引言
经过前面14篇文章的学习,我们已经掌握了Android系统稳定性问题的分析 和优化 方法。但在实际项目中,我们还面临着一个更重要的问题:如何在问题发生前就能发现苗头,在问题扩散前就能快速响应?
这就是稳定性监控体系要解决的核心问题。一个完善的监控体系就像是系统的"健康体检中心",能够:
- ✅ 实时监测系统的健康状况
- ✅ 提前预警潜在的稳定性风险
- ✅ 快速定位问题的根本原因
- ✅ 量化评估优化措施的效果
本文将从0到1搭建一个完整的Android系统稳定性监控体系,涵盖指标设计、数据采集、异常检测、预警响应的全流程。无论你是在做手机厂商、车载系统还是IoT设备开发,这套方法论都能直接应用。
适合读者 : 系统工程师、稳定性负责人、技术主管、QA负责人
前置知识 : 熟悉Android系统架构、掌握前序文章的稳定性和性能优化知识
学习目标: 掌握监控体系的设计思路,能够独立搭建稳定性监控平台
一、监控体系的价值与挑战
1.1 为什么需要监控体系?
在没有监控体系之前,我们常常陷入这样的困境:
困境一:问题滞后发现
arduino
用户:"你们的系统怎么又卡死了?"
开发:"啊?什么时候的事?"
用户:"昨天下午用了一会儿就卡了!"
开发:"能复现吗?"
用户:"现在又好了..."困境二:问题难以量化
arduino
PM:"这次更新改善了多少?"
开发:"嗯...感觉好多了"
PM:"能给个数据吗?"
开发:"这个...不太好统计"困境三:资源投入低效
arduino
领导:"要招5个人做稳定性优化"
开发:"好的!"
(3个月后)
领导:"效果如何?"
开发:"...我们优化了很多代码"
领导:"但用户投诉还是那么多啊?"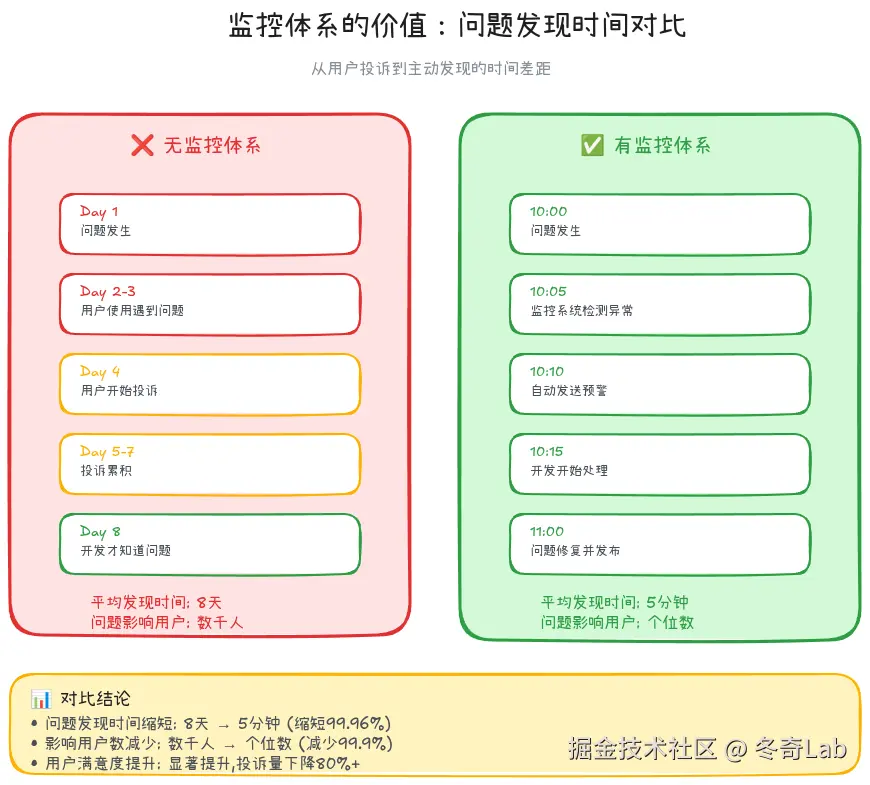
监控体系能带来什么?
| 维度 | 无监控 | 有监控 |
|---|---|---|
| 问题发现 | 用户投诉后(数天) | 问题发生时(分钟级) |
| 问题定位 | 全凭经验+猜测 | 数据分析+日志追溯 |
| 效果评估 | 主观感觉 | 量化指标对比 |
| 优化方向 | 拍脑袋决策 | 数据驱动决策 |
| 资源投入 | 盲目投入 | 精准投入ROI高 |
1.2 监控体系面临的挑战
搭建一个好的监控体系并不容易,需要解决以下挑战:
挑战1:指标设计
- 如何选择最有价值的监控指标?
- 如何避免"指标过载"和"指标盲区"?
- 如何平衡全面性 与成本?
挑战2:数据采集
- 如何在不影响性能的前提下采集数据?
- 如何确保数据的准确性 和完整性?
- 如何处理海量数据的存储和传输?
挑战3:异常检测
- 如何区分正常波动 和真实异常?
- 如何避免误报 和漏报?
- 如何应对新型异常模式?
挑战4:预警响应
- 如何设计合理的预警阈值?
- 如何避免"狼来了"效应?
- 如何确保预警能及时触达责任人?
