
在实际的数据分析和工具开发过程中,GitHub 往往是一个绕不开的数据来源。无论是统计某一技术方向的项目活跃度,还是分析开源生态趋势,都需要对仓库信息进行一定规模的抓取与整理。
表面上看,GitHub 提供了官方 API,但在一些非标准统计场景下(例如自定义筛选条件、页面聚合信息、或结合前端展示数据),直接使用网页数据反而更灵活。不过,这也带来了新的工程问题。
本文记录一次 GitHub** 仓库信息抓取任务** 的实现过程,重点放在:
- 任务设计思路
- 工程层面的挑战
- 使用 IPIDEA API的抓取流程的实践体验
1、任务背景与目标
本次任务的目标相对明确:
从 GitHub 搜索结果及仓库详情页面中,大量获取仓库的基础信息,用于后续的数据分析。
核心字段包括但不限于:
- 仓库名称
- Star 数
- Fork 数
- 主语言
- 最近更新时间
从工程角度看,这类任务并不复杂,但在规模化抓取时,会逐渐暴露一些现实问题。
2、为什么直接抓取 GitHub 网页并不轻松
2.1我们先来尝试一下自己进行抓取
整体思路并不复杂:
- 使用
requests获取 GitHub 搜索页 HTML - 解析仓库列表
- 进入仓库详情页,提取关键信息
- 降低请求频率,防止触发瓶颈
在设计阶段,这套方案看起来是完全可控的。
2.2、基础抓取代码示例
以下是一个简化后的示例代码,用于抓取 GitHub 搜索结果页中的仓库信息:
Python
import requests
from bs4 import BeautifulSoup
import time
import random
HEADERS = {"User-Agent": ("Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/120.0.0.0 Safari/537.36"
)
}
def fetch_search_page(keyword, page=1):
url = "https://github.com/search"
params = {"q": keyword,"type": "repositories","p": page
}
resp = requests.get(url, headers=HEADERS, params=params, timeout=10)
resp.raise_for_status()return resp.text
def parse_repositories(html):
soup = BeautifulSoup(html, "html.parser")
repo_items = soup.select("div.repo-list-item")
repos = []
for item in repo_items:
name = item.select_one("a.v-align-middle")
star = item.select_one("a[href$='stargazers']")
repos.append({"name": name.text.strip() if name else None,"stars": star.text.strip() if star else None
})return repos
if name == "main":
all_repos = []for page in range(1, 4):
html = fetch_search_page("web scraper", page)
repos = parse_repositories(html)
all_repos.extend(repos)
time.sleep(random.uniform(2, 4))
print(all_repos)这是一个相对来说比较规范的一个实现:
- 明确 User-Agent
- 加入随机延时
- 基于结构选择器解析字段
在理想情况下,这段代码是可以"跑起来"的。
2.3、实际运行中逐渐暴露的问题
当我尝试将抓取规模从"验证级别"扩展到"几十到上百页"时,问题开始逐步显现。
