TL;DR
- 场景:用二维 testSet 验证自写 K-Means,再切到 sklearn KMeans 跑真实数据并理解关键参数与 labels_。
- 结论:自写版重点在数据形状与标签列约定;sklearn 重点在 n_clusters 选择、收敛与版本参数兼容(algorithm='auto' 风险)。
- 产出:可复用的验证流程(读数→可视化→聚类→质心可视化)+ KMeans 参数与常见错误速查卡。

算法验证
函数编写完成后,先以 testSet 数据集测试模型运行效果(为了可以直观看出聚类效果,此处采用一个二维数据集进行验证)。testSet 数据集是一个二维数据集,每个观测值都只有两个特征,且数据之间采用空格进行分隔,因此可以使用 pd.read_table() 函数进行读取。
python
testSet = pd.read_table('testSet.txt', header=None)
testSet.head()
testSet.shape执行结果如下图是: 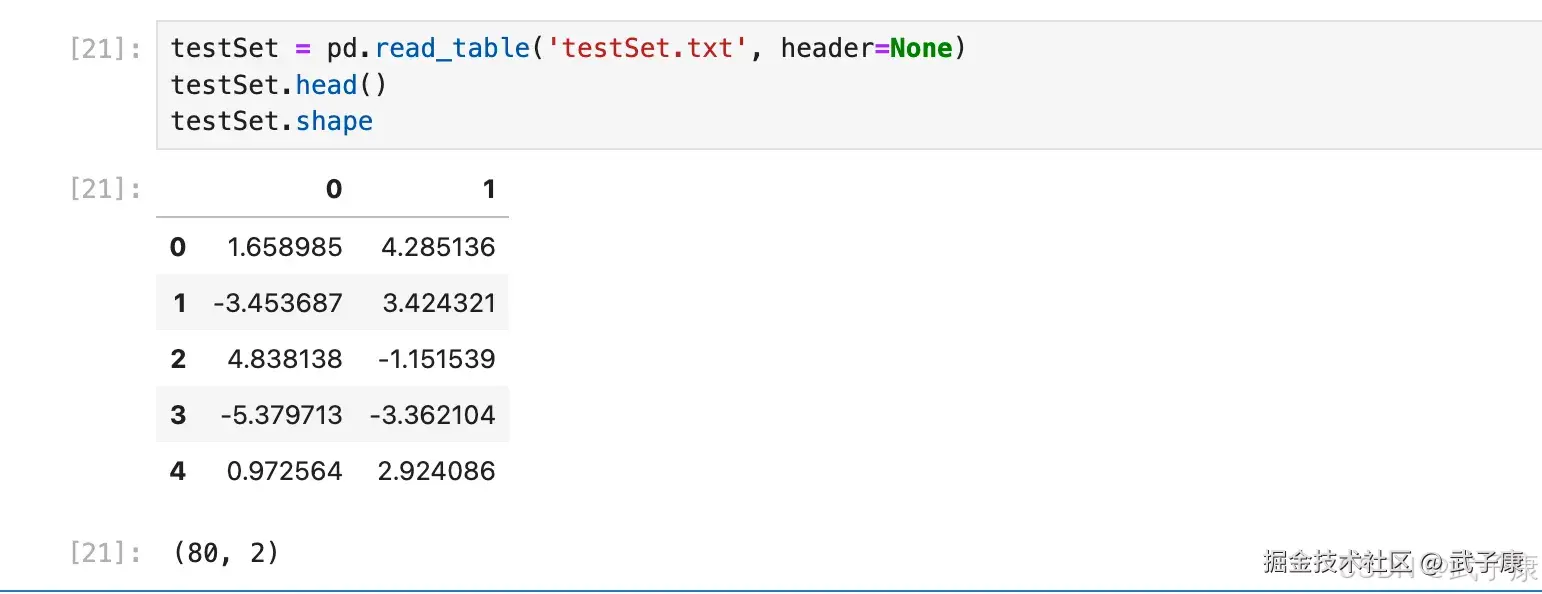 然后利用二维平面图观察其分布情况:
然后利用二维平面图观察其分布情况:
python
plt.scatter(testSet.iloc[:,0], testSet.iloc[:,1]);执行结果如下图所示: 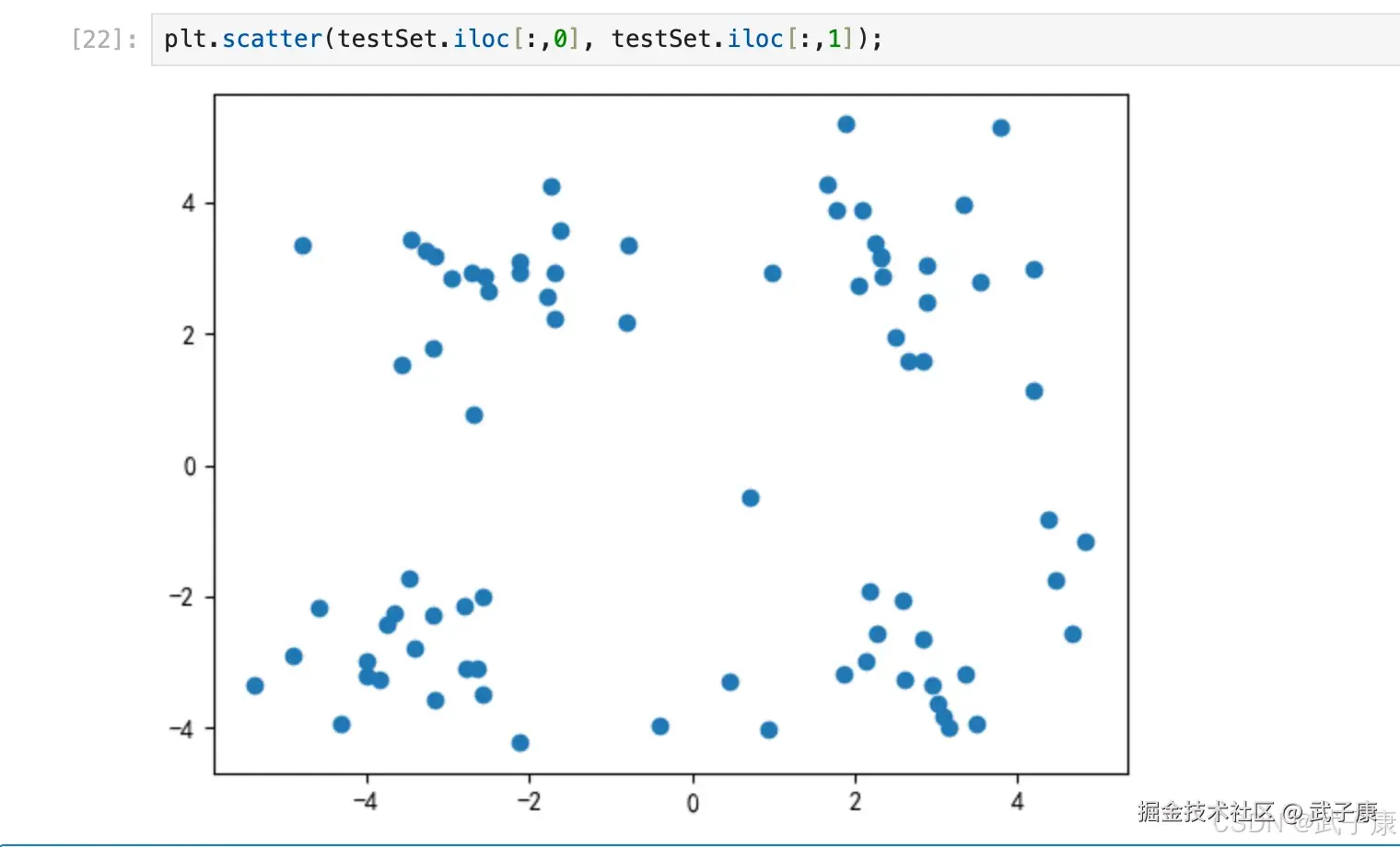 可以大概看出数据大概分布在空间的四个角上,后续我们对此进行验证。然后利用我们刚才编写的 K-Means 算法对其进行聚类,在执行算法之前需要添加一列虚拟标签列(算法是从倒数第二列开始计算特征值,因此这里需要人为增加多一列到最后)
