
- CMake 3.13+
- GCC 5.4+
- OpenBLS: 开源线性带束裤,用于CPU上的向量计算加速,是Faiss CPU版本的核心依赖。
- CUDA Toolkit: NVIDIA的CUDA Toolkit,用于GPU加速。
- Numpy
- Pillow, 可选图像特征提取。
使用ModelScope的CPU环境
https://modelscope.cn/my/mynotebook
安装命令
bash
# 安装CPU版本FAISS
pip install faiss-cpu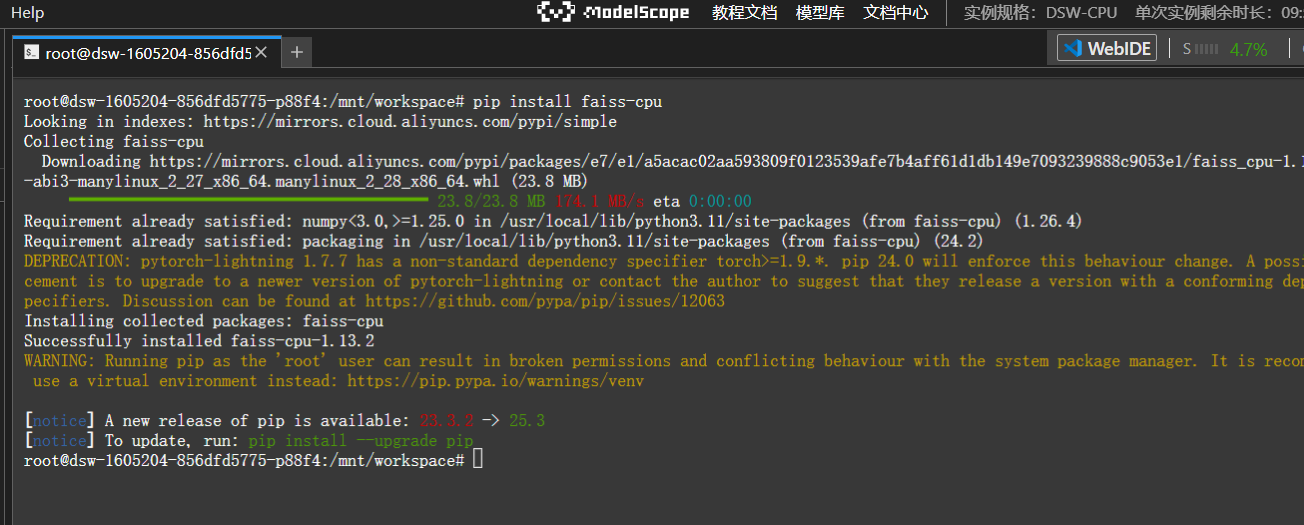
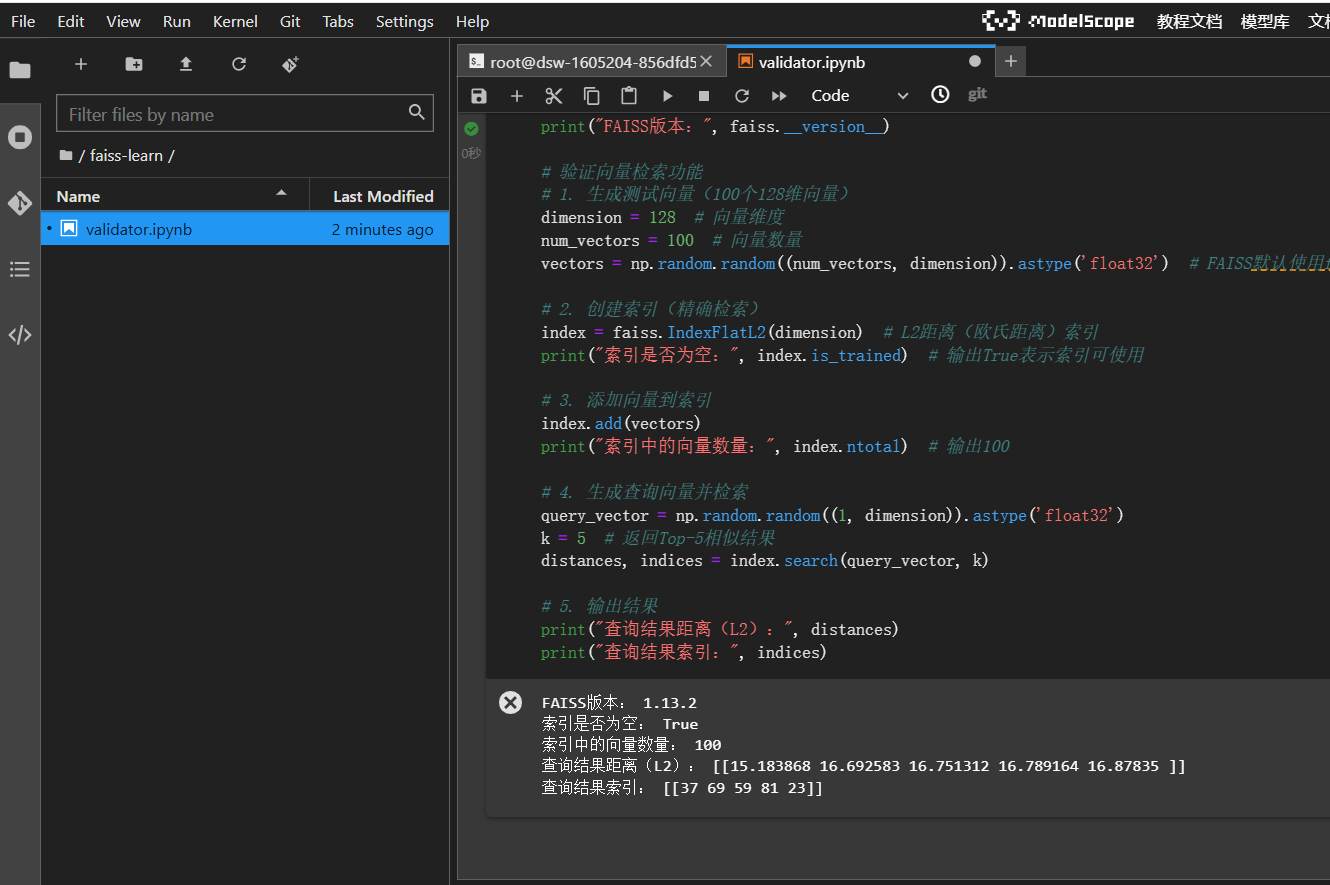
验证安装
Faiss数据结构
- Index: 索引类是Faiss中最核心的数据结构。所有向量的存储、检索操作都依赖于Index类及其派生类。
基类Index的核心作用(基础API)
- add(x): 将向量数据x添加到索引中,x的形状为(num_vectors, dimension), 数据类型为float32。
- search(x, k): 在索引中检索与x最相似的k个向量,返回数组(distances)和索引数组(indices)
- reset(): 清空索引中的所有向量数据,重置索引状态
- save(filename)/load(filename): 将索引保存到磁盘或从磁盘加载索引。
- is_trained: 属性,返回布尔值,表示索引是否已"训练"完成。
