FlowAct-R1:字节跳动实时交互式人形视频生成框架
一句话总结 :FlowAct-R1 是字节跳动智能创作团队提出的实时交互式人形视频生成框架,首次实现了 25fps、480p、首帧1.5秒 的流式无限时长视频生成,让虚拟人能够像真人一样自然地"说话、倾听、思考、反应"。
📖 论文信息
| 项目 | 内容 |
|---|---|
| 标题 | FlowAct-R1: Towards Interactive Humanoid Video Generation |
| 机构 | ByteDance Intelligent Creation(字节跳动智能创作) |
| 发布日期 | 2026年1月15日 |
| 论文链接 | arXiv:2601.10103 |
| 项目主页 | https://grisoon.github.io/FlowAct-R1/ |
🎯 核心问题:虚拟人如何实现"真正的实时互动"?
想象一下这样的场景:你和一个虚拟主播进行视频通话,她能实时听你说话、做出表情反应、自然地接话,整个过程流畅得就像和真人聊天一样。这听起来像是科幻电影中的场景,但 FlowAct-R1 正在让它成为现实。
现有方法面临的三大挑战
| 挑战 | 问题描述 | 生活化比喻 |
|---|---|---|
| 实时性瓶颈 | 现有方法要么只能生成固定长度视频,要么延迟太高无法实时 | 就像录播节目 vs 直播的区别 |
| 长时一致性崩塌 | 长时间生成后,人物外观、动作会逐渐"走形" | 像玩传话游戏,传到最后面目全非 |
| 行为单调僵硬 | 虚拟人只会机械地对口型,缺乏自然的表情和肢体语言 | 像提线木偶,看起来很假 |

图1:FlowAct-R1 系统能力展示。仅需一张参考图像,系统就能生成具有丰富行为状态(说话、倾听、思考、反应、空闲、手势)的实时视频流。支持多模态控制(音频、文本),实现25fps、首帧1.5秒的流式无限时长生成。
🏗️ 技术核心:像"流水线工厂"一样生成视频
要理解 FlowAct-R1 的工作原理,我们可以把它想象成一个视频生产流水线。
核心挑战:为什么视频生成这么难?
传统的视频生成方法就像"一次性写完一篇作文"------先构思好全部内容,再一口气写完。这种方式有两个致命问题:
- 等待时间太长:用户说一句话,要等好几秒甚至几十秒才能看到虚拟人的反应
- 长度受限:模型只能处理固定长度的视频,无法进行"无限时长"的对话
FlowAct-R1 的解决方案是:边生产边输出,就像直播一样。
整体架构:四个核心模块