可以大概看出数据大概分布在空间的四个角上,后续我们对此进行验证。然后利用我们刚才编写的 K-Means 算法对其进行聚类,在执行算法之前需要添加一列虚拟标签列(算法是从倒数第二列开始计算特征值,因此这里需要人为增加多一列到最后)
python
label = pd.DataFrame(np.zeros(testSet.shape[0]).reshape(-1, 1))
test_set = pd.concat([testSet, label], axis=1, ignore_index = True)
test_set.head()执行结果如下图所示: 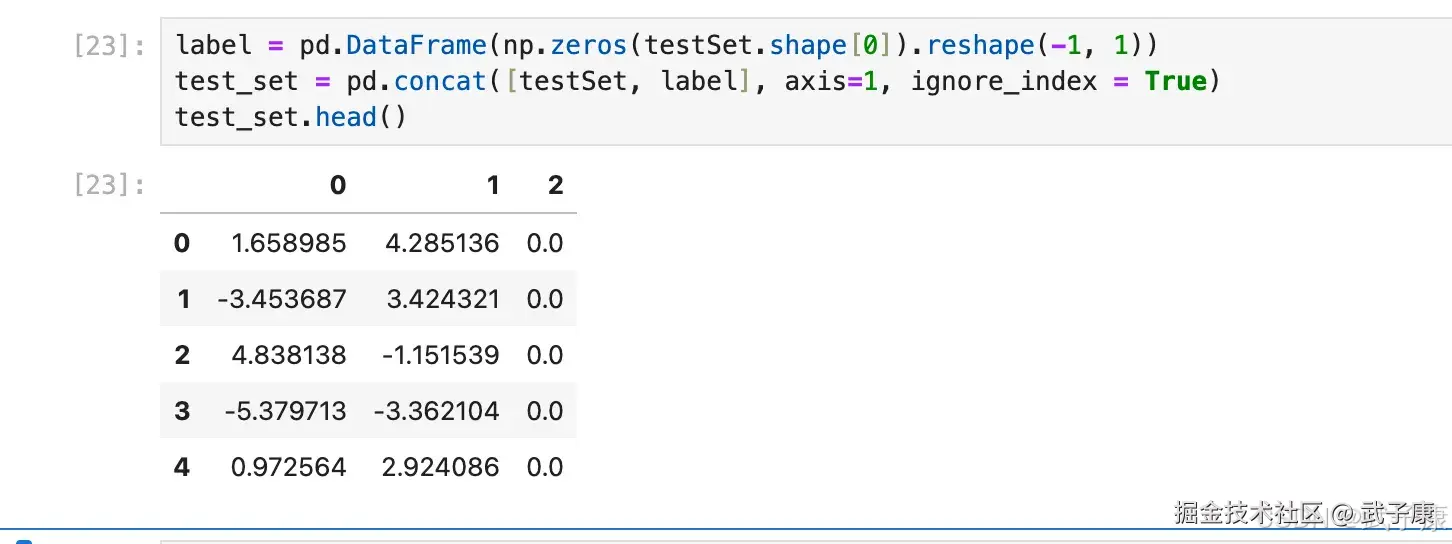 带入算法进行计算,根据二维平面坐标点的分布特征,我们可以考虑设置四个质心,即将其分为四个簇,并简单的查看运算结果:
带入算法进行计算,根据二维平面坐标点的分布特征,我们可以考虑设置四个质心,即将其分为四个簇,并简单的查看运算结果:
python
test_cent, test_cluster = kMeans(test_set, 4)
test_cent
test_cluster.head()执行结果如下图所示: 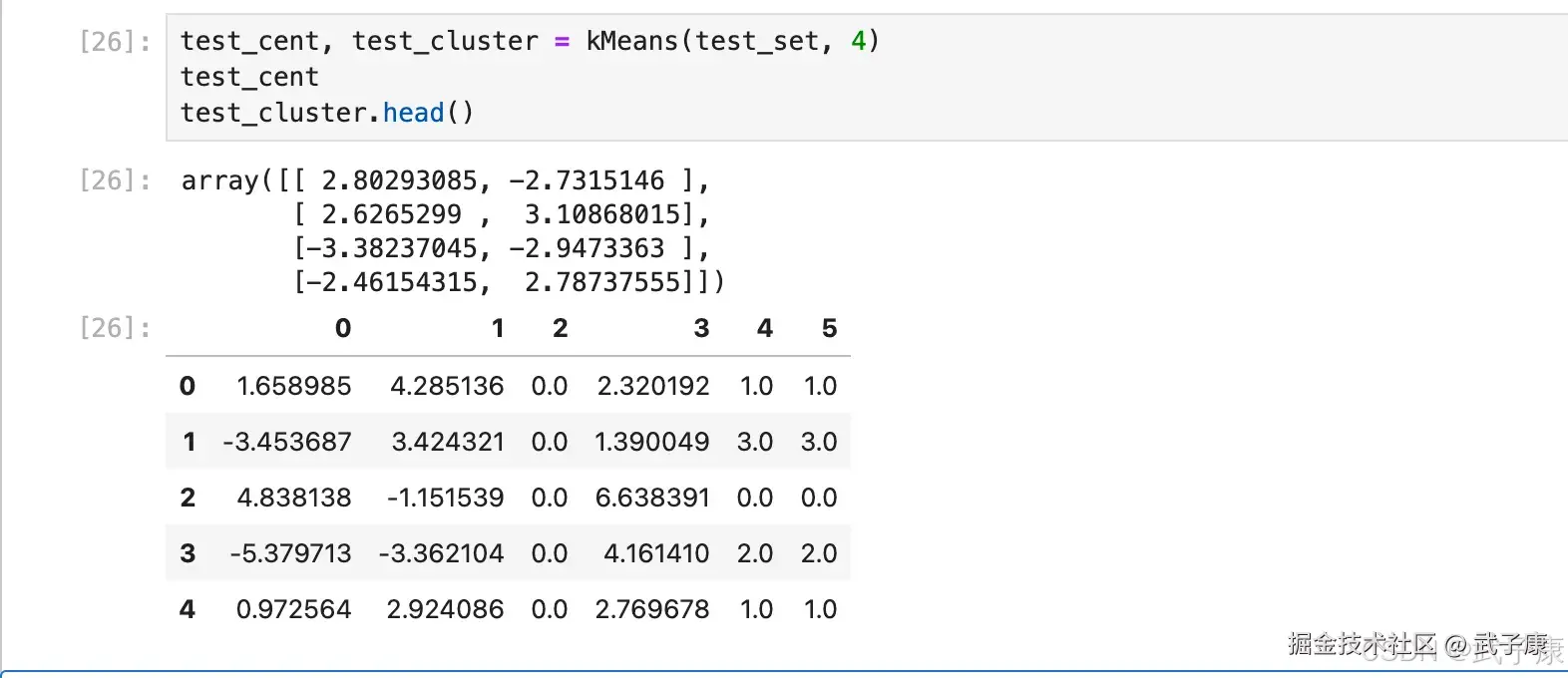 将分类结果进行可视化展示,使用 scatter 函数绘制不同分类点不同颜色的散点图,同时将质心也放入同一张图中进行观察:
将分类结果进行可视化展示,使用 scatter 函数绘制不同分类点不同颜色的散点图,同时将质心也放入同一张图中进行观察:
python
import matplotlib.pyplot as plt
# 绘制聚类点
plt.scatter(test_cluster.iloc[:, 0], test_cluster.iloc[:, 1], c=test_cluster.iloc[:, -1], cmap='viridis')