- ntotal: 索引中向量的数量。
常见派生类
精准检索
- IndexFlat2
- 基于L2(欧式距离)计算相似度,无近似误差,检索速度较慢,无需训练
- 适用场景:小规模数据(万级以下)、对精度极高的场景。
- IndexFlatIP
- 基于内积(Inner Product)计算相似度,适用于归一化向量的余弦相似度检索
- 适用场景:文本语义检索(向量已归一化)、特征匹配
近似检索
- IndexIVFFlat
- 基于倒排文件(Inverted File)结构,需先训练聚类中心,检索速度快,精度可调节。
- 适用场景:中大规模数据(百万级)、平衡速度与精度的场景。
- IndexIVFPQ
- 在IndexIVF基础上添加乘积量化(PQ)压缩,大幅减少内存占用,支持十亿级数据。
- 适用场景:超大规模数据(十亿级)、内存有限的场景。
- IndexHNSWFlat
- 基于层次化近似最近邻(HNSW)算法,检索速度极快,内存占用较高。
- 适用场景:对检索延迟要求极高的实时场景。
向量存储基础:数据格式与维度约束
数据格式
- 数据类型:FAISS仅支持32位浮点数(float32)作为向量数据类型,不支持其他格式。
- 数据结构:输入向量需为二维向量,形状为(num_vectors, dimension),其中num_vectors为向量数量,dimension为单个向量的维度(所有向量维度必须一致)。
- 数据来源适配:
- Numpy数组:可直接使用, add()方法添加。
- PyTorch/TensorFlow张量:需转换为Numpy数组后, 再转换为float32类型。