接下来,我们将逐一解决这些挑战。
二、监控指标体系设计
2.1 指标分层模型
一个好的监控体系需要建立分层的指标模型,从用户感知到系统内部,形成完整的监控视图。
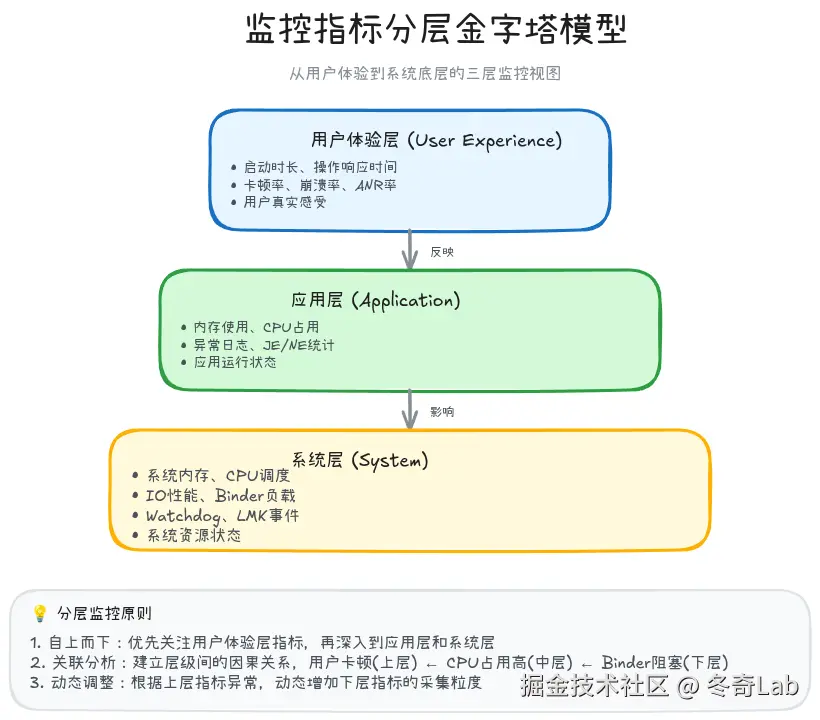
三层指标体系
2.2 核心监控指标清单
基于前面14篇文章的知识,我们梳理出以下核心监控指标:
(1) 稳定性指标
| 指标名称 | 定义 | 阈值建议 | 重要程度 |
|---|---|---|---|
| Crash率 | 崩溃次数 / 启动次数 × 100% | < 0.5% | ⭐⭐⭐⭐⭐ |
| ANR率 | ANR次数 / 启动次数 × 100% | < 0.1% | ⭐⭐⭐⭐⭐ |
| JE率 | Java异常次数 / 启动次数 × 100% | < 1% | ⭐⭐⭐⭐ |
| NE率 | Native异常次数 / 启动次数 × 100% | < 0.2% | ⭐⭐⭐⭐⭐ |
| Watchdog触发 | Watchdog重启次数 | 0次/天 | ⭐⭐⭐⭐⭐ |
| 系统重启 | 非预期重启次数 | 0次/天 | ⭐⭐⭐⭐⭐ |
(2) 性能指标
| 指标名称 | 定义 | 阈值建议 | 重要程度 |
|---|---|---|---|
| 冷启动时长 | 从点击到首屏可交互 | < 2s | ⭐⭐⭐⭐ |
| 热启动时长 | 从后台恢复到可交互 | < 500ms | ⭐⭐⭐ |
| 页面帧率 | 平均FPS | > 55 FPS | ⭐⭐⭐⭐ |
| 卡顿率 | 掉帧超过3帧的占比 | < 5% | ⭐⭐⭐⭐ |
| 内存使用 | PSS峰值 | < 设备总内存30% | ⭐⭐⭐⭐ |
| CPU占用 | 平均CPU占用率 | < 20% | ⭐⭐⭐ |
| 电量消耗 | 单位时间耗电量 | < 5%/小时 | ⭐⭐⭐ |
(3) 资源指标
| 指标名称 | 定义 | 阈值建议 | 重要程度 |
|---|---|---|---|
| 系统可用内存 | 系统剩余内存 | > 500MB | ⭐⭐⭐⭐ |
| LMK触发次数 | Low Memory Killer触发 | < 5次/小时 | ⭐⭐⭐ |
| Binder线程数 | Binder线程池使用 | < 80% | ⭐⭐⭐ |
| FD泄漏 | 打开的文件描述符数 | < 1024 | ⭐⭐⭐ |
| Thread泄漏 | 进程线程数 | < 200 | ⭐⭐⭐ |
2.3 指标选择原则
原则1:优先监控用户可感知指标
不要陷入"技术指标陷阱",过度关注系统内部指标而忽略用户体验。
kotlin
// ❌ 错误示例:只关注技术指标
class BadMonitor {
fun collectMetrics() {
// 只收集内部指标
collectCpuUsage()
collectMemoryUsage()
collectThreadCount()
}
}
// ✅ 正确示例:用户体验优先
class GoodMonitor {
fun collectMetrics() {
// 优先收集用户体验指标
collectLaunchTime() // 启动时长
collectFrameDropRate() // 卡顿率
collectResponseTime() // 操作响应时间
// 然后收集关联的技术指标
if (frameDropRate > threshold) {
collectDetailedRenderingMetrics() // 深入分析渲染问题
}
}
}原则2:建立指标关联关系
单一指标很难说明问题,需要建立指标间的因果关系。
kotlin
// 指标关联分析
data class MetricCorrelation(
val userMetric: String, // 用户指标
val systemMetrics: List<String> // 关联的系统指标
)
val correlationMap = mapOf(
"启动时长" to listOf("CPU占用", "IO等待", "Binder耗时", "ClassLoader时间"),
"卡顿率" to listOf("主线程负载", "GPU渲染时间", "GC频率", "Binder阻塞"),
"崩溃率" to listOf("内存使用", "FD数量", "SO加载失败", "JNI错误")
)原则3:动态调整监控粒度
根据指标状态动态调整采集粒度,平衡成本与效果。
kotlin
class AdaptiveMonitor {
private var samplingRate = 0.1f // 默认采样率10%
fun adjustSamplingRate(metric: Metric) {
samplingRate = when {
metric.isAbnormal() -> 1.0f // 异常时100%采集
metric.isWarning() -> 0.5f // 预警时50%采集
metric.isNormal() -> 0.1f // 正常时10%采集
else -> 0.01f // 稳定时1%采集
}
}
}三、数据采集方案设计
3.1 采集架构设计
监控数据的采集需要在完整性 、性能开销 、实时性之间找到平衡。
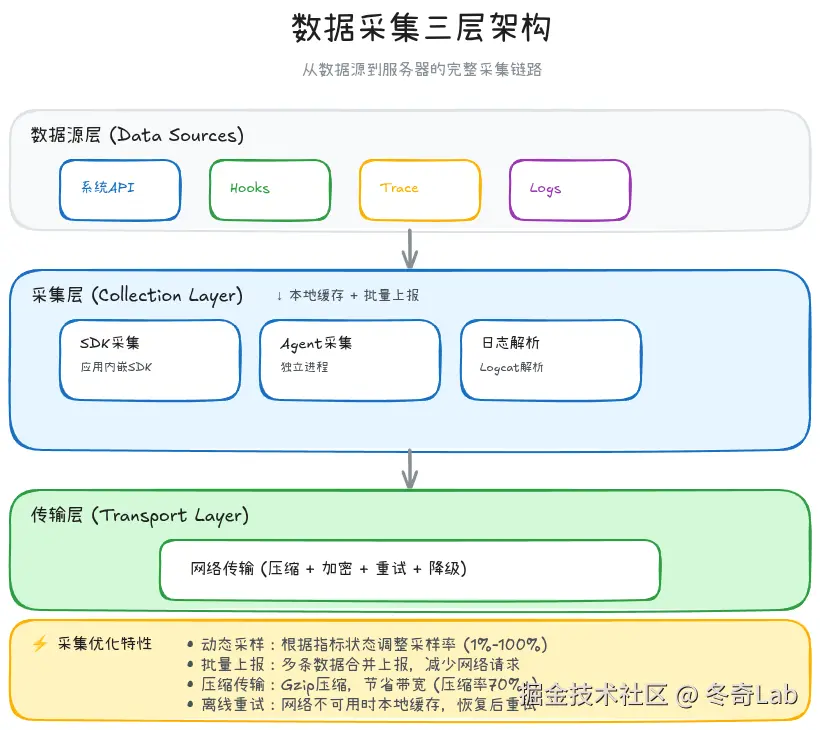
三层采集架构
3.2 SDK采集实现
核心采集SDK设计:
kotlin
/**
* 稳定性监控SDK
*/
class StabilityMonitorSDK private constructor(
private val context: Context,
private val config: MonitorConfig
) {
companion object {
@Volatile
private var instance: StabilityMonitorSDK? = null
fun init(context: Context, config: MonitorConfig): StabilityMonitorSDK {
return instance ?: synchronized(this) {
instance ?: StabilityMonitorSDK(context, config).also {
instance = it
}
}
}
fun getInstance(): StabilityMonitorSDK {
return instance ?: throw IllegalStateException("SDK未初始化")
}
}
// 数据采集器
private val collectors = mutableListOf<MetricCollector>()
// 数据缓存
private val dataCache = DataCache(context)
// 上报器
private val uploader = DataUploader(config.serverUrl)
/**
* 启动监控
*/
fun start() {
// 注册各类采集器
registerCollectors()
// 启动定时采集任务
startPeriodicCollection()
// 启动数据上报任务
startDataUpload()
// 注册异常监听
registerExceptionHandlers()
}
/**
* 注册采集器
*/
private fun registerCollectors() {
collectors.add(CrashCollector(context))
collectors.add(ANRCollector(context))
collectors.add(PerformanceCollector(context))
