文章目录
- [1. map的底层实现原理](#1. map的底层实现原理)
- [2. 为什么遍历map是无序的?](#2. 为什么遍历map是无序的?)
- [3. 如何实现有序遍历map?](#3. 如何实现有序遍历map?)
- [4. 为什么Go map是非线程安全的?](#4. 为什么Go map是非线程安全的?)
- [5. 线程安全的map如何实现?](#5. 线程安全的map如何实现?)
- [6. Go sync.map 和原生 map 谁的性能好,为什么?](#6. Go sync.map 和原生 map 谁的性能好,为什么?)
- [7. 为什么 Go map 的负载因子是 6.5?](#7. 为什么 Go map 的负载因子是 6.5?)
- [8. map扩容策略是什么?](#8. map扩容策略是什么?)
1. map的底层实现原理
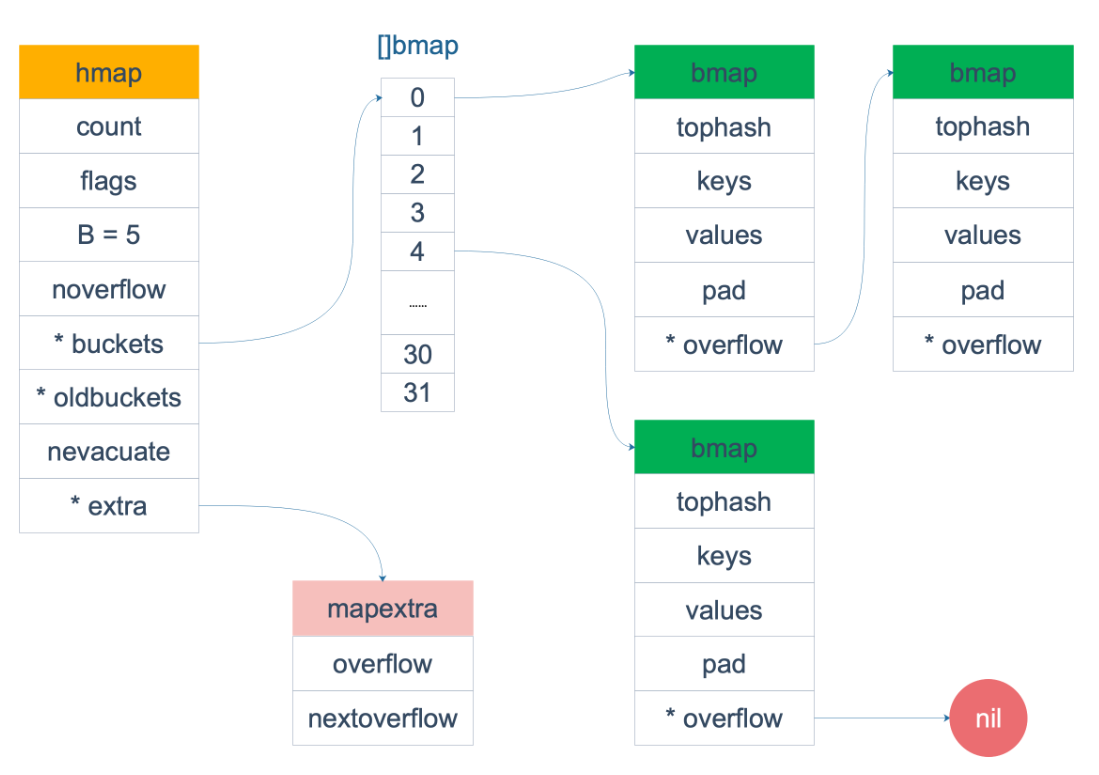
Map的底层实现数据结构实际上是一个哈希表 。在运行时表现为个指向hmap结构的指针,hmap中有记录了桶数组指针 ,溢出桶指针以及元素个数字段 。每个桶是一个bmap的数据结构,可以存储8个键值对和8个tophash以及指向下一个溢出桶的指针 。为了内存紧凑,采用的是先存8个key过后再存value。
2. 为什么遍历map是无序的?
map在遍历的时候会随机一个桶号和槽位,从这个随机的桶号开始,在每个桶中从这个随机的槽位开始遍历完所有的桶。至于为什么要随机开始?