# 绘制聚类中心
plt.scatter(test_cent[:, 0], test_cent[:, 1], color='red', marker='x', s=100)
# 设置图形的标题和轴标签
plt.title('Cluster Plot with Centroids')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
# 显示图形
plt.show()执行结果如下图所示: 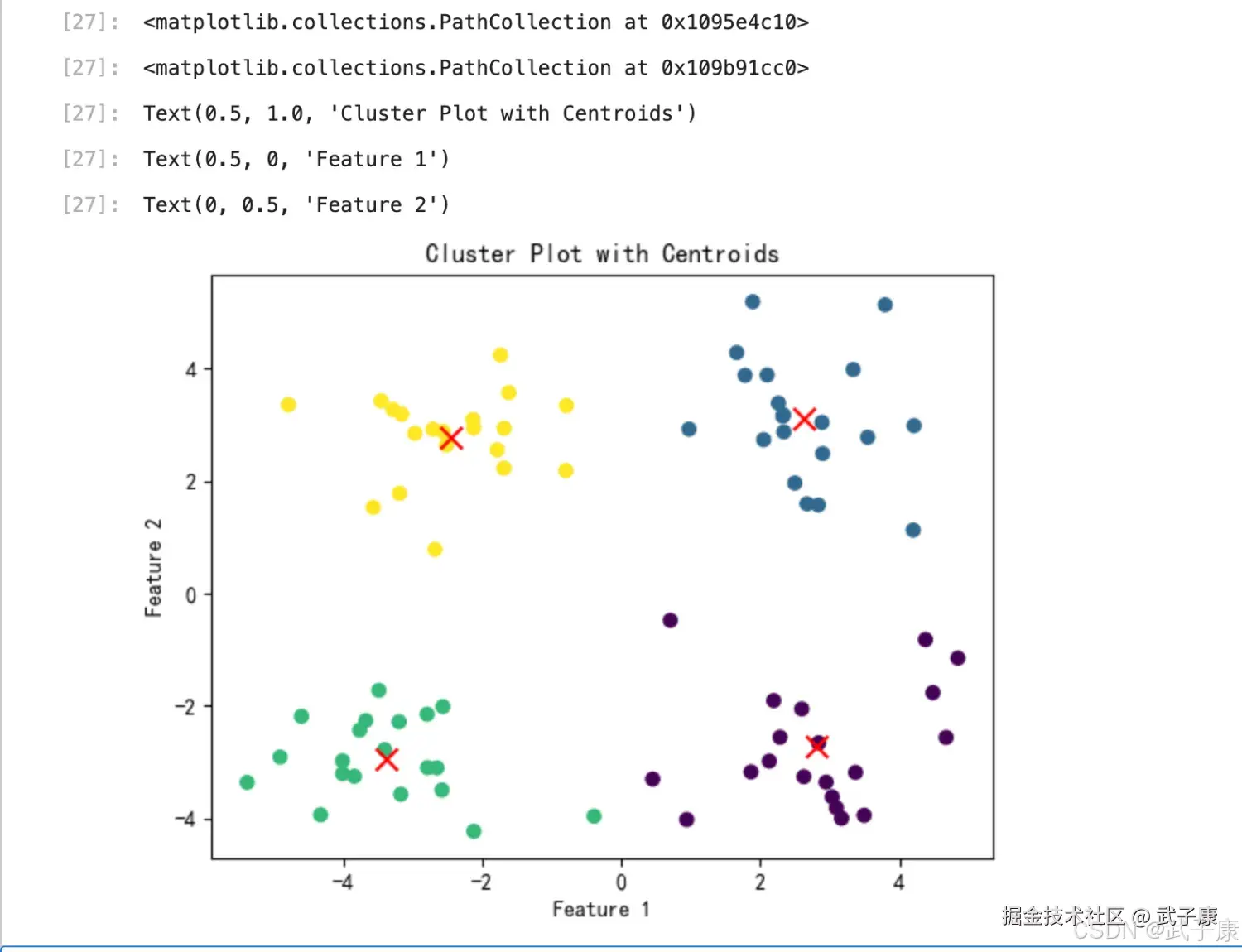 生成的图片如下所示:
生成的图片如下所示: 
sklearn实现 K-Means
python
from sklearn.cluster import KMeans
# KMeans 初始化示例
kmeans = KMeans(
n_clusters=8, # 聚类数量
init='k-means++', # 初始化质心的方法
n_init=10, # KMeans 算法重新运行的次数(初始质心选择不同)
max_iter=300, # 最大迭代次数
tol=0.0001, # 容忍度,控制收敛的阈值
verbose=0, # 控制输出日志的详细程度
random_state=None, # 随机种子控制聚类的随机性
copy_x=True, # 是否复制 X 数据
algorithm='auto' # 使用的 KMeans 算法,'auto' 已弃用,建议使用 'lloyd'
)
