前言
我试过基于模板检测,但是效果很差,所以,采用了YOLO的物体检测+训练,从结果来说,效果很好,但是需要很多的素材,当然,没有什么事情从一开始就简单的,这篇文章,虽说是写王者荣耀的对象检测,其实,根据素材和标注的不同,也可以用于其他场景,可以说是运用广泛。
1. 环境依赖
shell
# 基础依赖
pip install opencv-python numpy
# 如果需要使用YOLOv8训练
pip install ultralytics torch torchvision
# 如果需要使用YOLOv5
pip install -r https://raw.githubusercontent.com/ultralytics/yolov5/master/requirements.txt下载YOLO字体(迅雷):https://ultralytics.com/assets/Arial.Unicode.ttf
放到:C:\Users\用户名\AppData\Roaming\Ultralytics\
2. 数据准备
目录结构
shell\
game_dataset/ (数据集根目录)
├── images/ (存放所有图片)
│ ├── train/ (训练集图片)
│ ├── val/ (验证集图片)
│ └── test/ (测试集图片,可选)
└── labels/ (存放所有标注文件,与images结构相同)
├── train/
├── val/
└── test/也可以用代码执行
配置常量,通过常量统一管理变量,实现快速变更测试。
python
# YOLO模型
YOLO_MODEL_PATH = './static/yolov8n.pt'
# 训练项目名称
PROJECT_NAME = 'game_detection'
# 模型版本
MODEL_VERSION = 'wzry_yolo_v1'
# 训练保存的模型
SAVE_MODEL_NAME = PROJECT_NAME + '/' + MODEL_VERSION
# 数据集基本目录
DATASET_BASE_PATH = './game_dataset'
# 配置文件路径
DATA_YAML_PATH = './game_dataset/data.yaml'
# 训练好的最佳模型路径
BEST_MODEL_PATH = f'{PROJECT_NAME}/{MODEL_VERSION}/weights/best.pt'
# 测试场景图片
SCENSE_IMG_PATH = "H:/lrc/Pictures/opencv/scene6.png"
# 测试结果路径
SCENSE_RESULT_PATH = './recognition'
# 文件目录结构
DIRECTORIES = [
f'{DATASET_BASE_PATH}/images/train',
f'{DATASET_BASE_PATH}/game_dataset/images/val',
f'{DATASET_BASE_PATH}/game_dataset/images/test',
f'{DATASET_BASE_PATH}/game_dataset/labels/train',
f'{DATASET_BASE_PATH}/game_dataset/labels/val',
f'{DATASET_BASE_PATH}/game_dataset/labels/test'
]
# classes 类目列表
CLASS_NAMES = [
'soldiers',
'enemy_soldiers',
'our_hero',
'enemy_hero',
'me',
'tower',
'enemy_tower',
'monster',
'hp_monster',
'mp_monster',
'dragon',
'dominate',
'grass',
'wall'
]代码执行方法:
python
def create_dataset_structure():
"""创建YOLO训练所需的数据集目录结构"""
# 这是YOLO标准的数据集目录结构
# game_dataset/ (数据集根目录)
# ├── images/ (存放所有图片)
# │ ├── train/ (训练集图片)
# │ ├── val/ (验证集图片)
# │ └── test/ (测试集图片,可选)
# └── labels/ (存放所有标注文件,与images结构相同)
# ├── train/
# ├── val/
# └── test/
for directory in DIRECTORIES:
os.makedirs(directory, exist_ok=True)
print(f"创建目录: {directory}")
print("\n 数据集目录结构创建完成!")3. 配置数据集yaml文件
通过代码配置生成,避免手动操作的失误。
yaml
def create_data_config():
"""
创建数据集配置文件
这个文件告诉YOLO模型:
1. 数据集在哪里
2. 有哪些类别
3. 每个类别的名称是什么
"""
# 读取classes
os.read("")
