TIL:基于Markdown与Git的知识管理系统的工程化实践深度解析
1. 整体介绍
1.1 项目概要
TIL(Today I Learned)是一个托管于GitHub的公开个人知识管理仓库。它并非一个具备复杂交互逻辑的软件应用,而是一个通过高度工程化的组织方式,将碎片化技术知识进行系统性沉淀的内容集合 与工作流实践。其核心工程价值在于,将个人非正式学习笔记,通过版本控制工具(Git)和轻量级标记语言(Markdown),构建成一个可持续维护、便于检索、且具备社区价值的静态知识库。根据其README,该项目已持续维护多年,累积了超过1700条学习记录。
1.2 主要功能与价值主张
核心功能 :高效记录、分类、存储与检索碎片化技术知识点。
工程化体现:
- 内容即代码(Content as Code):所有知识条目均以Markdown文件形式存储,享有代码的版本控制、分支管理、变更追溯等所有优势。
- 基于文件系统的分类法:通过目录(Category)和文件(Note)的树形结构实现知识的自解释性分类,无需额外数据库。
- 静态可移植性:整个知识库可被克隆到本地,使用任何文本编辑器或Markdown阅读器查阅,不依赖特定平台或服务。
- 自动化友好:纯文本结构易于被脚本(如Shell、Python)处理,可实现自动生成索引、检查死链、同步发布等。
解决的核心问题:
- 个人层面:解决"知识碎片化"导致的遗忘与查找困难问题。开发者常遇到曾解决过的问题因未记录而重复耗时研究。
- 团队/社区层面:提供了一个低成本的内部知识共享范式。相比复杂的Wiki系统,基于Git的TIL更轻量,协作流程(Pull Request)更贴近开发习惯。
- 场景:适用于日常开发中的技巧记录、调试过程备忘、配置片段保存、阅读源码心得等"小而精"的内容。
1.3 解决方案演进与优势
传统方式:
- 大脑记忆:不可靠,易遗忘。
- 本地文本文件:杂乱无章,难以检索和同步。
- 商业笔记软件(如Evernote, Notion):存在格式锁定、检索功能局限、长期成本或数据迁移风险。
- 博客系统:写作负担重,不适合记录非常琐碎的内容。
TIL方式的优势:
- 极低的结构成本:仅需Git和Markdown知识,无需部署维护后台服务。
- 完整的所有权与控制力:数据完全自主,格式开放。