# 执行示例数据集上的 KMeans
# 例如,假设你有一个数据集 X:
# kmeans.fit(X)n_clusters
n_clusters 是 K-Means 中的 k ,表示着我们告诉模型我们要分几类,这是 K-Means当中唯一一个必填的参数,默认为 8 类,但通常我们聚类结果是一个小于 8 的结果,通常,在开始聚类的之前,我们并不知道 n_clusters 究竟是多少,因此我们要对它进行探索。 当我们拿到一个数据集,如果可能的话,我们希望能够通过绘图先观察一下这个数据集的数据分布,以此来为我们聚类时输入的 n_clusters 做一个参考。
首先,我们来自己创建一个数据集,这样的数据集是我们自己创建的,所以是有标签的。
python
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
# 创建数据集
X, y = make_blobs(n_samples=500, n_features=2, centers=4, random_state=1)
# 可视化数据集
plt.figure(figsize=(6, 6))
plt.scatter(X[:, 0], X[:, 1], marker='o', s=8) # s=8 表示点的大小
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.title('Scatter plot of generated blobs')
plt.show()对应结果如下图所示: 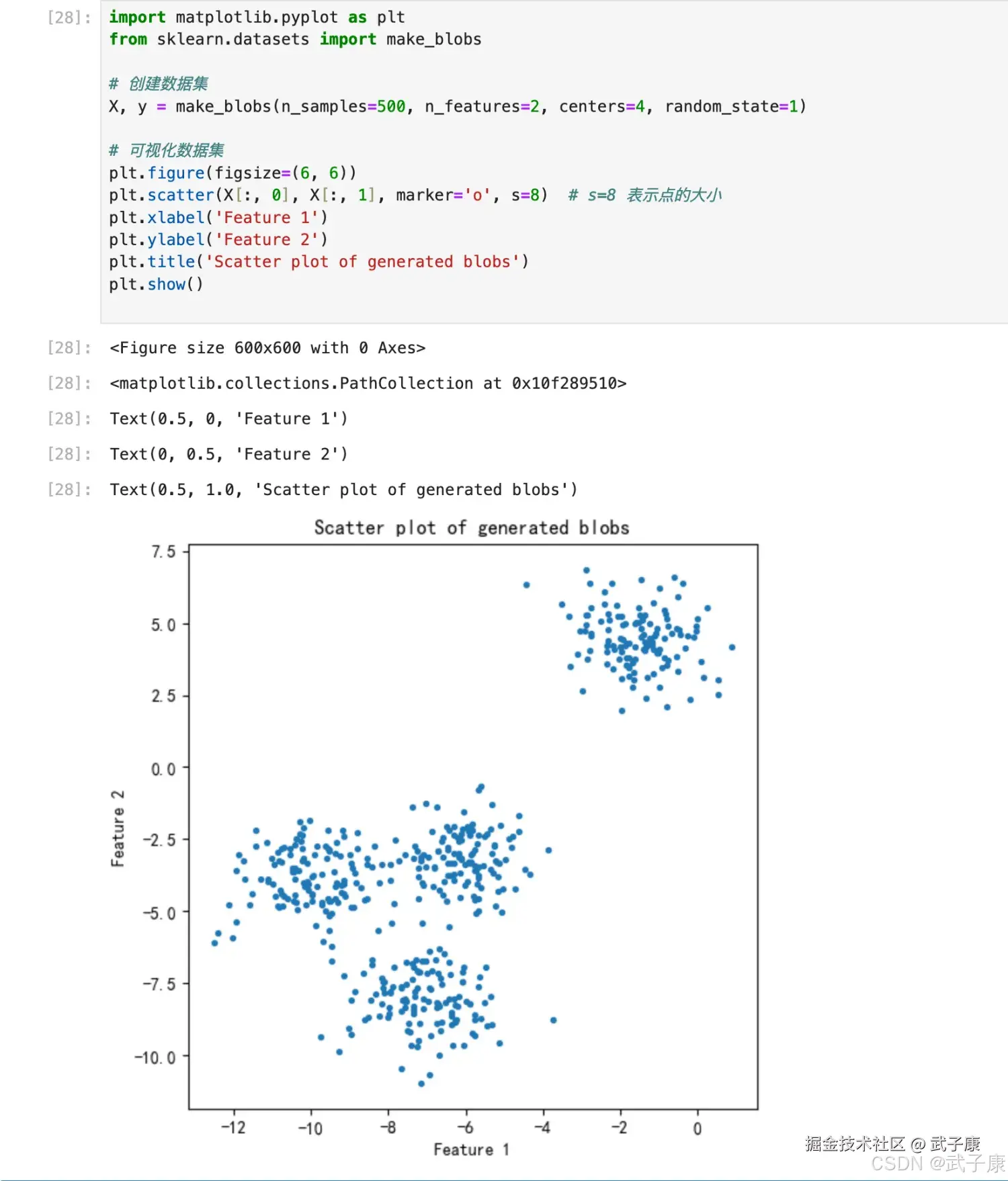 生成的图片如下所示:
生成的图片如下所示:  查看分布的情况:
查看分布的情况:
python
import matplotlib.pyplot as plt
# 查看数据分布
color = ["red", "pink"]
for i in range(2): # 由于 y 只有 0 和 1 两类,因此只需要两个循环