# YAML配置文件内容
data_config = {
# 'path': 数据集根目录的路径
# 训练时会根据这个路径找到所有数据
'path': DATASET_BASE_PATH,
# 'train': 训练集图片的路径
# YOLO会自动在这个路径下查找图片
'train': 'images/train',
# 'val': 验证集图片的路径
# 验证集用于在训练过程中评估模型性能
'val': 'images/val',
# 'test': 测试集图片的路径(可选)
# 测试集用于最终评估模型性能
'test': 'images/test',
# 'nc': 类别数量 (Number of Classes)
# 我们要检测多少种不同的物体
'nc': len(CLASS_NAMES),
# 'names': 类别名称列表
# 列表顺序非常重要!每个数字索引对应一个类别
# 索引0 -> 'hero'
# 索引1 -> 'vehicle'
# 索引2 -> 'tower'
# 索引3 -> 'enemy_hero'
# 索引4 -> 'monster'
'names': CLASS_NAMES
}
# 将配置保存为YAML文件
with open(DATA_YAML_PATH, 'w', encoding='utf-8') as f:
yaml.dump(data_config, f, default_flow_style=False, allow_unicode=True)
print(f" 数据集配置文件已创建: {DATA_YAML_PATH}")
# 显示配置文件内容
print("\n配置文件内容:")
print("=" * 50)
with open(DATA_YAML_PATH, 'r', encoding='utf-8') as f:
print(f.read())
print("=" * 50)写入的yaml格式
shell
names:
- soldiers
- enemy_soldiers
- our_hero
- enemy_hero
- me
- tower
- enemy_tower
- monster
- hp_monster
- mp_monster
- dragon
- dominate
- grass
- wall
nc: 14
path: E:/workspace/git/test_opencv/game_dataset
test: images/test
train: images/train
val: images/val注意:names的顺序,也就是它的索引号,对应标注文件.txt里的顺序
4. 标注工具:label-studio
别用Labellimg,一直闪退
shell
conda create -n labelstudio python=3.8
conda activate labelstudio
# 安装
pip install label-studio
# 启动
label-studio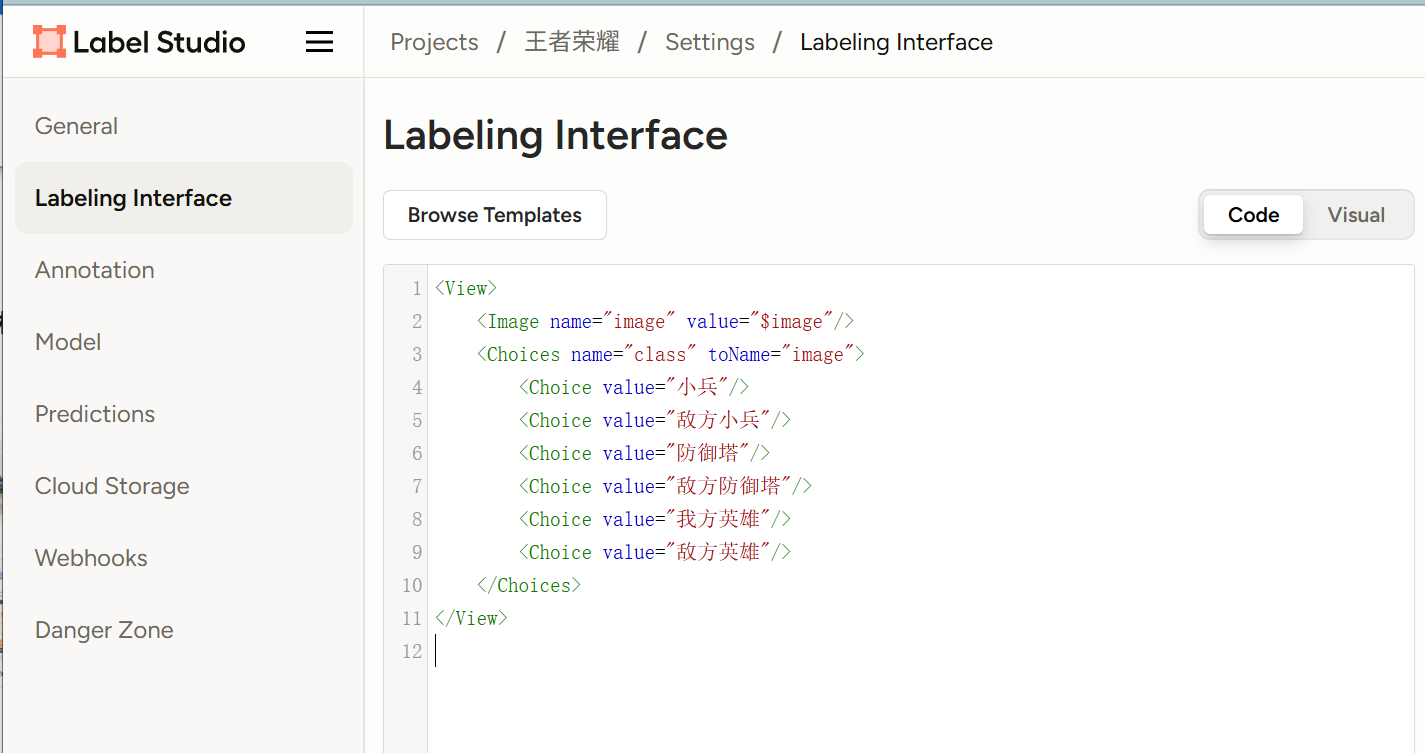
创建类别,右上角(setting)-》Labeling Interface
txt
<View>
<Image name="image" value="$image"/>
<Choices name="class" toName="image">
<Choice value="小兵"/>
<Choice value="敌方小兵"/>
<Choice value="防御塔"/>
<Choice value="敌方防御塔"/>
<Choice value="我方英雄"/>
<Choice value="敌方英雄"/>
</Choices>
</View>然后点击
进行标注,数字123标识label,CTRL+enter保存下一张
但是它导不出YOLO格式数据,还需要转换,而且操作也麻烦,所以建议使用Labelimg
4.2标注工具:Labelimg
虽然简单好用,但是容易崩溃,如果要使用最好用conda创建新环境使用。
python
conda create -n labelstudio python=3.8
conda activate labelstudio
pip install labelimg
labelimg
labelimg ./data predefined_classes.txt
4.3 标注工具:make-sense(推荐)
这是一个英文的在线标注平台,操作界面也挺简单的,这里没有截图,太简单了,直接在网页操作,导出就行。
5. train和val文件夹
将LabelStudio导出的标注文件分别按8:2的比例复制到images/train和images/val
标注文件txt文件也复制到label/train和images/val
最后的结构应是这样的:
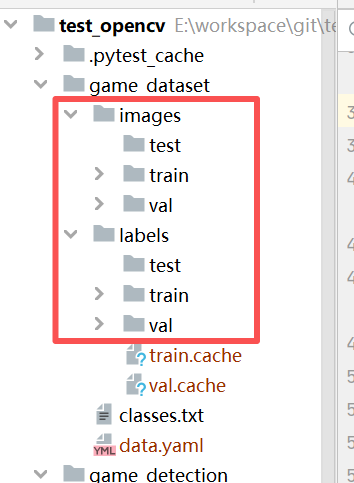
6. 验证
单独的验证方法,通过调整置信度来测试(conf_threshold),值越高,只显示越确信的框,漏检可能增加;值越低,显示的框越多,误检也可能增加。
python