- 无缝集成开发工作流 :可在终端中快速
git commit & push完成记录。 - 强大的可扩展性:可通过Git Hooks、CI/CD(如GitHub Actions)实现自动化校验与发布。
- 内置的版本历史:可以追溯一个知识点是如何被逐步完善和修正的。
1.4 商业价值与技术成本估算
- 代码/工程成本:极低。核心是内容创作与组织规范,而非软件开发。主要成本是作者的时间投入。
- 覆盖问题空间效益 :
- 对个人:节省大量未来因遗忘而导致的重复搜索和学习时间。假设每条记录平均节省0.5小时,1726条记录潜在节省超过860小时。
- 对团队:可作为内部"实践知识图谱",降低新成员学习曲线和跨团队问题解决成本。其效益随团队规模和使用频率非线性增长。
- 生成逻辑:效益主要来源于对"隐性知识"的"显性化"和"结构化"存储,从而减少信息检索的摩擦成本。这是一个典型的杠杆效应模型------前期较小的记录成本,撬动后期巨大的时间节省。
2. 详细功能拆解(产品+技术视角)
| 产品功能 | 技术实现与设计 |
|---|---|
| 1. 碎片化录入 | 入口分散化:允许从任何工作环境(终端、IDE)快速跳转到笔记目录进行记录。技术上依赖于开发者对终端和文件系统的熟练度。 |
| 2. 结构化分类 | 文件系统即数据库 :/git/, /javascript/ 等目录作为分类。文件名(如 case-insensitive-search.md)作为唯一标识和URL-Slug。这种方式查询效率依赖操作系统文件索引,但对于千级规模的数据量完全足够。 |
| 3. 内容格式化 | Markdown规范:所有笔记遵循一致的Markdown语法。标题(H1)作为笔记主题,代码块(```)用于封装示例,引用链接用于备注来源。这确保了内容可读性和可移植性。 |
| 4. 检索与导航 | 1. 本地检索 :可使用 grep, ripgrep 或 IDE 的全局搜索。 2. 生成索引页:可通过脚本(如Jekyll, Hugo)将目录结构生成为静态HTML索引页,提供Web化浏览界面(本项目未直接提供,但极易实现)。 |
| 5. 持续集成 | Git工作流 :add -> commit -> push。可扩展加入GitHub Actions,在推送后自动校验Markdown格式、生成最新README目录、甚至部署到静态网站。 |