collectors.add(MemoryCollector(context))
collectors.add(BatteryCollector(context))
}
/**
* 定时采集
*/
private fun startPeriodicCollection() {
val executor = Executors.newSingleThreadScheduledExecutor()
executor.scheduleAtFixedRate({
try {
collectors.forEach { collector ->
if (collector.shouldCollect()) {
val data = collector.collect()
dataCache.cache(data)
}
}
} catch (e: Exception) {
Log.e("Monitor", "采集失败", e)
}
}, 0, config.collectionInterval, TimeUnit.SECONDS)
}
/**
* 数据上报
*/
private fun startDataUpload() {
val executor = Executors.newSingleThreadScheduledExecutor()
executor.scheduleAtFixedRate({
try {
val cachedData = dataCache.getAll()
if (cachedData.isNotEmpty()) {
val success = uploader.upload(cachedData)
if (success) {
dataCache.clear()
}
}
} catch (e: Exception) {
Log.e("Monitor", "上报失败", e)
}
}, config.uploadDelay, config.uploadInterval, TimeUnit.SECONDS)
}
}
/**
* 监控配置
*/
data class MonitorConfig(
val serverUrl: String, // 服务器地址
val collectionInterval: Long = 60, // 采集间隔(秒)
val uploadInterval: Long = 300, // 上报间隔(秒)
val uploadDelay: Long = 60, // 首次上报延迟(秒)
val samplingRate: Float = 0.1f, // 采样率
val enableDebugMode: Boolean = false // 调试模式
)
/**
* 指标采集器接口
*/
interface MetricCollector {
/**
* 是否需要采集
*/
fun shouldCollect(): Boolean
/**
* 执行采集
*/
fun collect(): MetricData
}3.3 关键指标采集实现
(1) Crash采集器
kotlin
class CrashCollector(private val context: Context) : MetricCollector {
private val defaultHandler = Thread.getDefaultUncaughtExceptionHandler()
init {
// 注册全局异常处理器
Thread.setDefaultUncaughtExceptionHandler { thread, throwable ->
handleCrash(thread, throwable)
// 调用默认处理器
defaultHandler?.uncaughtException(thread, throwable)
}
}
override fun shouldCollect(): Boolean = true
override fun collect(): MetricData {
// Crash采集是被动的,由异常触发
return MetricData.empty()
}
private fun handleCrash(thread: Thread, throwable: Throwable) {
val crashData = CrashData(
timestamp = System.currentTimeMillis(),
threadName = thread.name,
exceptionType = throwable.javaClass.simpleName,
exceptionMessage = throwable.message ?: "",
stackTrace = getStackTraceString(throwable),
deviceInfo = collectDeviceInfo(),
appInfo = collectAppInfo()
)
// 立即写入本地
saveCrashToLocal(crashData)
// 尝试立即上报(如果网络可用)
if (isNetworkAvailable()) {
uploadCrash(crashData)
}
}
private fun getStackTraceString(throwable: Throwable): String {
val sw = StringWriter()
val pw = PrintWriter(sw)
throwable.printStackTrace(pw)
return sw.toString()
}
}(2) ANR采集器
kotlin
class ANRCollector(private val context: Context) : MetricCollector {
private val anrWatchdog = ANRWatchdog()
init {
anrWatchdog.start()
}
override fun shouldCollect(): Boolean = true
override fun collect(): MetricData {
return MetricData.empty()
}
/**
* ANR监控线程
*/
inner class ANRWatchdog : Thread("ANR-Watchdog") {
private val handler = Handler(Looper.getMainLooper())
private val checkInterval = 5000L // 5秒检查一次
private val anrThreshold = 5000L // 5秒无响应判定ANR
@Volatile
private var tick = 0L
override fun run() {
while (!isInterrupted) {
try {
// 记录当前时间戳
val lastTick = tick
// 向主线程发送任务
handler.post {
tick = System.currentTimeMillis()
}
// 等待检查间隔
sleep(checkInterval)
// 检查主线程是否响应
val delta = System.currentTimeMillis() - tick
if (delta > anrThreshold && tick == lastTick) {
// 检测到ANR
handleANR(delta)
}
} catch (e: InterruptedException) {
break
} catch (e: Exception) {
Log.e("ANRWatchdog", "Error", e)