def scene_single_image(image_path=SCENSE_IMG_PATH, conf_threshold=0.5):
"""
使用训练好的YOLO模型检测单张图片。
参数:
model_path (str): 训练好的模型路径 (例如: 'runs/detect/wzry_yolov8n/weights/best.pt')
image_path (str): 待检测的图片路径
conf_threshold (float): 置信度阈值,高于此值的检测框才会被显示
"""
# 1. 加载训练好的模型
print(f"正在加载模型: {BEST_MODEL_PATH}")
model = YOLO(BEST_MODEL_PATH)
# 2. 读取图片
print(f"正在读取图片: {image_path}")
img = cv.imdecode(np.fromfile(file=image_path, dtype=np.uint8), cv.IMREAD_COLOR)
if img is None:
print(f"错误!无法读取图片,请检查路径: {image_path}")
return
# 3. 进行推理(预测)
print("正在进行推理...")
results = model.predict(
source=img, # 输入源
conf=conf_threshold, # 置信度阈值,可调
save=False, # 设为True会自动保存图片到runs/detect/predict
show=False, # 设为True会弹出显示窗口
verbose=False # 设为True会打印详细结果
)
# 4. 解析并打印检测结果
result = results[0] # 因为只预测了一张图,所以取第一个结果
print(f"\n[INFO] 检测完成!")
print(f" 图片尺寸: {result.orig_shape}")
print(f" 检测到 {len(result.boxes)} 个目标:\n")
# 5. 在图片上绘制结果
result_img = result.plot() # 这个方法会返回一个绘制了所有框和标签的图片(BGR格式)
# 6. 显示和保存结果
cv.namedWindow('Detection Results', cv.WINDOW_NORMAL)
cv.resizeWindow('Detection Results', 1200, 800) # 可调整为你喜欢的大小
cv.imshow('Detection Results', result_img) # result_img已经是BGR格式
print(f"按任意键关闭窗口...")
cv.waitKey(0) # 等待按键
cv.destroyAllWindows() # 关闭所有OpenCV窗口
# 可选:保存结果图片
image_path_split = os.path.split(image_path)
image_name = image_path_split[len(image_path_split) - 1]
image_name_split = image_name.split('.')
output_path = SCENSE_RESULT_PATH + '/' + image_name_split[0] + '_result' + image_name_split[1]
cv.imwrite(output_path, result_img)
print(f"结果图片已保存至: {output_path}")
# 7. (可选)详细列出每个检测到的物体信息
print("\n详细检测信息:")
print("-" * 50)
for i, box in enumerate(result.boxes):
# 获取坐标、置信度、类别ID
xyxy = box.xyxy[0].tolist() # 左上右下坐标 [x1, y1, x2, y2]
conf = box.conf[0].item() # 置信度
cls_id = int(box.cls[0]) # 类别ID
cls_name = result.names[cls_id] # 类别名称
# 计算中心点坐标(相对于原图)
center_x = int((xyxy[0] + xyxy[2]) / 2)
center_y = int((xyxy[1] + xyxy[3]) / 2)
print(f"目标 {i + 1}:")
print(f" 类别: {cls_name} ({cls_id})")
print(f" 置信度: {conf:.4f}")
print(f" 边界框 (像素): [{int(xyxy[0])}, {int(xyxy[1])}, {int(xyxy[2])}, {int(xyxy[3])}]")
print(f" 中心点坐标: ({center_x}, {center_y})")
print("-" * 30)7. 训练
python
def train_custom_yolo():
"""训练自定义YOLO模型"""
print("\n 开始训练自定义YOLO模型...")