plt.scatter(X[y == i, 0], X[y == i, 1],
marker='o', # 点的形状
s=8, # 点的大小
c=color[i]) # 颜色
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.title('Scatter Plot of Two Classes')
plt.show()执行结果如下图所示: 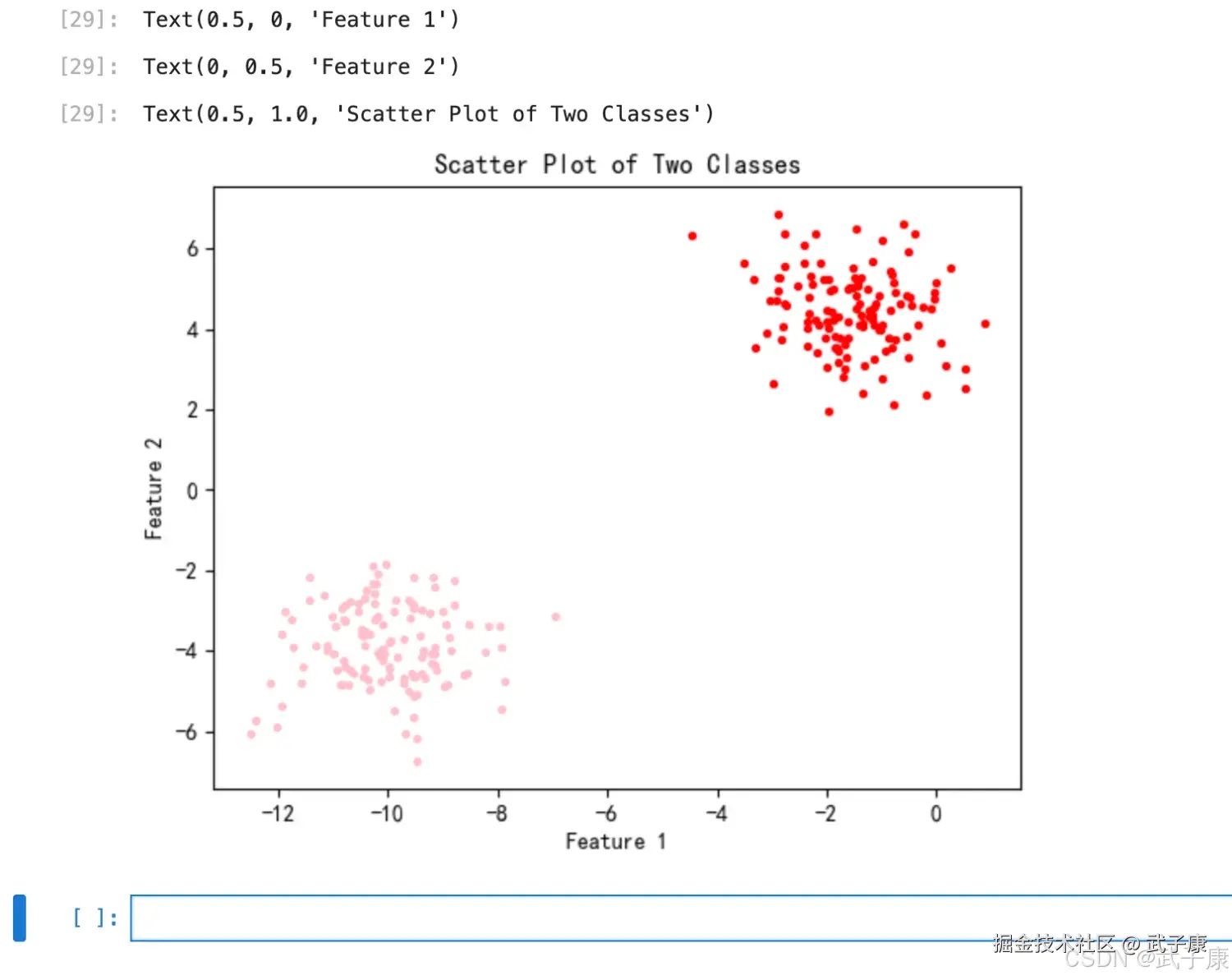
对应的图片如下所示: 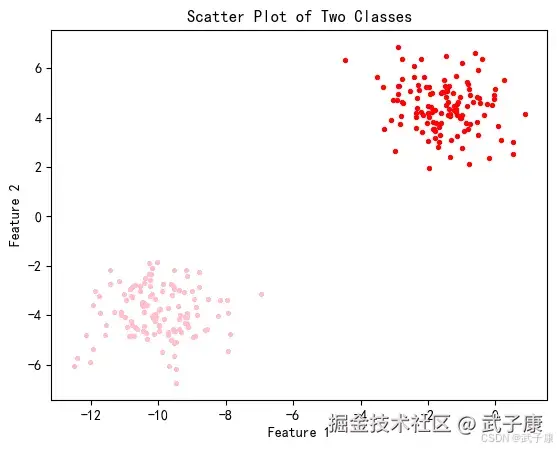 基于这个分布,我们来使用 K-Means 进行聚类。 首先,我们要猜测一下,这个数据中有几个簇?
基于这个分布,我们来使用 K-Means 进行聚类。 首先,我们要猜测一下,这个数据中有几个簇?
cluster.labels
重要属性 labels_,查看聚好的类别,每个样本所对应的类
python
from sklearn.cluster import KMeans
from sklearn.datasets import load_breast_cancer
import numpy as np
# 加载数据集
data = load_breast_cancer()
X = data.data
# 定义聚类的簇数
n_clusters = 3
# 使用KMeans进行聚类
cluster = KMeans(n_clusters=n_clusters, random_state=0).fit(X)
# 获取聚类结果的标签
y_pred = cluster.labels_
# 输出聚类的标签
print(y_pred)- K-Means 因此并不需要建立模型或者预测结果,因此我们只需要 fit 就能够得到聚类结果了
