李明欣∗^{*}∗ 张言昭∗^{*}∗ 龙鼎坤∗^{*}∗ 陈可钦
宋思博 白帅 杨志波 谢鹏君
杨安 刘大恒 周靖人 林俊阳
通义实验室,阿里巴巴集团
https://huggingface.co/collections/Qwen
https://modelscope.cn/organization/qwen
https://github.com/QwenLM/Qwen3-VL-Embedding
摘要
在本报告中,我们介绍了Qwen3-VL-Embedding和Qwen3-VL-Reranker模型系列,这是基于Qwen3-VL基础模型构建的Qwen家族的最新扩展。它们共同提供了端到端的高精度多模态搜索流水线,将包括文本、图像、文档图像和视频在内的多种模态映射到统一的表示空间中。Qwen3-VL-Embedding模型采用多阶段训练范式,从大规模对比预训练到重排序模型蒸馏,生成语义丰富的高维向量。它支持Matryoshka表示学习,能够灵活调整嵌入维度,并可处理最多32k个token的输入。作为补充,Qwen3-VL-Reranker通过使用具有交叉注意力机制的交叉编码器架构,对查询-文档对执行细粒度相关性估计。两个模型系列都继承了Qwen3-VL的多语言能力,支持超过30种语言,并以2B和8B参数规模发布,以满足不同的部署要求。实证评估表明,Qwen3-VL-Embedding系列在各种多模态嵌入评估基准上达到了最先进的结果。具体而言,Qwen3-VL-Embedding-8B在MMEB-V2上获得了77.8的综合得分,在所有模型中排名第一(截至2025年1月8日)。本报告介绍了该系列的架构、训练方法和实际能力,展示了它们在各种多模态检索任务上的有效性,包括图文检索、视觉问答和视频-文本匹配。
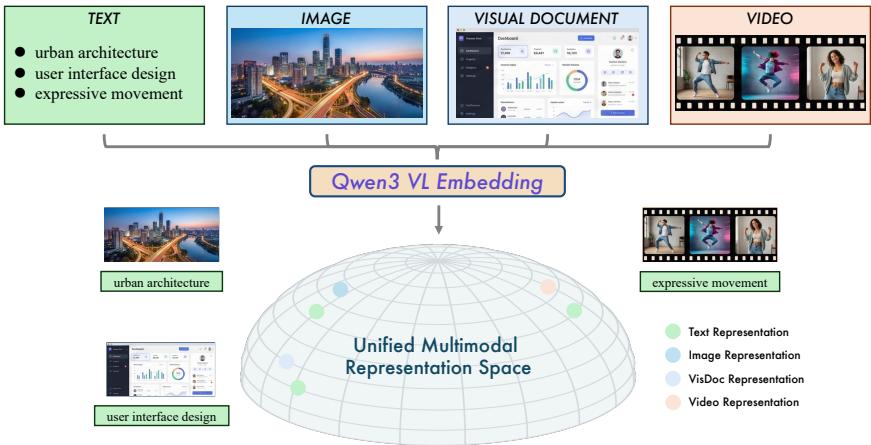
图1:统一多模态表示空间示意图。Qwen3-VL-Embedding模型系列将多源数据(文本、图像、视觉文档和视频)表示为一个共同的流形。通过在不同模态之间对齐语义概念(例如,文本"城市建筑"及其对应图像),该模型实现了对复杂视觉和文本信息的整体理解。
1 引言
互联网上多模态内容的指数级增长从根本上改变了信息的创建、共享和消费方式。现代数字生态系统越来越多地充斥着各种数据模态,包括自然图像、文本文档、信息图表、截图和视频。这种激增使得先进的检索系统变得必要,这些系统能够理解和匹配跨不同模态的语义概念,超越传统的纯文本搜索范式。多模态搜索旨在检索相关的内容,无论查询或文档的模态如何,已成为从电子商务产品发现到科学文献探索和社交媒体导航等应用的关键能力(Faysse等,2025;Fu等,2025)。
在当代多模态检索架构中,嵌入模型和重排序模型构成了两个最关键的模块。在过去的十年中,多模态表示学习领域取得了显著进展(Manzoor等,2023;Mei等,2025)。在这些开创性工作中,CLIP(对比语言-图像预训练)(Radford等,2021)通过证明在图像-文本对上进行大规模对比学习可以产生强大的对齐表示而产生了特别大的影响。它的成功确立了学习共享嵌入空间的重要性,在这种空间中,语义相似的内容无论其模态如何,都在表示空间中彼此靠近。
随着基础模型的发展加速,多模态预训练的视觉-语言模型(VLMs)如Qwen-VL(Wang等,2024b;Bai等,2025)和GPT-4o(Hurst等,2024)在多模态理解方面取得了前所未有的成功。基于这些突破,多模态检索社区越来越多地探索基于VLMs训练统一的多模态嵌入模型。这一领域值得注意的工作包括E5-V(Jiang等,2024)、GME(Zhang等,2025b)、BGE-VL(Zhou等,2025)和VLM2Vec(Meng等,2025;Jiang等,2025)。基于VLMs训练统一的多模态表示具有几个令人信服的优势。首先,VLMs通过在大规模图像-文本数据集上的预训练,具有固有的跨模态对齐能力。其次,它们利用复杂的注意力机制来捕获视觉和文本元素之间的细粒度交互。第三,它们为处理信息图表和演示幻灯片等复杂多模态文档提供了自然途径,其中视觉和文本信息是深度交织的。此外,基于VLM的方法可以继承基础模型中编码的广泛多语言和多领域知识,从而在各种检索场景中实现更强大的泛化能力。