因为map 在扩容后,会发生 key 的搬迁,原来落在同一个 bucket 中的 key,搬迁后,有些 key 的位置就会发生改变。而遍历的过程,就是按顺序遍历 bucket,同时按顺序遍历 bucket 中的 key。搬迁后,key 的位置发生了重大的变化,有些 key 飞上高枝,有些 key 则原地不动。这样,遍历 map 的结果就不可能按原来的顺序了。所以,go语言,强制每次遍历都随机开始。
就是让使用map的程序员都知道,遍历时无序的 如果不这么设计的话,没扩容之前时一直一个顺序 但扩容之后顺序就全然变化了,那会让使用者面临更多困惑 所以不如每一次都时随机遍历
3. 如何实现有序遍历map?
可以在遍历的时候将结果保存到一个slice里面,对slice进行排序
4. 为什么Go map是非线程安全的?
go官方给出的原因是:map 适配的场景应该是简单的(不需要从多个 goroutine 中进行安全访问的),而不是为了小部分情况(并发访问),导致大部分程序付出锁的代价,因此决定了不支持
在查找、赋值、遍历、删除的过程中都会检测写标志,一旦发现写标志置位(等于1),则直接 fatal error。赋值和删除函数在检测完写标志是复位之后,先将写标志位置位,才会进行之后的操作。
检测写标志:
go
if h.flags&hashWriting == 0 {
throw("concurrent map writes")
}设置写标志:
go
h.flags |= hashWriting5. 线程安全的map如何实现?
加锁或者使用sync.map
6. Go sync.map 和原生 map 谁的性能好,为什么?
原生map的性能好,因为Go sync.map为了保证线程安全,以空间换时间,采用了read和dirty两个 map ,用了原子操作和锁两种方式来实现线程安全,只是在操作read的时候用原子操作,当read中不存在某个key的时候要加锁操作dirty,过程中还是会有加锁操作,所以性能上会有损耗。
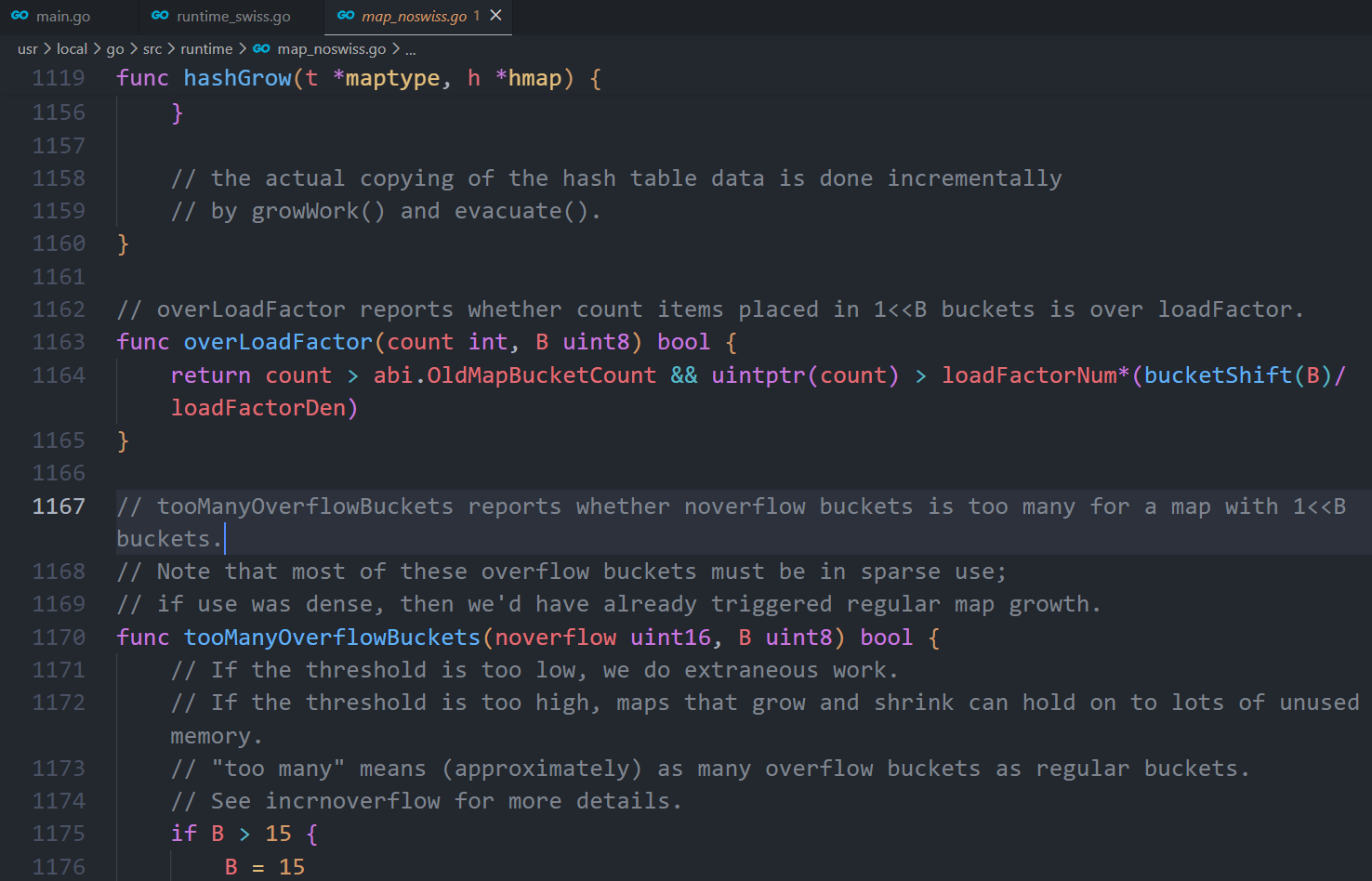
7. 为什么 Go map 的负载因子是 6.5?
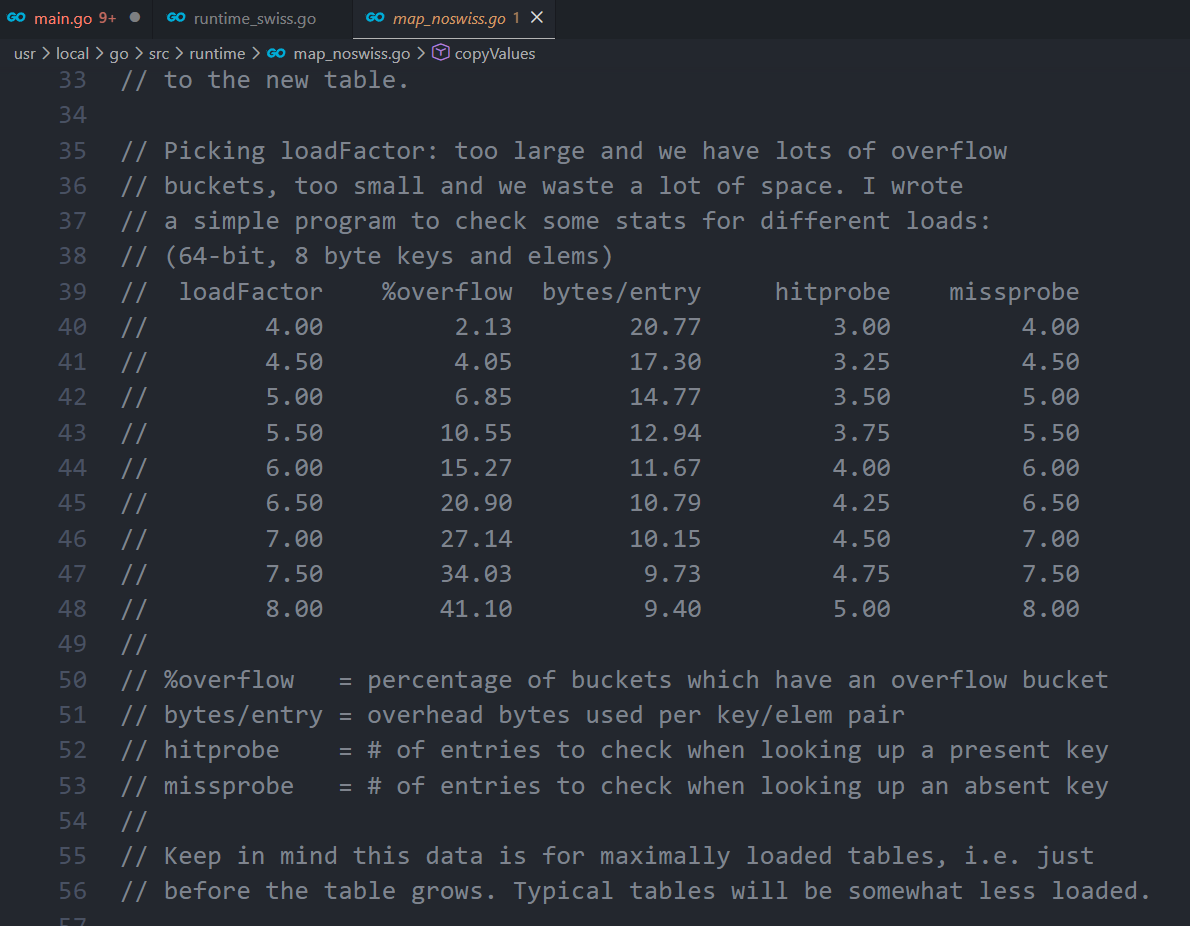