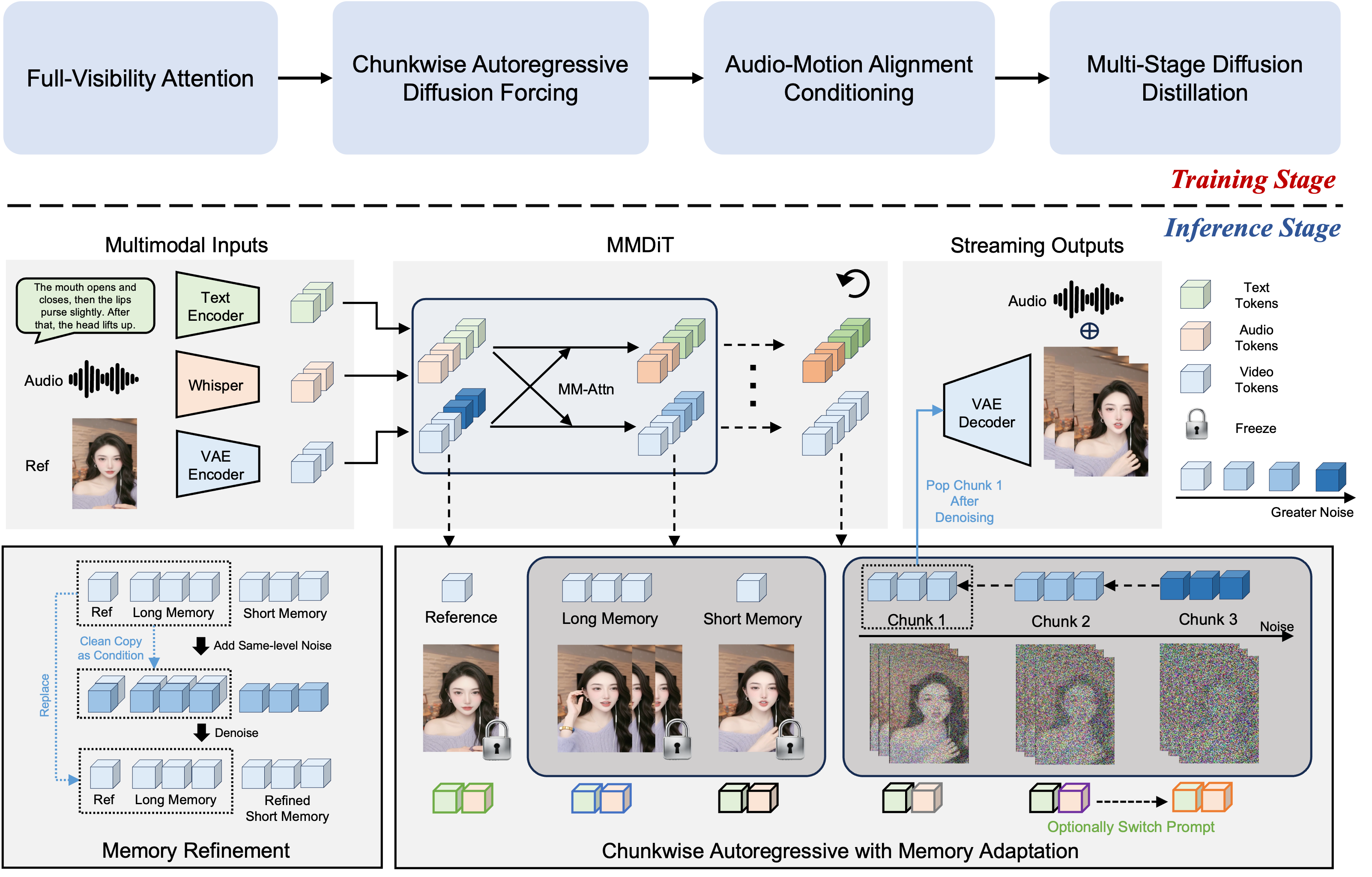
图2:FlowAct-R1 框架架构图。上半部分为训练阶段的三个关键组件:分块自回归适应、音频-动作对齐训练、多阶段蒸馏;下半部分为推理阶段的流式缓冲机制和记忆优化策略。
🎬 关键技术一:流式缓冲区------视频生成的"传送带"
类比理解:汽车生产流水线
想象一条汽车生产流水线:
- 不需要等所有零件都准备好才开始组装
- 每个工位只负责自己那部分工作
- 上游工位完成的半成品不断传递给下游
FlowAct-R1 的"流式缓冲区"就是这样的设计:
┌─────────────────────────────────────────────────────────────────┐
│ 流式缓冲区(Streaming Buffer) │
├─────────┬───────────────┬───────────────┬─────────────────────────┤
│ 身份证 │ 长期记忆 │ 短期记忆 │ 生产线(去噪流) │
│ (1帧) │ (最多3个视频块) │ (刚完成的块) │ (正在生产的3个视频块) │
├─────────┼───────────────┼───────────────┼─────────────────────────┤
│ "我长 │ "10秒前我在 │ "刚才我在 │ "现在正在做的动作..." │
│ 什么样" │ 做什么动作" │ 做什么动作" │ │
└─────────┴───────────────┴───────────────┴─────────────────────────┘
↑ ↓
保持身份不变 提供上下文参考四个组件的具体作用
| 组件 | 存储内容 | 作用 | 生活化比喻 |
|---|---|---|---|
| 参考潜在 | 1张参考图像 | 锚定"这个人长什么样" | 身份证照片,确保不会"换脸" |
| 长期记忆 | 最多3个早期视频块 | 记住较早的动作状态 | 像"上一集回顾",防止剧情矛盾 |
| 短期记忆 | 最近完成的视频块 | 保证动作连贯 | 像写字时看刚写的那几个字 |
| 去噪流 | 3×3=9帧正在生成 | 当前正在处理的内容 | 像画家笔下正在画的部分 |
工作流程:每0.5秒循环一次
时间轴:
t=0s t=0.5s t=1.0s t=1.5s t=2.0s
│ │ │ │ │
▼ ▼ ▼ ▼ ▼
[生成块1] [生成块2] [生成块3] [生成块4] [生成块5]
↓ ↓ ↓ ↓
