影响关系研究常用回归模型进行分析,但是回归模型的种类非常多,不同研究目的、应用等使用的回归方法是各不相同的。对于没有统计学基础或者基础比较薄弱的同学,如何选择合适的回归模型进行自己的研究就成了一个难题。本文以SPSSAU软件为例,总结了64种回归模型并分类整理,帮助大家认识、选择并完成回归分析。
一、64种回归模型汇总
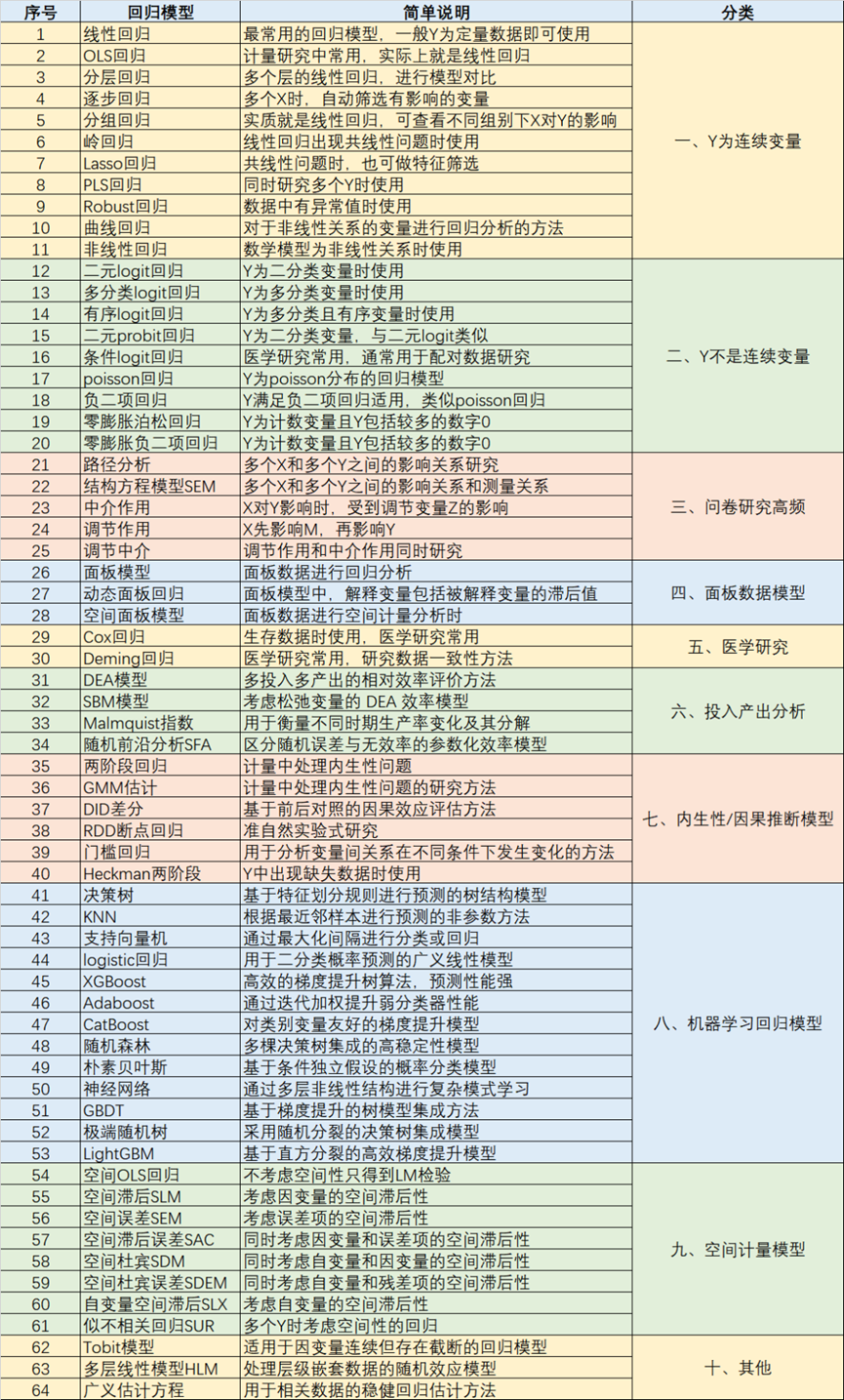
回归模型可用于分析自变量X对因变量Y的作用机制,通过构建模型,不仅能预测Y值,还能揭示各自变量对Y的具体影响程度。SPSSAU平台现提供60多种回归分析方法,简单说明如下:
下面教大家对常用的回归模型进行简单选择。
二、常用回归模型选择
在进行实证分析时,回归模型的选择主要取决于自变量与因变量的数据类型及数量。尽管回归模型多达几十种,但实际研究中高频使用的回归模型还是有限的。常用回归模型初步选择方法如下:

1、Y为定量数据(仅1个)
(1 ) 多元线性回归
当因变量Y为定量数据且只有1个时,一般多元线性回归比较常用。多元线性回归是当前使用最为成熟,研究最多的回归分析方法之一。SPSSAU输出线性回归结果如下:
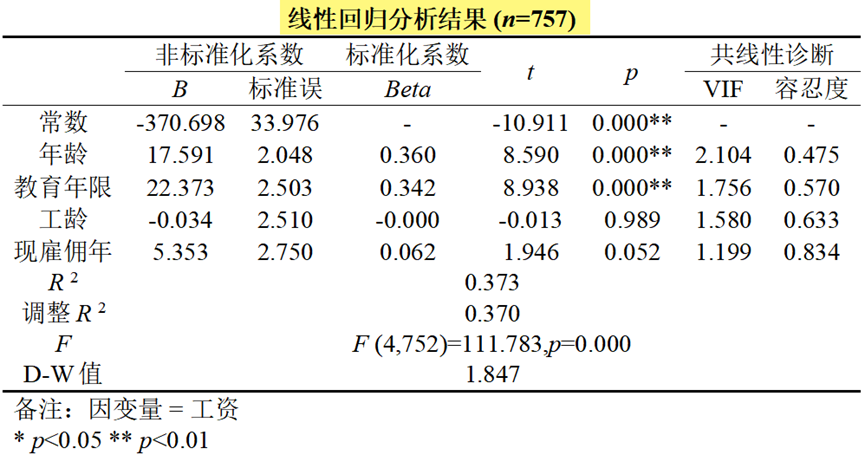
线性回归模型有很多需要满足的前提条件(如线性、独立性、正态性、方差齐、无多重共线性),如果不满足这些假定或者条件可能会导致模型使用出错,那么此时就有对应的其它回归模型出来解决这些问题,因而跟着线性回归后面又出来很多其他回归分析方法。关于多元线性回归模型可查看下方文章:深度解析 | 多元线性回归模型(超详细适用条件检验、软件操作及结果解读)
(2 ) 逐步回归
逐步回归分析分析X对Y的影响关系时,X可以为多个,但并非所有X均会对Y产生影响;当X个数很多时,可以让系统自动识别出有影响的X,这一自动识别分析方法则称为逐步回归分析。逐步回归时共提供3种方式,默认为逐步法,可选为向前法和向后法,一般情况下使用逐步法最多。逐步回归帮助手册