%overflow = 发生过溢出的主 bucket 数 / 主 bucket 总数
注意:它不是"溢出桶数量占比",而是"有 overflow 的主桶占比"。
一个主桶只要挂了至少一个 overflow bucket,就计入。
overflow 链越长,cache locality 越差(内存访问更散)




bash
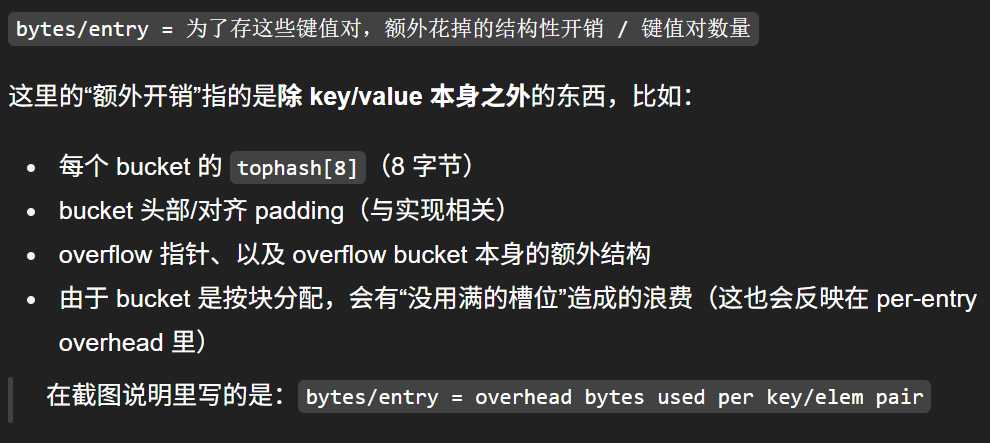
负载因子 = 哈希表存储的元素个数 / 桶个数装载因子越大,填入的元素越多,空间利用率就越高,但发生哈希冲突的几率就变大。
装载因子越小,填入的元素越少,冲突发生的几率减少,但空间浪费也会变得更多,而且还会提高扩容操作的次数
源码里对负载因子的定义是6.5,是经过测试后取出的一个比较合理的值,
每个 bucket 有 8 个空位,假设map里所有的数组桶都装满元素,没有一个数组桶有溢出桶,那么这时的负载因子刚好是8。而负载因子是6.5的时候,说明数组桶快要用完了,存在溢出的情况下,查找一个key很可能要去遍历溢出桶,会造成查找性能下降,所以有必要扩容了
8. map扩容策略是什么?