# 检查CUDA是否可用(NVIDIA GPU)
if torch.cuda.is_available():
device = 'cuda' # 使用GPU
gpu_name = torch.cuda.get_device_name(0)
print(f"检测到GPU: {gpu_name}")
else:
device = 'cpu' # 使用CPU
print("未检测到GPU,使用CPU训练(训练会很慢)")
# 加载预训练模型
# 'yolov8n.pt' 是YOLOv8的nano版本,体积小,适合快速训练
# 也可以选择其他版本:
# - yolov8n.pt (nano, 最小最快)
# - yolov8s.pt (small)
# - yolov8m.pt (medium)
# - yolov8l.pt (large)
# - yolov8x.pt (xlarge, 最大最准)
print("正在加载YOLOv8n预训练模型...")
model = YOLO(YOLO_MODEL_PATH)
# 开始训练
print("\n📊 开始训练,参数配置:")
print(f" 数据集: {DATA_YAML_PATH}")
print(f" 设备: {device}")
print(f" 训练轮数: 100")
print(f" 图片尺寸: 640x640")
print(f" 批大小: 16")
if os.path.exists(SAVE_MODEL_NAME):
shutil.rmtree(SAVE_MODEL_NAME)
# 训练参数说明:
results = model.train(
# data: 数据集配置文件路径
data=DATA_YAML_PATH,
# epochs: 训练轮数
# 模型会完整遍历数据集多少次
# 通常100-300轮,根据数据集大小调整
epochs=100,
# imgsz: 输入图片尺寸
# YOLO会将所有图片缩放到这个尺寸
# 越大越准确但越慢,常用640或320
imgsz=640,
# batch: 批大小
# 一次处理多少张图片
# 越大训练越快,但需要更多显存
batch=16,
# device: 训练设备
# 'cuda' = GPU, 'cpu' = CPU, '0' = 第一块GPU
device=device,
# workers: 数据加载线程数
# 用于并行加载数据,提高数据读取速度
workers=4,
# project: 项目名称
# 训练结果会保存在runs/detect/{project}目录下
project=PROJECT_NAME,
# name: 训练任务名称
# 会创建一个子目录保存本次训练的所有结果
name=SAVE_MODEL_NAME,
# 以下是可选的高级参数:
# lr0: 初始学习率 (默认0.01)
lr0=0.01,
# lrf: 最终学习率因子 (默认0.01)
# 学习率会从lr0衰减到lr0*lrf
lrf=0.01,
# momentum: 动量参数 (默认0.937)
momentum=0.937,
# weight_decay: 权重衰减 (默认0.0005)
weight_decay=0.0005,
# warmup_epochs: 热身轮数 (默认3.0)
# 前几轮使用较小的学习率
warmup_epochs=3.0,
# box: 边界框损失权重 (默认7.5)
box=7.5,
# cls: 分类损失权重 (默认0.5)
cls=0.5,
# dfl: DFL损失权重 (默认1.5)
dfl=1.5,
# patience: 早停耐心值 (默认100)
# 如果验证集性能在patience轮内没有提升,则提前停止训练
patience=50,
# save_period: 保存周期 (默认-1)
# 每多少轮保存一次中间模型,-1表示只在最后保存
save_period=10,
# 是否使用数据增强
# 通过翻转、旋转、缩放等方式增加数据多样性
augment=True,
# 是否使用马赛克数据增强
# 将4张图片拼成1张进行训练
mosaic=1.0,
# 是否使用cutout数据增强
# 随机遮挡部分图像
hsv_h=0.015, # 色调增强
hsv_s=0.7, # 饱和度增强
hsv_v=0.4, # 亮度增强
degrees=0.0, # 旋转角度
translate=0.1, # 平移
scale=0.5, # 缩放
shear=0.0, # 剪切
perspective=0.0, # 透视变换
flipud=0.0, # 上下翻转概率
fliplr=0.5, # 左右翻转概率
mixup=0.0, # mixup数据增强概率
)
print("\n 训练完成!")