(3 ) 岭回归
岭回归是一种正则化的线性回归方法,特别适用于处理多重共线性问题。它通过在损失函数中添加一个L2惩罚项(即回归系数的平方和乘以一个常数)来减少共线性对参数估计的影响,从而提高模型的稳定性,但可能会牺牲一些模型的解释力。岭回归帮助手册
(4 ) Lasso回归
岭回归是使用L2正则化,Lasso回归是使用L1正则化。相对来讲,岭回归用于解决共线性问题的时候较多,Lasso回归除了有解决共线性问题的功能外,其还可用于进行'特征筛选',即找出有意义的自变量X,一般在机器学习领域使用此功能较多。lasso回归帮助手册
(5 ) Robust回归
是一种对异常值和模型误设定不那么敏感的回归方法。它使用不同的损失函数来减少异常值对回归系数估计的影响,使得模型更加健壮,适用于数据中存在较多异常值的情况。Robust回归帮助手册
分层回归用于处理数据存在层次结构的情况,考虑不同层次的效应。分组回归则是根据某些特征将数据分组,并在每组中进行回归分析。分层回归帮助手册分组回归帮助手册
曲线回归或非线性回归用于建模因变量和自变量之间的非线性关系。这种方法通过使用多项式函数、指数函数、对数函数等非线性函数来更好地拟合数据,从而提供更准确的预测和解释。曲线回归帮助手册非线性回归帮助手册
(8 ) 面板模型
用于分析时间序列数据和横截面数据的组合,考虑时间和个体效应。适用于研究变量随时间变化的影响。面板模型分析帮助手册
2、Y为定量数据(多个)
一般回归模型只包括一个因变量Y,如果研究存在多个因变量Y,可以根据研究选择PLS回归、路径分析或者结构方程模型。
++(1++ ++)++ PLS回归
PLS回归(偏最小二乘回归),是一种可以解决共线性问题、多个因变量Y同时分析、以及处理小样本时影响关系研究的一种多元统计方法。从原理上,PLS回归集合三种研究方法,分别是多元线性回归、典型相关分析和主成分分析,PLS回归是此三种方法的集合运用,多元线性回归用于研究影响关系,典型相关分析用于研究多个X和多个Y之间的关系,主成分分析用于对多个X或者多个Y进行信息浓缩。PLS回归帮助手册
