Milvus 向量数据库:架构解析与生产级实现深度剖析
1. 整体介绍
项目地址: GitHub - milvus-io/milvus。截至分析时,该项目拥有超过 27k Stars 和 3k Forks,是 LF AI & Data Foundation 旗下的顶级开源项目之一,标志着其在向量数据库领域的领先地位和广泛的社区认可。
核心定位与功能: Milvus 是一个云原生、高性能的向量数据库,专门为处理海量非结构化数据(通过嵌入模型转换为向量)的相似性搜索而设计。其核心功能并非简单的向量检索,而是构建了一个完整的、生产就绪的数据管理系统,支持数据的实时插入、索引构建、持久化存储、分布式查询以及多租户隔离。
面临问题与目标场景:
- 问题:AI 应用(如 RAG、推荐系统、以图搜图)需要快速从数十亿甚至数百亿的向量中找出最相似的条目。传统关系型数据库或简单的键值存储无法高效处理此类高维数据、近邻搜索(ANN)和复杂的元数据过滤。
- 目标人群:AI 应用开发者、算法工程师、需要构建大规模语义搜索或个性化推荐平台的中大型企业技术团队。
- 核心场景:低延迟、高并发的向量检索,尤其是在数据持续流入(实时更新)且需要与标量过滤结合(混合搜索)的场景。
解决方案演进:
- 传统方式:早期方案可能依赖于独立的ANN库(如FAISS)搭配传统数据库进行元数据管理,需要开发者自行解决数据同步、一致性、高可用和水平扩展等复杂问题,系统集成和维护成本很高。
- Milvus 新方式:将专用的向量索引引擎、流批一体数据管道、分布式协调、存储抽象层和查询引擎封装为一个完整的数据库系统。它提供了标准的客户端接口(SDK)、SQL-like 查询语言,并内置了集群管理、负载均衡、故障恢复等生产级特性,极大地简化了开发运维复杂度。
技术价值与商业逻辑:
- 代码成本效益:Milvus 将向量搜索从"算法库集成项目"提升为"基础设施服务",节约了企业自研类似系统所需的大量人力和时间成本(估计数十人年)。其开源属性进一步降低了技术采纳的初始门槛。
- 覆盖问题空间效益:通过一套系统解决了向量数据的"存、管、算、查"全链路问题,覆盖了从实验原型到超大规模生产的各类场景。其商业化托管服务(如 Zilliz Cloud)则证明了其在商业场景下的可靠性与可服务性,为企业提供了从开源自建到全托管的平滑演进路径。价值生成逻辑在于将复杂的分布式系统工程能力产品化、服务化。
2. 详细功能拆解
从技术与产品结合视角,其核心功能可拆解如下:
-
向量化数据生命周期管理:
- 写入与流处理 :支持批量导入与实时插入。从提供代码可见,DataNode 内部有
syncMgr负责数据的刷盘同步,importScheduler管理导入任务,实现了流批一体的数据摄入。 - 索引构建与管理 :支持多种向量索引(HNSW, IVF, DiskANN等)。
DataNode中的taskScheduler和taskManager负责协调索引构建任务,与底层的segcore(C++核心)交互。 - 持久化与分层存储 :通过
ChunkManager抽象接入对象存储(S3)、本地盘等,并设计了冷热数据分层机制(代码中提及fileresource模块的不同Mode)。
- 写入与流处理 :支持批量导入与实时插入。从提供代码可见,DataNode 内部有
-
分布式查询与计算:
- 查询协调 :
QueryNode作为查询执行节点,其clusterManager可以管理本地和远程工作者(LocalWorker/PoolingRemoteWorker),实现跨节点的分布式查询。 - 查询调度与优化 :
QueryNode中的scheduler负责查询任务的调度。queryHook插件机制允许动态加载优化器,实现运行时查询参数调优(如自动调整搜索参数ef、nprobe)。 - 混合搜索:在向量检索的基础上,原生集成标量过滤、全文检索(BM25)和结果重排,由查询引擎在检索链路中统一处理。
- 查询协调 :
-
系统可观测性与运维:
- 度量收集 :