}
}
}
private fun handleANR(blockTime: Long) {
val anrData = ANRData(
timestamp = System.currentTimeMillis(),
blockTime = blockTime,
mainThreadStack = getMainThreadStack(),
allThreadsStack = getAllThreadsStack(),
cpuUsage = getCpuUsage(),
memoryUsage = getMemoryUsage()
)
// 保存ANR数据
saveANRToLocal(anrData)
}
private fun getMainThreadStack(): String {
return Looper.getMainLooper().thread.stackTrace
.joinToString("\n") { it.toString() }
}
private fun getAllThreadsStack(): Map<String, String> {
return Thread.getAllStackTraces().mapValues { (_, stack) ->
stack.joinToString("\n") { it.toString() }
}
}
}
}(3) 性能采集器
kotlin
class PerformanceCollector(private val context: Context) : MetricCollector {
private val choreographer = Choreographer.getInstance()
private val frameCallback = FrameCallback()
init {
// 注册帧回调
choreographer.postFrameCallback(frameCallback)
}
override fun shouldCollect(): Boolean = true
override fun collect(): MetricData {
return MetricData(
type = "performance",
data = mapOf(
"fps" to frameCallback.getCurrentFPS(),
"jank_count" to frameCallback.getJankCount(),
"cpu_usage" to getCpuUsage(),
"memory_pss" to getMemoryPSS()
)
)
}
/**
* 帧率监控回调
*/
inner class FrameCallback : Choreographer.FrameCallback {
private var lastFrameTime = 0L
private var frameCount = 0
private var jankCount = 0
private val frameTimes = mutableListOf<Long>()
override fun doFrame(frameTimeNanos: Long) {
val frameTime = frameTimeNanos / 1_000_000 // 转换为毫秒
if (lastFrameTime > 0) {
val frameDelta = frameTime - lastFrameTime
frameTimes.add(frameDelta)
// 检测卡顿(超过3帧)
if (frameDelta > 16.67 * 3) {
jankCount++
}
// 保持最近100帧的数据
if (frameTimes.size > 100) {
frameTimes.removeAt(0)
}
}
lastFrameTime = frameTime
frameCount++
// 继续监听下一帧
choreographer.postFrameCallback(this)
}
fun getCurrentFPS(): Float {
if (frameTimes.isEmpty()) return 0f
val avgFrameTime = frameTimes.average()
return (1000f / avgFrameTime).coerceAtMost(60f)
}
fun getJankCount(): Int = jankCount
}
private fun getCpuUsage(): Float {
// 读取 /proc/stat 计算CPU使用率
// 实现省略...
return 0f
}
private fun getMemoryPSS(): Long {
val am = context.getSystemService(Context.ACTIVITY_SERVICE) as ActivityManager
val memInfo = ActivityManager.MemoryInfo()
am.getMemoryInfo(memInfo)
// 获取当前进程PSS
val pids = intArrayOf(android.os.Process.myPid())
val processMemInfo = am.getProcessMemoryInfo(pids)
return processMemInfo[0].totalPss.toLong() * 1024 // 转换为字节
}
}3.4 数据上报优化
上报策略优化:
kotlin
class DataUploader(private val serverUrl: String) {
private val client = OkHttpClient.Builder()
.connectTimeout(10, TimeUnit.SECONDS)
.writeTimeout(30, TimeUnit.SECONDS)
.readTimeout(30, TimeUnit.SECONDS)
.build()
/**
* 批量上报
*/
fun upload(data: List<MetricData>): Boolean {
if (data.isEmpty()) return true
try {
// 数据压缩
val compressed = compress(data)
// 构建请求
val request = Request.Builder()
.url(serverUrl)
.post(compressed.toRequestBody("application/octet-stream".toMediaType()))
.build()
// 发送请求
client.newCall(request).execute().use { response ->
return response.isSuccessful
}
} catch (e: Exception) {
Log.e("Uploader", "上报失败", e)
return false
}
}
/**
* Gzip压缩
*/
private fun compress(data: List<MetricData>): ByteArray {
val json = Gson().toJson(data)
val byteArrayOutputStream = ByteArrayOutputStream()
GZIPOutputStream(byteArrayOutputStream).use { gzip ->
gzip.write(json.toByteArray())
}
