Memory in the Age of AI Agents: A Survey:Forms, Functions and Dynamics
这篇文章在formalize记忆的时候,给了三个层次的工作
形成,演进,召回。Rethinking Memory in AI: Taxonomy, Operations, Topics, and Future 这篇更早的survey,把记忆的任务分为6大类------梳理、索引、更新、删除、检索、整合,也正好对应这个框架里的 形成,演进,召回
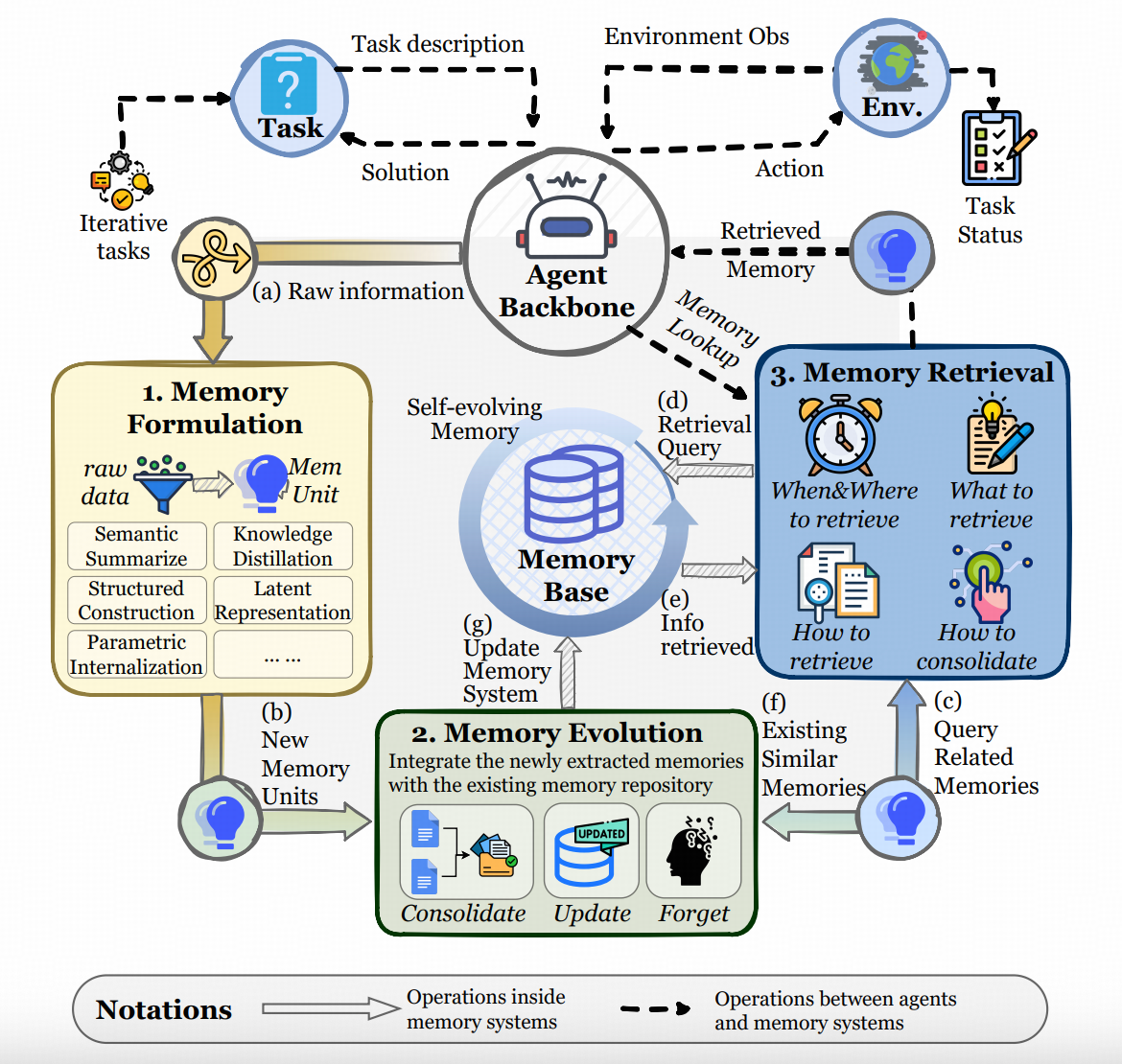
在方法总结上,这个图画得也比较好,很清楚的区隔了各个工作的专门方向。
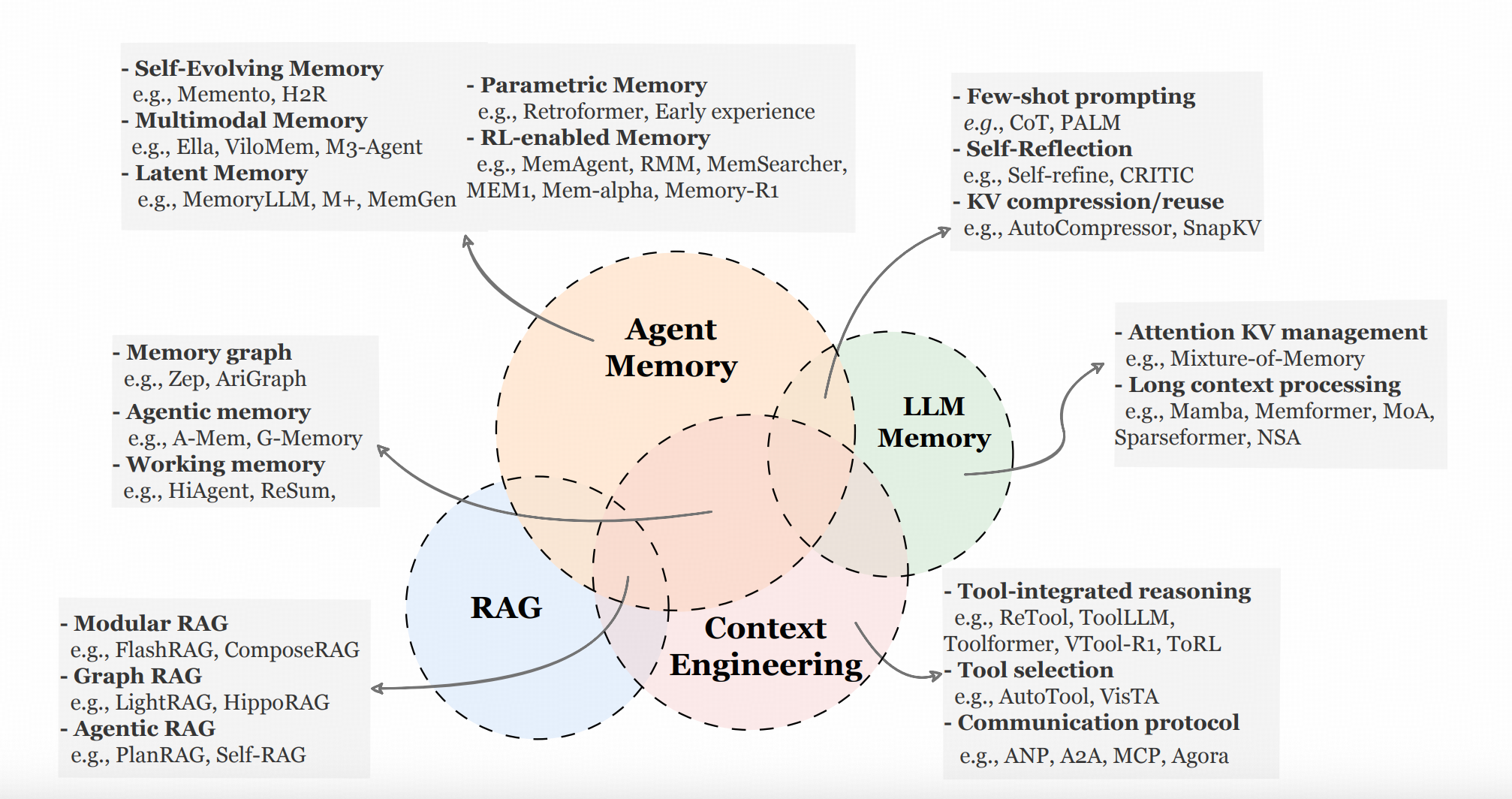
因为我的切入点仍然在于【异构内容】的记忆工程,所以作者众多较好的图中,我主要抠下来下面这张,这张其实也是工程实现中最常使用的集中存储形态。
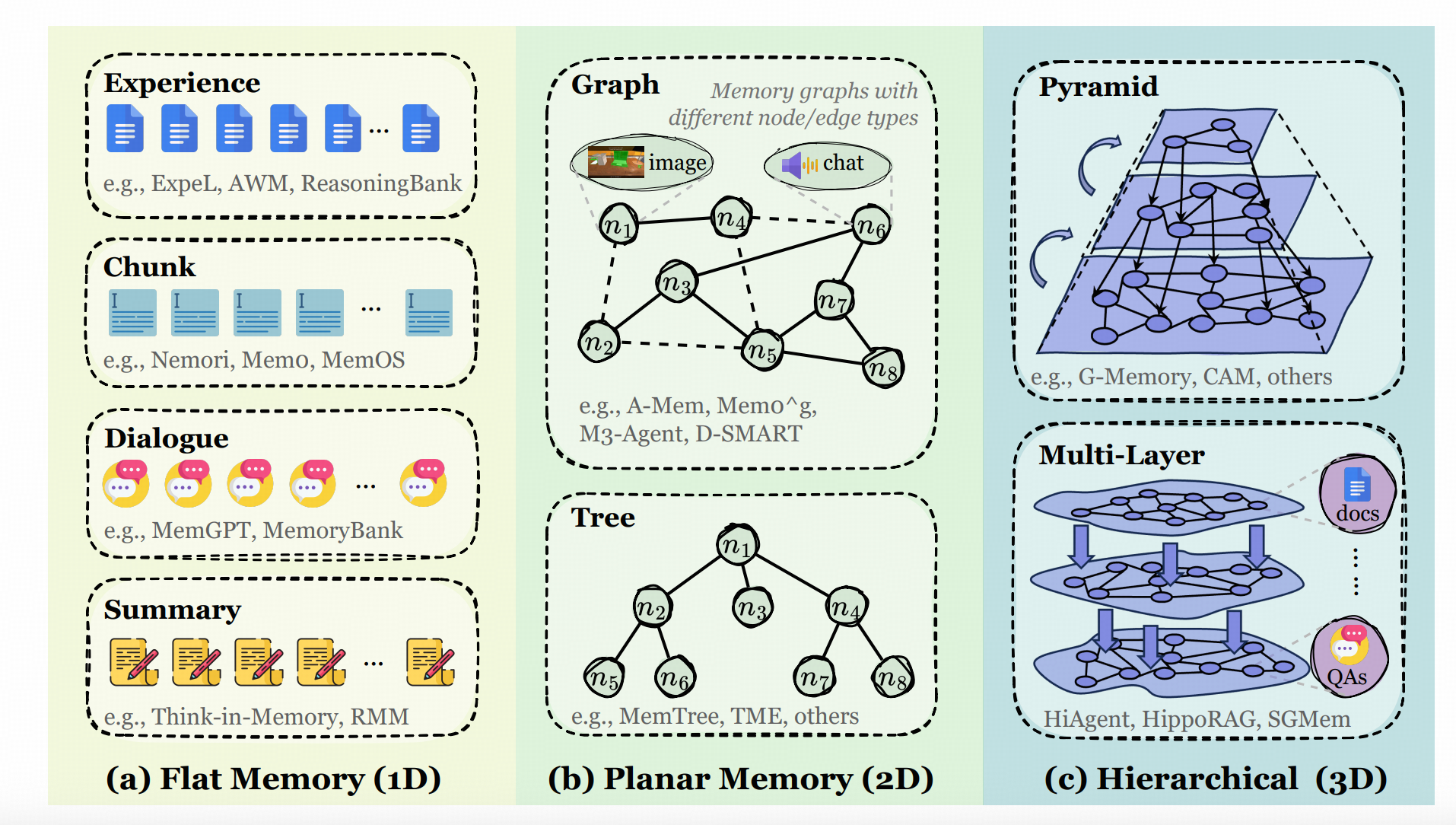
另外,这篇Survey提到了一些同类工作没有强调,但这一领域非常容易忽视的重要议题------记忆系统到底要记忆什么,不仅仅是用户相关的信息,所见的事实,还有Agent的经验。后者之所以重要,也在于他实际上关联了Agent如何演化这一重要议题。(Era of Experienceo(* ̄︶ ̄*)o)
我这两篇会简单的介绍一些我关心的工作的具体做法。由于这些工作大部分都是Agent相关的,纵然现有的Benchmark 照顾到了这个领域的很多方面,但这上面的指标和实际开发中的适用性仍然不完全是一回事。所以这些方法,我都没有对比方法的效果。
MemoryBank: Enhancing Large Language Models with Long-Term Memory
这篇工作比较老了,主要是经常被提及和比较,所以说说
方法说明
记忆的梳理入库
- 针对每日(session)对话总结两项内容:关键信息摘要和用户画像描述