- K-Means 也有接口 predict 和 fit_predict
- predict 表示学习数据 X 并对 X 的类进行预测(对分类器 fit 之后,再预测)
- fit_predict 不需要分类器.fit()之后都可以预测
- 对于全数据而言,分类器 fit().predict 的结果 = 分类器.fit_predict(X) = cluster.labels
执行结果如下图所示: 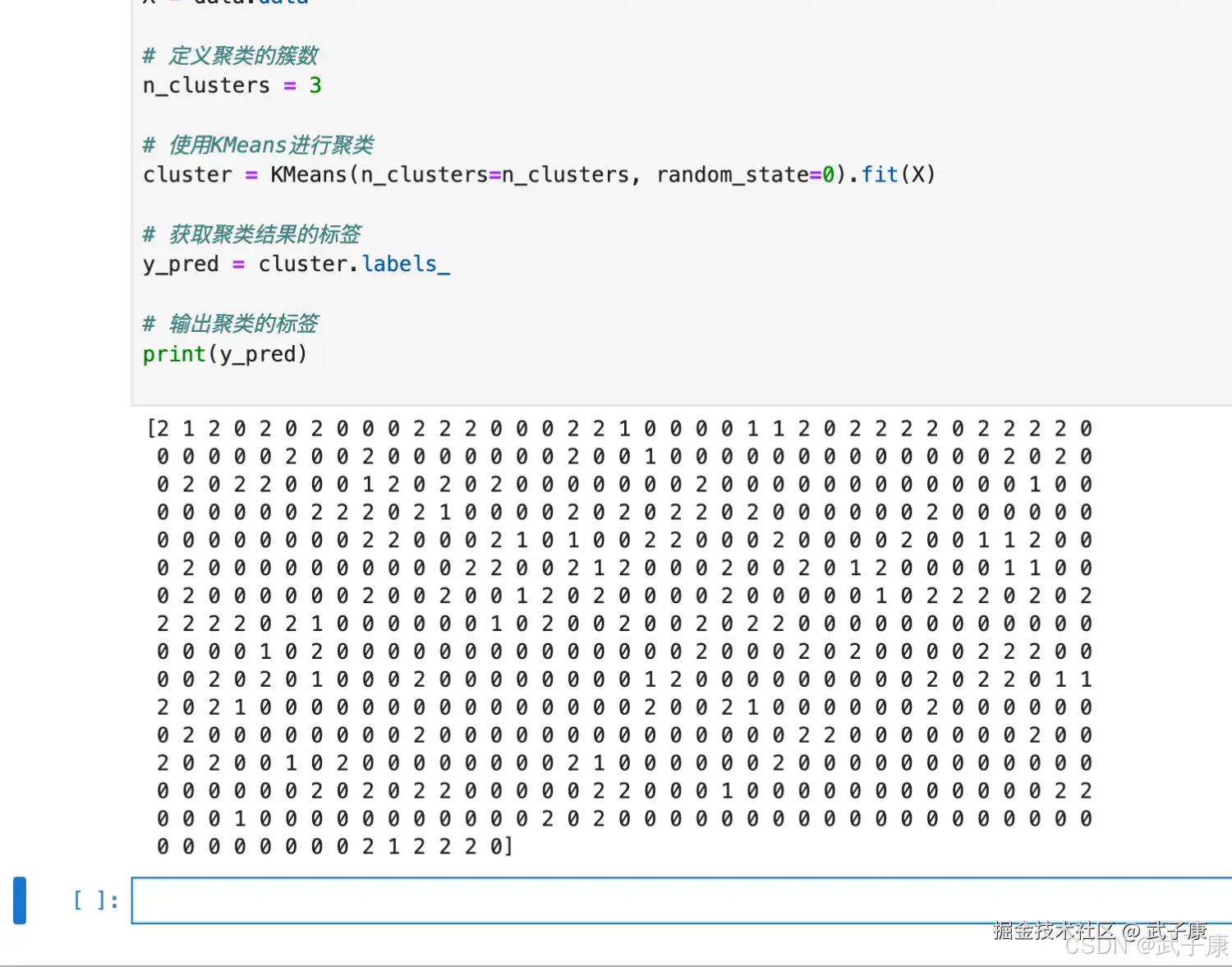 我们什么时候需要 predict?当数据量太大的时候,当我们数据量非常大,我们可以使用部分数据来帮助我们确认质心。 剩下的数据的聚类结果,使用 predict 来调用:
我们什么时候需要 predict?当数据量太大的时候,当我们数据量非常大,我们可以使用部分数据来帮助我们确认质心。 剩下的数据的聚类结果,使用 predict 来调用:
python
cluster_smallsub = KMeans(n_clusters=3, random_state=0).fit(X[:200])
sample_pred = cluster_smallsub.predict(X)
y_pred == sample_pred执行结果如下图所示: 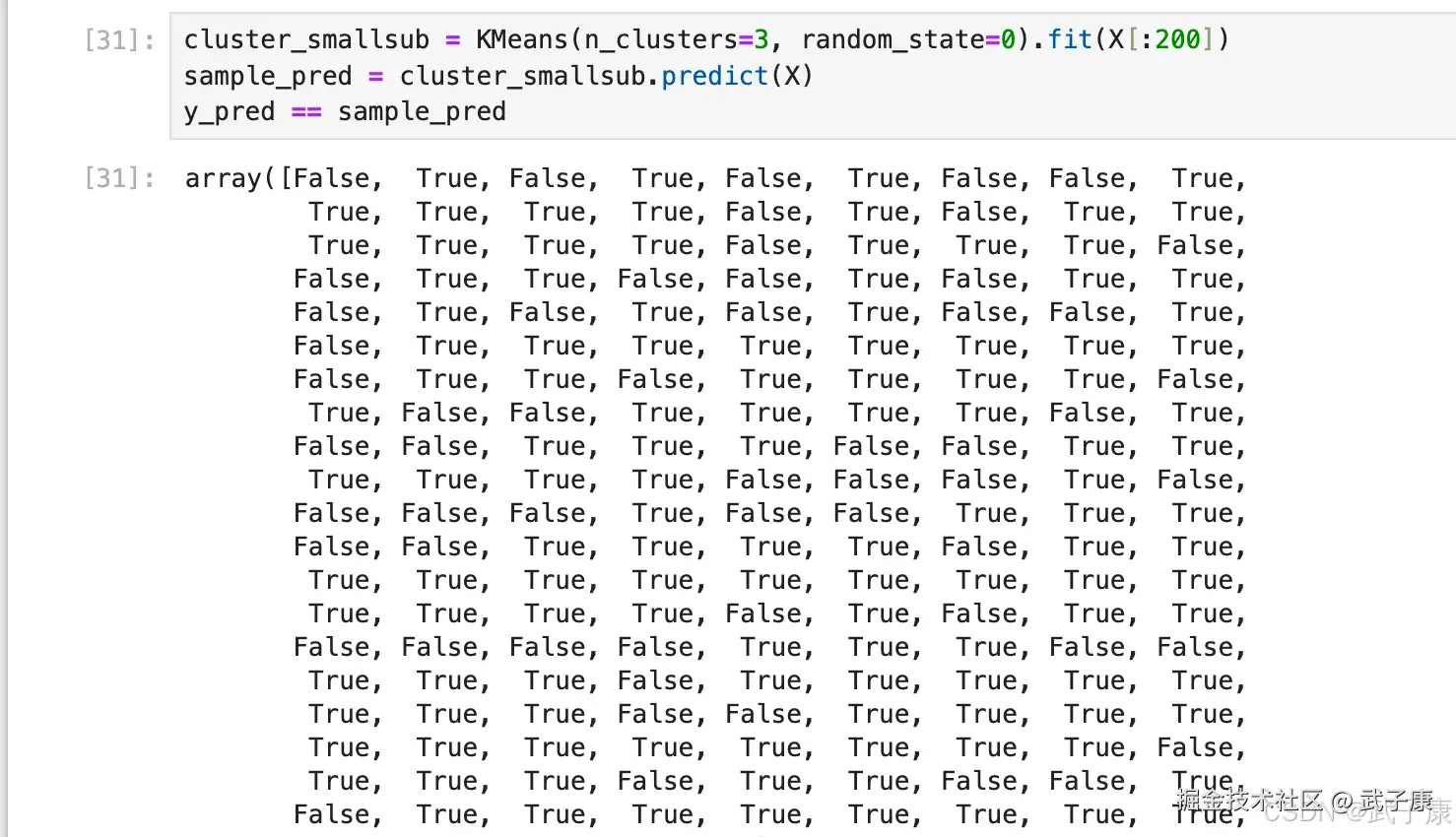 但这样的结果,肯定与直接 fit 全部数据会不一致,有时候,当我们不要求那么精确,或者我们的数据量实在太大,那我们可以使用这样的做法。
但这样的结果,肯定与直接 fit 全部数据会不一致,有时候,当我们不要求那么精确,或者我们的数据量实在太大,那我们可以使用这样的做法。
错误速查
| 症状 | 根因定位 | 修复 | 自写提示修改建议 |
|---|---|---|---|