路径分析在于研究模型影响关系,用于对模型假设进行验证。路径分析帮助手册
可用于研究多个潜变量之间的影响关系情况。结构方程模型共包括两部分结构,分别是测量关系和影响关系。结构方程模型帮助手册
3、Y为定类数据
当因变量Y为定类数据时,logistic回归模型比较常用。
++(1++ ++)++ 二元logistic回归
因变量为二分类变量时,比如"买&不买"、"阳性&阴性",选择二元logistic回归分析。还有两种方法,二元probit回归、条件logistic回归,也可针对二分类变量进行回归分析。
因变量为多分类变量时,比如村长候选人"甲、乙、丙",选择多分类logistic回归分析。(3)有序logistic回归
因变量为多分类变量且有序时,比如"不满意、一般、满意",选择有序logistic回归分析。logistic回归分析全流程可查看下方文字:统计小白 | 一文搞懂二元Logistic回归分析全流程
三、应用场景分类
上文已经对Y为定量数据、Y为定类数据时一些常用的模型进行了说明。下面对问卷研究常用、面板数据模型、医学研究和投入产出研究常用的回归模型进行介绍。
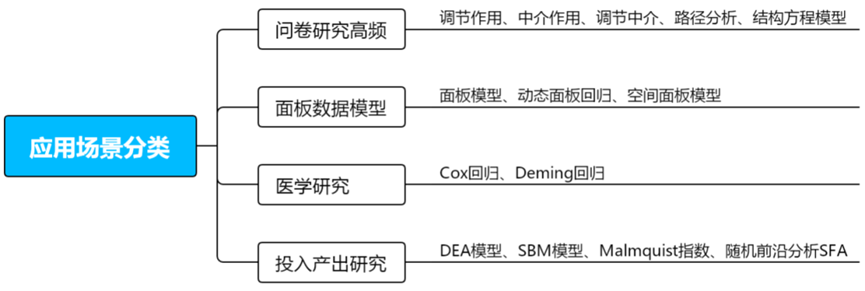
1、问卷研究高频
通过量表问卷收集的数据,常用的回归模型有调节作用、中介作用、调节中介、路径分析、结构方程模型,它们不是严格意义上的回归模型,但是本质也是研究影响关系的模型。
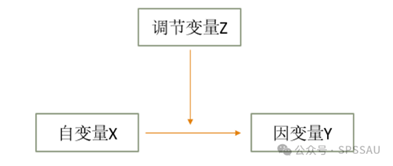
(1 ) 调节作用
调节作用是研究X对Y的影响时,是否会受到调节变量Z的干扰;比如开车速度(X)会对车祸可能性(Y)产生影响,这种影响关系受到是否喝酒(Z)的干扰,即喝酒时的影响幅度,与不喝酒时的影响幅度 是否有着明显的不一样。
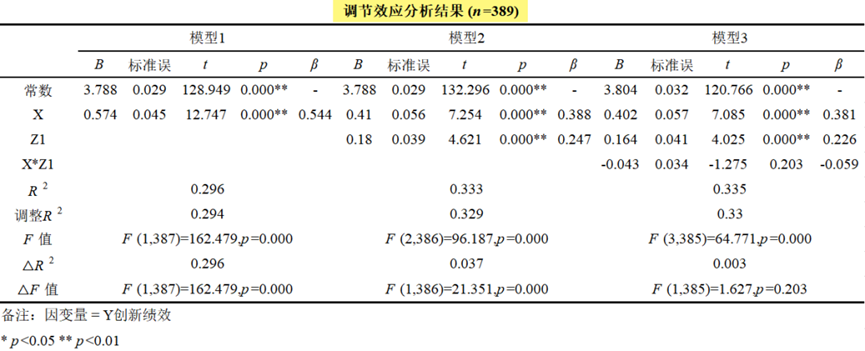