输出 输出 输出 输出
每个"块"包含0.5秒的视频(约12帧)
首帧延迟约1.5秒(需要预热3个块)这种设计保证了:
- 低延迟:首帧只需等待约1.5秒
- 无限时长:理论上可以一直生成下去
- 25fps输出:每0.5秒输出12帧,刚好是25fps
🔄 关键技术二:Self-Forcing++ ------解决"越生成越崩"的问题
问题根源:训练与推理的"两张皮"
这是自回归生成模型的经典难题:
训练时: 推理时:
┌────────┐ ┌────────┐
│ 真实帧 │ → 作为条件 → 生成下一帧 │ 生成帧 │ → 作为条件 → 生成下一帧
└────────┘ └────────┘
完美的输入 有误差的输入
↓ ↓
模型从没见过"有误差的输入" 误差不断累积,最终崩塌!生活化比喻:这就像一个学生,平时做作业只看标准印刷体的题目,考试时突然遇到老师的手写字迹,就完全不会了。
FlowAct-R1 的解法:训练时就"故意制造不完美"
核心思想:既然推理时会遇到"有误差的帧",那训练时就让模型提前适应。
Self-Forcing++ 训练流程:
步骤1:用中间模型对真实帧加噪
┌──────────┐ 加噪 ┌──────────┐
│ 真实视频 │ ──────────→ │ 带噪视频 │
└──────────┘ └──────────┘
步骤2:再去噪得到"伪生成帧"(有轻微瑕疵)
┌──────────┐ 去噪 ┌──────────┐
│ 带噪视频 │ ──────────→ │ 伪生成帧 │
└──────────┘ └──────────┘
↓
质量略低于真实帧,但接近推理时的情况
步骤3:随机混合真实帧和伪生成帧作为训练输入
┌───────────────────────────────────────┐
│ 帧1(真实) + 帧2(伪) + 帧3(真实) + ... │
└───────────────────────────────────────┘
↓
让模型适应"不完美"的输入条件与原始 Self-Forcing 的区别
| 特性 | 原始 Self-Forcing | Self-Forcing++ |
|---|---|---|
| 实现方式 | 完全展开自回归,用生成的帧训练 | 随机混合真实帧和伪生成帧 |
| 计算成本 | 很高(需要完整展开) | 较低(只需局部替换) |
| 伪帧来源 | 当前模型生成 | 中间版本模型生成 |
| 稳定性 | 训练不稳定 | 更稳定,效果更好 |
为什么用"中间模型"而非"当前模型"?