- 归总所有用户画像描述,整合成全局用户画像
- 为每日对话和关键信息摘要打上时间戳及
callback强度指标(初始为1)
记忆的索引和检索
这里无额外工作,用当前用户的话做语义表征查询。
记忆的更新和删除
本文主要讲按照记忆曲线管理记忆(其实这挺有问题的)
每当历史记忆被召回,其callback强度+1。记忆是否被丢弃取决于两个因素:callback强度 SSS 和上次召回距今的时间差 ttt。
是否丢弃,取决于 RRR 是否大于某阈值,其中 R=et/SR=e^{t/S}R=et/S
但这方法的BUG也在此:记忆是否被遗忘主要看召回,而召回依赖相似度 。一些有用但不常用的东西注定被忘 ;另一些需知识推理做二度关联的内容,也会因表征不相似无法查到而被忘。
ZEP: A TEMPORAL KNOWLEDGE GRAPH ARCHITECTURE FOR AGENT MEMORY
方法总结
总架构
用原始message构建三层记忆库,均以图的形式存储:
原始层(Episode)
知识图谱层(Semantic)
信息图聚类层(Community)
其中原始层、信息图聚类层只与知识图谱层有边,相当于两个二部图贴在一起(也不大准确,知识图谱层内部仍有关系边)。
记忆入库
一次性初始
- 记录进入时间后,原始message直接存入
原始层(Episode图)。 - 利用LLM从原始message提取实体与关系三元组,标记
有效性和写入时间,存入知识图谱层(Semantic图);同时将原始信息与实体的连接关系写入原始层。 - 对
知识图谱层进行LPA图聚类,生成的Cluster作为信息图聚类层的节点。将Cluster节点与知识图谱层的关联关系写入信息图聚类层。
记忆更新
- 记录
写入时间后,原始message直接存入原始层。 - 利用LLM从原始message提取三元组。先用实体去查询已有关系,再通过表征检索相似的现有三元组。最后将相似三元组交给LLM,判定是否重复或冲突。
-- 若重复,则不写入;
