在"数字法治"国家战略的宏大背景下,司法体系正经历一场从"信息化"向"智能化"的深刻变革。面对日益严峻的"案多人少"结构性矛盾,传统依赖人力的审判模式已触及效率瓶颈。如何利用前沿技术为法官减负、为司法增效、为正义提速,成为时代赋予我们的核心命题。
本文将深度剖析《智慧法院法律大模型辅助办案与文书生成系统建设方案》这一重量级文档,为您全面拆解一个融合了大语言模型(LLM)、知识图谱(KG)、检索增强生成(RAG)等尖端技术的"法治大脑"是如何被设计、构建并最终赋能司法全流程的。这不仅是一份技术蓝图,更是一场关于未来司法形态的深度思考。
一、破局之问:为何需要智慧法院?直面司法体系的三大核心痛点
任何伟大的技术革新,都源于对现实痛点的深刻洞察。本方案开篇即以数据为矛,精准刺中了当前审判业务运行中的三大核心痛点,为整个项目的必要性奠定了坚实基础。
1.1 案件负荷:持续增长的"堰塞湖"
数据显示,某级法院年均结案数持续以约15%的增幅攀升。这意味着,法官们不仅要应对存量案件的审理压力,还要不断承接新增案件的冲击。这种"案多人少"的结构性矛盾,如同一个不断蓄水的堰塞湖,随时可能因资源供给不足而引发系统性风险。传统的"人海战术"和加班加点已无法从根本上解决问题,亟需通过技术手段提升司法生产力的"天花板"。
1.2 阅卷效率:淹没在卷宗海洋中的关键事实
法官作为案件的"事实发现者",其核心工作之一是阅卷。然而,现状是法官日均阅卷时长超过4小时,且大量卷宗仍处于非结构化的扫描件状态。这意味着,法官需要耗费大量时间在"看图"而非"读意"上,从海量文字、图片、表格中手动摘录、比对、梳理证据。这种低效的阅卷模式,不仅延长了审理周期,更增加了因疏漏而错失关键事实的风险。
1.3 文书制作:重复性劳动挤占核心审判思维
一份高质量的裁判文书,是司法智慧的结晶。但在现实中,法律文书初稿的撰写占据了法官约40%的工作时间。大量的时间被耗费在格式调整、当事人信息录入、法条引用、判项标准化等高度重复、机械性的事务上。这直接导致法官用于复杂法律关系论证、价值判断和自由心证等核心审判思维的时间被严重挤占。
总结来看,当前司法体系的核心矛盾在于:法官的宝贵智力资源被大量低价值、高耗时的事务性工作所捆绑,无法聚焦于最能体现其专业价值的法律适用与裁判说理环节。 因此,构建一个能够深度嵌入办案流程、智能处理事务性工作、精准辅助决策的"AI助手",已不再是锦上添花,而是雪中送炭的必然选择。