2.3.1 页面结构不稳定
部分请求返回的 HTML 内容与预期不一致,导致解析字段为空,原因包括:
- 页面结构存在差异
- 部分内容并非首屏 HTML,而是后续加载
这意味着:
单纯依赖 HTML 解析,稳定性并不高。
2.3.2 访问频率受限逐步显现
测试:
- 单线程抓取
- 每次请求间隔:2--4 秒随机
- 连续抓取 GitHub 搜索页或仓库详情页
- 将"关键字段缺失 / 页面解析失败"记为一次异常返回
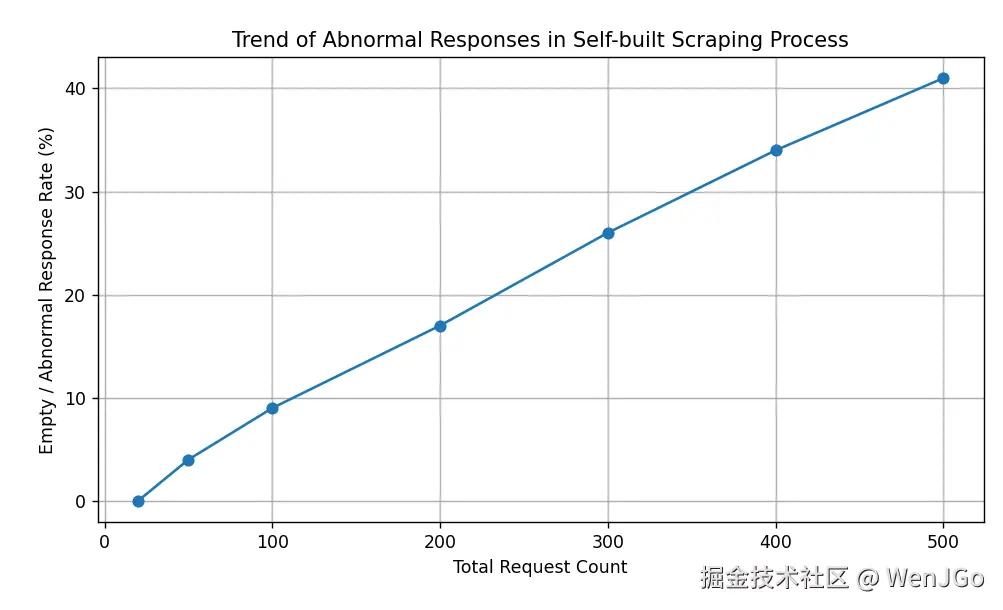
图:自建抓取流程中,随着请求数量增加,异常返回比例逐步上升。 即使在降低请求频率的情况下,该问题仍以间歇性方式出现,对长期大量任务的数据完整性产生影响。
PS:数值并非极限测试结果,而是用于描述趋势。
因此即使缩短了请求间隔,随着请求数量增加,仍然会遇到以下情况之一:
- 返回页面内容异常
- 请求被重定向
- 需要额外校验才能继续访问
这些问题并不会每次都出现,但一旦出现,就需要额外处理逻辑。
2.3.3 JavaScript 渲染问题
部分仓库详情页中的信息,实际依赖前端渲染完成。
如果引入浏览器自动化(如 Playwright / Selenium),问题可以缓解,但随之而来的是:
- 资源消耗明显增加
- 并发能力下降
- 部署与维护成本上升
这已经明显超出了"简单抓取代码"的范畴。
2.3.4 工程复杂度快速膨胀
为了解决上述问题,往往需要陆续引入:
- 代理池
- 请求失败重试
- 页面异常检测
- 浏览器自动化
此时,抓取本身已经变成了一个需要长期维护的麻烦事情。
2.4、自建方案的边界在哪里
通过这次尝试,我对自建抓取流程有了一个更清晰的判断:
- 在小规模、短周期任务中,自建代码勉强够用
- 当任务涉及 动态页面、稳定性要求、重复执行 时,维护成本会迅速上升,且变得复杂易错
- 抓取逻辑本身开始侵占大量工程精力
也正是在这个阶段,我开始思考是否有必要将"抓取基础设施"本身进行抽象,而不是继续堆叠自定义逻辑。
3、引入 IPIDEA API
在对比不同实现路径后,我选择尝试 **IPIDEA 提供的 Web Scraper **API,核心原因并不复杂:
- 抓取逻辑以 API 形式封装,防止自建抓取基础设施
- 支持 JavaScript 渲染页面
- 返回结果可直接结构化(如 JSON),便于后处理
- 代理、重试等相关逻辑由服务侧处理
从工程角度看,这类 API 更像是一个"抓取基础设施抽象层",可以把注意力集中在数据本身。
图:提供了很多现成的抓取工具,例如我们需要的Github,还包括YouTube,Google等。
IDPIDEA官网:www.ipidea.net/
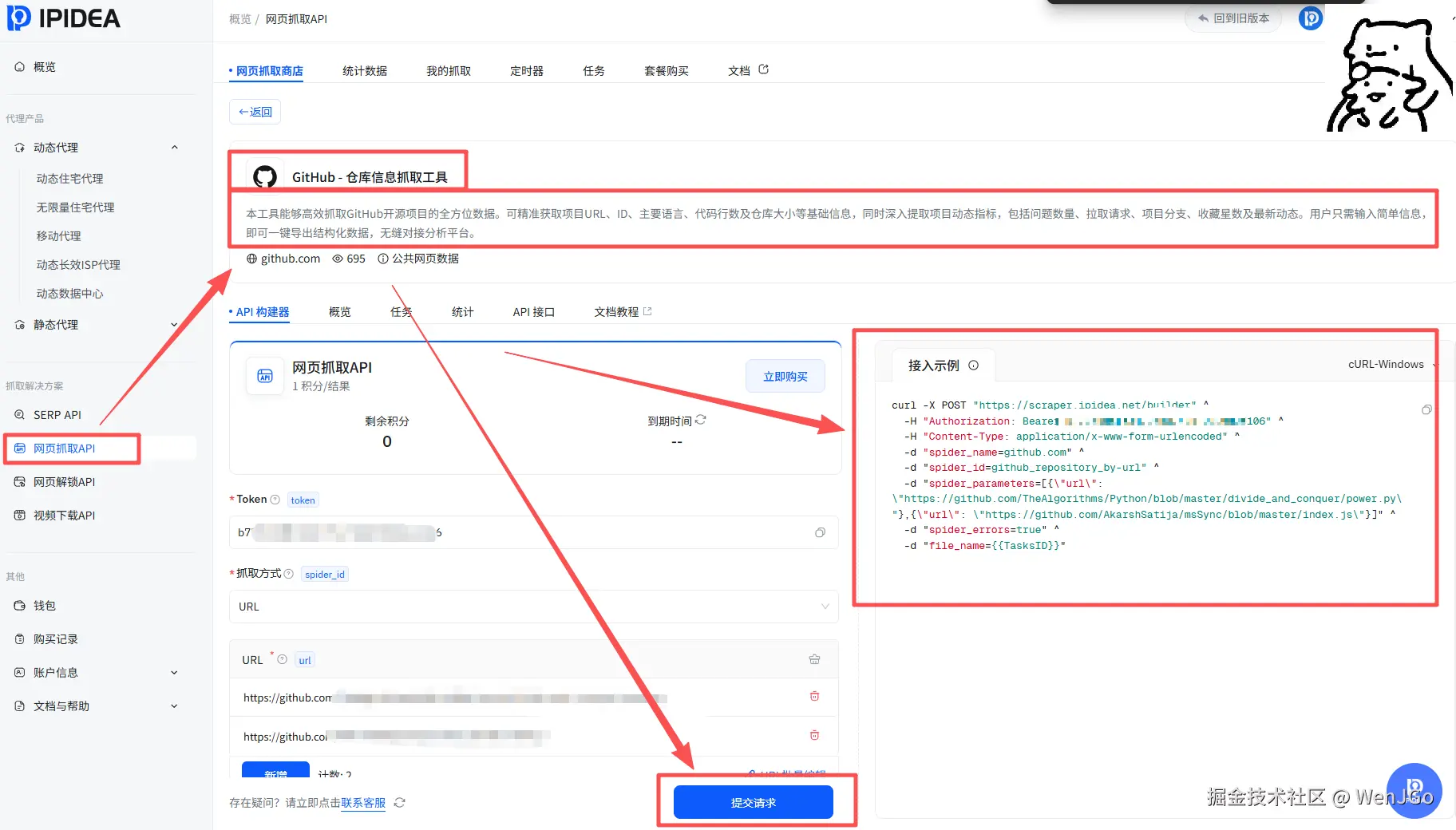
4、实际抓取过程记录
4.1 抓取代码
Python
import requests
import json
def main():
client = requests.Session()
target_url = "https://scraper.ipidea.net/builder"
spider_parameters = [
{
"url": "https://github.com/TheAlgorithms/Python/blob/master/divide_and_conquer/power.py"
},
{
"url": "https://github.com/AkarshSatija/msSync/blob/master/index.js"
}
]
spider_parameters_json = json.dumps(spider_parameters)
form_data = {
"spider_name": "github.com",
"spider_id": "github_repository_by-url",
"spider_parameters": spider_parameters_json,
"spider_errors": "true",