print(f"最佳模型保存在: {BEST_MODEL_PATH}")
return results日志如下:

Epoch:当前轮数
GPU_mem:GPU显存
box_loss:边界框回归损失,预测物体边界框位置和真实标注框的差异;值越低越好
cls_loss:分类损失,衡量预测物体类别与真实类别之间的差异;值越低越好
dfl_loss:分布焦点损失,YOLO8引入的,优化边界回归,让模型学习更灵活、更准确的边界框分布;值越低越好
instanse:当前批次的训练图片中,检测到目标物体的评价数量
size:模型输入图片的分辨率
Class:类别名称,all标识所以类别的平均值
Images:用于验证图片总数,13表示验证集有13张图片
Instances:验证集中,所以真实标注的目标物体的总数
Box(P:精确率,在所以被预测为阳性(检测为物体)的边界框中,有多少真正正确的;值越高越好(0-1)
Box(R:召回率,在所以真实存在的物体中,模型成功检测出多少;值越高越好
mAP50:在IoU阈值为0.5时的平均精度,目标检测的最核心综合评估指标;值越高越好(0-1)
mAP50-95:在IoU阈值从0.5-0.95区间内,多个mAP的平均值
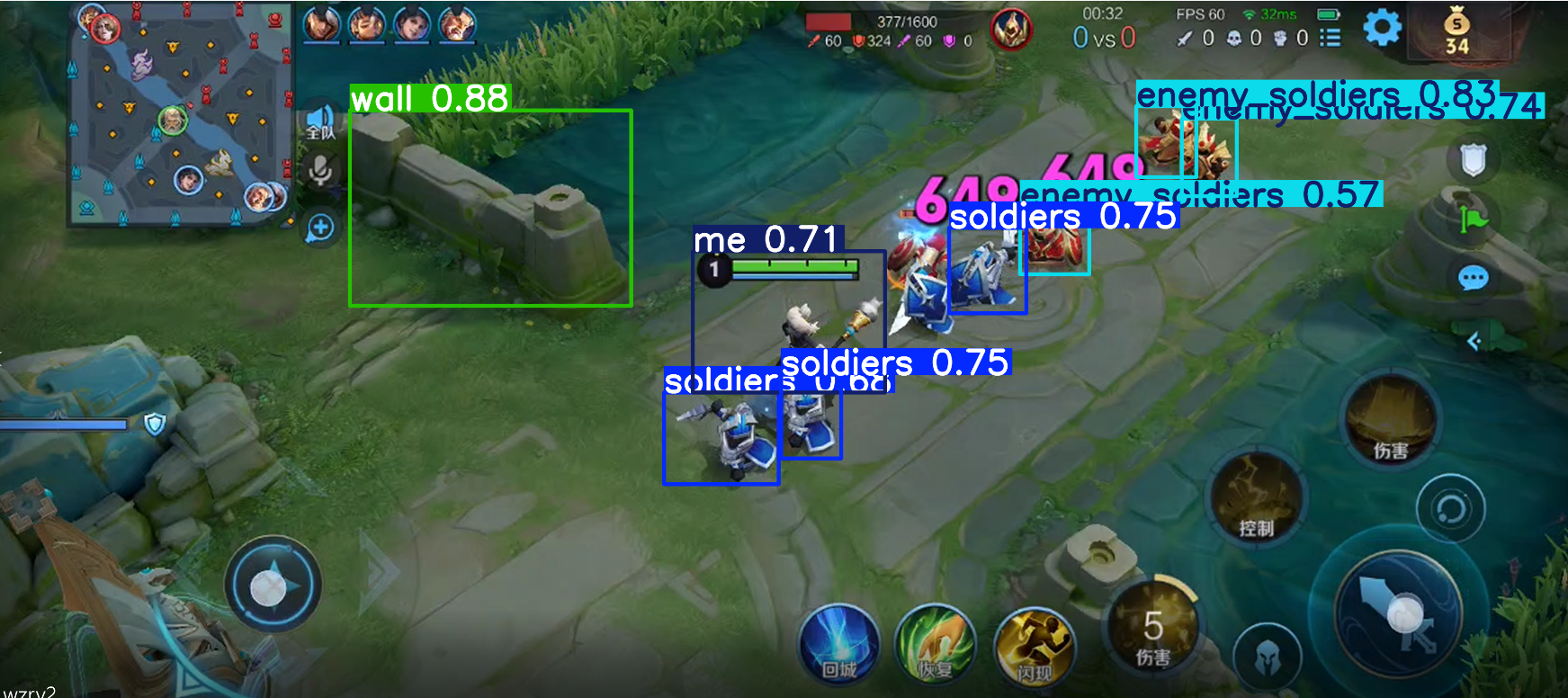
8. 结果
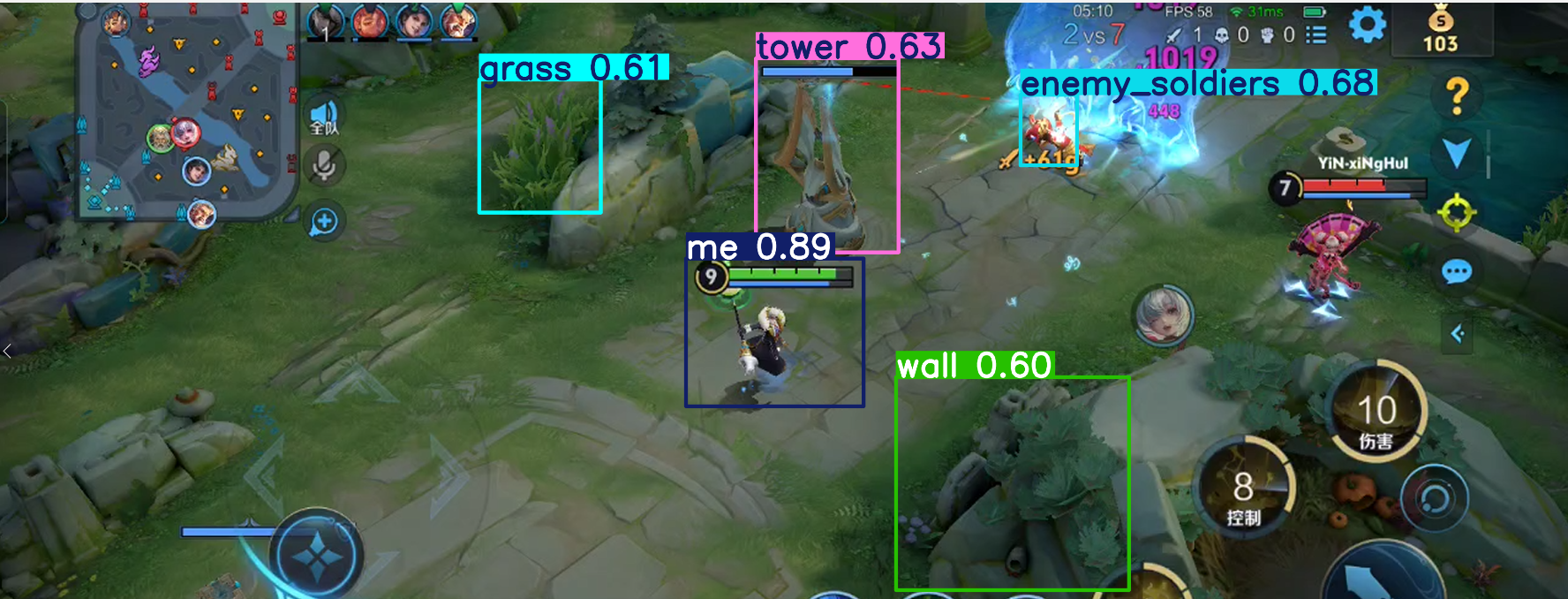
下面是用了30张样张训练的效果,已经能够识别基础对象了,但对于全英雄识别,这个工作量是巨大的需要上千张样张,和上百个游戏视频。
9. 完整代码
python
import os
import cv2 as cv
import numpy as np
import yaml # 用于读写YAML格式的配置文件
from ultralytics import YOLO # YOLOv8的Python接口
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
import torch # PyTorch深度学习框架
import shutil
# YOLO模型
YOLO_MODEL_PATH = './static/yolov8n.pt'
# 训练项目名称
PROJECT_NAME = 'game_detection'
# 模型版本
MODEL_VERSION = 'wzry_yolo_v1'
# 训练保存的模型
SAVE_MODEL_NAME = PROJECT_NAME + '/' + MODEL_VERSION
# 数据集基本目录
DATASET_BASE_PATH = './game_dataset'
# 配置文件路径
DATA_YAML_PATH = './game_dataset/data.yaml'
# 训练好的最佳模型路径
BEST_MODEL_PATH = f'{PROJECT_NAME}/{MODEL_VERSION}/weights/best.pt'
# 测试场景图片
SCENSE_IMG_PATH = "H:/lrc/Pictures/opencv/scene6.png"
# 测试结果路径
SCENSE_RESULT_PATH = './recognition'
# 文件目录结构
DIRECTORIES = [
f'{DATASET_BASE_PATH}/images/train',
f'{DATASET_BASE_PATH}/game_dataset/images/val',
f'{DATASET_BASE_PATH}/game_dataset/images/test',
f'{DATASET_BASE_PATH}/game_dataset/labels/train',