二、顶层设计:构建"智审、智管、智服"三位一体的智慧支撑体系
面对上述痛点,本方案提出了清晰、量化、可衡量的建设目标,旨在通过AI技术实现从"工具辅助"到"决策辅助"的战略跨越。其核心目标可概括为"智审、智管、智服"三个维度。
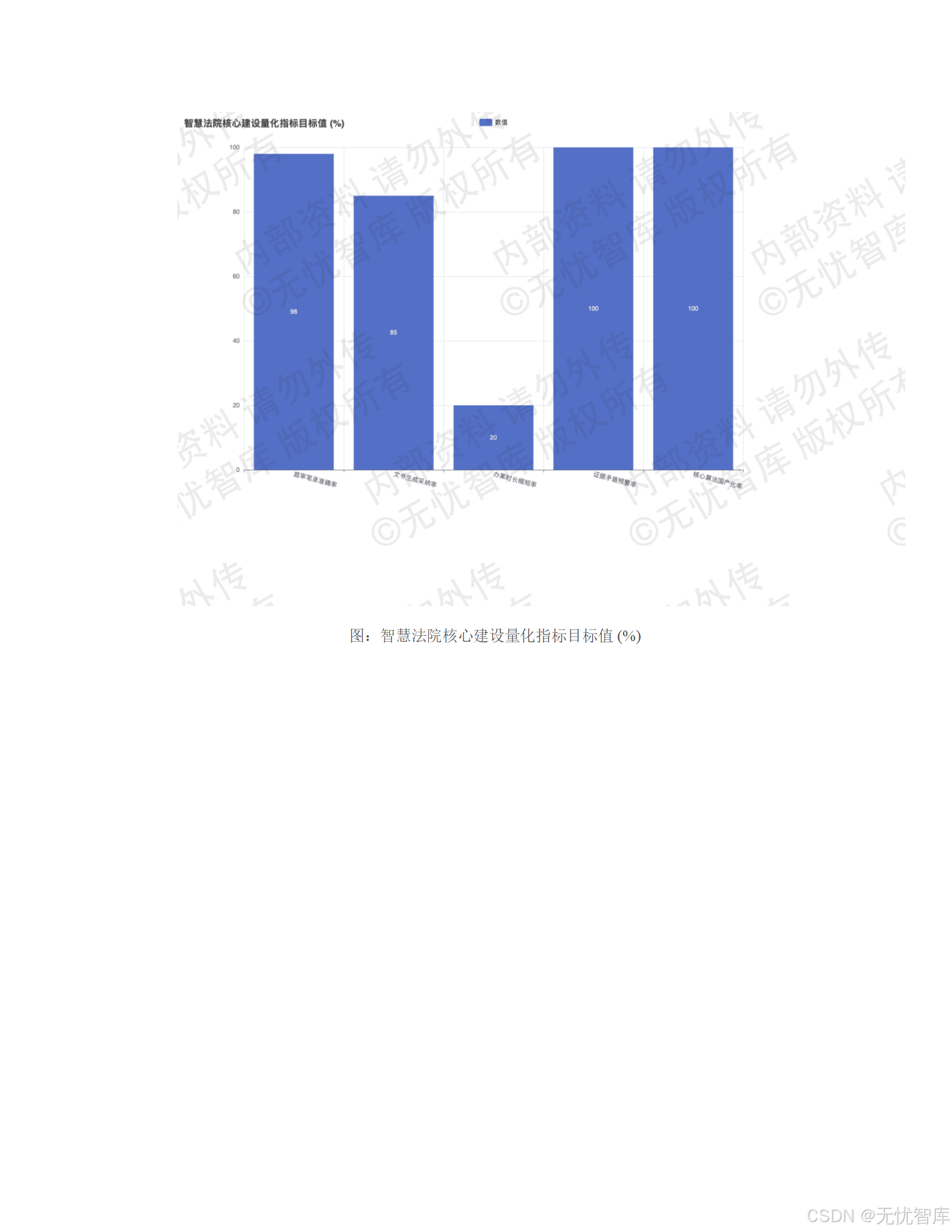
2.1 业务效能目标:为法官减负,为司法提速
这是最直接、最迫切的目标。方案设定了三项硬核量化指标:
- 庭审笔录实时生成准确率 ≥ 98%:利用语音识别与语义解析技术,将书记员从繁重的记录工作中解放出来,确保庭审过程的完整、高效还原。
- 简易案件文书自动生成采纳率 ≥ 85%:针对事实清楚、法律关系简单的案件,AI能自动生成符合规范的文书初稿,法官只需进行审核与微调,大幅提升文书制作效率。
- 法官单案平均办理时长缩短20%:通过智能排期、要素式审判及自动化事务处理,系统性地压缩案件流转周期,让正义来得更快。
2.2 司法公正目标:用技术筑牢公平正义的底线
AI不仅是效率工具,更是公正的守护者。方案强调通过技术手段强化司法公正保障:
- 构建"类案同判"精准推送机制:利用深度语义匹配技术,为法官推送高度相似的指导性案例和历史判例,有效降低量刑偏差,确保"同案同判",维护法律适用的统一性和权威性。
- 建立证据链自动校验模型:对卷宗事实进行逻辑闭环核查,实时预警证据间的矛盾点(如时间冲突、空间冲突),最大限度减少事实认定错漏,从源头上防范冤假错案。
2.3 系统建设目标:打造自主可控、安全可靠的司法AI底座
在追求效能与公正的同时,方案将安全与自主可控置于最高优先级:
- 构建自主可控的法律行业大模型底座:确保司法数据主权安全,避免核心技术受制于人。
- 沉淀千万级高质量司法文书数据集:通过对海量司法数据的要素化解析,形成具备深度司法语义理解能力的行业知识资产。
- 形成可复制、可推广的智慧法院新范式:为全国司法体制综合配套改革提供坚实的技术底座和实践样板。
这三个目标环环相扣,共同构成了一个完整的智慧法院建设愿景:一个既能显著提升效率、又能有力保障公正、同时还绝对安全可靠的智能化司法支撑体系。
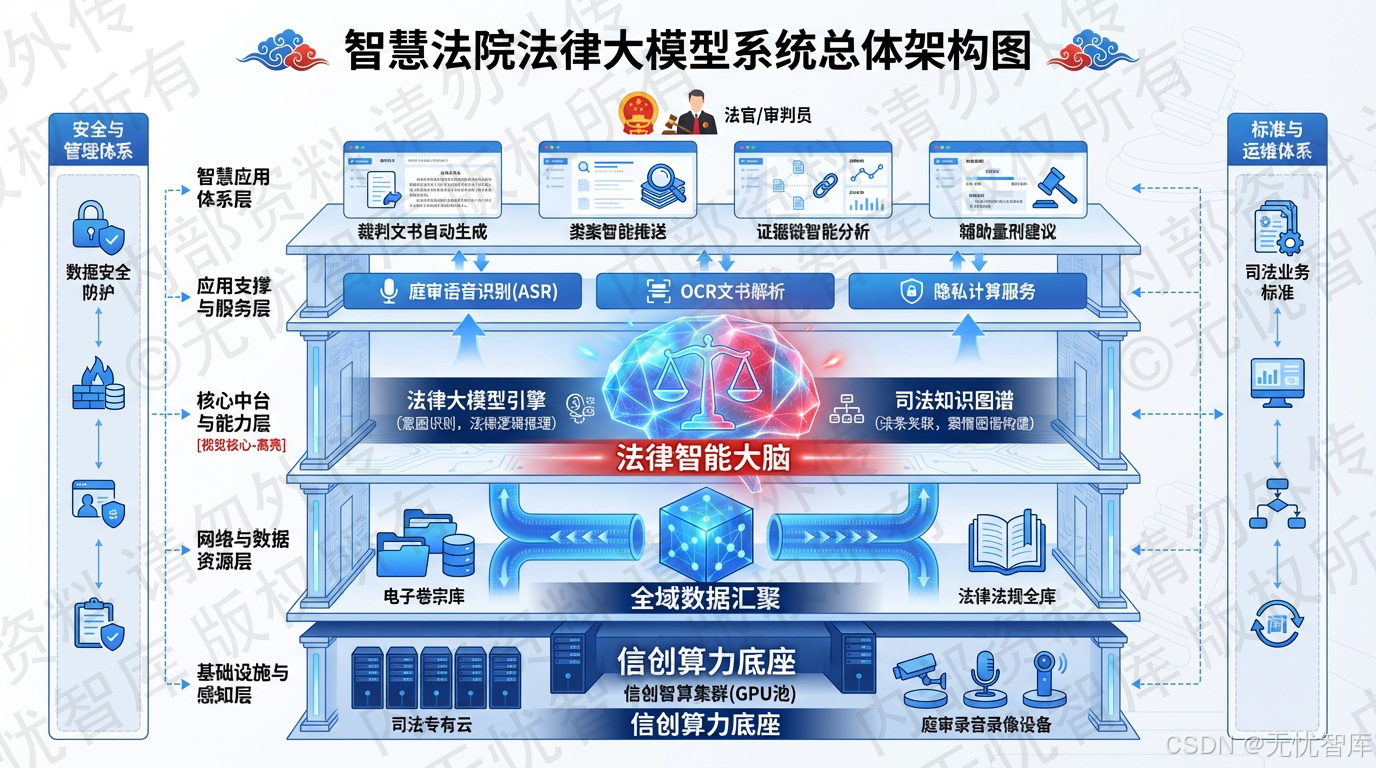
三、技术基石:揭秘"法治大脑"的双引擎驱动架构