DataNode和QueryNode都集成了metricsRequest,注册了系统指标、同步任务状态、段和通道信息等,可通过统一的GetMetrics接口暴露,方便接入监控系统。 - 优雅停止与负载均衡 :
QueryNode的Stop()方法展示了其优雅停止流程,会等待数据迁移(sealedSegments,growingSegments,channel清零)后再完全退出,这是配合集群负载均衡和滚动升级的关键特性。 - 配置热更新 :
QueryNode.RegisterSegcoreConfigWatcher()展示了如何监听配置变动(如线程池系数、磁盘写入参数)并动态应用到底层 C++ 核心 (segcore)。
- 度量收集 :
3. 技术难点与核心因子
基于代码分析,实现 Milvus 这类系统面临的主要技术难点包括:
- 分布式状态管理与一致性 :在由多个无状态 QueryNode 和 DataNode 组成的集群中,如何管理数据段(Segment)的分布、副本、加载状态,并保证查询视图的一致性,是一大挑战。代码中通过
sessionutil在 etcd 中注册节点信息,并依赖上层 Coordinator 进行全局调度。 - 内存与磁盘资源的精细管控 :向量搜索对内存带宽和容量敏感。
QueryNode中关于mmap的一系列配置,以及segments.Manager对内存中段的生命周期管理,体现了对内存使用的精细控制。DiskWrite相关参数的热更则关注磁盘 I/O 的优化。 - 查询延迟与吞吐的平衡 :高并发下的低延迟查询需要高效的调度和资源隔离。
QueryNode中的scheduler以及可配置的HighPriorityThreadCoreCoefficient正是为此设计。插件化的queryHook则为针对不同数据和负载进行自动化调优提供了可能。 - 系统可扩展性与插件化架构 :需要支持多样的索引类型、存储后端和硬件加速。代码中通过工厂模式(如
StorageFactory)、依赖注入(dependency.Factory)和动态链接库插件(plugin.Open)等机制,实现了良好的扩展性。 - 生产级稳健性 :随处可见的
sync.Once确保初始化幂等,lifetime.Lifetime管理组件状态机,stopOnce保证资源释放不重复,以及信号处理、子进程管理、defer清理等,共同构建了系统的容错能力。
4. 详细设计图
4.1 顶层架构图
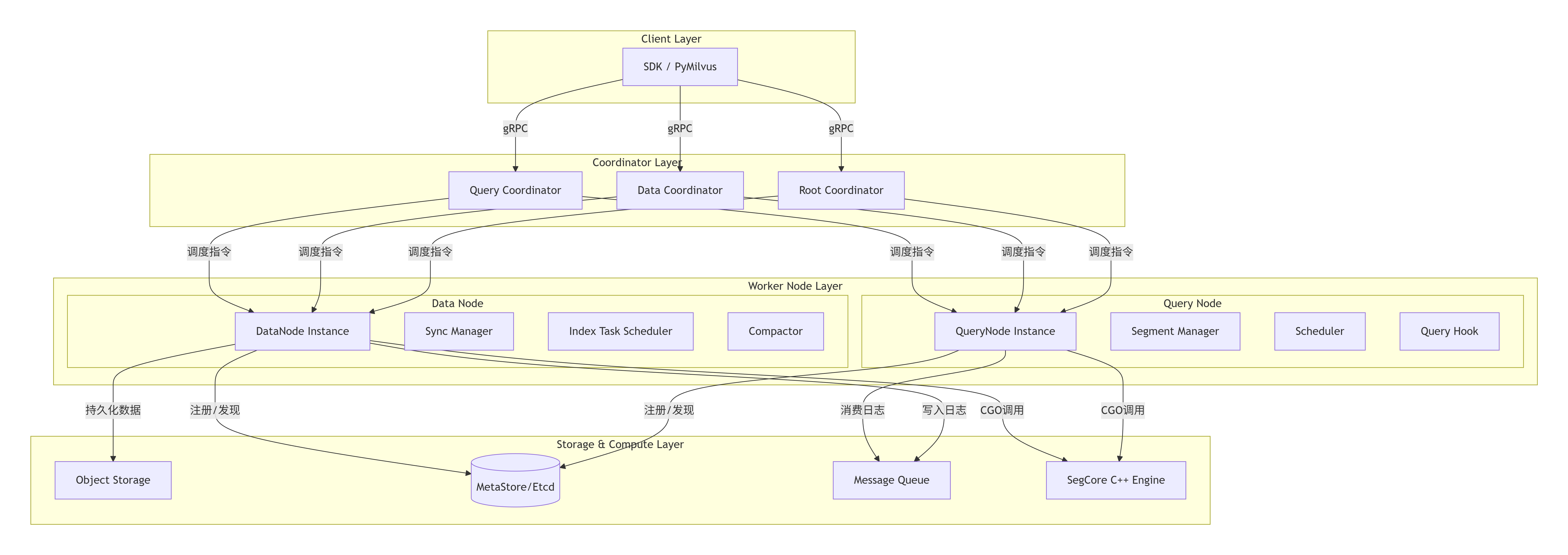
- 说明 :此图展示了 Milvus 分布式部署的核心组件分层。用户通过 SDK 访问 Coordinator 层。Coordinator 是无状态的调度大脑,负责元数据管理和任务下发。Worker Node(DataNode, QueryNode)是执行单元,通过消息队列进行数据同步,通过对象存储进行持久化,并通过 CGO 调用高性能 C++ 计算内核
SegCore。Etcd 用于服务发现和分布式协调。
4.2 核心链路序列图:向量搜索请求
Mem/SSD Cache SegCore Engine Segment Manager QueryNode Proxy (Coordinator Layer) Client Mem/SSD Cache SegCore Engine Segment Manager QueryNode Proxy (Coordinator Layer) Client alt 数据在缓存 数据不在缓存 发送搜索请求 (collection, vector, filter) 查询元数据, 确定目标段分布 路由请求至负责的 QueryNode (s) 获取相关 Segment 信息 检查数据/索引是否在内存 命中 通过 Loader 从存储加载 返回 Segment 访问句柄 通过 CGO 调用 SegCore 执行搜索 (含过滤) 返回初步结果 (IDs, scores) 可能进行跨节点归并或重排 返回本节点结果 全局结果归并、排序 返回最终 TopK 结果