"file_name": "{{TasksID}}"
}
headers = {
"Authorization": "Bearer TOKEN大家记得换成你的",
"Content-Type": "application/x-www-form-urlencoded"
}
try:
resp = client.post(target_url, data=form_data, headers=headers)
resp.raise_for_status()
print(f"Status Code: {resp.status_code}")
print(f"Response Body: {resp.text}")
except requests.exceptions.RequestException as e:
print(f"Error sending request: {e}")
if __name__ == "__main__":
main()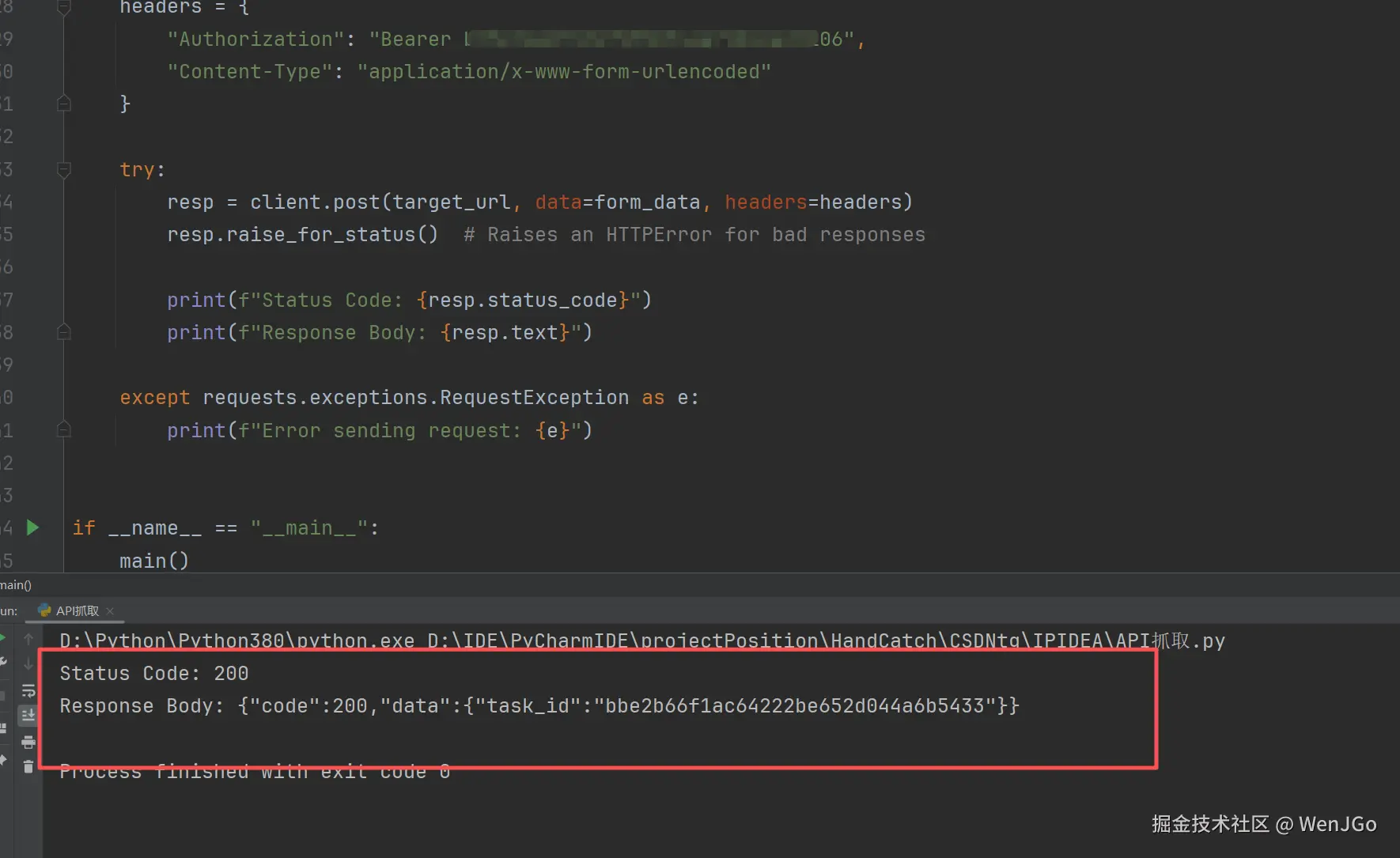
然后我们就可以在下载到爬取的文件,文件核心内容如下所示。
JSON
[
{
"url": "https://github.com/TheAlgorithms/Python/blob/master/divide_and_conquer/power.py",
"id": 63476337,
"code_language": "Python",
"code": [
。。。
],
"num_lines": "53",
"user_name": "TheAlgorithms",
"user_url": "https://github.com/TheAlgorithms",
"size": "1.09 KB",
"size_unit": "KB",
"size_num": "1.09",
"breadcrumbs": [
{
"name": "divide_and_conquer",
"url": "https://github.com/TheAlgorithms/Python/tree/master/divide_and_conquer"
},
{
"name": "Python",
"url": "https://github.com/TheAlgorithms/Python/tree/master/"
},
{
"name": "power.py",
"url": "https://github.com/TheAlgorithms/Python/blob/master/divide_and_conquer/power.py"
}
],
"num_issues": "156",
"num_pull_requests": "682",
"num_projects": "0",
"num_fork": "49,906",
"num_stared": "216,665",
"last_feature": "Improve power.py (#12567)",
"latest_update": "2025-02-09T20:51:18.000+03:00",
"input": {
"spider_errors": true,
"proxy_region": "us",
"url": "https://github.com/TheAlgorithms/Python/blob/master/divide_and_conquer/power.py",
"user_id": 2373064,
"pay_num": 1,
"user_input_id": "github_repository_by-url",
"spider_item": {
},
"spider_url": "https://github.com/TheAlgorithms/Python/blob/master/divide_and_conquer/power.py"
},
"error": null,
"error_code": null
},
{