如果说目标是灯塔,那么技术就是航船。本方案最核心的创新在于其独特的"双引擎"技术架构------大语言模型(LLM) + 法律知识图谱(KG)。这种深度融合的设计,旨在扬长避短,既发挥大模型强大的语义理解和生成能力,又利用知识图谱严谨的逻辑约束来遏制其"幻觉"风险。
3.1 大语言模型(LLM):司法领域的"通才"
通用大模型虽然强大,但缺乏对法律专业术语、逻辑和时效性的深刻理解。因此,方案提出了一套完整的法律大模型定制化路径:
- 基座选型 :方案经过详细对比,优先选择
Qwen-2-72B作为主干基座模型。原因在于其在中文语义理解、法律逻辑推理、政治合规性以及私有化部署成本之间取得了最佳平衡。 - 领域微调(SFT):通过监督微调,将百万级的法律专用指令集注入模型。这些指令涵盖案情要素提取、法条推荐、判决预测、文书纠错等具体任务,并引入"思维链"(Chain of Thought, CoT)训练,要求模型展示完整的法律推理过程。
- 人类反馈强化学习(RLHF):组织资深法官、律师等专家团队,对模型输出进行排序和打分,利用PPO算法不断优化模型策略,使其输出严格对齐司法价值观和社会主义核心价值观。
3.2 法律知识图谱(KG):司法领域的"专才"
知识图谱是解决大模型"幻觉"问题的关键。它将离散的法律知识结构化、关联化,形成一个确定性的"逻辑骨架"。
- 本体层设计:定义了法律法规、法律主体、罪名/案由、证据要素、量刑情节等核心实体类,以及它们之间的引用、构成、属于等关系类。这为法律推理提供了清晰的逻辑框架。
- 知识抽取与融合:利用NER、RE等NLP技术,从海量裁判文书中自动提取结构化知识,并通过实体对齐、消歧等技术,构建一个包含千万级实体、亿级关系的庞大知识网络。
- 图数据库选型 :方案最终选择
NebulaGraph作为核心存储引擎,因其在分布式扩展、多跳查询性能和国产化适配方面表现优异。
3.3 "LLM + KG"融合机制:协同作战,优势互补
两者并非孤立存在,而是通过精巧的融合机制协同工作:
- 知识增强的检索生成(RAG):当用户提问时,系统首先从知识图谱和向量库中检索相关事实,再将这些确定性知识作为上下文注入大模型的提示词(Prompt),确保其生成内容有据可查。
- 逻辑约束的解码策略:在生成关键内容(如量刑建议)时,系统会触发知识图谱中的逻辑规则进行校验。例如,若模型建议对未成年人判处死刑,系统会立即强制修正,因为这违反了法定的逻辑规则。