3. 技术难点与核心因子
尽管项目看似简单,但其可持续运营依赖以下被巧妙解决的工程难点:
- 分类体系的可扩展性与一致性(信息架构难点):随着技术栈扩展,如何避免分类膨胀或重叠?本项目采用"发现即创建"的宽松策略,同时依靠后期的内容量来自然验证分类的合理性。难点在于维护一个清晰的心理模型。
- 内容质量与格式的一致性(工程规范难点) :如何确保上千条由同一个人在不同时间撰写的笔记保持风格统一?这依赖于一套隐式的内部编写规范(如标题格式、代码块语言标注、上下文说明),并通过定期回顾来修正偏差。
- 习惯的养成与工作流的低摩擦(行为设计难点):最大的挑战是坚持。本项目通过将记录动作无缝嵌入开发者的Git工作流(与代码提交类似),并采用最轻量的工具(文本编辑器),将摩擦降至最低。
4. 详细设计图
4.1 系统架构图(工作流视角)
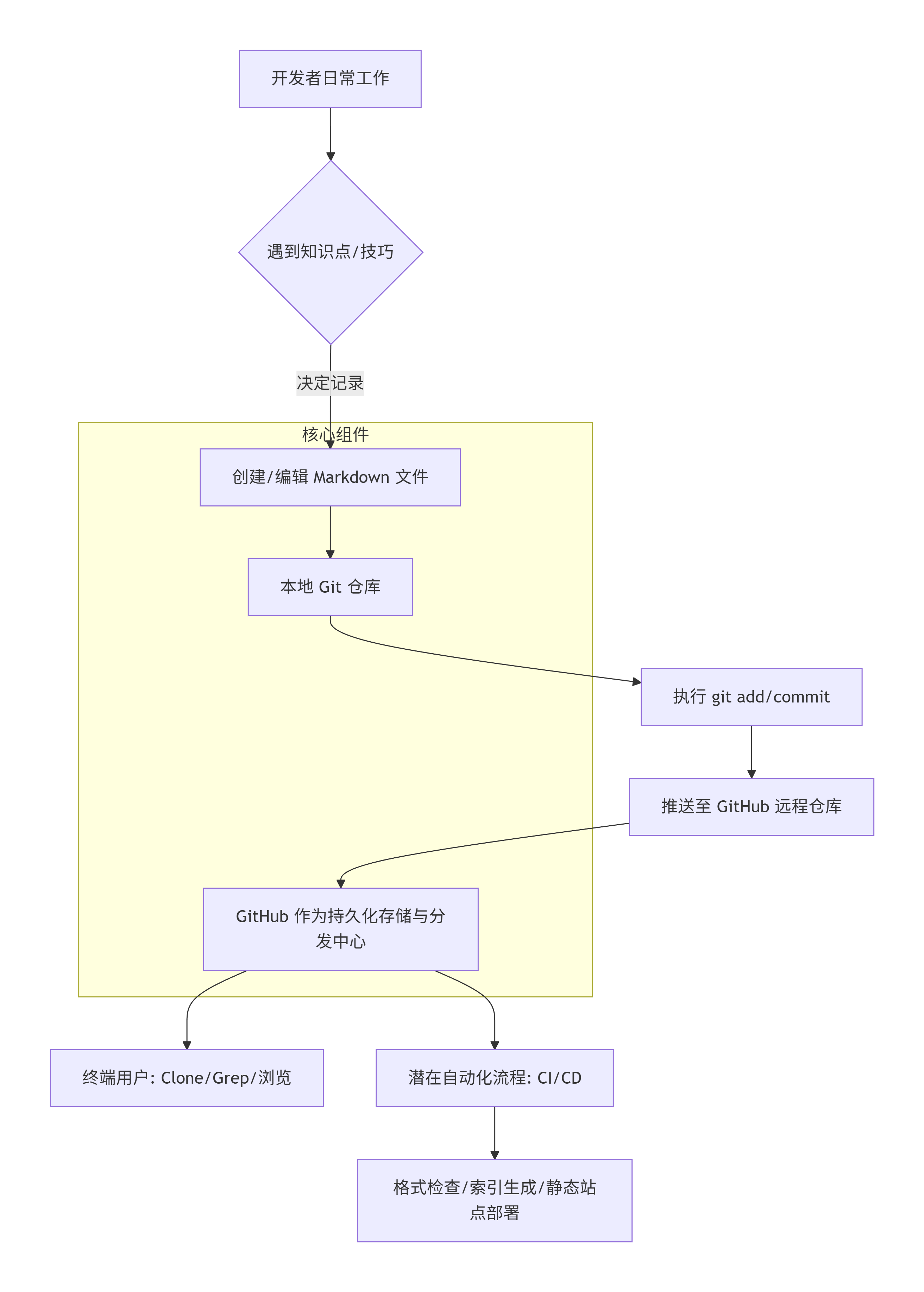
4.2 核心链路序列图(一次记录过程)
GitHub 本地Git 本地文件系统 Developer GitHub 本地Git 本地文件系统 Developer 1. 定位到对应分类目录 (e.g., /git) 2. 创建新文件 case-insensitive-search.md 3. 使用编辑器编写Markdown内容 4. git add . 5. git commit -m "Add git case-insensitive search tip" 6. git push origin main 7. 推送成功,知识持久化
4.3 核心"类"图(内容结构元模型)
虽然项目无面向对象代码,但其内容结构可抽象为以下元模型:
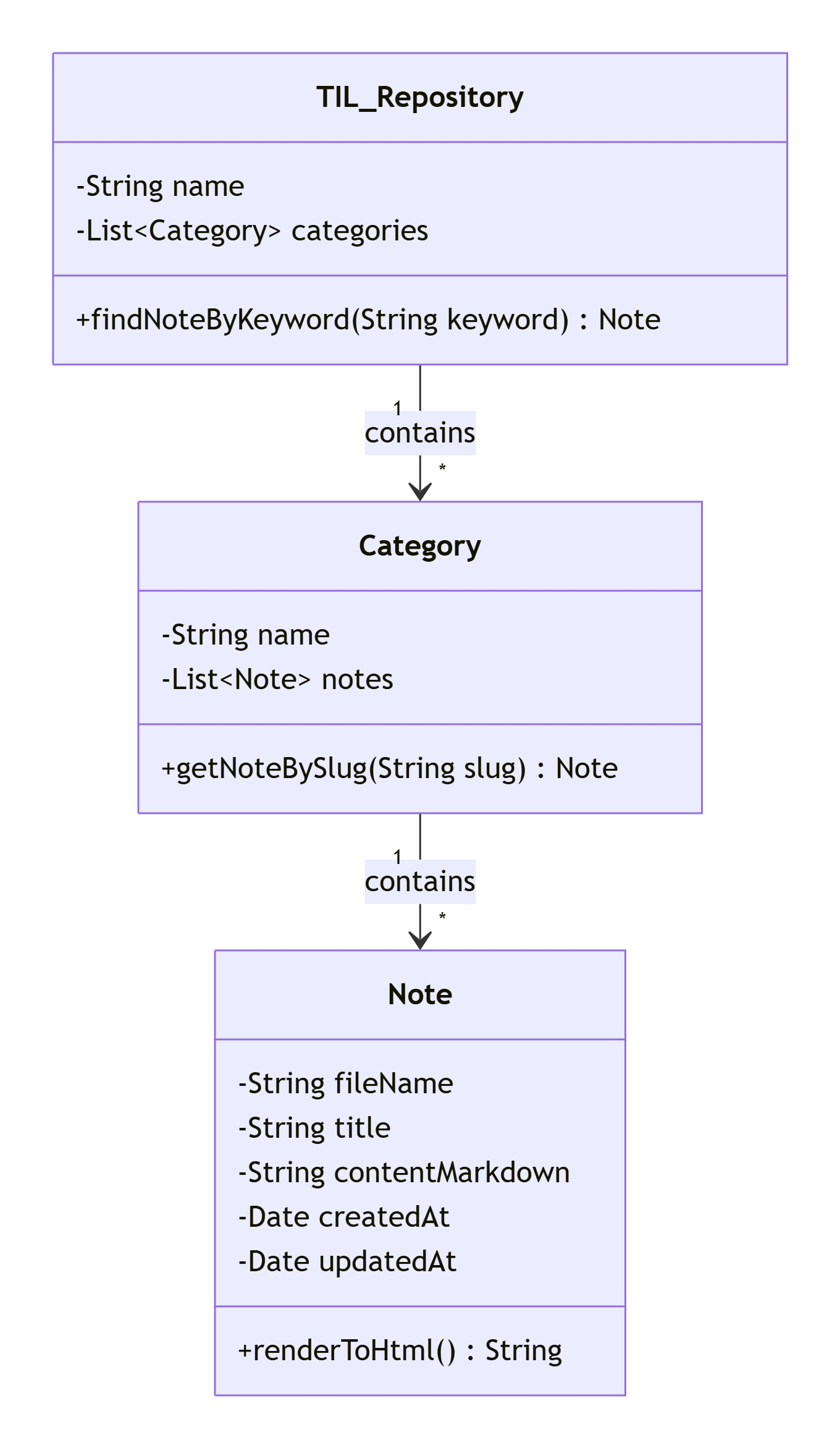
说明:此图描述了项目的逻辑结构,在物理存储上,TIL_Repository对应项目根目录,Category对应子目录,Note对应Markdown文件。
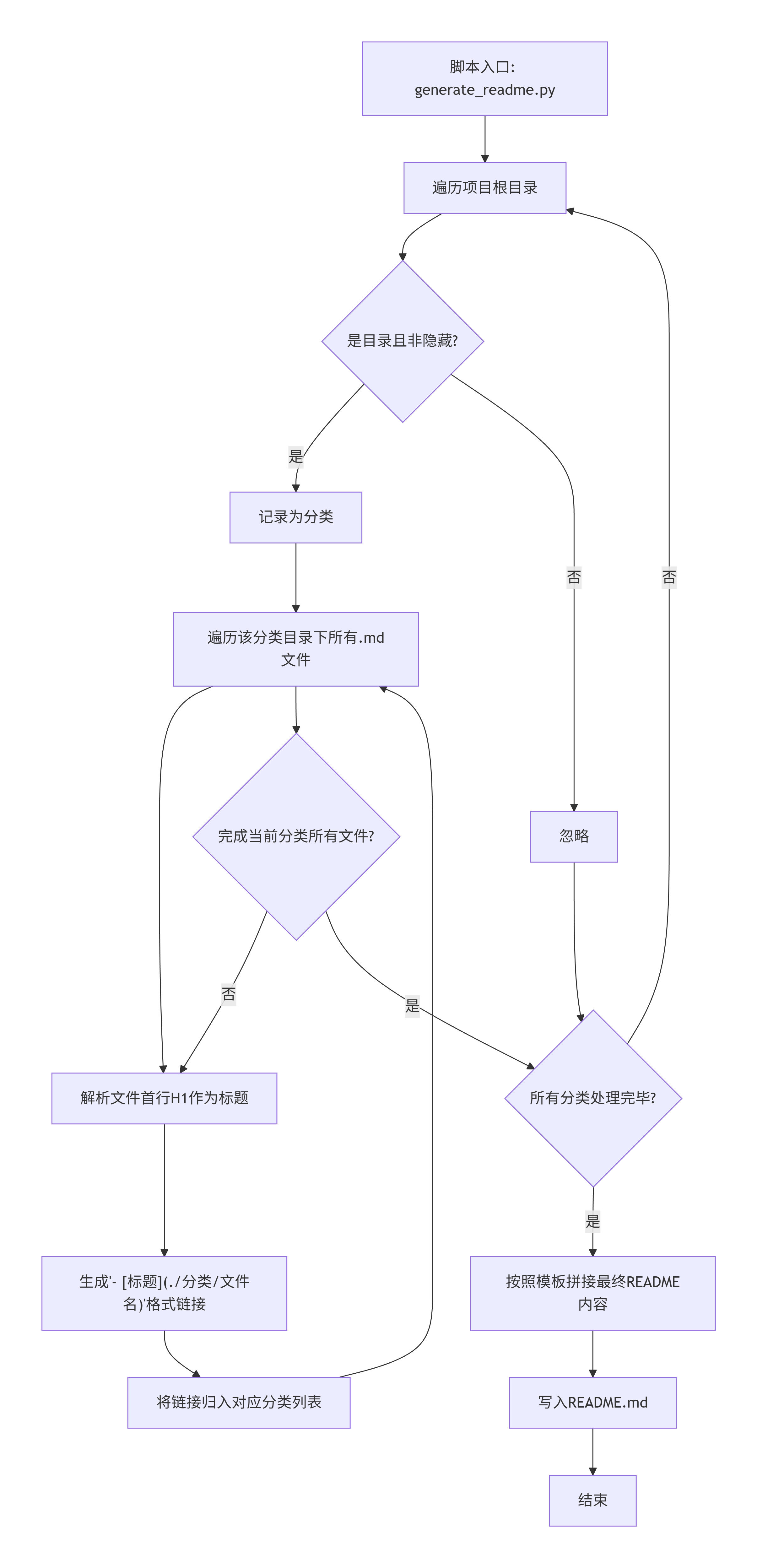
4.4 核心函数/脚本拆解图(以自动化生成为例)
假设我们编写一个Python脚本用于生成汇总的README索引。
5. 核心"代码"解析