f'{DATASET_BASE_PATH}/game_dataset/labels/val',
f'{DATASET_BASE_PATH}/game_dataset/labels/test'
]
# classes 类目列表
CLASS_NAMES = [
'soldiers',
'enemy_soldiers',
'our_hero',
'enemy_hero',
'me',
'tower',
'enemy_tower',
'monster',
'hp_monster',
'mp_monster',
'dragon',
'dominate',
'grass',
'wall'
]
# 创建数据集目录
def create_dataset_structure():
"""创建YOLO训练所需的数据集目录结构"""
# 这是YOLO标准的数据集目录结构
# game_dataset/ (数据集根目录)
# ├── images/ (存放所有图片)
# │ ├── train/ (训练集图片)
# │ ├── val/ (验证集图片)
# │ └── test/ (测试集图片,可选)
# └── labels/ (存放所有标注文件,与images结构相同)
# ├── train/
# ├── val/
# └── test/
for directory in DIRECTORIES:
os.makedirs(directory, exist_ok=True)
print(f"创建目录: {directory}")
print("\n 数据集目录结构创建完成!")
# 创建配置文件,
def create_data_config():
"""
创建数据集配置文件
这个文件告诉YOLO模型:
1. 数据集在哪里
2. 有哪些类别
3. 每个类别的名称是什么
"""
# 读取classes
os.read("")
# YAML配置文件内容
data_config = {
# 'path': 数据集根目录的路径
# 训练时会根据这个路径找到所有数据
'path': DATASET_BASE_PATH,
# 'train': 训练集图片的路径
# YOLO会自动在这个路径下查找图片
'train': 'images/train',
# 'val': 验证集图片的路径
# 验证集用于在训练过程中评估模型性能
'val': 'images/val',
# 'test': 测试集图片的路径(可选)
# 测试集用于最终评估模型性能
'test': 'images/test',
# 'nc': 类别数量 (Number of Classes)
# 我们要检测多少种不同的物体
'nc': len(CLASS_NAMES),
# 'names': 类别名称列表
# 列表顺序非常重要!每个数字索引对应一个类别
'names': CLASS_NAMES
}
# 将配置保存为YAML文件
with open(DATA_YAML_PATH, 'w', encoding='utf-8') as f:
yaml.dump(data_config, f, default_flow_style=False, allow_unicode=True)
print(f" 数据集配置文件已创建: {DATA_YAML_PATH}")
# 显示配置文件内容
print("\n配置文件内容:")
print("=" * 50)
with open(DATA_YAML_PATH, 'r', encoding='utf-8') as f:
print(f.read())
print("=" * 50)
# 训练模型
def train_custom_yolo():
"""训练自定义YOLO模型"""
print("\n🚀 开始训练自定义YOLO模型...")