-- 若冲突,将旧知识的有效性标记为无效(不删除),并写入新知识。 - 新知识将继承其
知识图谱层关联节点在信息图聚类层中的标签。
记忆查询
召回
将用户消息直接作为Query。
利用表征检索和BM25检索节点与边,随后使用BFS进行图搜索(作者在Method及实验章节对这里的具体操作语焉不详)。
实验设置中,选了Top-20的节点与边。
重排
使用BGE-reranker重排。
整合
将记忆填入一个简单的Prompt模板。

效果
这个方法贴了效果,主要是我想展示一下这个方法和用全文的差异。
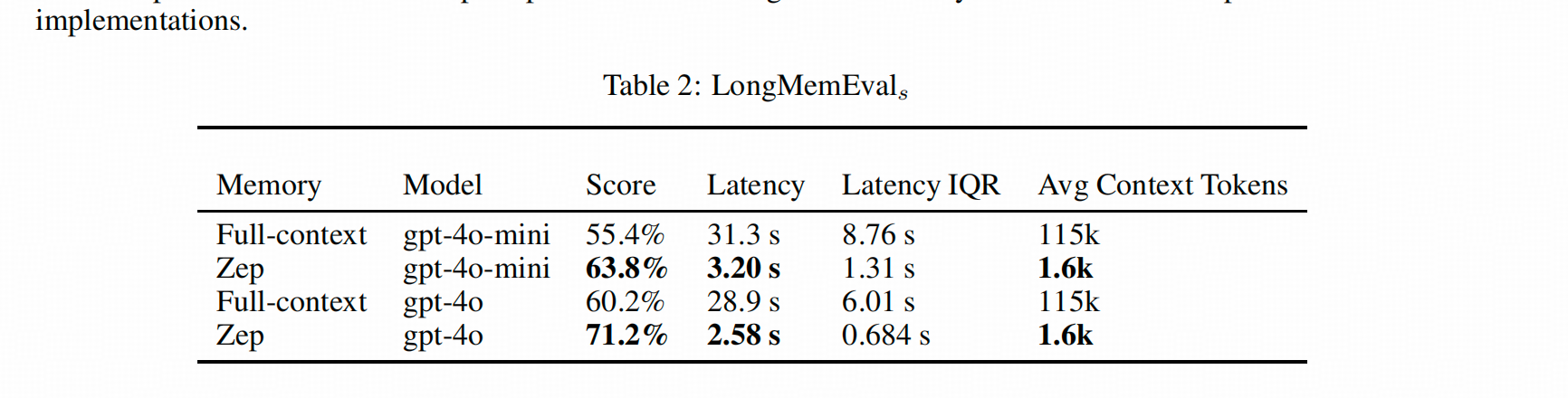
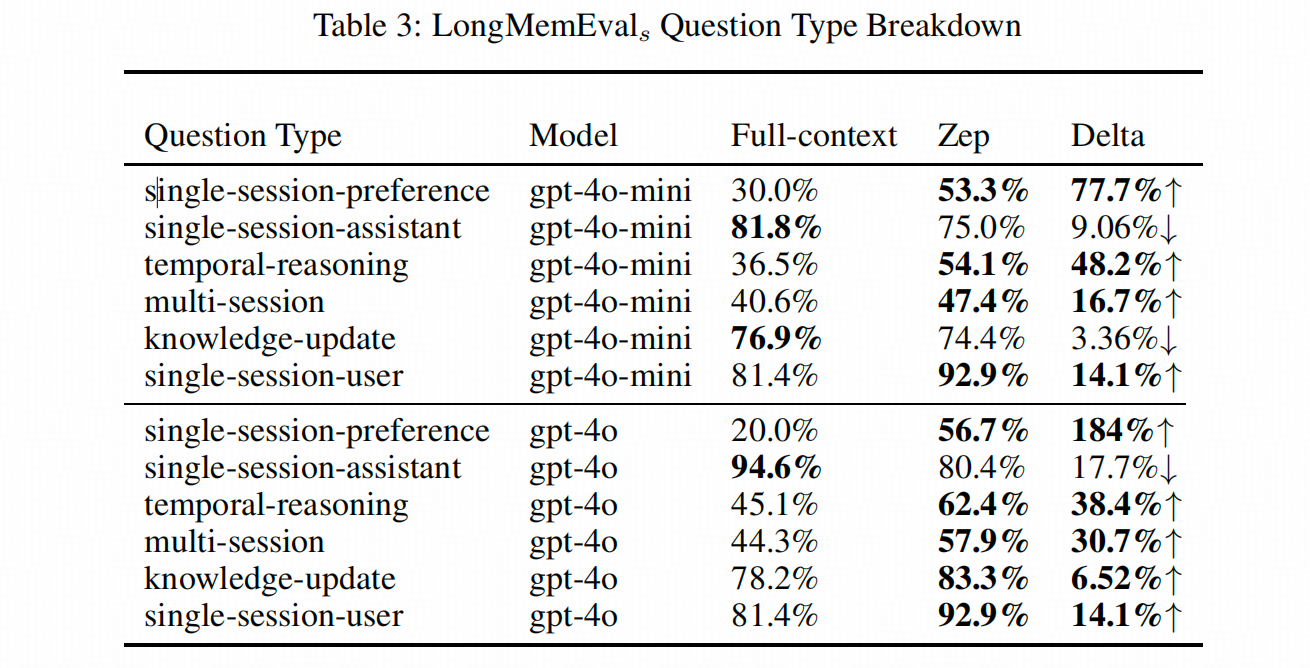
总的来看,在LongMemEval上,Zep在单轮检索(single-session)、时序推理(temporal-reasoning)、跨Session检索(multi-session)以及知识更新(knowledge-update)上都有优势。
其中优势最明显的是单轮检索和时序推理。但在检索Assistant信息时,表现不如直接使用历史对话。这是因为Zep只对User信息构建了知识图谱层和信息图聚类层,Assistant信息仅在Episode层有记录。加上召回时可能受到其他相关信息的干扰导致折损,所以效果比直接用历史对话还差。
SGMEM: SENTENCE GRAPH MEMORY FOR LONGTERM CONVERSATIONAL AGENTS
方法总结
这篇文章把User和Assistant的话切成句子,用这些句子的语义相似性来构图。
查询时,将User的Message切成句子,用语义相关性确定图上的查找起点,然后在图上做1跳(1-hop)遍历。
检索后,根据与User Message的语义相关性对记忆排序,并直接喂给LLM。
记忆入库
※ Step 1:设置 chunk_size=N,将对话历史按每N句(或轮)切分为一个Chunk。