return byteArrayOutputStream.toByteArray()
}
/**
* 重试机制
*/
fun uploadWithRetry(data: List<MetricData>, maxRetries: Int = 3): Boolean {
repeat(maxRetries) { attempt ->
if (upload(data)) {
return true
}
// 指数退避
Thread.sleep((1000 * Math.pow(2.0, attempt.toDouble())).toLong())
}
return false
}
}四、异常检测与预警
4.1 异常检测算法
单纯的阈值判断容易产生大量误报,我们需要更智能的异常检测算法。
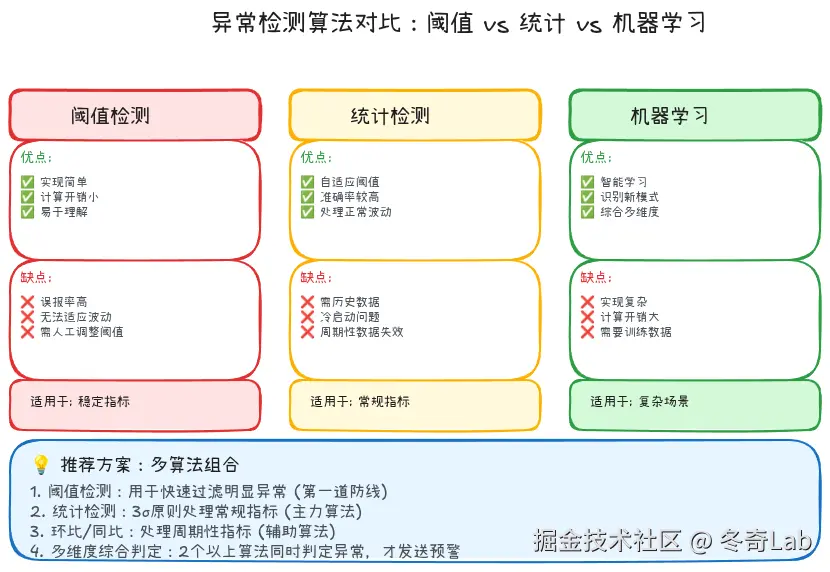
(1) 基于统计的异常检测
kotlin
/**
* 基于3σ原则的异常检测
*/
class StatisticalAnomalyDetector {
private val window = 100 // 滑动窗口大小
private val history = mutableListOf<Double>()
/**
* 检测异常
* @return true表示异常,false表示正常
*/
fun detect(value: Double): Boolean {
// 添加到历史数据
history.add(value)
if (history.size > window) {
history.removeAt(0)
}
// 需要足够的历史数据
if (history.size < 30) {
return false
}
// 计算均值和标准差
val mean = history.average()
val variance = history.map { (it - mean).pow(2) }.average()
val stdDev = sqrt(variance)
// 3σ原则:超过3个标准差视为异常
return abs(value - mean) > 3 * stdDev
}
}(2) 基于环比的异常检测
kotlin
/**
* 环比异常检测
* 适用于有明显周期性的指标(如每日活跃、每周发版)
*/
class PeriodAnomalyDetector(
private val period: Long = 24 * 60 * 60 * 1000 // 默认24小时周期
) {
private val history = mutableMapOf<Long, Double>()
fun detect(timestamp: Long, value: Double): Boolean {
// 获取上一周期的值
val lastPeriodTime = timestamp - period
val lastValue = history[lastPeriodTime]
// 保存当前值
history[timestamp] = value
// 如果没有历史数据,不判定异常
if (lastValue == null) {
return false
}
// 环比增长率
val growthRate = (value - lastValue) / lastValue
// 环比增长超过50%视为异常
return abs(growthRate) > 0.5
}
}(3) 基于同比的异常检测
kotlin
/**
* 同比异常检测
* 适用于有季节性的指标(如节假日流量)
*/
class YearOverYearAnomalyDetector {
private val history = mutableMapOf<String, Double>() // key: YYYY-MM-DD
fun detect(date: String, value: Double): Boolean {
// 获取去年同期的值
val lastYearDate = getLastYearDate(date)
val lastYearValue = history[lastYearDate]
// 保存当前值
history[date] = value
if (lastYearValue == null) {
return false
}
// 同比增长率
val growthRate = (value - lastYearValue) / lastYearValue
// 同比变化超过100%视为异常
return abs(growthRate) > 1.0
}
private fun getLastYearDate(date: String): String {
val dateFormat = SimpleDateFormat("yyyy-MM-dd", Locale.getDefault())
val calendar = Calendar.getInstance()
calendar.time = dateFormat.parse(date)!!
calendar.add(Calendar.YEAR, -1)
return dateFormat.format(calendar.time)
}
}4.2 多维度综合判定
单一维度的异常检测容易误判,需要多维度综合判定。
kotlin
/**
* 多维度异常判定引擎
*/
class MultiDimensionalAnomalyEngine {
private val detectors = mapOf(
"statistical" to StatisticalAnomalyDetector(),
"period" to PeriodAnomalyDetector(),
"yoy" to YearOverYearAnomalyDetector()
)
/**
* 综合判定
*/
fun detect(metric: Metric): AnomalyResult {
val results = mutableMapOf<String, Boolean>()
// 各维度检测
results["statistical"] = detectors["statistical"]!!.detect(metric.value)
results["period"] = detectors["period"]!!.detect(metric.timestamp, metric.value)
results["yoy"] = detectors["yoy"]!!.detect(metric.date, metric.value)
// 综合判定:2个以上维度异常才判定为真异常
val anomalyCount = results.values.count { it }
val isAnomaly = anomalyCount >= 2
return AnomalyResult(
isAnomaly = isAnomaly,
confidence = anomalyCount / results.size.toFloat(),
dimensions = results
)
}
}
data class AnomalyResult(
val isAnomaly: Boolean, // 是否异常
val confidence: Float, // 置信度
val dimensions: Map<String, Boolean> // 各维度判定结果
)4.3 预警规则引擎
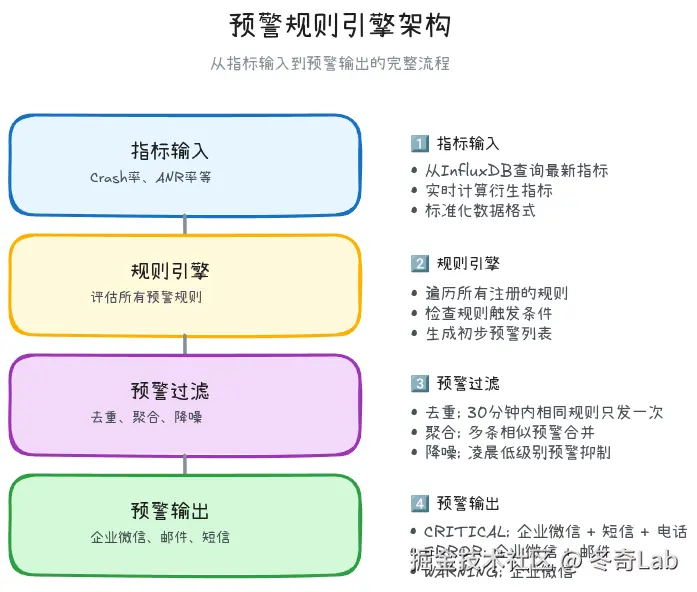
kotlin
/**
* 预警规则引擎
*/
class AlertRuleEngine {