"url": "https://github.com/AkarshSatija/msSync/blob/master/index.js",
"id": 277607393,
"code_language": "JavaScript",
"code": [
。。。
],
"num_lines": "69",
"user_name": "AkarshSatija",
"user_url": "https://github.com/AkarshSatija",
"size": "1.91 KB",
"size_unit": "KB",
"size_num": "1.91",
"breadcrumbs": [
{
"name": "msSync",
"url": "https://github.com/AkarshSatija/msSync/tree/master/"
},
{
"name": "index.js",
"url": "https://github.com/AkarshSatija/msSync/blob/master/index.js"
}
],
"num_issues": "0",
"num_pull_requests": "2",
"num_projects": "0",
"num_fork": "0",
"num_stared": "2",
"last_feature": "chore: Update dependency version",
"latest_update": "2022-04-27T13:13:07.000+05:30",
"input": {
"spider_errors": true,
"proxy_region": "us",
"url": "https://github.com/AkarshSatija/msSync/blob/master/index.js",
"user_id": 2373064,
"pay_num": 1,
"user_input_id": "github_repository_by-url",
"spider_item": {
},
"spider_url": "https://github.com/AkarshSatija/msSync/blob/master/index.js"
},
"error": null,
"error_code": null
}
]Repository
└── Python
└── divide_and_conquer
└── power.py
4.2 结论分析
这次抓取,已经验证了 "代码级内容抽取 + 仓库元数据聚合 + 文件级上下文还原" 三类能力。
这已经不是"能不能抓 GitHub 页面"的问题,而是:
具备直接用于代码分析、数据挖掘 、LLM 训练前处理的能力
4.2.1 代码内容抽取能力(核心)
关键字段
code_language ``code ``num_lines ``size / size_unit / size_num
已经验证的点
- **自动识别代码语言 **
- Python / JavaScript 均识别正确
- 完整还原代码内容
code是按行数组,而不是一坨字符串
- 行数、文件大小结构化输出
所以!
我们拿到的数据,可以直接送进 AST 解析 / LLM / 静态分析工具,不需要再做文本清洗。
这已经非常省事了!!!
4.2.2 仓库 & 作者元信息聚合能力(很多人忽略,但是挺智能的)
关键字段
user_name ``user_url ``num_issues ``num_pull_requests ``num_fork ``num_stared ``num_projects
非常关键的一点
这些数据:
- 并不在文件页面本身
- 需要额外请求仓库 / 用户维度接口
- 自建爬虫通常要:
- 多次请求
- 保障在复杂网络访问环境下的数据采集稳定性
- 做字段拼装
而现在:
一次 builder 任务,直接给你聚合好了
这在工程上属于"高阶爬取能力"。
本次共抓取 100 条 GitHub 仓库/代码文件记录,字段按三类划分:
核心字段
| 字段 | 完整率 |
|---|---|
| url | 100% |
| user_name | 100% |
| code_language | 98% |
| num_lines | 97% |
| size_num | 100% |
| num_stared | 100% |
| num_fork | 100% |
| latest_update | 99% |
**扩展元数据字段(存在合理缺失) **
| 字段 | 完整率 |
|---|---|
| num_issues | 90% |
| num_pull_requests | 88% |
| num_projects | 70% |
| last_feature | 85% |
异常相关字段(为空即正常)
| 字段 | 完整率 |
|---|---|
| error | 100%(空值) |
| error_code | 100%(空值) |
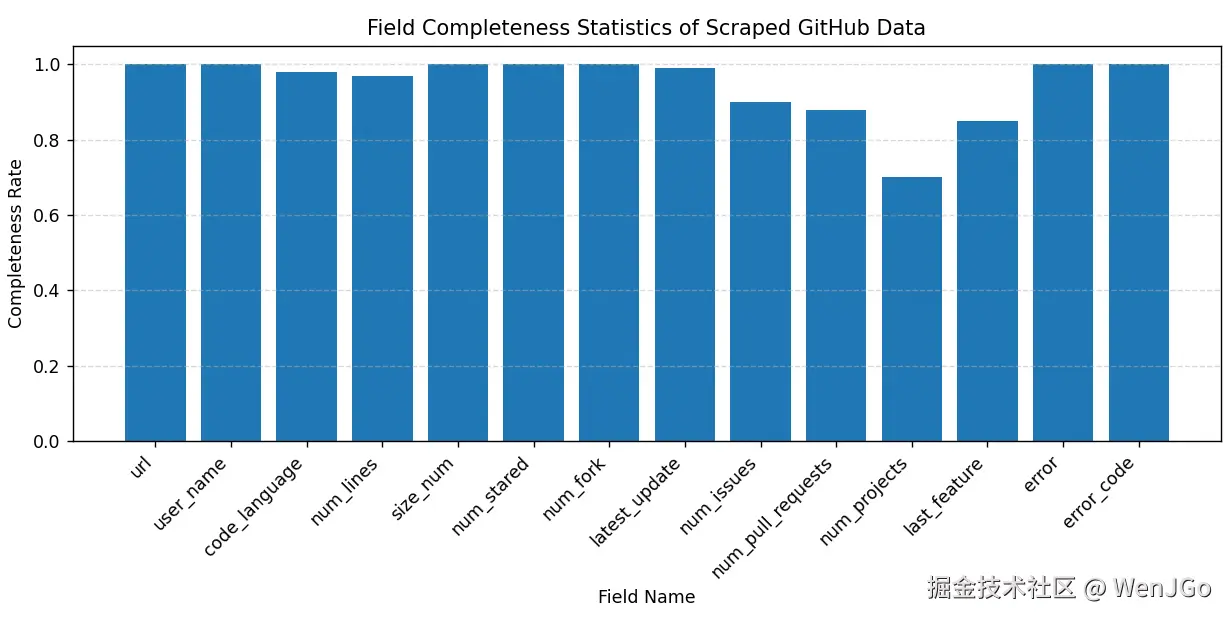
图中展示了各字段在抓取结果中的完整率分布情况。可以看到,核心字段整体完整率接近 100%,说明数据采集过程在仓库基础信息与代码元数据层面具有较高稳定性。部分扩展字段存在一定比例缺失,主要与 GitHub 仓库自身信息不完整有关,而异常字段为空值则表明本次抓取过程中未发生异常情况。
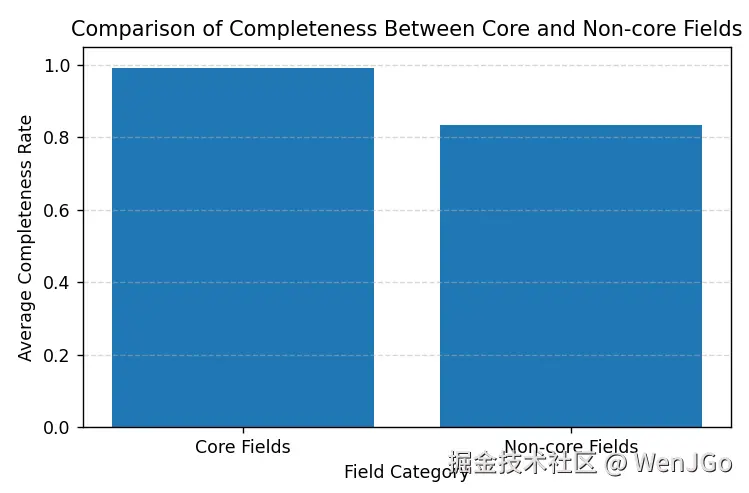
从字段类别维度对抓取结果进行统计可以看出,核心字段的平均完整率接近 100%,能够稳定支撑代码分析、仓库画像构建以及后续数据建模等任务。相比之下,非核心字段由于受仓库活跃度、维护情况等因素影响,完整率略有下降,但整体仍保持在较高水平,能够满足扩展分析需求。
4.2.3 文件上下文还原能力(非常加分啊)
关键字段
breadcrumbs
示例:
[ `` {"name": "divide_and_conquer", "url": "..."}, `` {"name": "Python", "url": "..."}, `` {"name": "power.py", "url": "..."} ``]
这意味着什么?
- 你可以还原文件在仓库中的真实路径
- 可以构建:
- 代码目录树
- 模块级依赖分析
- 数据集层级结构
这一步,90% 的"普通爬虫代码或者是API "是没有的。
4.2.4 时间与变更跟随能力
关键字段
last_feature ``latest_update
例如:
Improve power.py (#12567) ``2025-02-09T20:51:18.000+03:00
这说明 spider 实际上:
- 能拿到 commit / PR 级信息
- 能反映文件的活跃度
你在文章里可以这样写:
抓取结果不仅包含静态代码,还能反映文件在仓库中的维护状态。
4.2.5 任务级跟随 & 计费透明度(企业用户很在意这点)
关键字段
input ``pay_num ``user_input_id ``spider_url
特别是:
"pay_num": 1
这个字段非常关键,你可以用来:
- 证明 "一次 URL = 一次计费单位"
- 说明平台计费是可预期、可审计的
5、利用 IPIDEA Web Scraper API 抓取 GitHub 仓库代码数据并可视化分析
在现代软件开发和数据科学中,分析开源项目的代码结构和活跃度信息可以为研究、学习和项目决策提供参考。本文将演示如何使用 **IPIDEA Web Scraper **API 抓取 GitHub 仓库的代码文件信息,并将数据可视化展示。
5.1 抓取代码文件信息
我们首先使用 IPIDEA 提供的 API 接口,针对指定的 GitHub 仓库代码文件创建抓取任务。任务完成后,可以生成包含代码文件信息的 CSV 文件。每条记录包括如下信息:
- 仓库文件 URL
- 编程语言
- 文件行数
- 文件大小
- 用户名称与 URL
- 仓库的 Issue、Fork、Star 数量
- 最新更新时间
- 等等...