※ Step 2:针对每个Chunk,将用户和Assistant的Message都切分为句子,作为图节点(不区分节点类型)。同时构建两种边:一种是指向所属Chunk的归属边,一种是与其他句子的语义相似边。
记忆检索
※ Step 1:在用户发出新一轮Message的时候,把用户的Message切成若干句子。
※ Step 2:每一句都用表征在图上查找语义相似的节点。
※ Step 3:针对Step 2查得的节点,查询它的1跳邻居。
※ Step 4:把Step 2和Step 3节点所属的Chunk拿出来作为检索结果。
记忆整合
这篇工作没有在整合上做复杂操作,仅用了语义Re-ranker对Chunk和Message的相似度进行排序,取Top-k个Chunk,拼接成模型的Context。
效果
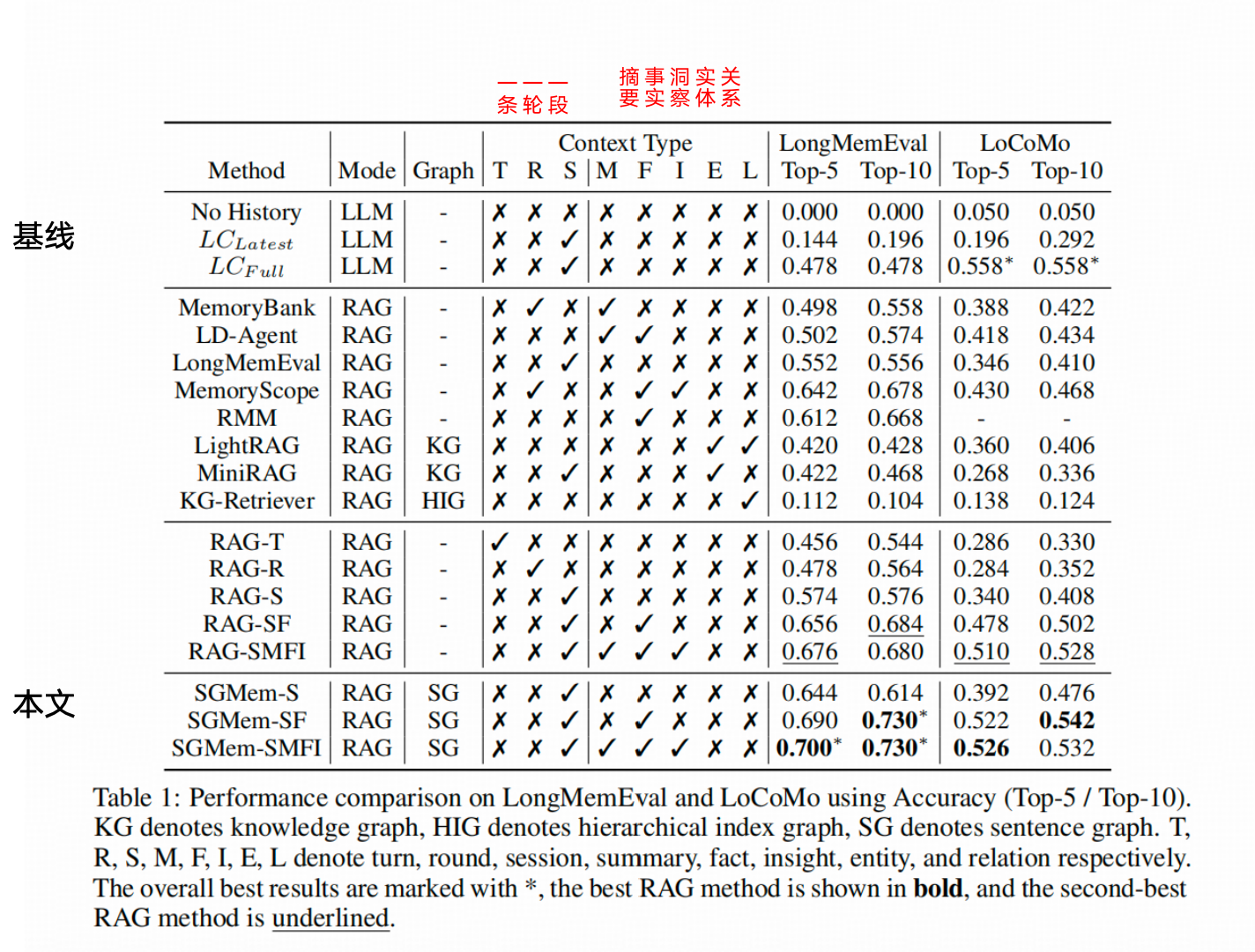
要对比Zep结果的朋友注意一下,SGMEM这篇文章用的测试模型不是 GPT-4o,而是 Qwen2.5-32B-Instruct。
作者给出的效果比较表有个额外的好处,就是标明了其他对比方法在使用历史数据时的粒度(比如单句 User 话语、单轮 User 和 Assistant 的交互,或者一段时间内的完整互动),以及建索引时是从哪个维度做的二度抽象(比如总结、事实提取、关键洞察、关系提取等等)。
单从效果看,Top-10 Chunk 的综合准确率达到了 70%+,比 Zep 用 GPT-4o 测出来的结果还要略高一点。
MemTree:FROM ISOLATED CONVERSATIONS TO HIERARCHICAL SCHEMAS: DYNAMIC TREE MEMORY REPRESENTATION FOR LLMS
方法总结
这个方法给Agent对话记录建了一个Hierarchical Cluster(MemTree),作为管理记忆的结构。
这棵树上每个分支节点不挂载记忆内容,但都保留一个内容简述 c,每个叶子节点挂载记忆内容,并把记忆内容作为该节点的c。