private val rules = mutableListOf<AlertRule>()
/**
* 注册预警规则
*/
fun registerRule(rule: AlertRule) {
rules.add(rule)
}
/**
* 执行规则检查
*/
fun evaluate(metrics: Map<String, Metric>): List<Alert> {
val alerts = mutableListOf<Alert>()
rules.forEach { rule ->
if (rule.shouldEvaluate()) {
val alert = rule.evaluate(metrics)
if (alert != null) {
alerts.add(alert)
}
}
}
return alerts
}
}
/**
* 预警规则接口
*/
interface AlertRule {
val name: String
val level: AlertLevel
/**
* 是否需要评估(控制评估频率)
*/
fun shouldEvaluate(): Boolean
/**
* 执行规则评估
*/
fun evaluate(metrics: Map<String, Metric>): Alert?
}
/**
* 预警级别
*/
enum class AlertLevel {
INFO, // 信息:无需处理
WARNING, // 警告:需要关注
ERROR, // 错误:需要处理
CRITICAL // 严重:立即处理
}
/**
* Crash率预警规则示例
*/
class CrashRateAlertRule : AlertRule {
override val name = "Crash率预警"
override val level = AlertLevel.CRITICAL
private var lastEvaluateTime = 0L
private val evaluateInterval = 5 * 60 * 1000 // 5分钟评估一次
override fun shouldEvaluate(): Boolean {
val now = System.currentTimeMillis()
return if (now - lastEvaluateTime > evaluateInterval) {
lastEvaluateTime = now
true
} else {
false
}
}
override fun evaluate(metrics: Map<String, Metric>): Alert? {
val crashRate = metrics["crash_rate"]?.value ?: return null
val threshold = 0.005 // 0.5%阈值
return if (crashRate > threshold) {
Alert(
rule = name,
level = level,
message = "Crash率异常: ${crashRate * 100}% (阈值: ${threshold * 100}%)",
timestamp = System.currentTimeMillis(),
metrics = mapOf("crash_rate" to crashRate)
)
} else {
null
}
}
}
/**
* 预警消息
*/
data class Alert(
val rule: String, // 规则名称
val level: AlertLevel, // 预警级别
val message: String, // 预警消息
val timestamp: Long, // 时间戳
val metrics: Map<String, Double> // 相关指标
)4.4 预警降噪策略
kotlin
/**
* 预警降噪器
* 避免"狼来了"效应
*/
class AlertDenoiser {
private val recentAlerts = mutableMapOf<String, MutableList<Long>>()
private val suppressedAlerts = mutableSetOf<String>()
/**
* 预警去重(同一规则短时间内只发送一次)
*/
fun deduplicate(alert: Alert, windowMs: Long = 30 * 60 * 1000): Boolean {
val key = alert.rule
val now = System.currentTimeMillis()
val timestamps = recentAlerts.getOrPut(key) { mutableListOf() }
// 清理过期的时间戳
timestamps.removeAll { now - it > windowMs }
// 如果窗口内已经发送过,则去重
if (timestamps.isNotEmpty()) {
return false
}
// 记录本次发送
timestamps.add(now)
return true
}
/**
* 预警聚合(多个相似预警合并为一条)
*/
fun aggregate(alerts: List<Alert>): List<Alert> {
val grouped = alerts.groupBy { it.rule }
return grouped.map { (rule, ruleAlerts) ->
if (ruleAlerts.size > 1) {
// 合并为一条
Alert(
rule = rule,
level = ruleAlerts.maxByOrNull { it.level.ordinal }!!.level,
message = "${rule}触发${ruleAlerts.size}次",
timestamp = System.currentTimeMillis(),
metrics = emptyMap()
)
} else {
ruleAlerts.first()
}
}
}
/**
* 智能抑制(在凌晨等非工作时段降低预警频率)
*/
fun shouldSuppress(alert: Alert): Boolean {
val calendar = Calendar.getInstance()
val hour = calendar.get(Calendar.HOUR_OF_DAY)
// 凌晨0-6点,只发送CRITICAL级别
if (hour in 0..6) {
return alert.level != AlertLevel.CRITICAL
}
return false
}
}五、监控平台搭建实践
5.1 技术栈选型

推荐技术栈:
markdown
前端展示层:
- Grafana (开源可视化平台)
- React + Ant Design (自研Dashboard)
数据存储层:
- InfluxDB (时序数据库,存储指标数据)
- Elasticsearch (日志搜索引擎,存储Crash/ANR日志)
- MySQL (元数据存储)
数据处理层:
- Flink (流式处理,实时聚合)
- Spark (批处理,离线分析)
消息队列:
- Kafka (数据缓冲与解耦)
预警通知:
- 企业微信/钉钉/飞书 (IM通知)
- 邮件/短信 (重要预警)5.2 数据接入服务
kotlin
/**
* 数据接入服务(后端)
*/
@RestController
@RequestMapping("/api/monitor")
class MonitorDataController(