# 检查CUDA是否可用(NVIDIA GPU)
if torch.cuda.is_available():
device = 'cuda' # 使用GPU
gpu_name = torch.cuda.get_device_name(0)
print(f"检测到GPU: {gpu_name}")
else:
device = 'cpu' # 使用CPU
print("未检测到GPU,使用CPU训练(训练会很慢)")
# 加载预训练模型
# 'yolov8n.pt' 是YOLOv8的nano版本,体积小,适合快速训练
# 也可以选择其他版本:
# - yolov8n.pt (nano, 最小最快)
# - yolov8s.pt (small)
# - yolov8m.pt (medium)
# - yolov8l.pt (large)
# - yolov8x.pt (xlarge, 最大最准)
print("正在加载YOLOv8n预训练模型...")
model = YOLO(YOLO_MODEL_PATH)
# 开始训练
print("\n 开始训练,参数配置:")
print(f" 数据集: {DATA_YAML_PATH}")
print(f" 设备: {device}")
print(f" 训练轮数: 100")
print(f" 图片尺寸: 640x640")
print(f" 批大小: 16")
if os.path.exists(SAVE_MODEL_NAME):
shutil.rmtree(SAVE_MODEL_NAME)
# 训练参数说明:
results = model.train(
# data: 数据集配置文件路径
data=DATA_YAML_PATH,
# epochs: 训练轮数
# 模型会完整遍历数据集多少次
# 通常100-300轮,根据数据集大小调整
epochs=100,
# imgsz: 输入图片尺寸
# YOLO会将所有图片缩放到这个尺寸
# 越大越准确但越慢,常用640或320
imgsz=640,
# batch: 批大小
# 一次处理多少张图片
# 越大训练越快,但需要更多显存
batch=16,
# device: 训练设备
# 'cuda' = GPU, 'cpu' = CPU, '0' = 第一块GPU
device=device,
# workers: 数据加载线程数
# 用于并行加载数据,提高数据读取速度
workers=4,
# project: 项目名称
# 训练结果会保存在runs/detect/{project}目录下
project=PROJECT_NAME,
# name: 训练任务名称
# 会创建一个子目录保存本次训练的所有结果
name=SAVE_MODEL_NAME,
# 以下是可选的高级参数:
# lr0: 初始学习率 (默认0.01)
lr0=0.01,
# lrf: 最终学习率因子 (默认0.01)
# 学习率会从lr0衰减到lr0*lrf
lrf=0.01,
# momentum: 动量参数 (默认0.937)
momentum=0.937,
# weight_decay: 权重衰减 (默认0.0005)
weight_decay=0.0005,
# warmup_epochs: 热身轮数 (默认3.0)
# 前几轮使用较小的学习率
warmup_epochs=3.0,
# box: 边界框损失权重 (默认7.5)
box=7.5,
# cls: 分类损失权重 (默认0.5)
cls=0.5,
# dfl: DFL损失权重 (默认1.5)
dfl=1.5,
# patience: 早停耐心值 (默认100)
# 如果验证集性能在patience轮内没有提升,则提前停止训练
patience=50,
# save_period: 保存周期 (默认-1)
# 每多少轮保存一次中间模型,-1表示只在最后保存
save_period=10,
# 是否使用数据增强
# 通过翻转、旋转、缩放等方式增加数据多样性
augment=True,
# 是否使用马赛克数据增强
# 将4张图片拼成1张进行训练
mosaic=1.0,
# 是否使用cutout数据增强
# 随机遮挡部分图像
hsv_h=0.015, # 色调增强
hsv_s=0.7, # 饱和度增强
hsv_v=0.4, # 亮度增强
degrees=0.0, # 旋转角度
translate=0.1, # 平移
scale=0.5, # 缩放
shear=0.0, # 剪切
perspective=0.0, # 透视变换
flipud=0.0, # 上下翻转概率
fliplr=0.5, # 左右翻转概率
mixup=0.0, # mixup数据增强概率
)
print("\n 训练完成!")
print(f"最佳模型保存在: {BEST_MODEL_PATH}")
return results
# 验证模型
def validate_model(pt_path=BEST_MODEL_PATH):
"""验证训练好的模型"""
print("\n 验证模型性能...")