这棵树只负责管理内容,并不要求特殊的检索方案。在检索记忆的时候,对所有节点的c进行表征查询(不分级),即完成了召回。
记忆的梳理、索引、入库
※ Step1:每条记忆(用户说话的原文)在存入MemTree的时候并不做原文的修改,直接用原文生成一条语义表征(Embedding)。
※ Step2:新记忆的表征从Cluster的根节点 开始逐层遍历分支节点的c的语义表征(Root→Leaf),比如,假设根节点(level-1)有5个子节点(level-2),都是分支节点,那么把这5个节点的下一层子节点(level-3)的c的表征与新记忆表征计算距离。
※ Step3:如果5个level-2节点的子节点中,存在表征距离小于阈值且为相对最小 的节点,继续沿着这个level3的子节点向下查找;
※ Step3-1:如果最终找到了一个距离小于阈值的叶子节点 ,则新记忆挂载在该叶子节点上 。该节点成为新的分支节点,原叶子节点挂载的记忆与新记忆,都成为新的叶子节点。
※ Step4:如果所有level2节点的子节点,与新记忆表征的距离都大于阈值,就在level2新增一个叶子节点,挂载新记忆。
※ Step5:不管是Step3还是Step4的挂载方式,记忆挂载到树上后,其所有上级节点都执行一遍描述更新的动作。
【描述更新动作】指的是:分支节点把其所有子节点的内容放到同一个prompt里,要求LLM更新节点的描述。这样,所有相关上级节点的内容简述c就都包含了新的记忆,以便于后续的查询。
记忆的检索,过滤和合成
本作在查询的时候,讲当前语句转化成检索表征,并与树上左右的节点的c的表征进行相似性检索,这里不区分层级。只使用了常规的阈值过滤和Top-K排序。
然后就放到上下文中使用了。
效果如何
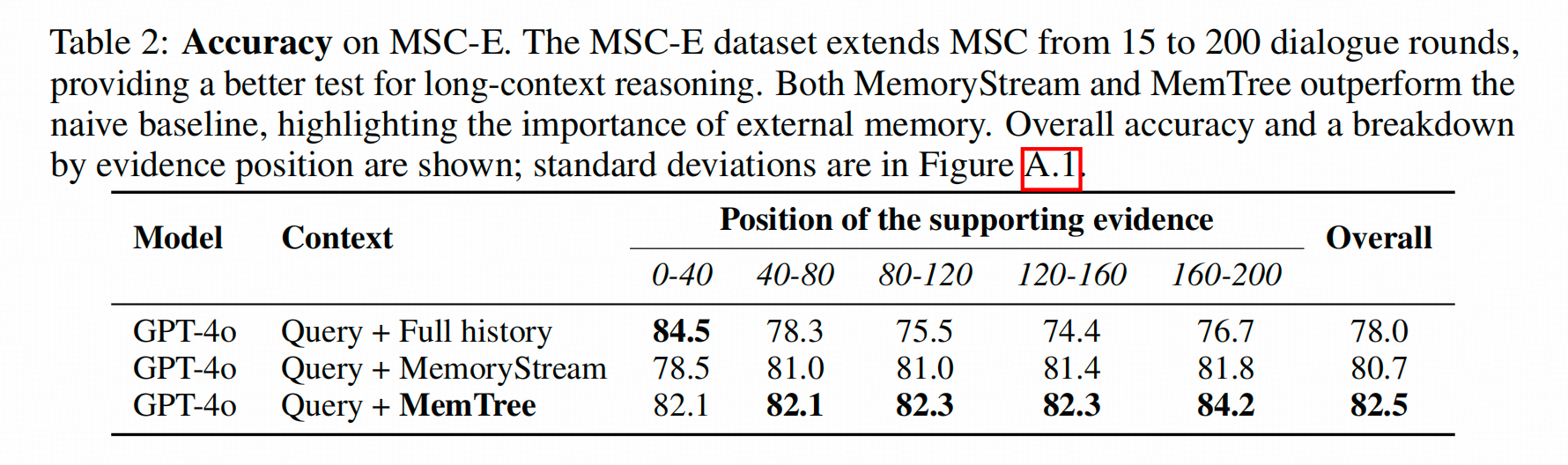
超长对话中,比使用全文上下文效果要好,尤其是知识线索集中于长对话的最后几十段的时候,使用全文的回答正确率为76.7%,而本文方法可以达到84.2%