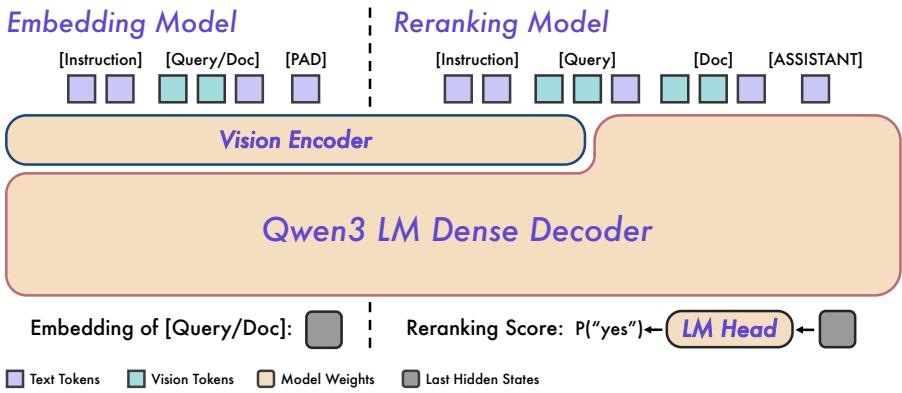
图2:Qwen3-VL-Embedding和Qwen3-VL-Reranker架构概述。
在本工作中,我们介绍了专为多模态检索应用设计的Qwen3-VL-Embedding和Qwen3-VL-Reranker模型系列。这些模型基于强大的Qwen3-VL(Bai等,2025)基础模型构建,将先进的视觉-语言理解能力与为检索任务量身定制的专业训练方法结合起来。Qwen3-VL-Embedding系列采用复杂的多阶段训练范式,从大规模多模态数据上的对比预训练进展到排序模型的知识蒸馏,最终产生捕获跨模态细微关系的语义丰富嵌入。这些模型支持Matryoshka表示学习(Kusupati等,2022),允许用户根据存储和计算约束灵活选择嵌入维度,而无需重新训练。此外,我们在训练过程中整合了量化感知训练策略,以确保生成的嵌入在量化后仍保持稳健的性能。这一能力显著提高了下游任务的存储效率和计算友好性。这些模型可以处理包含最多32,768个token的输入,能够全面理解长文档和视频。作为嵌入模型的补充,Qwen3-VL-Reranker系列采用交叉编码器架构,在查询和文档表示之间执行深度交叉注意力,为候选检索结果提供精确的相关性分数。两个模型系列都继承了Qwen3-VL基础模型令人印象深刻的多语言能力,以高熟练度支持超过30种语言,并以两种规模(2B和8B参数)发布,以适应不同的应用场景。
我们在一套涵盖多个任务和领域的综合基准测试中评估了Qwen3-VL-Embedding和Qwen3-VL-ReRanker模型系列。实验结果表明,我们的嵌入和重排序模型在多种下游任务上达到了最先进的性能。例如,旗舰模型Qwen3-VL-Embedding-8B在MMEB-V2基准测试(Meng等,2025)上获得了77.8分,截至2026年1月评估,超过了排行榜上所有当前模型1^{1}1,包括开源模型和闭源API服务。除了多模态评估之外,在纯文本评估中,Qwen3-VL-Embedding-8B模型在MTEB多语言基准测试(Enevoldsen等,2025a)上达到了67.9的平均任务得分,展示了极具竞争力的性能。此外,我们的重排序模型在一系列检索任务中提供了有竞争力的结果。Qwen3-VL-Reranker-2B模型在众多检索任务中超过了先前表现最好的模型,而更大的Qwen3-VL-Reranker-8B模型展示了更优越的性能,在多个任务上比2B模型提高了4.1分的排序结果。此外,我们包括了一个建设性的消融研究,以阐明Qwen3-VL-Embedding系列卓越性能的关键因素,提供了对其有效性的见解。
在接下来的章节中,我们介绍了我们模型的架构设计,详细阐述了训练过程,报告了嵌入和重排序组件的综合实验结果,并通过综合关键发现和讨论有前景的未来研究方向来总结本技术报告。
表1:Qwen3-VL-Embedding和Qwen3-VL-Reranker的模型规格。"量化支持"表示嵌入支持的量化格式。"MRL支持"表示嵌入模型是否允许用户指定嵌入维度。"指令感知"表示模型是否支持输入指令的任务特定定制。
|--------------------|----|----|------|------|------|-------|------|
