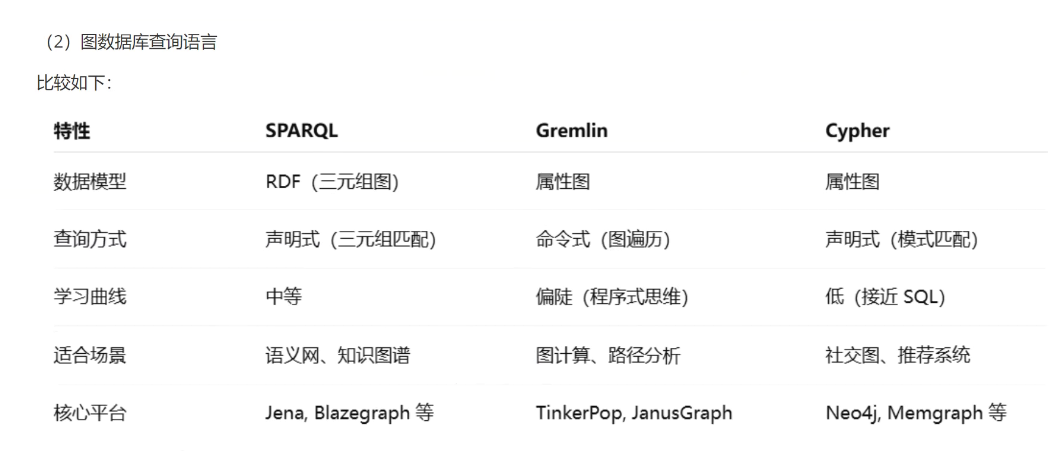
一:查询语言介绍
1.为什么不使用sql
关系型数据库查询语言------SQL
方式:数据以表的形式存在, 有比较强的schema定义, 表和表之间的数据关联以join的方式实现.
缺点:MySQL主要是存储和查询二维表数据,对三元组数据没有单独意义;
多跳关联查询需要多表连接,效率低
2.图数据查询语言的区别
二:命名实体识别(NER)
2.1基础知识
2.1.1什么是NER
-
实体:文本之中承载信息的语义单元。
-
常见的实体包括七种类别:人名、地名、机构名、时间、日期、货币、百分比。
-
实体抽取:又称为命名实体识别,指的是从文本之中抽取出命名性实体,并把这些实体划分到指定的类别。
2.1.2识别后格式
原文本:
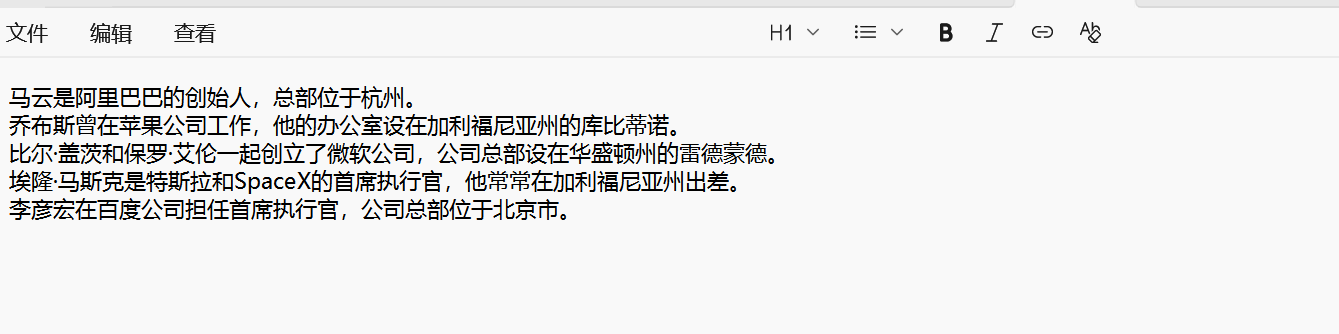
命名实体后的文本:
总体是字典格式,里面的命名实体是双层列表嵌套格式,下标是左闭右开.

补充:文本分类后的格式

2.2命名实体识别的方法
2.2.1基于规则的方法实现NER
使用自定义规则匹配NER:
eg:使用正则表达式匹配NER
优点:方便,快捷
缺点:泛用性差,后期格式越来越复杂,难以维护
2.2.2基于机器学习方法实现NER
机器学习把NER转换为序列标注任务
1.实现步骤:
-
人工选择特征
-
训练模型
-
预测实体
2.模型选择
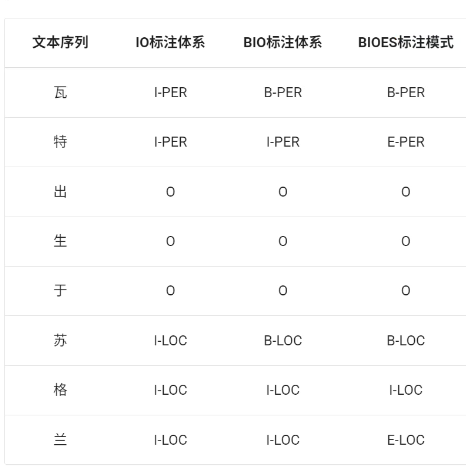
机器学习的方法是把实体抽取任务转换为序列任务,每个token做标注(理论上所有分类模型都可以作为标注模型,但是效果最好的是条件随机场(CRF)):
B:开头
E:结尾
3.缺点:
缺点:依赖特征的选择,特征选择的不好,很难有好的效果.
2.2.3基于深度学习的方法实现NER
深度学习也是把NER转换为序列标注任务
1.概念:
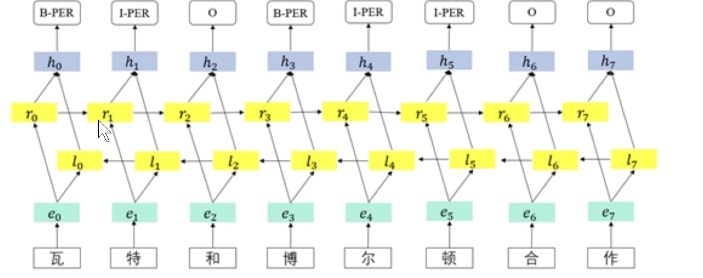
基于深度学习的方法主要使用神经网络模型,结合条件随机场模型。常用的神经网络模型包括卷积神经网络(CNN)、循环神经网络(RNN)、长短期记忆网络(LSTM)等,其中BiLSTM-CRF是目前最为常用的命名实体识别模型
2.原理:
3.优缺点
优点:特征靠模型自己提取
缺点:需要大量的标注文本
2.3NER评测标准
精确率:模型识别出来的实体中,被所有预测为正的样本中实际为正样本的概率
召回率:模型识别出来的实体中,实际为正的样本中被预测为正样本的概率
F1值: 准确率和召回率的调和平均值,可以对系统的性能进行综合性的评价