5.1 核心"类"------笔记模板(Markdown文件规范)
这是一个典型的TIL笔记结构,是其最核心的"数据模型"。
markdown
# 在Git中进行不区分大小写的搜索
## 上下文
在大型代码库中,有时我们只记得一个函数名的大致样子,但忘记了确切的大小写。
## 解决方案
使用 `git grep` 的 `-i` 标志。
```bash
# 示例:搜索 "username", 会匹配 "userName", "Username" 等。
git grep -i "username"
```
## 补充说明
这个标志同样适用于 `git log -S` 和 `git log -G` 命令,用于在提交历史中搜索代码变更。
## 参考
- Git官方文档:`git grep --help`代码解析:
# 标题:H1标题,清晰定义知识点。作为文件在目录列表中的显示名称。## 上下文:(可选但推荐) 说明遇到该问题的场景,增加知识的可理解性。## 解决方案:核心内容。直接给出命令、代码或步骤。## 补充说明:(可选) 提供边界情况、相关命令或额外技巧,提升笔记深度。## 参考:(可选) 引用官方文档或其他来源,确保知识的准确性和可追溯性。- 代码块:使用反引号明确标注语言(如bash, javascript),保证在渲染时语法高亮,提升可读性。
5.2 核心"函数"------自动化索引生成脚本(Python伪代码示例)
以下脚本模拟了自动生成分类索引的功能,展示了如何以编程方式管理此知识库。
python
#!/usr/bin/env python3
"""
generate_til_index.py
用于生成 TIL 项目的目录索引 README 文件。
"""
import os
import re
from pathlib import Path
def parse_note_title(file_path: Path) -> str:
"""从Markdown文件的第一行解析出H1标题作为笔记标题。"""
with open(file_path, 'r', encoding='utf-8') as f:
first_line = f.readline().strip()