# 加载训练好的最佳模型
model = YOLO(pt_path)
# 在验证集上评估模型
metrics = model.val(
data=DATA_YAML_PATH,
split='val', # 使用验证集
imgsz=640,
batch=16,
conf=0.5, # 置信度阈值
iou=0.45, # IoU阈值
device='cuda' if torch.cuda.is_available() else 'cpu'
)
# 打印评估结果
print("\n 模型性能指标:")
print(f" mAP50: {metrics.box.map50:.4f}") # IoU阈值为0.5时的平均精度(标量)
print(f" mAP50-95: {metrics.box.map:.4f}") # IoU阈值从0.5到0.95的平均精度(标量)
print(f" 平均精确率 (mP): {metrics.box.mp:.4f}") # 查准率 (Mean Precision)
print(f" 平均召回率 (mR): {metrics.box.mr:.4f}") # 查全率 (Mean Recall)
return metrics
def train_main():
"""主函数"""
print("1. 创建/校验数据集目录结构")
create_dataset_structure()
print("2. 创建数据集配置文件")
create_data_config()
print("3. 开始训练模型")
train_custom_yolo()
print("4. 验证模型性能")
validate_model()
print("5. 场景测试")
scene_single_image()
print("6. 导出模型")
# export_model()
# 加载场景识别
def scene_single_image(image_path=SCENSE_IMG_PATH, conf_threshold=0.5):
"""
使用训练好的YOLO模型检测单张图片。
参数:
model_path (str): 训练好的模型路径 (例如: 'runs/detect/wzry_yolov8n/weights/best.pt')
image_path (str): 待检测的图片路径
conf_threshold (float): 置信度阈值,高于此值的检测框才会被显示
"""
# 1. 加载训练好的模型
print(f"正在加载模型: {BEST_MODEL_PATH}")
model = YOLO(BEST_MODEL_PATH)
# 2. 读取图片
print(f"正在读取图片: {image_path}")
img = cv.imdecode(np.fromfile(file=image_path, dtype=np.uint8), cv.IMREAD_COLOR)
if img is None:
print(f"错误!无法读取图片,请检查路径: {image_path}")
return
# 3. 进行推理(预测)
print("正在进行推理...")
results = model.predict(
source=img, # 输入源
conf=conf_threshold, # 置信度阈值,可调
save=False, # 设为True会自动保存图片到runs/detect/predict
show=False, # 设为True会弹出显示窗口
verbose=False # 设为True会打印详细结果
)
# 4. 解析并打印检测结果
result = results[0] # 因为只预测了一张图,所以取第一个结果
print(f"\n[INFO] 检测完成!")
print(f" 图片尺寸: {result.orig_shape}")
print(f" 检测到 {len(result.boxes)} 个目标:\n")
# 5. 在图片上绘制结果
result_img = result.plot() # 这个方法会返回一个绘制了所有框和标签的图片(BGR格式)
# 6. 显示和保存结果
cv.namedWindow('Detection Results', cv.WINDOW_NORMAL)
cv.resizeWindow('Detection Results', 1200, 800) # 可调整为你喜欢的大小
cv.imshow('Detection Results', result_img) # result_img已经是BGR格式
print(f"按任意键关闭窗口...")
cv.waitKey(0) # 等待按键
cv.destroyAllWindows() # 关闭所有OpenCV窗口
# 可选:保存结果图片
image_path_split = os.path.split(image_path)
image_name = image_path_split[len(image_path_split) - 1]
image_name_split = image_name.split('.')
output_path = SCENSE_RESULT_PATH + '/' + image_name_split[0] + '_result' + image_name_split[1]
cv.imwrite(output_path, result_img)
print(f"结果图片已保存至: {output_path}")
# 7. (可选)详细列出每个检测到的物体信息
print("\n详细检测信息:")
print("-" * 50)
for i, box in enumerate(result.boxes):
# 获取坐标、置信度、类别ID
xyxy = box.xyxy[0].tolist() # 左上右下坐标 [x1, y1, x2, y2]
conf = box.conf[0].item() # 置信度
cls_id = int(box.cls[0]) # 类别ID
cls_name = result.names[cls_id] # 类别名称
# 计算中心点坐标(相对于原图)
center_x = int((xyxy[0] + xyxy[2]) / 2)
center_y = int((xyxy[1] + xyxy[3]) / 2)
print(f"目标 {i + 1}:")
print(f" 类别: {cls_name} ({cls_id})")
print(f" 置信度: {conf:.4f}")
print(f" 边界框 (像素): [{int(xyxy[0])}, {int(xyxy[1])}, {int(xyxy[2])}, {int(xyxy[3])}]")
print(f" 中心点坐标: ({center_x}, {center_y})")
print("-" * 30)
if __name__ == "__main__":
train_main()
path = "H:\lrc\Pictures\opencv\完整\ScreenShot_2025-12-04_192658_391.png"
path2 = "H:\lrc\Pictures\opencv\scene6.png"
scense_img = path2 # 例如: 'game_dataset/images/val/wzry_001.jpg'
# 3. 置信度阈值: 值越高,只显示越确信的框,漏检可能增加;值越低,显示的框越多,误检也可能增加。
confidence_threshold = 0.55 # 可以尝试调整为0.3, 0.5等
# scene_single_image(scense_img, confidence_threshold)