- 说明:此序列图描绘了一次向量搜索请求的核心流程。它涵盖了请求路由、元数据查询、数据段加载(涉及冷热分层)、调用底层计算引擎执行核心搜索逻辑,以及最终的结果归并。
4.3 核心类图(简略)
依赖插件
DataNode
-syncMgr SyncManager
-compactionExecutor Compactor.Executor
-taskScheduler *index.TaskScheduler
-session *sessionutil.Session
-lifetime lifetime.Lifetime
+Init() : error
+Start() : error
+Stop() : error
+UpdateStateCode(commonpb.StateCode)
+Register() : error
QueryNode
-manager *segments.Manager
-scheduler scheduler.Scheduler
-clusterManager cluster.Manager
-queryHook optimizers.QueryHook
-session *sessionutil.Session
-lifetime lifetime.Lifetime
+Init() : error
+Start() : error
+Stop() : error
+initHook() : error
segments.Manager
+Segment *Collection // 管理 Segment 集合
-loader Loader
+SetLoader(Loader)
lifetime.Lifetime<T>
-state T
-cond *sync.Cond
+SetState(T)
+GetState() : T
+Wait()
optimizers.QueryHook
- 说明 :类图聚焦于两个核心工作节点的主要结构和关系。
DataNode和QueryNode都内嵌了lifetime.Lifetime用于状态管理,这是保证组件生命周期可控的通用模式。QueryNode依赖segments.Manager管理数据段,并可通过插件接口queryHook扩展优化能力。
5. 核心函数解析
以下对提供的代码中几个关键函数进行解析:
5.1 入口与进程管理 (cmd/main.go - main)
go
func main() {
// ... 初始化设置 ...
idx := slices.Index(os.Args, "--run-with-subprocess")
// 执行命令作为子进程,如果命令包含"--run-with-subprocess"
if idx > 0 {
args := slices.Delete(os.Args, idx, idx+1)
log.Println("run subprocess with cmd:", args)
/* #nosec G204 */ // 安全审查注释:参数受控
cmd := exec.Command(args[0], args[1:]...)
// ... 设置输出、启动子进程 ...
waitCh := make(chan error, 1)
go func() { waitCh <- cmd.Wait(); close(waitCh) }()
sc := make(chan os.Signal, 1)
signal.Notify(sc) // 捕获所有系统信号
for {
select {
case sig := <-sc:
// 将接收到的信号转发给子进程
if err := cmd.Process.Signal(sig); err != nil {
log.Println("error sending signal", sig, err)
}
case err := <-waitCh:
// 子进程退出,执行清理工作(如清理etcd中的会话信息)
paramtable.Init()
// ... 清理逻辑 ...