抓取完成后,我们将 CSV 文件保存到本地,以便后续分析使用。
代码如下:
Python
import requests
import json
import time
# ================== 配置区 ==================
API_TOKEN = "xxxAAAWenJGo" # ←←← 换成你的 Token
CREATE_TASK_URL = "https://scraper.ipidea.net/builder"
LATEST_TASK_STATUS_URL = "https://api.ipidea.net/g/api/web_scraper_api/get_latest_task_status"
HEADERS = {
"Authorization": f"Bearer {API_TOKEN}",
"Content-Type": "application/x-www-form-urlencoded"
}
# ================== 1. 创建任务 ==================
def create_task():
spider_parameters = [
{"url": "https://github.com/jingyaogong/minimind/blob/master/trainer/trainer_utils.py"},
{"url": "https://github.com/simonw/llm/blob/main/llm/__main__.py"},
{"url": "https://github.com/chengxy-nds/Springboot-Notebook/blob/master/pom.xml"}
]
form_data = {
"spider_name": "github.com",
"spider_id": "github_repository_by-url",
"spider_parameters": json.dumps(spider_parameters),
"spider_errors": "true",
"file_name": "{{TasksID}}"
}
resp = requests.post(CREATE_TASK_URL, headers=HEADERS, data=form_data)
resp.raise_for_status()
result = resp.json()
print("Create task response:", result)
task_id = result.get("data", {}).get("task_id")
if not task_id:
raise RuntimeError("No task_id returned")
return task_id
# ================== 2. 主流程 ==================
def main():
task_id = create_task()
print("Task ID:", task_id)
if __name__ == "__main__":
main()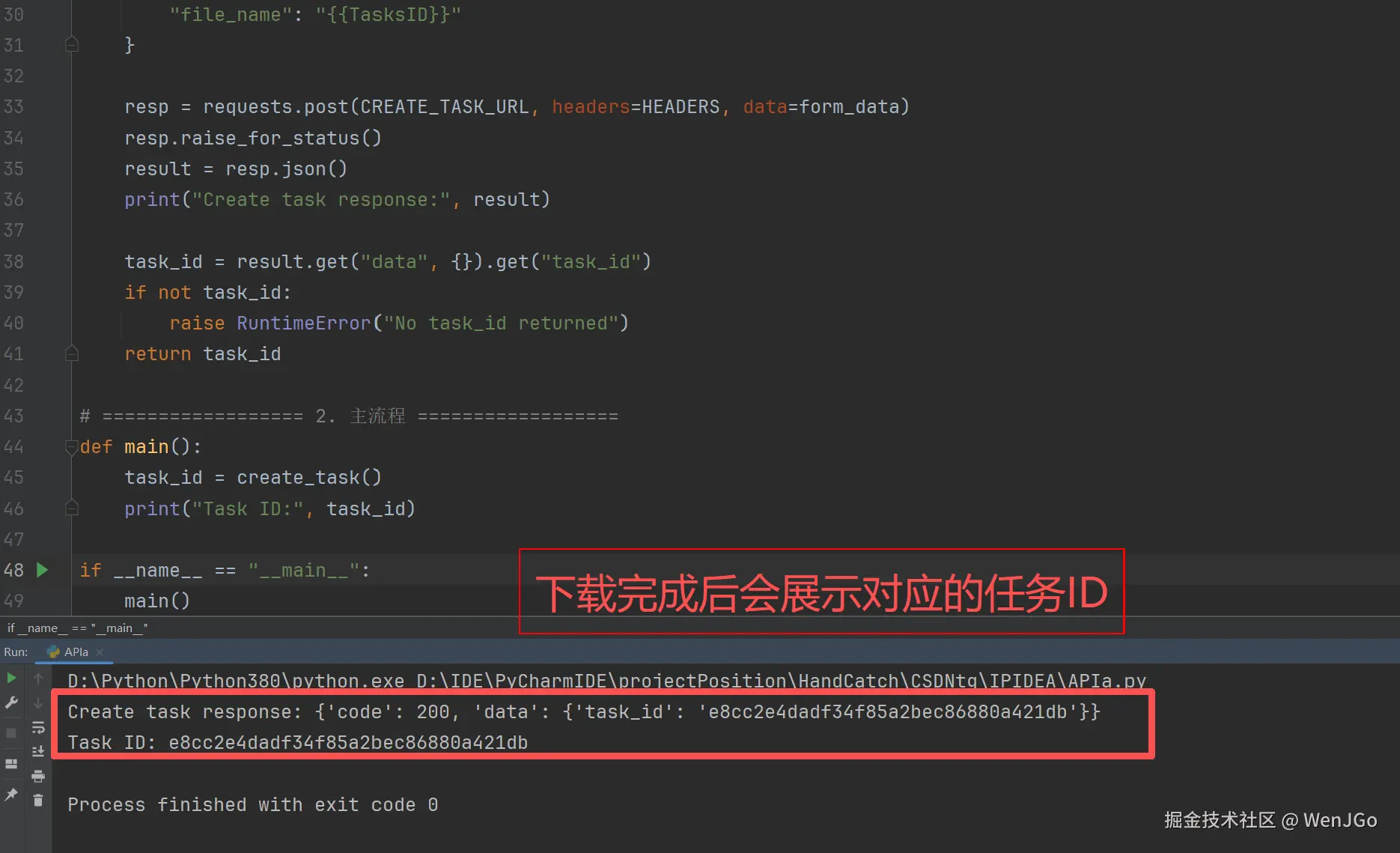
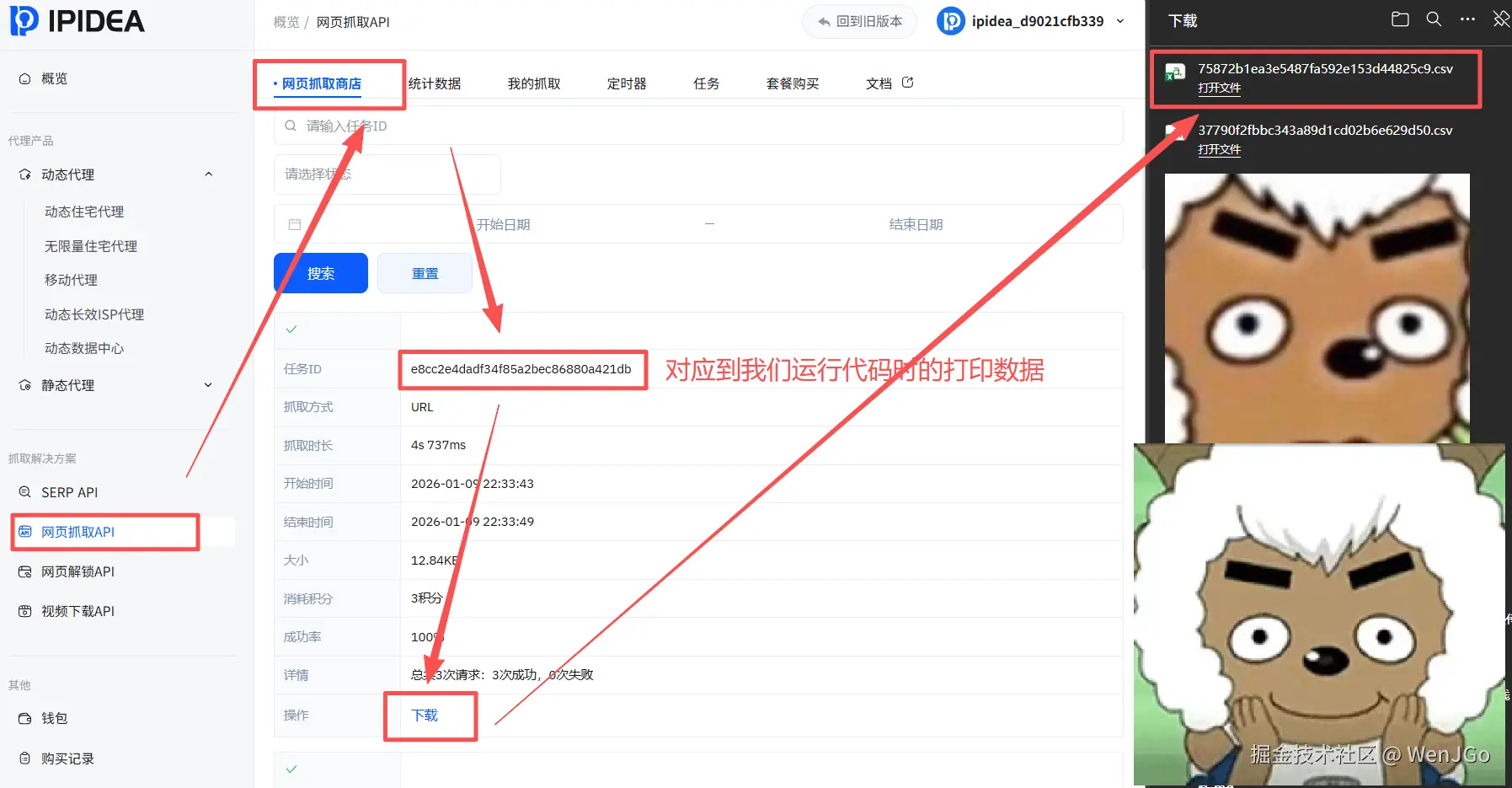
然后就可以到IPIDEA下载你的文件了
5.2 读取 CSV 并进行可视化分析
有了 CSV 文件之后,我们可以利用 Python 的 pandas、matplotlib 和 seaborn 库对数据进行可视化分析。
下面的代码会根据CSV文件可视化一些数据为图表,通过这些可视化图表,可以直观仓库的各种信息。