| 模型类型 | 规模 | 层数 | 序列长度 | 嵌入维度 | 量化支持 | MRL支持 | 指令感知 |
| Qwen3-VL-Embedding | 2B | 28 | 32K | 2048 | 是 | 是 | 是 |
| Qwen3-VL-Embedding | 8B | 36 | 32K | 4096 | 是 | 是 | 是 |
| Qwen3-VL-Reranker | 2B | 28 | 32K | - | - | - | 是 |
| Qwen3-VL-Reranker | 8B | 36 | 32K | - | - | - | 是 |
2 模型
Qwen3-VL-Embedding和Qwen3-VL-Reranker模型旨在对多模态实例进行任务感知的相关性判断。如图2所示,嵌入模型遵循双编码器架构,为实例生成密集向量表示,并使用余弦相似度作为相关性度量。相比之下,重排序模型采用交叉编码器架构,为每个查询-文档对提供更细粒度的相关性估计。
模型架构 嵌入模型和重排序模型都基于Qwen3-VL骨干网络构建,使用因果注意力机制。在大规模多模态、多任务相关性数据上训练后,它们保留了骨干网络的世界知识、多模态感知和指令遵循能力,同时额外获得了估计相关性的能力。我们训练了两种模型规模------2B和8B------并在表1中总结了它们的规格。
嵌入方法 嵌入模型为多模态输入提取任务感知的密集向量。输入格式遵循Qwen3-VL上下文结构,其中指令作为系统消息传递,默认指令是"表示用户的输入"。要表示的多模态实例作为用户消息传递,可以是文本、图像、视频或这些模态的任意组合。最后,在输入末尾追加一个"PAD"(填充)token,并使用对应于此token的最后一个隐藏状态作为实例的密集向量表示。
嵌入的输入模板
<lim_start>system {Instruction}
<lim_end>
<lim_start>user {Instance}
<lim_end>重排序方法 重排序模型采用点式排序方法,根据指令中提供的相关性定义,评估一对多模态实例之间的相关性。输入格式遵循Qwen3-VL上下文结构,其中相关性定义指令和要评估的多模态实例对都作为用户消息传递。这些多模态输入可以是文本、图像、视频或这些模态的任意组合。最后,通过计算模型预测"yes"或"no"作为下一个输出token的概率,获得该对的相关性估计。
重排序的输入模板
<lim_start>system
根据提供的查询和指令判断文档是否符合要求。
→ 注意:答案只能是"yes"或"no"。
<lim_end>
<lim_start>user
<Instruct>: {Instruction}
<Query>:{Query}
<Document>:{Document}
<lim_end>
<lim_start>assistant3 数据
为了赋予模型跨不同模态、任务和领域的通用表示能力,我们策划了一个大规模数据集。数据集中不同类别的分布如图3所示。然而,公开可用和专有的内部数据在这几个维度上都表现出显著的不平衡性,并且在特定场景中明显稀缺。为了解决这些挑战,我们利用数据合成来构建一个平衡的训练语料库,确保在所有模态、任务和领域上都有稳健的覆盖。
3.1 数据集格式
完整的数据集包含多个子数据集,表示为D={Di}i=1MD = \{D_{i}\}{i=1}^{M}D={Di}i=1M。每个子数据集DiD{i}Di由四元组Di=(Ii,Qi,Ci,Ri)D_{i} = (I_{i}, Q_{i}, C_{i}, R_{i})Di=(Ii,Qi,Ci,Ri)定义,结构如下:
• 指令(Ii)(I_{i})(Ii):定义子数据集特定相关性标准和任务目标的文本描述。