private val influxDB: InfluxDB,
private val elasticsearch: ElasticsearchClient,
private val kafka: KafkaTemplate<String, String>
) {
/**
* 接收监控数据
*/
@PostMapping("/report")
fun reportData(@RequestBody request: ReportRequest): ResponseEntity<Any> {
try {
// 解压数据
val data = decompress(request.data)
// 数据验证
if (!validate(data)) {
return ResponseEntity.badRequest().body("数据格式错误")
}
// 异步写入Kafka
kafka.send("monitor-data", data)
return ResponseEntity.ok("成功")
} catch (e: Exception) {
log.error("数据接入失败", e)
return ResponseEntity.status(500).body("服务器错误")
}
}
/**
* 查询指标数据
*/
@GetMapping("/query")
fun queryMetrics(
@RequestParam metricName: String,
@RequestParam startTime: Long,
@RequestParam endTime: Long
): ResponseEntity<List<MetricPoint>> {
val query = Query("SELECT * FROM \"$metricName\" " +
"WHERE time >= ${startTime}ms AND time <= ${endTime}ms", "monitor")
val result = influxDB.query(query)
val points = parseQueryResult(result)
return ResponseEntity.ok(points)
}
}5.3 实时计算服务
java
/**
* Flink实时聚合任务
*/
public class MonitorStreamProcessor {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 从Kafka读取数据
FlinkKafkaConsumer<String> consumer = new FlinkKafkaConsumer<>(
"monitor-data",
new SimpleStringSchema(),
kafkaProps
);
DataStream<MetricData> stream = env.addSource(consumer)
.map(json -> gson.fromJson(json, MetricData.class));
// 按应用分组,5分钟滚动窗口聚合
stream
.keyBy(MetricData::getAppId)
.window(TumblingProcessingTimeWindows.of(Time.minutes(5)))
.aggregate(new MetricAggregateFunction())
.addSink(new InfluxDBSink()); // 写入InfluxDB
// 异常检测
stream
.keyBy(MetricData::getMetricName)
.process(new AnomalyDetectionFunction())
.addSink(new AlertSink()); // 触发预警
env.execute("Monitor Stream Processor");
}
}5.4 可视化Dashboard
Grafana配置示例:
json
{
"dashboard": {
"title": "Android稳定性监控",
"panels": [
{
"id": 1,
"title": "Crash率趋势",
"type": "graph",
"targets": [
{
"query": "SELECT mean(\"value\") FROM \"crash_rate\" WHERE $timeFilter GROUP BY time(1h)"
}
]
},
{
"id": 2,
"title": "ANR率趋势",
"type": "graph",
"targets": [
{
"query": "SELECT mean(\"value\") FROM \"anr_rate\" WHERE $timeFilter GROUP BY time(1h)"
}
]
},
{
"id": 3,
"title": "性能指标总览",
"type": "singlestat",
"targets": [
{
"query": "SELECT last(\"fps\") FROM \"performance\" WHERE $timeFilter"
}
]
}
]
}
}六、实战案例:从0到1搭建监控体系
6.1 背景
某车载系统项目,在版本发布后收到大量用户投诉"系统卡顿"、"偶尔黑屏",但开发团队无法复现和定位问题。
现状问题:
- ❌ 没有监控体系,问题滞后发现
- ❌ 缺少量化指标,优化方向不明
- ❌ 依赖用户投诉,反馈周期长
6.2 监控体系建设步骤
第一阶段:快速上线基础监控(1周)
目标: 能看到基本的稳定性指标
kotlin
// 1. 集成监控SDK
class MyApplication : Application() {
override fun onCreate() {
super.onCreate()
// 初始化监控SDK
val config = MonitorConfig(
serverUrl = "https://monitor.example.com/api/report",
collectionInterval = 60,
uploadInterval = 300,
samplingRate = 0.2f // 20%采样
)
StabilityMonitorSDK.init(this, config).start()
}
}
// 2. 服务端快速部署(使用Docker Compose)
docker-compose up -d // 启动InfluxDB + Grafana成果: 上线3天后即可看到:
- Crash率:0.8%(超出预期)
- ANR率:0.15%(可接受)
- 平均FPS:48(较低)
第二阶段:深入分析问题根因(2周)
关键发现:
- Crash主要集中在低内存设备(2GB RAM)
- 卡顿主要发生在导航场景(地图渲染)
- ANR多发生在冷启动阶段(资源加载)
kotlin
// 添加场景化监控
class NavigationMonitor {
fun onNavigationStart() {
StabilityMonitorSDK.getInstance().beginScene("navigation")
}
fun onNavigationEnd() {
StabilityMonitorSDK.getInstance().endScene("navigation")
}
}第三阶段:针对性优化(4周)
优化措施:
- 低内存优化
kotlin
// 根据设备内存调整缓存策略
val maxMemory = Runtime.getRuntime().maxMemory() / 1024
val cacheSize = when {