- Python列表:需先通过np.array()转换为Numpy数组,再处理类型和形状。
维度约束
- 维度一致性: FAISS的索引对象在创建时会固定向量维度(由构造函数的参数指定),后续添加的向量必须与该维度一致。
ID映射机制:向量与自定义ID的关联
- 默认情况下,FAISS为添加到索引的向量分配自增的整数ID(从0开始),实际应用中,可以自定义。
IndexIDMap的使用
- IndexIDMap: 通过ID映射机制,将向量与自定义ID关联起来,方便后续查询。
注意事项
- 自定义ID类型:必须为int64类型,否则会导致ID映射错误。
- ID唯一性:添加的自定义ID需唯一,若重复添加相同ID,后续添加的向量会覆盖之前的向量。
- 索引操作兼容性:包装后的IndexIDMap支持基础索引的所有方法(如search、reset),但部分近似索引(如IndexIVFPQ)需先训练基础索引,再进行包装和添加ID。
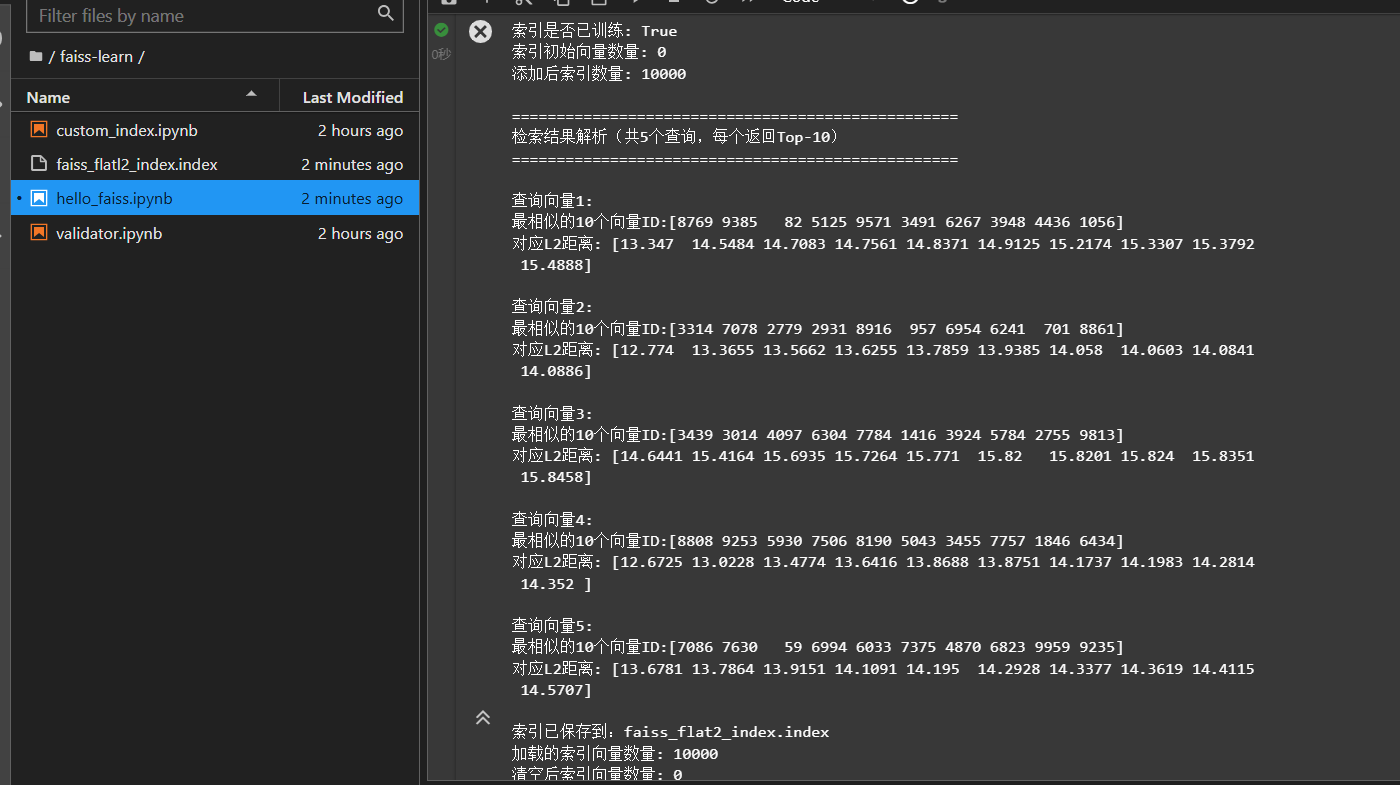
Faiss示例:随机向量精确检索
- 串联Faiss核心操作:向量生成、索引创建、向量添加、检索、结果解析
- 基础API使用方法。
总结
- Faiss:大规模向量检索数据库,偏向算法实现,非完整数据库,存储需结合Milvus等自行集成。
- Faiss数据结构:Index及其派生类,支持精确检索和近似检索。
- Faiss自定义ID映射:通过IndexIDMap实现,支持自定义向量ID。