| K-Means 聚类结果异常/全被分到一类 | 输入数据列约定不一致:算法从倒数第二列取特征,用"追加虚拟标签列"绕过但读者容易误用 | 检查 kMeans 内部对特征列的切片逻辑(是否依赖"最后一列为标签"),明确写出算法的输入约定(特征列范围与标签列位置) | 在正文中把"为何必须加虚拟列/算法用哪些列"写成规则与示例 |
| sklearn KMeans 报弃用/警告或行为变化 | algorithm='auto' 在新版本中可能弃用/变更 | 运行时警告信息 + sklearn 版本号,将 algorithm 改为 'lloyd'(或显式指定可用算法) | 把"auto 已弃用,建议 lloyd"放到参数解释段落的第一屏 |
| make_blobs centers=4,但后续按"两类 y=0/1"绘图 | 示例逻辑不一致:数据生成是 4 簇,但绘图循环只画 2 类 | 若展示 4 簇就用 range(4)/调色板 4 色;若想两类就 centers=2 | 统一为"4 簇示例"并说明 y 的取值范围 |
| 聚类图颜色混乱/看不出簇 | c 参数传入的标签列 dtype/范围不符合预期,或标签列位置错 | print(test_cluster.iloc:, -1.unique()) + dtype,确保标签列是整数类别;绘图前显式转 int | 在可视化前加一行标签检查与类型转换示例 |
| 结果不可复现:每次运行质心不同 | random_state=None 且初始化有随机性(k-means++) | 多次运行对比 centroids/labels,固定 random_state;必要时增大 n_init | 在"工程建议"里强调固定 random_state 与记录 n_init |