中介作用是研究X对Y的影响时,是否会先通过中介变量M,再去影响Y;即是否有X->M->Y这样的关系;比如工作满意度(X)会影响到创新氛围(M),再影响最终工作绩效(Y)。
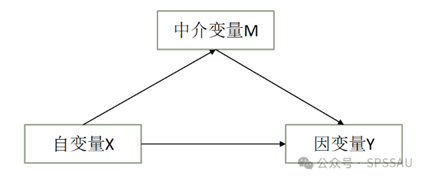
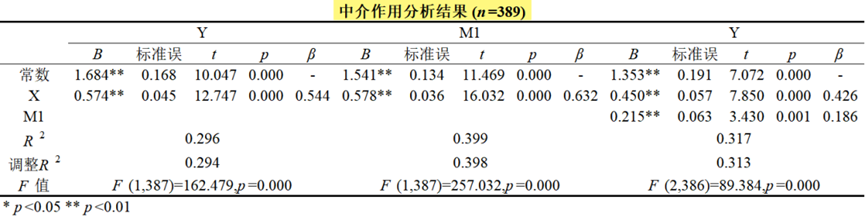
调节中介作用同时考虑中介变量和调节作用,其核心是中介作用,基于中介作用基础上再进一步讨论调节作用。比如X->M->Y这条中介路径存在,即说明具有中介作用。接着在进一步分析条件中介作用,即在另外一个调节变量Z取不同水平时(通常分为3个水平,低水平,平均水平,高水平),中介作用的幅度(也称条件间接效应)情况如何。调节中介帮助手册
(4 ) 路径分析
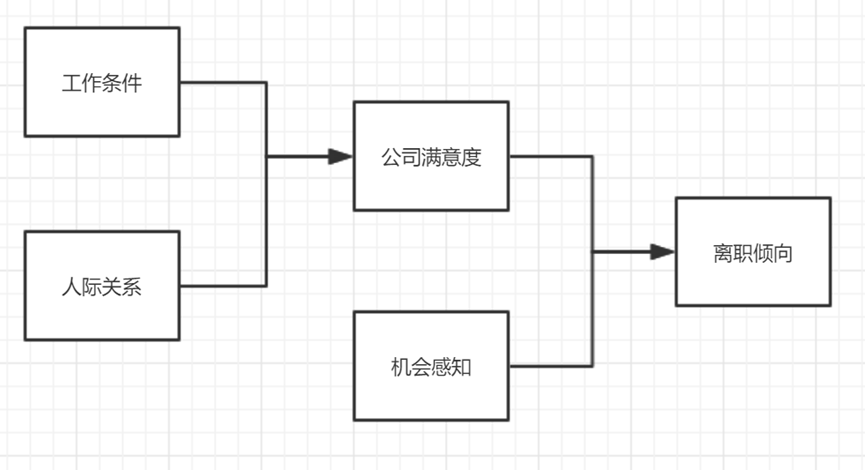
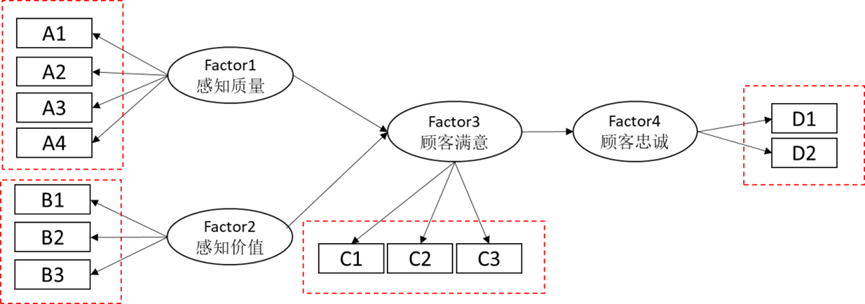
研究模型影响关系,用于对模型假设进行验证。比如下图的模型框架:希望研究工作条件,人际关系对于公司满意度的影响;同时还希望研究公司满意度和机会感知对于离职倾向的影响,路径有一共有4条(即4对影响关系)。
(5 ) 结构方程模型
结构方程模型SEM是一种多元数据分析方法,其可用于研究多个潜变量之间的影响关系情况。结构方程模型共包括两部分结构,分别是测量关系和影响关系(路径分析只有影响关系)。
2、面板数据模型
面板数据分析常用的模型有面板模型、动态面板回归、空间面板模型。
++(1++ ++)++ 面板模型
面板数据进行回归影响关系研究时,即称为面板模型(面板回归)。一般情况下,面板模型可继续分为三种类型,分别是FE模型,POOL模型(就是普通的OLS回归)和RE模型。最终应该选择哪个模型,可通过各个检验进行判断。SPSSAU分别进行F检验,BP检验和Hausman检验(豪斯曼检验),以判断出最终应该使用哪个模型。面板模型分析帮助手册