这种"双引擎"架构,使得系统既有大模型的"灵性"------能理解复杂的自然语言并生成流畅文本,又有知识图谱的"理性"------能确保输出内容的专业、准确和合规,从而构建了一个真正可靠、可用的"法治大脑"。
四、核心引擎:RAG------连接静态知识与动态生成的战略枢纽
在法律AI应用中,单纯依赖大模型是危险的,因为它可能编造不存在的法条或引用已废止的法规。检索增强生成(RAG)引擎正是解决这一致命缺陷的核心组件,它为大模型装载了一个实时更新、精准检索的"专业图书馆"。
4.1 向量化索引:法律知识的数字化重构
RAG的第一步是将海量法律文本转化为机器可理解的向量。但这并非简单的"一刀切":
- 精细化切片(Chunking):采用"语义原子切片"策略。对于法律条文,以"条"为单位;对于判决书,则按"首部、事实、理由、依据、判决结果"进行结构化拆分,并保留关键的元数据关联。
- 高维向量化(Embedding) :使用经过法律语料微调的
BGE-Large-ZH等模型,将文本转化为1024维的高维向量,确保法律术语的语义能被精准捕捉。 - 混合索引体系:单一的向量检索不足以应对所有场景。因此,系统构建了"关键词(Elasticsearch)+ 向量(Milvus)+ 知识图谱(NebulaGraph)"的混合索引体系,兼顾精确匹配、语义相似和逻辑推理的需求。
4.2 检索重排序策略:确保法律输出的绝对精准
检索的深度决定了生成的精度。方案设计了一套从查询改写到重排序的闭环流程:
- 查询改写与意图对齐:将用户模糊的自然语言问题(如"邻居吵架怎么办")转化为标准的法律术语(如"相邻关系纠纷"),并生成多个假设性检索式,以弥合语义鸿沟。
- 多路召回机制:同时启动向量、倒排、图谱三种检索方式,确保信息覆盖全面。
- 精细化重排序(Rerank) :引入专门微调的Cross-Encoder模型,对召回结果进行深度打分。在此过程中,系统会注入法律效力位阶权重 (宪法 > 法律 > 行政法规)、时效性强过滤 (自动剔除废止条文)和权威性加权(指导性案例权重更高),确保最终进入大模型上下文的是最相关、最权威、最有效的法律依据。
RAG引擎的建设,从根本上解决了法律AI的可信度问题。它让每一次回答、每一份文书都有迹可循、有法可依,实现了从"自由创作"到"严谨查阅"的根本性转变。
五、功能落地:AI如何深度嵌入"立案-审理-判决"全链条?
