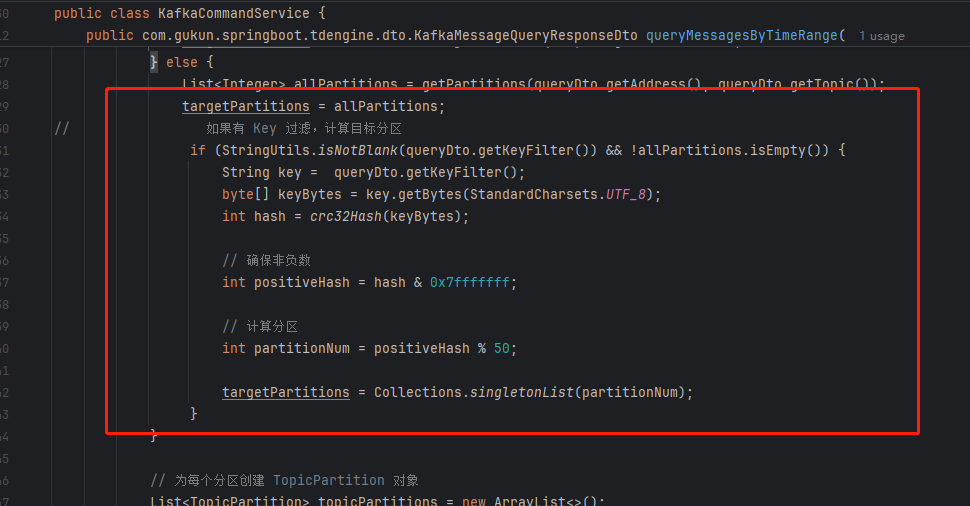
生产端使用C++,将std:string key 传入,parititon设为-1,表示让kafka自动计算分区id
java端拿到反序列化后的key string,通过murmur2 算法计算出的分区id和kafka分配的分区id不一致
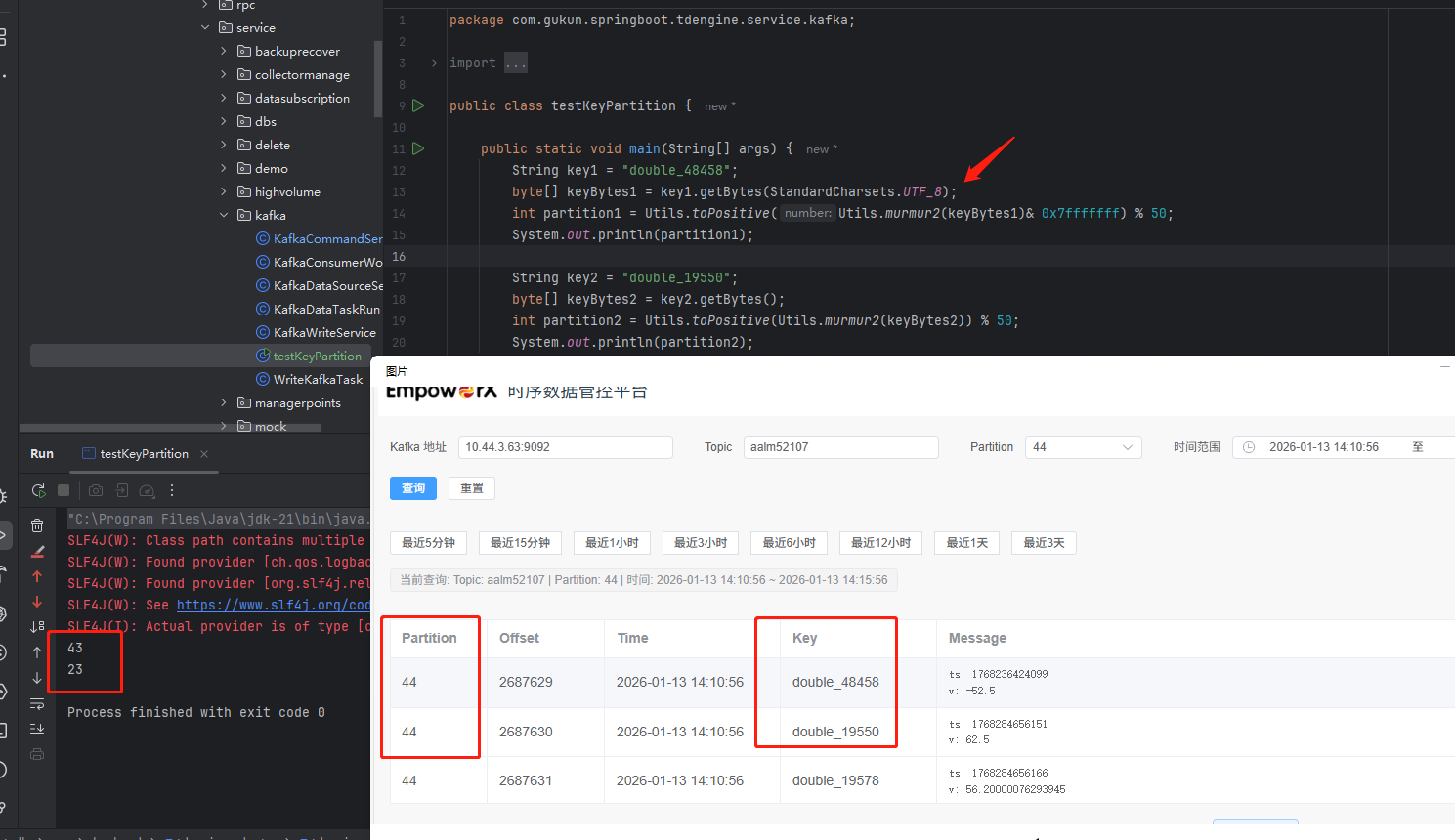
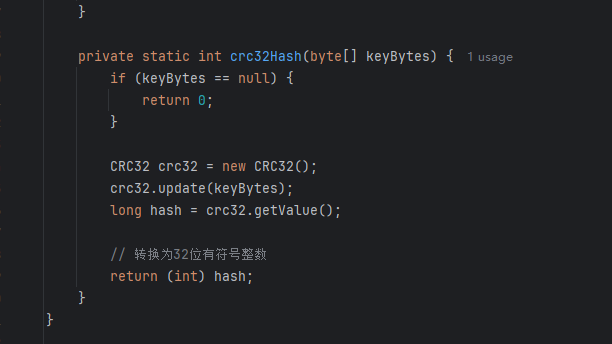
根本原因:C++的kafka使用CRC32 计算hash,Java端使用Murmur2
Key Difference: Hashing Algorithms
Java clients use the Murmur2 hash function by default.
C/C++ clients (which use the librdkafka library) use the CRC32 hash function by default.
只需要在java端也使用CRC32 计算key的hash就行了