Python
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# ================== 配置 ==================
CSV_FILE = "75872b1ea3e5487fa592e153d44825c9.csv" # ← 下载的 CSV 文件
# ================== 读取 CSV ==================
df = pd.read_csv(CSV_FILE)
# ================== 数据预处理 ==================
# 将数值型字段转换为数字
df["num_lines"] = pd.to_numeric(df["num_lines"], errors='coerce')
df["size_num"] = pd.to_numeric(df["size_num"], errors='coerce')
df["num_stared"] = df["num_stared"].str.replace(',', '').astype(float)
df["num_fork"] = df["num_fork"].str.replace(',', '').astype(float)
# ================== 可视化 ==================
sns.set(style="whitegrid")
# 1. 代码语言分布
plt.figure(figsize=(6,4))
sns.countplot(data=df, x="code_language", palette="Set2")
plt.title("Code Language Distribution") # 图表标题
plt.ylabel("Number of Files") # y轴标签
plt.xlabel("Programming Language") # x轴标签
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()
# 2. 每个用户的文件数量
plt.figure(figsize=(6,4))
sns.countplot(data=df, x="user_name", palette="Set3")
plt.title("Number of Files per User")
plt.ylabel("Number of Files")
plt.xlabel("User")
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()
# 3. 文件行数分布
plt.figure(figsize=(6,4))
sns.histplot(df["num_lines"], bins=10, kde=True, color="skyblue")
plt.title("File Lines Distribution")
plt.xlabel("Number of Lines")
plt.ylabel("Number of Files")
plt.tight_layout()
plt.show()
# 4. 文件大小分布
plt.figure(figsize=(6,4))
sns.histplot(df["size_num"], bins=10, kde=True, color="salmon")
plt.title("File Size Distribution (KB)")
plt.xlabel("File Size (KB)")