HUMAN-INSPIRED EPISODIC MEMORY FOR INFINITE CONTEXT LLMS
方法总结
这个方法所处理的记忆是体外参数记忆(KV Cache),同时所处理的记忆是不区分User的信息和Assistant的信息,只把LLM处理的所有上文当做待处理的历史。这点与多个前述方法并不相同。
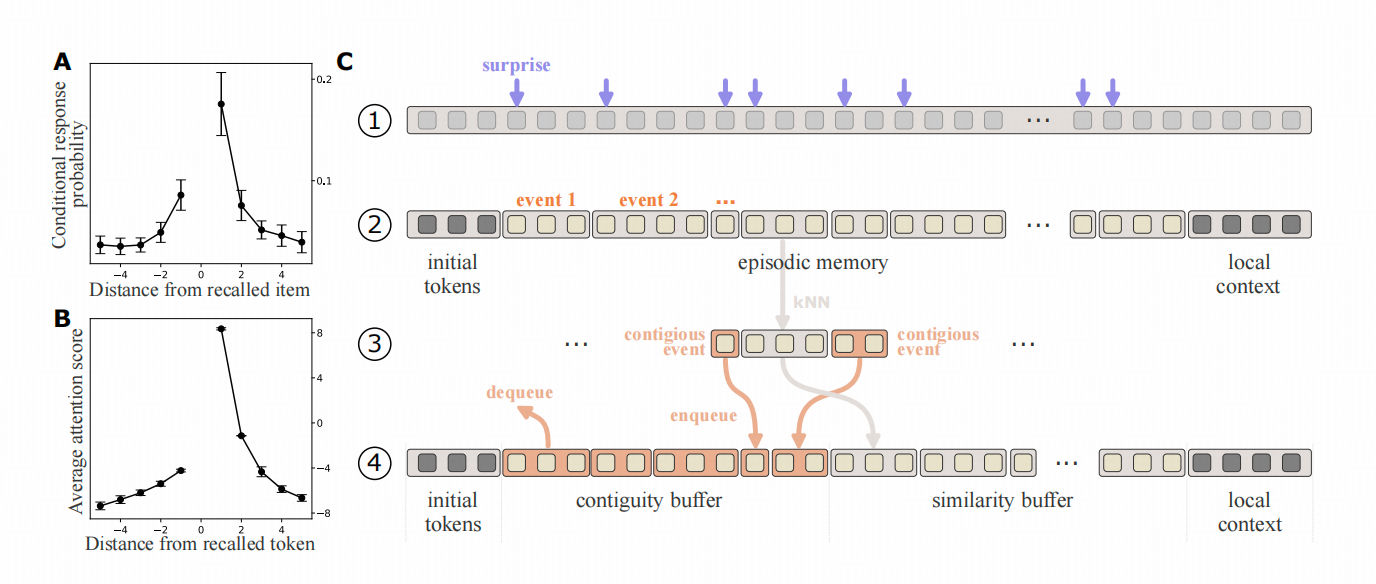
※ Step 1 :LLM对于当前处理的上下文,计算每个Token的【意外概率】-当前Token被LLM生成的概率,如果概率较低,即LLM对其非常意外,用这个【意外概率】大于阈值的Token作为上下文分块的标志。(分出来的块就是上图的event1等)
※ Step 2:基于块内部的modularity来调试块的边界,以此来消除意外Token往往可能在句中的问题。计算Modularity的表征就是Key 向量了。
※ Step 3:用块中累计Attention Score最高的Key向量作为这个KV Cache 块的索引向量。
※ Step 4: 生成下一句的时候,用当前query查询索引向量,查得top-K个KVCache,再把其前后的块也带到上文里。形成上下文。
Buffer of Thoughts: Thought-Augmented Reasoning with Large Language Models
方法总结
这篇工作主要处理的是经验性记忆------即LLM做对的经验如何沉淀并存储给未来使用的问题。
这篇文章的思路是将LLM成功结题的整个COT和回答,二度抽象成一个解题模板,在处理新问题的时候,先用【问题抽取器】(problem distiller)二度抽象当前的问题,然后基于抽象过的问题描述去经验库中查找经验,查到后,就作为提示工程的一部分来知道模型执行任务。
这其中的存储解题模板的经验库被作者试做Buffer,这个方法被称作 Buffer of Thought 即 BOT。
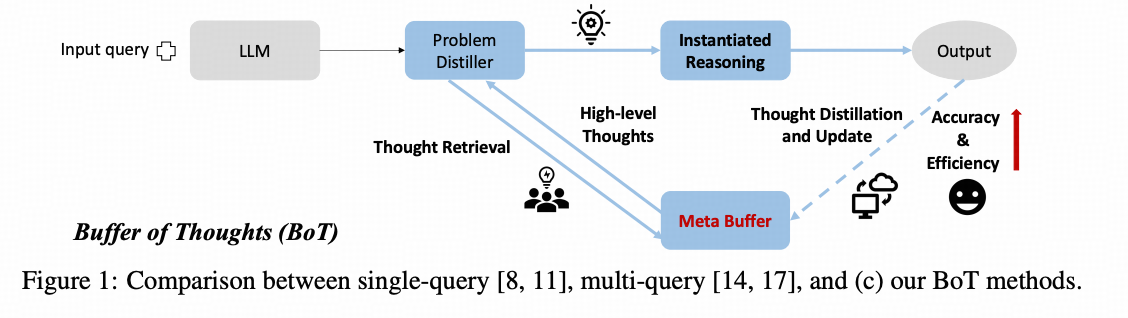
记忆的梳理、入库