- 用当前模型生成伪帧会导致训练不稳定(自我循环)
- 中间模型质量适中,既不完美也不太差,刚好模拟推理时的情况
👁️ 关键技术三:伪因果注意力------让模型"看得准"
问题:注意力计算开销太大
在 Transformer 架构中,每个 token 都要和所有其他 token 计算注意力,计算量是 O(n²)。对于视频生成来说,token 数量巨大,直接算会爆显存。
解决方案:设计巧妙的注意力掩码
FlowAct-R1 的核心洞察:不是所有信息都需要双向关注。
注意力矩阵(✓表示可以看到,✗表示看不到):
参考 长期记忆 短期记忆 去噪流
┌────────────────────────────────┐
参考 │ ✓ ✓ ✓ ✗ │ ← 参考帧不需要看正在生成的内容
长期记忆 │ ✓ ✓ ✓ ✗ │ ← 历史帧也不需要
短期记忆 │ ✓ ✓ ✓ ✗ │ ← 同上
去噪流 │ ✓ ✓ ✓ ✓ │ ← 但正在生成的内容需要参考所有历史
└────────────────────────────────┘生活化比喻:
- 写作文时,你需要不断回顾已经写好的段落(去噪流看记忆)
- 但已经写好的段落不会因为你后面写了什么而改变(记忆不看去噪流)
好处
- 计算量减少:记忆部分的注意力计算大幅简化
- 稳定性提升:已去噪的信息不会被未完成的内容"污染"
- 信息流向清晰:历史→当前的单向流动,符合时序逻辑
🎵 关键技术四:多模态融合------让虚拟人"听懂"并"反应"
三种输入信号的处理
输入信号融合流程:
┌─────────────┐ Whisper编码 ┌─────────────┐
│ 音频(16kHz) │ ───────────────→ │ 声学token │──┐
└─────────────┘ └─────────────┘ │
│
┌─────────────┐ 文本编码器 ┌─────────────┐ │ 交叉注意力
│ 文本提示 │ ───────────────→ │ 语义token │──┼───────────→ MMDiT
└─────────────┘ └─────────────┘ │
│
┌─────────────┐ VAE编码 ┌─────────────┐ │
│ 参考图像 │ ───────────────→ │ 视觉token │──┘
└─────────────┘ └─────────────┘各信号的作用
| 输入类型 | 处理方式 | 控制内容 |
|---|---|---|
| 音频 | Whisper → 25 token/秒 | 唇形同步、说话节奏、语气表情 |
| 文本提示 | 密集行为注释 | 整体动作状态(说话/倾听/思考/空闲) |
| 参考图像 | VAE 压缩 | 身份特征、衣着、背景 |
MLLM 动作规划:让行为更自然
最关键的创新是引入**多模态大语言模型(MLLM)**来规划动作:
MLLM 动作规划流程:
输入:
- 最近的音频片段(用户说了什么)
- 当前的参考图像(虚拟人长什么样)
- 对话历史(之前聊了什么)
↓ MLLM 推理
输出:
- 下一个行为状态的文本描述
例如:"用户问了一个问题,应该先做思考状,皱眉、微微抬头,
然后缓缓点头,开始回答时嘴角带笑"
↓ 转换为文本提示
MMDiT 据此生成对应的视频帧为什么这样更自然?
- 传统方法只做"唇形同步",表情和动作很机械
- MLLM 能理解语义,知道什么时候该"思考"、什么时候该"惊讶"
- 实现了"说话→思考→倾听→反应"的自然状态切换
⚡ 关键技术五:三阶段蒸馏------从"慢工细活"到"流水线作业"
问题:扩散模型太慢
原始的扩散模型需要几十步去噪才能生成高质量图像/视频,这对于实时应用来说太慢了。
解决方案:三阶段渐进蒸馏
蒸馏流程(实现8倍加速):
原始模型:~24步去噪
│
▼ 阶段1:CFG消除
│
│ 原来:每步需要算2次(有引导+无引导)
│ 现在:训练一个统一模型,只需算1次
│
▼ 阶段2:步数压缩
│
│ 将24步分成3段,每段8步
│ 每段的8步蒸馏为1步
│ 24步 → 3步
│
▼ 阶段3:质量优化(DMD)
│
│ 用分布匹配蒸馏进一步优化3步模型
│ 确保质量不下降
│
最终模型:3步去噪(3 NFEs)系统级优化:榨干硬件性能
| 优化技术 | 原理 | 效果 |
|---|---|---|
| FP8量化 | 将权重从FP16降为FP8 | 显存减半,计算加速 |
| 帧级混合并行 | 不同帧分配到不同GPU | 减少GPU间通信 |
| 算子融合 | 多个小操作合并为一个kernel | 减少调度开销 |
| 异步流水线 | DiT和VAE并行执行 | 隐藏延迟 |
🔧 关键技术六:记忆细化------给"记忆"做"体检和修复"
问题:长时间运行后"记忆"会积累杂质
就像复印机复印复印件,每次都会损失一点质量,长期累积会导致画面出现伪影。
解决方案:定期"清洗"记忆
记忆细化策略:
正常运行:
帧1 → 帧2 → 帧3 → ... → 帧100 → 帧101 → ...