动态面板数据是处理内生性问题的一种方法,将被解释变量的滞后项作为解释变量纳入模型,并且设置工具变量,进而进行估计,其工具变量的设置较为复杂,但需要尤其注意两个检验,分别是Hansen过度识别检验和扰动项无自相关AR检验。动态面板回归帮助手册
面板数据进行空间计量分析时需要注意几个问题,一是数据格式,空间面板分析时需要为平衡面板数据且其id编号需要与权重矩阵里面的顺序保持一致性;二是空间计量模型的选择,具体应该使用空间面板滞后模型还是空间面板误差模型,应该结合LM检验进行决策;三是面板模型也包括FE固定效应和RE随机效应,具体应该由hausman检验进行判断。空间面板模型帮助手册
3、医学研究
医学领域常用的回归模型有Cox回归、条件logit回归、Deming回归、Possion回归、负二项回归等。
++(1++ ++)++ Cox回归
是一种用于生存分析的统计方法,主要用于研究不同因素对生存时间的影响。它不需要对生存时间的分布做任何假设,能够处理右删失数据,并提供每个自变量对生存风险的影响大小。Cox回归广泛应用于医学研究,用于评估治疗方案或其他因素对患者生存时间的影响。cox回归帮助手册
是一种特殊的线性回归方法,适用于自变量和因变量都存在测量误差的情况。与传统的OLS回归不同,Deming回归考虑了自变量和因变量的误差方差比,常用于比较不同测量方法的准确性或一致性。它在医学、化学、生物学等领域广泛应用于方法比较研究。Deming回归帮助手册
4、投入产出研究
投入产出研究常用的模型有DEA模型、SBM模型、Malmquist指数、随机前沿分析SFA。
++(1++ ++)++ DEA模型
数据包络分析DEA是一种多指标投入和产出评价的研究方法,其应用数学规划模型计算比较决策单元(DMU)之间的相对效率,对评价对象做出评价。DEA模型帮助手册
非期望SBM模型是DEA 衍生模型中的一种。相对传统 DEA 模型,非期望产出 SBM 模型不仅避免径向和角度度量引起的偏差,而且考虑生产过程中非期望产出因素的影响,更能反映效率评价的本质。SBM模型帮助手册