当LLM成功解决了一个问题后,BOT会通过一个提示工程提炼一个模板,然后用表征相似来检测新增模板与已有模板库的相似度,如果相似度高于阈值,该模板就会被丢弃。

记忆的更新和记忆库的管理
作为早期版本的工作,(毕竟还在X of Thought这个逻辑上),这篇工作没有对经验库有更多的操作,不存在旧模板退出机制,也不存在旧模板更新机制。
记忆的索引和整合
作者使用 【问题描述器】作为整合索引空间的办法,直接用问题描述器的输出文字对应的表征向量作为检索的key,模板文字的表征向量作为待检索的key,当匹配的时候,就直接插入提示工程。
PRINCIPLES: Synthetic Strategy Memory for Proactive Dialogue Agents
方法总结
这个方法针对的是引导性对话的场景,这个方法先让策略LLM和演员LLM分别扮演Assistant和User来进行模拟对话,并让评价LLM评估Assistant是否帮助User达到了他的需求(情感需求),然后比对失败路径和成功路径,进而用提示工程提取对话中场景、可采取的成功策略、不建议采取的失败策略及分析原因。
在实际工作的时候,该方法用用户的query的语义表征召回已经生成的策略,然后经过【重新解读】召回的策略------把策略写成适合当前场景的内容,然后注入上下文。
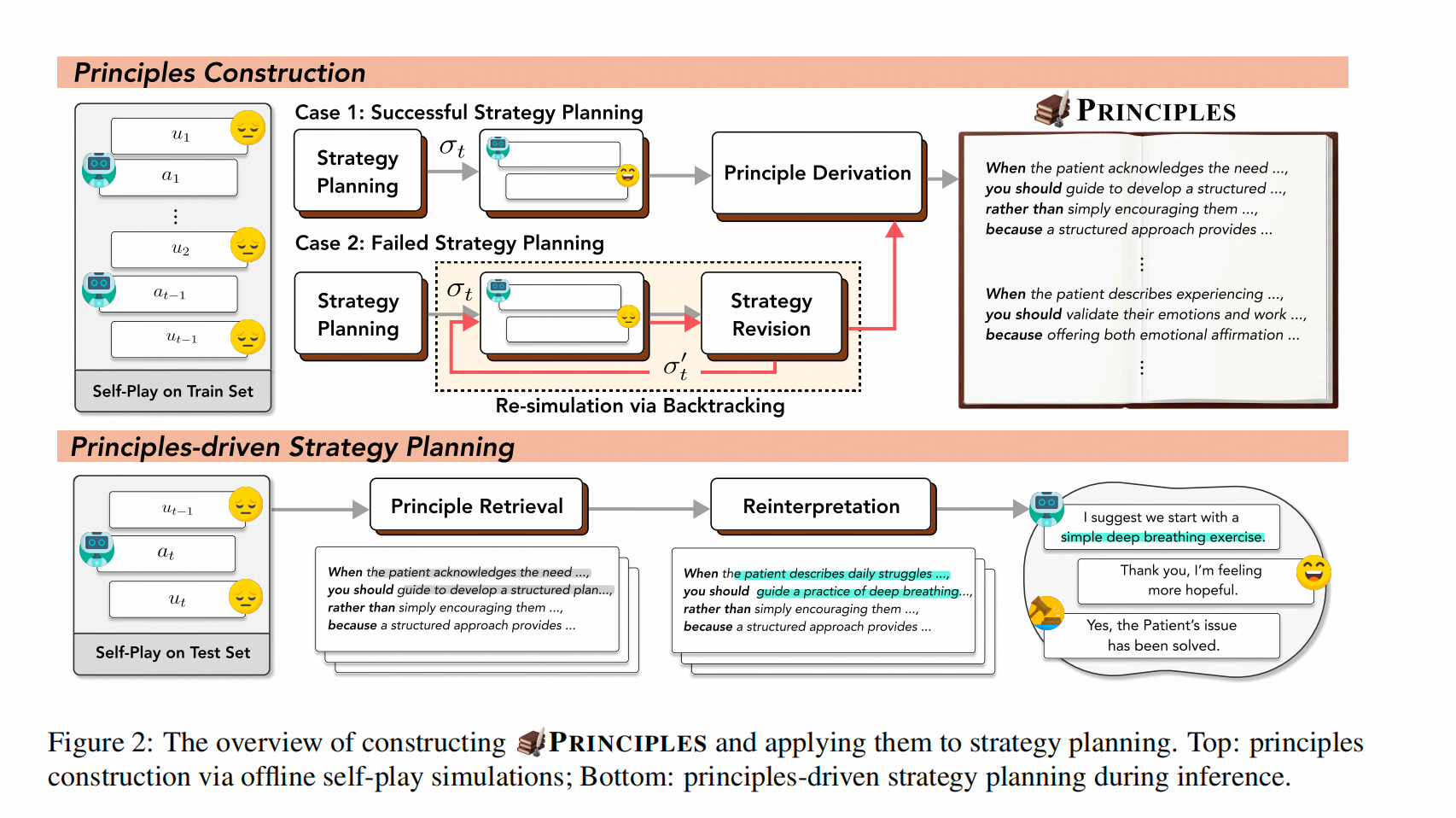
记忆的梳理、入库
让多个LLM进行Role-play其实是引导性对话中很场景的工程操作,这个操作有助于采样相对好的策略和相对不那么好的策略。
这里作者就利用了这点对场景进行了假的因果梳理,让LLM给出如下策略总结。

不过Role-Play本身的隐患是比较多的,这里不讨论。仅讨论这么总结的问题,关键有两个难点:一个是situation能发现真正导致因果的变量组,一个是roll-out出真正成功的策略。这两点在实践中,其实要求有个悖论,就是LLM本来就会,如果LLM本身并不掌握当前场景的核心动因,对roll-out的结果(即便是给了LLM)