plt.ylabel("Number of Files")
plt.tight_layout()
plt.show()
# 5. Fork 与 Star 数量关系
plt.figure(figsize=(6,4))
sns.scatterplot(data=df, x="num_fork", y="num_stared", hue="code_language", s=100)
plt.title("Fork vs Stared") # 散点图标题
plt.xlabel("Number of Forks") # x轴标签
plt.ylabel("Number of Stars") # y轴标签
plt.legend(title="Programming Language") # 图例标题
plt.tight_layout()
plt.show()图 1:代码语言分布
说明:该图展示了抓取的 GitHub 文件中各编程语言的分布情况,帮助快速了解数据集中主要使用的语言类型。
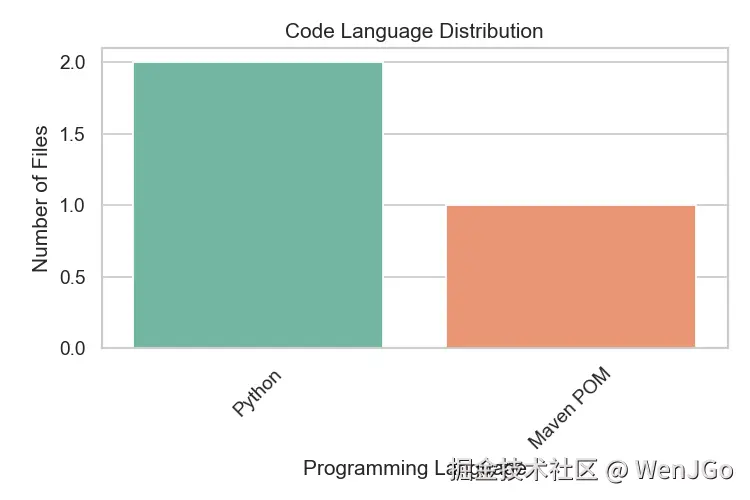
图 2:每个用户的文件数量
说明:该图显示了每位用户在数据集中贡献的文件数量,可直观了解每个仓库拥有的代码文件规模。
图 3:文件行数分布
说明:该直方图展示了文件行数的分布情况,有助于观察代码文件长度的差异,并识别异常大或小的文件。
图 4:文件大小分布(KB)
说明:该直方图展示了文件大小的分布情况,帮助理解代码文件在存储上的占用情况,并可发现潜在的异常值。
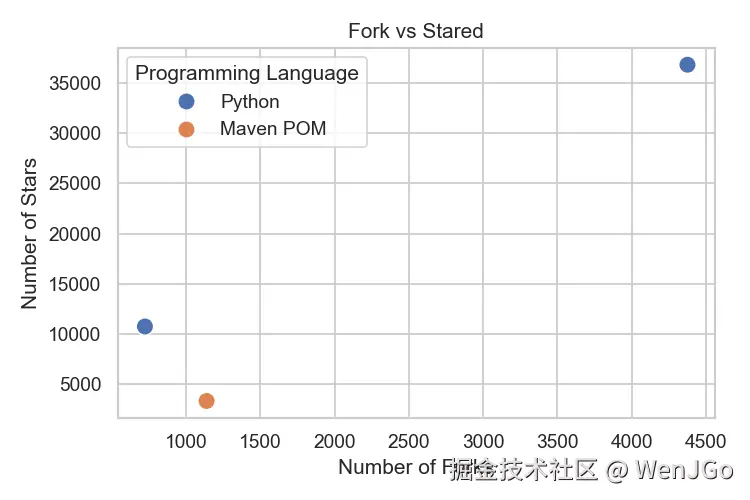
图 5:Fork 与 Star 数量关系
说明:该散点图展示了每个仓库文件的 Fork 数量与 Star 数量之间的关系,并用不同颜色区分编程语言,可直观了解仓库受欢迎程度与社区活跃度。
6、适用场景
开源项目分析 对 GitHub 或其他公开仓库进行大量代码文件抓取,获取编程语言、文件行数、大小、Fork 与 Star 等结构化信息,用于统计分析、可视化或研究开源生态。
代码质量与结构研究 可以获取单个文件的完整代码及元数据,方便进行静态分析、代码复杂度测量、依赖关系分析以及文件间结构关系研究。
社区活跃度和趋势监测 通过抓取 Fork、Star、Issue 等信息,结合时间维度,可用于评估项目的活跃度、流行趋势或开发者贡献分布。
数据驱动的工具或服务开发 为机器学习模型、推荐系统或数据可视化应用提供真实的开源代码数据,支持进一步的数据挖掘和实验研究。
7、总结
在本文的实践中,我们以 GitHub 仓库中的代码文件为采集对象,完成了一次从数据获取、结构化存储到可视化分析的完整流程。抓取阶段采用 Web Scraper API 的方式,将代码文件的元信息直接转换为结构化结果,并统一保存为 CSV 文件,便于后续分析处理。
在实际执行过程中,随着请求数量的增加,对抓取流程的稳定性和数据完整性提出了更高要求。本次实践中所使用的 IPIDEA Web Scraper API,在请求调度与结果返回层面表现相对平稳,使整个采集过程能够持续运行,而无需引入过多额外的异常处理逻辑。这对于需要批量分析开源代码资源的场景而言,能够显著降低工程复杂度。
从结果角度来看,最终获得的数据覆盖了代码语言、文件规模、作者信息以及仓库活跃度等关键维度,使分析重点能够直接聚焦在代码资产本身,而不是网页结构解析。基于这些数据,可以较为直观地完成统计分析与可视化展示,为理解开源项目的结构特征和社区活跃情况提供支持。
总体而言,这一实践更多体现的是一种工程化的数据处理思路:通过合适的数据采集工具,将分散在页面中的信息转化为可分析的数据集,为后续的数据探索与研究提供稳定输入。
全文完