传统的DEA模型可以反映静态的投入产出效率情况,但如果是面板数据,则需要使用malmquist指数进行研究。malmquist指数可以分析从t期到t+1期的效率变化情况。Malmquist指数帮助手册
随机前沿分析(Stochastic Frontier Analysis, SFA)是一种用于测量技术效率的计量经济学方法。其可以用来评估决策单元(如企业、农场等)相对于最佳实践前沿面的技术效率。类似DEA数据包络分析研究投入和产出效率关系,SFA使用统计方式来计算(DEA是使用求解器方式)。随机前沿分析SFA帮助手册
除此之外还有内生性/因果推断模型、机器学习回归模型、空间计量模型等,相对来讲使用比较少,大家如果需要学习,可在SPSSAU查看帮助手册教程。SPSSAU帮助手册
四、回归模型软件操作教程
使用SPSSAU在线数据分析软件进行数据分析非常简单,对没有统计学基础的小白也是十分友好的,只需要三步即可得到分析结果。
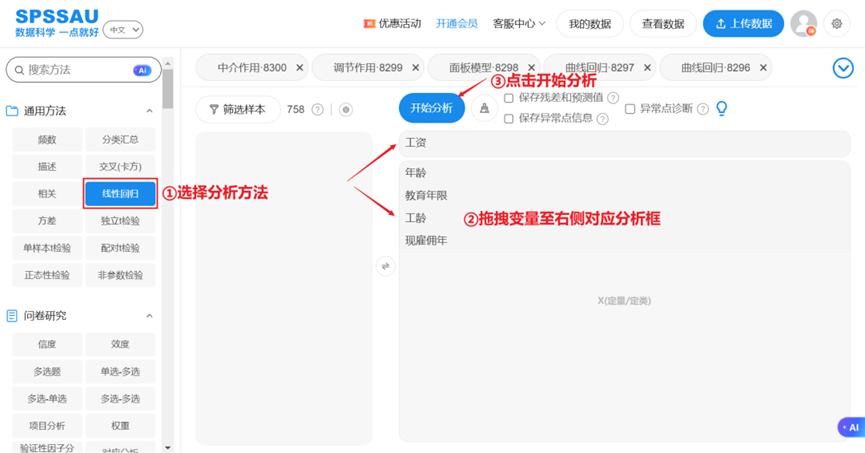
(1 )SPSSAU 软件操作
①上传数据至SPSSAU系统,在分析页面左侧选择分析方法例如【线性回归】;
②拖拽变量至右侧对应分析框中;
③点击开始分析按钮,即可得到分析结果,软件操作如下图:
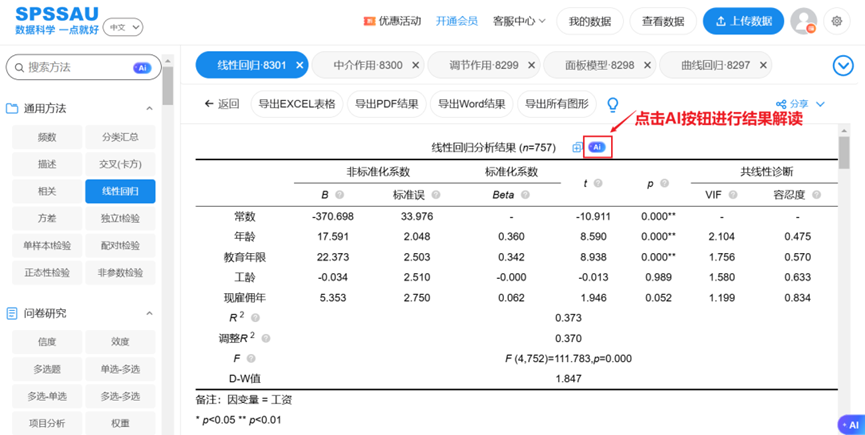
(2 )SPSSAU 输出分析结果
①SPSSAU输出的分析结果都是标准三线表格式,清晰明了,符合科研规范,支持一键导出、复制,无需手动调整格式;
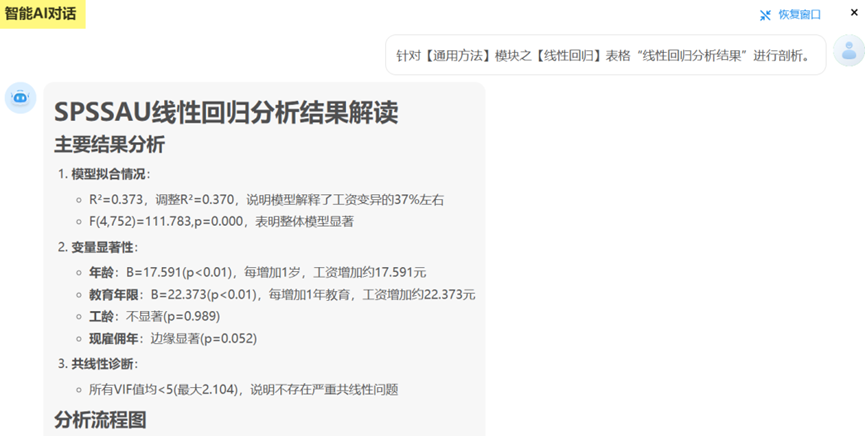
②分析结果表格下方提供"分析建议"与"智能分析",帮助用户理解表格及解读结果;

③SPSSAU内嵌大模型,每个表格提供"AI解读",点击AI按钮即可针对当前数据分析结果进行解读,同时大模型也会给出对应的分析建议。
今天的内容就分享到这里,大家还想看什么欢迎留言~