记忆的索引
用当前用户的语句的语义表征当做检索的query ,用策略中When的那一句------即只使用situation 作为待检索的语义表征,仍然是以top-k原则选择策略。
记忆的整合
每条被召回的策略,都会单独通过重写模块,让LLM把策略的细节微调成跟当前场景比较相近的描述。然后把这些召回的策略,放入上下文。
感想
-
管理记忆的第一个问题很泛,但很关键------记什么东西对我的任务有用,这点在不同的场景下有很大的不同,比如我这里完全没有收录的Code/ToolAgent相关的记忆工作,最近已经把记忆升格为Skill。这种升格在这类任务上,是有极大必要性的,但对对话Agent而言,则并不是一种很好的抽象。
-
多数方法中,图搜索是对语义表征检索的一种常见的补充。但本质上没有解决语义表征难以做到深层推理的问题 。上篇中,那些异构的检索方案(还有大量异构RAG方案)往往能够一定程度上补足,单使用语义表征进行检索的问题,但一个BUG点就在于,这些图(或者其他结构)也是用语义表征建立的(好处就是建法简单)。 一个简单的例外就是,教育场景中,如果我只记录学生哪个题目做错了,并基于题目的语义表征建立异构记忆,会发现学生到底知识点哪里不懂,认知能力上有什么缺陷,是找不到的,必须使用对应的抽象工具 ,把潜层的,本场景关心的信息,先挖掘出来。而挖掘什么?这又回到了上一个问题。
-
记忆的整合:一些方法在记忆的整合上下了一些功夫,这些功夫也都下在了我这个场景中,什么信息有用 ,这点上,这很好,但整体观感上,仍然缺乏记忆系统长期运行态中 ,信息整合如何不导致【上下文腐烂】的视角。
-
一个视野的补充:学术方法更倾向于找到泛用性更强的做法,工程方案则更倾向于适用性更强的方法。做实际场景的设计,纵然希望能更贴合【可见论文的趋势】,但更重要的仍然是自己场景下的效用(效果如何,扩展性如何,维护难度如何等等)。当然退一步讲,学术上问题定义既想泛用性更强,又馋工程上的简洁,也可能是这一年来,这一领域方法没有收敛的一个原因。