↑
伪影开始累积
触发细化(例如每50帧一次):
│
┌─────────▼─────────┐
│ 1. 对短期记忆加噪 │
│ 2. 用参考+长期记忆 │
│ 作为指导去噪 │
│ 3. 得到"修复"的帧 │
└─────────┬─────────┘
│
▼
继续生成...生活化比喻:
- 像定期校准罗盘:航行途中不断用北极星修正方向
- 像定期重启电脑:清除累积的"内存垃圾"
📊 实验结果:全方位领先
与竞争对手的对比
| 方法 | 流式 | 实时 | 全身控制 | 泛化 | 生动性 | 最长时长 |
|---|---|---|---|---|---|---|
| FlowAct-R1 | ✓ | ✓ | ✓ | ✓ | ✓ | 无限 |
| KlingAvatar 2.0 | ✗ | ✗ | ✓ | ✓ | ✓ | 5分钟 |
| LiveAvatar | ✓ | ✓ | ✓ | ✓ | ✗ | 无限 |
| OmniHuman-1.5 | ✗ | ✗ | ✓ | ✓ | ✓ | 30秒 |
用户研究结果
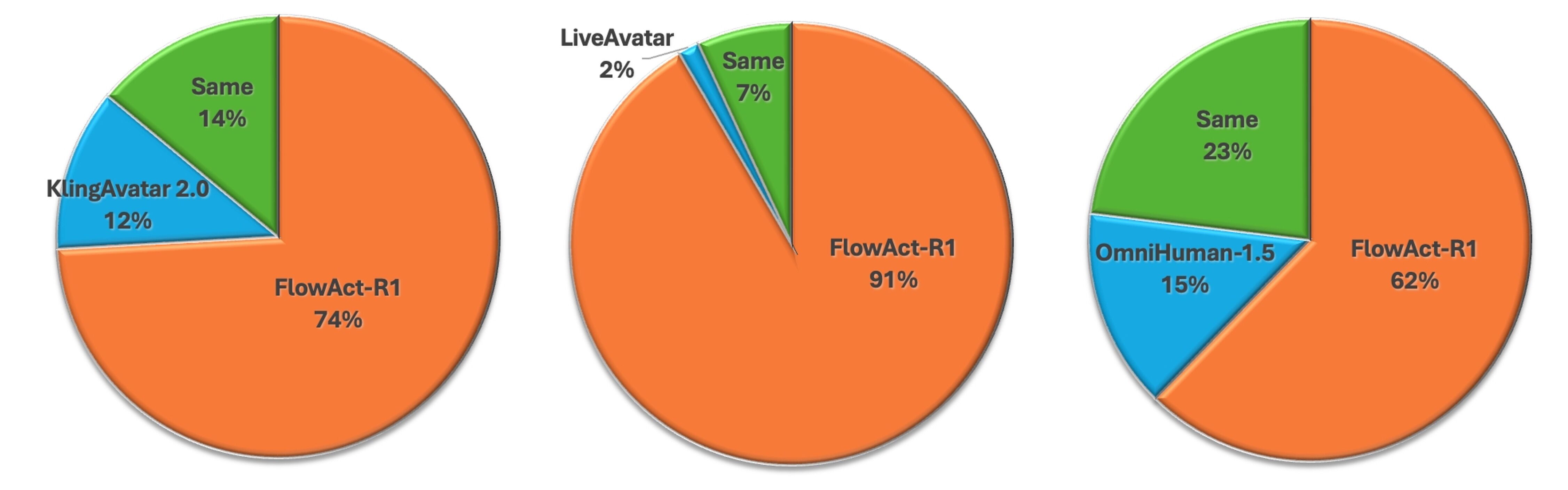
图3:用户偏好研究结果(GSB指标)。FlowAct-R1 在与 LiveAvatar(91%)、KlingAvatar 2.0(62%)、OmniHuman-1.5(74%)的对比中均获得显著优势。
关键性能指标
| 指标 | 数值 | 意义 |
|---|---|---|
| 帧率 | 25 fps | 人眼感知流畅的阈值 |
| 分辨率 | 480p | 视频通话的主流分辨率 |
| 首帧延迟 | ~1.5秒 | 接近人类反应时间 |
| 去噪步数 | 3 NFEs | 比常规方法快8倍 |
| 生成时长 | 无限 | 突破固定长度限制 |
💡 设计哲学总结:为什么 FlowAct-R1 能成功?
核心洞见
FlowAct-R1 的成功源于一个核心设计哲学:
训练时模拟推理的"不完美",推理时用记忆维护"一致性"
这体现在三个层面:
| 层面 | 挑战 | FlowAct-R1 的解法 |
|---|---|---|
| 训练-推理一致性 | 训练用真实帧,推理用生成帧 | Self-Forcing++:训练时混入伪生成帧 |