负载因子已经超过6.5:双倍扩容
溢出桶的数量过多:等量扩容(一般认为溢出桶数量接近正常桶数量时)
当溢出桶过多,发生等量扩容,溢出桶过多的标志:
- 当正常桶数量小于215的时候,溢出桶多于正常桶,溢出桶数量就过多了
- 当正常桶数量大于215 的时候,溢出桶一旦多于215,溢出桶数量就过多了
两个条件之一
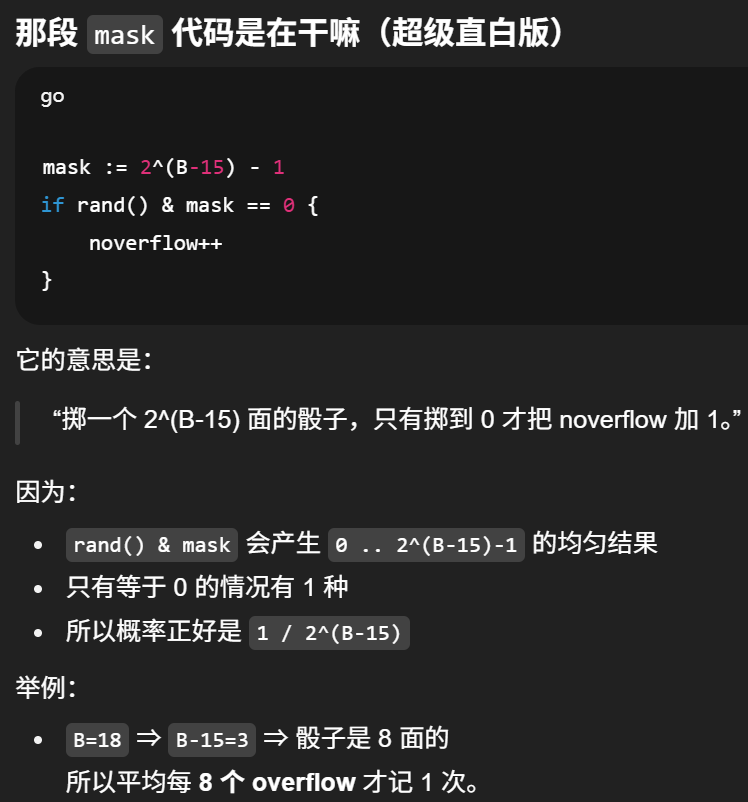
noverflow >= 2B
noverflow >= 215
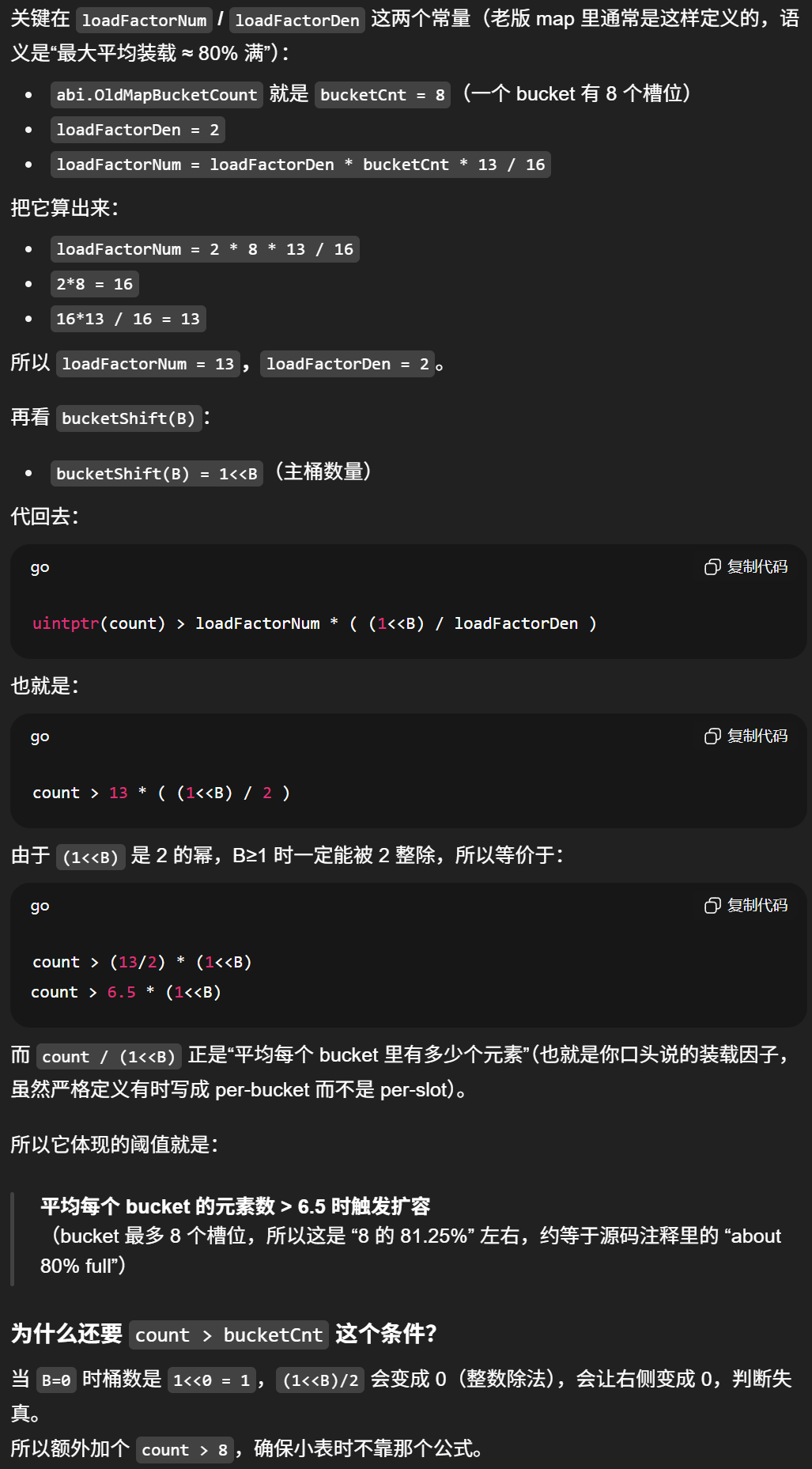
noverflow是溢出桶数量
incrnoverflow() 是 overflow 桶计数器:map 小时精确数,map 大时为了不让 16 位计数器溢出,就改用"随机抽样"来近似计数;当这个近似计数达到约 215 时,就说明 overflow 已经多到该触发等量扩容了。
通俗点讲:incrnoverflow() 就是在"记溢出桶有多少个",用来判断要不要触发等量扩容。
但因为计数器 noverflow 太小(只有 uint16,最多 65535),当 map 很大时不能每个溢出桶都加 1,否则会溢出、失真,所以它改成了抽样计数。





之后我会持续更新,如果喜欢我的文章,请记得一键三连哦,点赞关注收藏,你的每一个赞每一份关注每一次收藏都将是我前进路上的无限动力 !!!↖(▔▽▔)↗感谢支持!