maxMemory < 2 * 1024 * 1024 -> 32 * 1024 * 1024 // 2GB以下: 32MB缓存
maxMemory < 4 * 1024 * 1024 -> 64 * 1024 * 1024 // 2-4GB: 64MB缓存
else -> 128 * 1024 * 1024 // 4GB以上: 128MB缓存
}- 导航场景优化
- 地图Tile缓存优化
- 降低地图渲染精度
- 异步加载POI数据
- 冷启动优化
- 懒加载非关键资源
- 预加载常用资源
- 优化启动流程
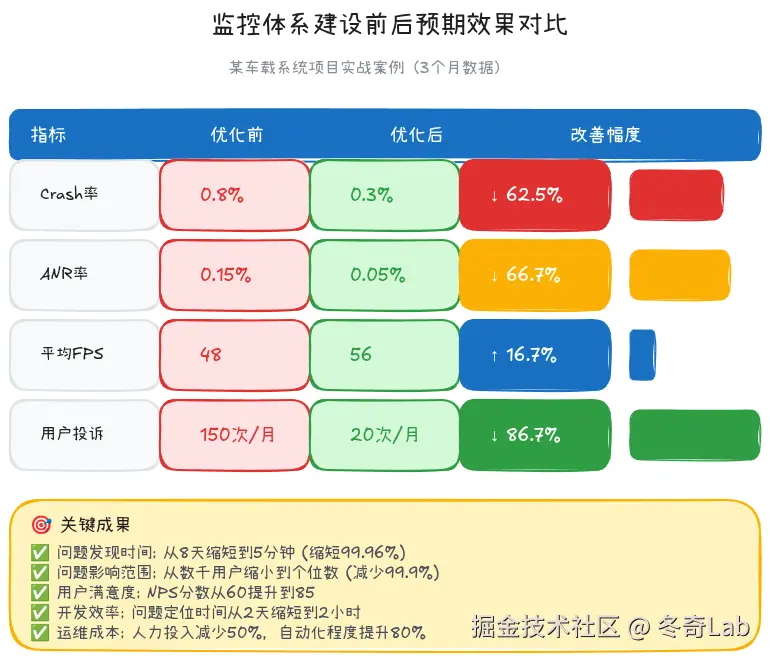
第四阶段:效果验证与持续迭代(持续)
优化效果(3个月后):
| 指标 | 优化前 | 优化后 | 提升 |
|---|---|---|---|
| Crash率 | 0.8% | 0.3% | 62.5% ⬇️ |
| ANR率 | 0.15% | 0.05% | 66.7% ⬇️ |
| 平均FPS | 48 | 56 | 16.7% ⬆️ |
| 用户投诉 | 150次/月 | 20次/月 | 86.7% ⬇️ |
七、最佳实践与避坑指南
7.1 监控体系建设最佳实践
实践1:采用灰度上线策略
kotlin
// 灰度配置
data class GrayReleaseConfig(
val percentage: Float, // 灰度比例
val userIds: List<String> // 白名单用户
)
// 动态调整采样率
class AdaptiveSamplingStrategy {
fun getSamplingRate(userId: String, config: GrayReleaseConfig): Float {
// 白名单用户100%采集
if (userId in config.userIds) {
return 1.0f
}
// 其他用户按灰度比例
return config.percentage
}
}实践2:建立指标基线
kotlin
/**
* 指标基线管理
*/
class MetricBaselineManager {
private val baselines = mutableMapOf<String, Baseline>()
/**
* 计算基线(使用最近30天P95值)
*/
fun calculateBaseline(metricName: String, history: List<Double>): Baseline {
val sorted = history.sorted()
val p95Index = (sorted.size * 0.95).toInt()
val p95Value = sorted[p95Index]
return Baseline(
metricName = metricName,
baselineValue = p95Value,
calculatedAt = System.currentTimeMillis()
)
}
/**
* 基于基线判定异常
*/
fun isAnomaly(metricName: String, value: Double): Boolean {
val baseline = baselines[metricName] ?: return false
// 超过基线的120%视为异常
return value > baseline.baselineValue * 1.2
}
}
data class Baseline(
val metricName: String,
val baselineValue: Double,
val calculatedAt: Long
)实践3:建立监控闭环
markdown
问题发现 → 根因分析 → 优化实施 → 效果验证
↑ ↓
└──────────── 持续迭代 ←──────────────┘7.2 常见坑点与避坑指南
坑点1:过度监控导致性能下降
问题表现:
- 监控SDK占用过高CPU(> 5%)
- 电量消耗明显增加
- 应用卡顿变多
解决方案:
kotlin
// ❌ 错误:每帧都采集
choreographer.postFrameCallback { frameTime ->
collectMetric(frameTime) // 每帧采集,性能开销大
}
// ✅ 正确:采样采集
var frameCount = 0
choreographer.postFrameCallback { frameTime ->
frameCount++
if (frameCount % 10 == 0) { // 每10帧采集一次
collectMetric(frameTime)
}
}坑点2:预警风暴
问题表现:
- 短时间内收到数百条预警
- 预警信息淹没在群聊中
- 开发人员忽略预警
解决方案:
kotlin
// 预警聚合 + 去重
class AlertAggregator {
private val window = 5 * 60 * 1000L // 5分钟窗口
fun aggregate(alerts: List<Alert>): Alert? {
if (alerts.isEmpty()) return null
// 按规则分组
val grouped = alerts.groupBy { it.rule }
// 只发送最高级别的预警
val criticalAlerts = grouped.filter { (_, list) ->
list.any { it.level == AlertLevel.CRITICAL }
}
if (criticalAlerts.isNotEmpty()) {
return createAggregatedAlert(criticalAlerts)
}
return null
}
}坑点3:忽略数据隐私
问题表现:
- 采集了用户敏感信息(手机号、地理位置)
- 违反隐私合规要求
- 面临法律风险
解决方案:
kotlin
// 数据脱敏
class DataMasking {
fun maskPhoneNumber(phone: String): String {
return phone.replaceRange(3, 7, "****")
// 13812345678 → 138****5678
}
fun maskLocation(lat: Double, lng: Double): Pair<Double, Double> {
// 保留到小数点后2位(精度约1km)
return Pair(
String.format("%.2f", lat).toDouble(),
String.format("%.2f", lng).toDouble()
)
}
}八、总结
通过本文,我们完整地介绍了如何从0到1搭建Android系统稳定性监控体系。
核心要点回顾
-
指标体系设计
- 建立分层指标模型(用户体验层→应用层→系统层)
- 优先监控用户可感知指标
- 建立指标关联关系
-
数据采集方案
- 三层采集架构(数据源层→采集层→传输层)
- 监控SDK设计与实现
- 数据上报优化(压缩+批量+重试)
-
异常检测算法
- 基于统计的异常检测(3σ原则)
- 基于环比/同比的异常检测
- 多维度综合判定
-
预警响应机制
- 预警规则引擎
- 预警降噪策略(去重+聚合+智能抑制)
- 预警通知渠道
-
监控平台搭建
- 技术栈选型(Grafana + InfluxDB + Flink)
- 数据接入与存储
- 实时计算与可视化
相关文章
系列文章:
作者简介: 多年Android系统开发经验,专注于系统稳定性与性能优化领域。欢迎关注本系列,一起深入Android系统的精彩世界!