return
}
}
} else {
// 正常模式,直接运行Milvus主逻辑
milvus.RunMilvus(os.Args)
}
}- 解析 :这是系统的总入口。
--run-with-subprocess参数是一个关键设计,它允许主进程作为"保姆进程"启动一个子进程来运行实际服务。这样做的好处是:- 信号转发:主进程可以捕获系统信号(如 SIGTERM)并优雅地转发给子进程,确保子进程有机会进行清理。
- 资源清理 :子进程退出后,主进程可以在
case err := <-waitCh:分支中执行必要的全局资源清理(如调用milvus.CleanSession删除 etcd 中残留的节点信息),避免因进程意外崩溃导致元数据"脏数据"。 - 隔离与重启 :为未来实现进程监控和自动重启提供了架构基础。
#nosec G204注释表明团队已意识到动态命令执行的安全风险,并在此受控上下文中评估为可接受。
5.2 DataNode 初始化 (internal/datanode/data_node.go - Init)
go
func (node *DataNode) Init() error {
var initError error
node.initOnce.Do(func() { // 使用 sync.Once 确保并发安全且只初始化一次
node.registerMetricsRequest() // 1. 注册度量指标收集器
if err := node.initSession(); err != nil { // 2. 初始化并注册到 etcd (会话)
initError = err; return
}
syncMgr := syncmgr.NewSyncManager(nil) // 3. 创建同步管理器,负责数据刷盘
node.syncMgr = syncMgr
// 4. 根据配置初始化文件资源管理器(支持同步/异步模式)
fileMode := fileresource.ParseMode(paramtable.Get().CommonCfg.DNFileResourceMode.GetValue())
if fileMode == fileresource.SyncMode {
cm, err := node.storageFactory.NewChunkManager(node.ctx, compaction.CreateStorageConfig())
if err != nil { initError = err; return }
fileresource.InitManager(cm, fileMode) // 传入存储管理器
} else {
fileresource.InitManager(nil, fileMode) // 异步模式可能延迟初始化
}
node.importTaskMgr = importv2.NewTaskManager() // 5. 初始化导入任务管理器
node.importScheduler = importv2.NewScheduler(node.importTaskMgr)
err := index.InitSegcore(node.GetNodeID()) // 6. 初始化底层 C++ segcore 环境
if err != nil { initError = err }
analyzer.InitOptions() // 7. 初始化分析器选项(可能用于查询优化)
})
return initError
}- 解析 :
DataNode.Init()方法清晰地展示了数据节点启动时的模块化初始化顺序。它严格遵守"依赖前置"原则:先建立会话和元数据连接,再初始化核心数据处理组件(syncMgr,importScheduler),最后初始化底层计算引擎。sync.Once和错误提前返回的模式保证了初始化的安全性和可预测性。文件资源管理器的模式化初始化体现了对性能(异步)和数据可靠性(同步)的权衡设计。
5.3 QueryNode 插件化查询钩子初始化 (internal/querynodev2/server.go - initHook)
go
func (node *QueryNode) initHook() error {
path := paramtable.Get().QueryNodeCfg.SoPath.GetValue() // 1. 从配置获取插件路径
if path == "" { return errors.New("fail to set the plugin path") }
hookutil.LockHookInit() // 2. 全局锁,防止并发加载同一插件
defer hookutil.UnlockHookInit()
p, err := plugin.Open(path) // 3. Go 标准库 plugin 动态加载 .so 文件
if err != nil { return fmt.Errorf("fail to open the plugin, error: %s", err.Error()) }
h, err := p.Lookup("QueryNodePlugin") // 4. 查找约定的符号 `QueryNodePlugin`
if err != nil { return fmt.Errorf("fail to find the 'QueryNodePlugin' object...") }
hoo, ok := h.(optimizers.QueryHook) // 5. 断言为约定的接口类型
if !ok { return errors.New("fail to convert the `Hook` interface") }
// 6. 使用配置初始化插件
if err = hoo.Init(paramtable.Get().AutoIndexConfig.AutoIndexSearchConfig.GetValue()); err != nil { return err }
if err = hoo.InitTuningConfig(paramtable.Get().AutoIndexConfig.AutoIndexTuningConfig.GetValue()); err != nil { return err }
node.queryHook = hoo // 7. 赋值给节点成员
node.handleQueryHookEvent() // 8. 注册配置变更监听器,支持热更新
return nil
}- 解析 :此函数是 Milvus 系统可扩展性 和智能化 的一个关键体现。它利用 Go 的
plugin机制,在运行时动态加载编译好的共享库,实现了查询优化逻辑的热插拔。optimizers.QueryHook是一个预定义的接口,插件开发者只需实现该接口并暴露名为QueryNodePlugin的符号即可。这使得第三方或内部团队可以开发复杂的查询优化算法(如基于强化学习的参数调优)而不必修改 Milvus 核心代码。结合后续的handleQueryHookEvent监听的配置热更新,实现了算法策略的动态调整,非常适用于 AI 场景下多变的工作负载。
总结 :通过对 Milvus 项目,特别是其 Go 语言层核心代码的深度剖析,我们可以看到它是一个设计严谨、面向生产环境的复杂系统。它不仅仅是一个向量检索库,更是一个集成了分布式协调、流式数据处理、资源管理、可观测性和插件化扩展的全功能数据库。其架构设计充分考虑了云原生环境的需求,代码实现中随处可见的并发控制、状态管理、错误处理和资源清理逻辑,体现了其对企业级稳定性与可靠性的高要求。对于需要构建大规模、低延迟向量检索应用的中高级开发者而言,理解其内部机制有助于更好地使用、调试和运维这一强大工具。