| 使用部分数据 fit 后对全量 predict,与全量 fit 结果不一致 | 这是算法预期:质心由子集决定,全量只做分配 | 对比 cluster_smallsub.cluster_centers_ 与 full_fit.cluster_centers_ | 把这段从"现象描述"改成"策略:抽样拟合→全量分配"的场景化说明 |
| KMeans 参数解释读者误解"必填只有 n_clusters" | 叙述没区分"必填参数"与"工程必配参数(random_state / n_init)" | 对照 sklearn KMeans 文档参数表(本地环境),把"必填/建议/可选"分层列出 | 在参数小节加入三层结构与默认值副作用说明 |
其他系列
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究 ,持续打造实用AI工具指南! AI研究-132 Java 生态前沿 2025:Spring、Quarkus、GraalVM、CRaC 与云原生落地 🔗 AI模块直达链接
💻 Java篇持续更新中(长期更新)
Java-218 RocketMQ Java API 实战:同步/异步 Producer 与 Pull/Push Consumer MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务已完结,Dubbo已完结,MySQL已完结,MongoDB已完结,Neo4j已完结,FastDFS 已完结,OSS已完结,GuavaCache已完结,EVCache已完结,RabbitMQ已完结,RocketMQ正在更新... 深入浅出助你打牢基础! 🔗 Java模块直达链接
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解 🔗 大数据模块直达链接