技术的价值最终要体现在业务场景中。本方案详细规划了三大核心业务功能模块,展示了AI如何从"外挂式"辅助转变为"嵌入式"赋能。
5.1 庭审语音识别与转写:打造"音落字现"的数字化法庭
庭审是审判的核心环节。本系统通过以下技术实现高精度、高效率的庭审记录:
- 多路音频流与声纹分离:支持多通道音频接入,并利用声纹识别技术自动区分审判员、原告、被告等角色,在笔录中精准标注。
- 法律领域知识增强:内置50万+法律术语词库,对"罪刑法定"、"不当得利"等专业词汇进行重点优化,确保识别准确率≥98%。
- 语义修正与一键归档:NLP引擎自动修正同音异义词、口语化表达,并一键生成符合规范的庭审笔录,支持电子签名与自动归档。
5.2 证据链智能分析:从"看图"到"读意"的跨越
阅卷是法官认定事实的基础。AI在此环节的作用是革命性的:
- 全案卷宗OCR与要素提取:对各类扫描件进行高精度OCR,并自动提取"时间、地点、人物、行为、结果"等关键要素。
- 证据矛盾点自动检测:通过逻辑推理机,自动发现不同证据间的冲突,如证人证言与监控录像的时间、空间矛盾。
- 证据链可视化图谱:基于知识图谱技术,将全案证据以拓扑图形式呈现,法官可直观地看到证据如何支撑或削弱某一待证事实,并可点击节点直接调取原始卷宗,实现"图文对照"。
5.3 类案智能推送与文书自动生成:让"同案同判"成为现实
这是提升司法效率与公正的终极体现:
- 类案智能推送:系统自动解析当前案件特征,生成"案件指纹",并从全国案例库中精准推送相似案例。它不仅能推送案例,还能自动生成《类案对比分析报告》,高亮异同点,为法官提供深度参考。
- 文书自动生成:系统聚合立案、庭审、质证等各环节的结构化数据,利用大模型自动生成"本院认为"等核心论述段落。针对"判决结果",系统还能自动核算复杂的利息、违约金,并生成标准化的判项表述。
- 全流程质量防控:内置逻辑一致性校验、法条时效性校验、敏感词过滤等多重纠错机制,确保生成的文书严谨无误。
通过这三大功能,AI深度融入了法官办案的每一个关键节点,将法官从繁琐的事务性工作中解放出来,使其能够真正专注于法律适用、价值判断和裁判说理等核心审判工作。
六、安全与自主可控:筑牢司法AI的生命线
司法数据的敏感性和重要性,决定了安全与自主可控是本项目不可逾越的红线。方案对此进行了全方位、多层次的设计。
6.1 内容安全:构建大模型的"防火墙"
针对AIGC特有的安全挑战,方案构建了覆盖输入输出的内容安全网关:
- 输入端:防范提示词注入、自动脱敏个人敏感信息(PII)、拦截违规意图。
- 输出端:多级敏感词过滤、价值观对齐校验、幻觉检测与事实校核,并嵌入隐形数字水印用于溯源。
6.2 数据安全:全生命周期的隐私保护
严格执行《数据安全法》和相关国标:
- 自动化脱敏:采用"NER+正则"双路检测,对姓名、身份证号、住址等敏感信息进行掩码或泛化处理。
- 隐私计算:在跨部门数据共享场景下,引入联邦学习、差分隐私等技术,实现"数据可用不可见"。
- 物理隔离:系统整体部署于司法专网,确保核心数据不出内网。
6.3 全栈信创适配:确保技术自主
积极响应国家信创战略,实现从芯片到应用的全面国产化:
- 算力底座:深度适配华为昇腾、海光DCU等国产AI芯片。
- 基础软件:全面兼容银河麒麟、统信UOS操作系统,达梦、人大金仓数据库,东方通中间件等。
- 开发框架:后端采用Spring Cloud,前端采用Vue.js,均通过国产编译器严格测试。
这套纵深防御体系,确保了智慧法院系统在享受AI红利的同时,牢牢守住了安全、合规、自主的生命线。
七、实施与展望:从蓝图到现实的稳健路径
再好的方案,也需要扎实的落地。方案规划了为期12个月的分阶段实施计划,并设计了多层次的培训推广体系。
- 第一阶段(0-3月):聚焦基础设施与模型底座构建。
- 第二阶段(4-8月):进行应用开发与小范围试点,通过真实场景反馈进行迭代优化。
- 第三阶段(9-12月):全面推广、完成等保测评,并组织全员培训,确保系统平稳上线。
投资估算方面,项目总投资约1383万元,其中硬件设备783万元,软件与服务600万元,充分体现了对算力和高质量数据工程的重视。
总而言之,《智慧法院法律大模型辅助办案与文书生成系统建设方案》不仅描绘了一幅技术赋能司法的宏伟蓝图,更提供了一套兼具前瞻性、可行性与安全性的完整实施路径。它标志着司法智能化建设已从概念探讨迈入了深度实践的新阶段,必将为构建更高水平的"数字正义"贡献核心力量。