# 匹配以1-6个#开头的Markdown标题,并提取标题文本
match = re.match(r'^#{1,6}\s+(.+)$', first_line)
return match.group(1) if match else file_path.stem
def generate_category_section(category_dir: Path) -> str:
"""为一个分类目录生成Markdown格式的章节内容。"""
notes = list(category_dir.glob('*.md'))
if not notes:
return ""
section_lines = [f"## {category_dir.name}\n"]
for note_file in sorted(notes):
title = parse_note_title(note_file)
# 构建相对链接
link = f"./{category_dir.name}/{note_file.name}"
section_lines.append(f"- [{title}]({link})")
section_lines.append("") # 添加空行分隔
return "\n".join(section_lines)
def main():
repo_root = Path(__file__).parent
readme_content = ["# Today I Learned (TIL)\n"]
# 获取所有非隐藏的目录作为分类
categories = [d for d in repo_root.iterdir() if d.is_dir() and not d.name.startswith('.')]
for category in sorted(categories, key=lambda x: x.name.lower()):
section = generate_category_section(category)
if section:
readme_content.append(section)
# 写入README.md
with open(repo_root / 'README.md', 'w', encoding='utf-8') as f:
f.write("\n".join(readme_content))
print("README index generated successfully.")
if __name__ == "__main__":
main()技术解析:
- 文件遍历 :使用
pathlib.Path进行面向对象的路径操作,比传统os.path更清晰。 - 标题解析 :通过正则表达式
re.match(r'^#{1,6}\s+(.+)$', first_line)精确匹配Markdown标题语法,确保鲁棒性。 - 链接生成 :构建相对于仓库根的Markdown链接
[标题](./分类/文件.md),确保在GitHub上可直接点击跳转。 - 排序:对分类和笔记进行排序,保证生成的索引顺序一致、美观。
总结:同类方案对比与适用性分析
| 方案 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| TIL (Git + Markdown) | 完全自主、零成本、版本化、可自动化、格式纯净、离线可用。 | 无内置Web UI、高级检索需借助外部工具、协作依赖Git知识。 | 开发者个人、技术团队,追求控制力、长期可维护性和与开发流程集成的场景。 |
| Notion / 语雀等专业知识库 | 协作体验好、富文本编辑强大、内置数据库和看板视图、权限管理完善。 | 有锁定风险、数据迁移复杂、长期可能产生费用、离线能力弱。 | 混合角色团队、非技术内容为主,需要强协作和多样化内容组织的场景。 |
| 个人博客 (Hexo, Hugo) | 展示性强、易于传播、SEO友好、社区主题丰富。 | 写作负担重、不适合碎片内容、结构相对固定。 | 体系化知识输出、技术布道、个人品牌建设。 |
| Wiki.js 等自建Wiki | 功能全面、权限精细、搜索强大。 | 需要服务器和维护成本、配置复杂。 | 企业中需要集中化、结构化知识管理,且有专门运维资源的场景。 |
结论 :TIL模式并非要替代其他知识管理工具,而是在技术学习的垂直领域,提供了一个极其简洁、强大且与开发者原生工作流深度契合的"底层方案"。它代表了"内容即代码"和"数字园艺"理念的卓越实践,其工程思想的价值远超过其项目本身的内容积累。对于中高级开发者而言,借鉴其方法论,构建属于自己的自动化知识管理系统,是一项高回报率的技术投资。