| 长期时序一致性 | 越生成越"走样" | 记忆细化:定期"校准"短期记忆 |
| 行为自然度 | 动作机械、状态切换生硬 | MLLM规划:用大模型理解语义,规划行为 |
架构设计的取舍
FlowAct-R1 的设计选择
质量 ←──────────────────┬──────────────────→ 速度
│
┌───────────────┼───────────────┐
│ │ │
选择480p分辨率 3步蒸馏 流式分块生成
(够用即可) (质量换速度) (边生成边输出)
│ │ │
└───────────────┴───────────────┘
│
适合实时交互场景🚀 应用场景与展望
四大应用场景
| 场景 | 具体应用 | 关键需求 |
|---|---|---|
| 虚拟直播 | 24小时AI主播、虚拟偶像 | 无限时长、实时互动 |
| 视频会议 | 虚拟形象出镜、隐私保护 | 低延迟、自然表情 |
| 数字人客服 | 智能客服、导购助手 | 情感反馈、多轮对话 |
| 游戏/元宇宙 | 智能NPC、虚拟社交 | 实时响应、个性化 |
当前局限与未来方向
| 局限 | 可能的改进方向 |
|---|---|
| 分辨率仅480p | 更高效的蒸馏方法、硬件升级 |
| 单人场景 | 多人交互建模、场景理解 |
| 需要强GPU | 端侧部署、模型压缩 |
| 潜在滥用风险 | 水印技术、检测模型 |
📝 总结
FlowAct-R1 代表了交互式人形视频生成领域的重要突破:
| 核心贡献 | 技术创新 | 实际意义 |
|---|---|---|
| 实时流式生成 | 流式缓冲区 + 分块去噪 | 首帧1.5秒,无限时长 |
| 长期一致性 | Self-Forcing++ + 记忆细化 | 长时间生成不崩塌 |
| 自然行为 | MLLM动作规划 | 说、听、思、应自然切换 |
| 极致效率 | 三阶段蒸馏 + 系统优化 | 3步推理,25fps输出 |
这项工作的意义不仅在于技术突破本身,更在于它展示了一种解决"训练-推理分布偏移"问题的通用思路------这种思路对其他需要长时序自回归生成的任务(如长文本生成、音乐生成、机器人规划)同样具有借鉴价值。