• 查询(Qi)(Q_{i})(Qi):NqN_{q}Nq个查询对象的集合,Qi={qj}j=1NqQ_{i}=\{q_{j}\}{j=1}^{N{q}}Qi={qj}j=1Nq。每个qjq_{j}qj可以包含文本、图像、视频或这些模态的任何组合。
• 语料库(Ci)(C_{i})(Ci):NdN_{d}Nd个文档对象的存储库,Ci={dj}j=1NdC_{i}=\{d_{j}\}{j=1}^{N{d}}Ci={dj}j=1Nd。与查询类似,每个djd_{j}dj可能是单一模态或多模态组合,包含文本、图像和视频。
• 相关性标签(Ri)(R_{i})(Ri):此组件标识查询和文档之间的关系,表示为Ri={(qj,{dj,k+}k=1n+,{dj,k−}k=1n−)}j=1NqR_{i}=\{(q_{j},\{d_{j,k}^{+}\}{k=1}^{n^{+}},\{d{j,k}^{-}\}{k=1}^{n^{-}})\}{j=1}^{N_{q}}Ri={(qj,{dj,k+}k=1n+,{dj,k−}k=1n−)}j=1Nq。对于每个查询qj,{dj,k+}k=1n+⊂Ciq_{j},\{d_{j,k}^{+}\}{k=1}^{n^{+}}\subset C{i}qj,{dj,k+}k=1n+⊂Ci表示相关文档集(正文档),而{dj,k−}k=1n−⊂Ci\{d_{j,k}^{-}\}{k=1}^{n^{-}}\subset C{i}{dj,k−}k=1n−⊂Ci表示不相关文档集(负文档)。
代表性数据集示例在附录A中提供。
3.2 数据合成
图3:训练数据中不同类别的分布。
图4:用于数据合成的种子池的数据分布。
我们利用数据合成来构建各种子数据集DiD_{i}Di。具体而言,我们将Qwen3 Embedding(Zhang等,2025c)中引入的方法扩展到多模态场景。
种子池构建 由于合成数据的多样性取决于底层种子池,我们首先聚合了一个高质量和多样化的原始图像和视频数据集集合。为了建立高质量的基础,我们首先应用粗粒度质量过滤,修剪低分辨率或不规则纵横比的资源。随后进行结构细化,特别是使用场景切割检测并移除静态或损坏的片段,以保持视频数据中时间动态的完整性。之后,我们利用Qwen3-VL-32B(Bai等,2025)为剩余资源生成细粒度类别标签。为了确保跨模态对齐,我们实施了严格的过滤机制,排除置信度低的标注或视觉-文本对应性差的样本,使用GME(Zhang等,2025b)嵌入模型的相似度分数进行衡量。最后,我们在细化后的数据集上执行类别级再平衡,以构建最终的种子池。最终的类别分布如图4所示。
基于种子池,我们利用Qwen3-VL-32B(Bai等,2025)执行多模态和多任务标注。
图像任务标注 我们合成了三种主要任务范式的图像数据集:
- 图像分类:查询qqq包含图像和分类指令,而文档ddd是特定类别标签。我们为各种分类任务合成数据集,包括对象识别、场景解析、地标识别和动作识别。对于每个样本,模型指定特定任务类型,并用其真实类别以及语义混淆的负标签对图像进行标注。
- 图像问答:查询qqq包含图像和基于图像的问题,文档ddd是相应答案。我们生成涵盖事实识别、视觉推理、基于OCR的数据提取和领域特定知识查询的多样化QA对。按照规定的任务导向,模型基于视觉内容制定问题,提供真实响应和一个似是而非但具有欺骗性的干扰项。
- 图像检索:查询qqq是搜索文本,文档ddd是候选图像。我们在语义深度层次上合成检索查询,跨越直接视觉描述、抽象叙事场景、组合逻辑约束和以知识为中心的文本定位。模型分配特定检索意图,并生成捕获图像中显著视觉特征或嵌入文本逻辑的相应搜索查询。
视频任务标注 我们合成了四种主要任务范式的视频数据集:
- 视频分类:查询qqq结合视频和分类任务,文档ddd是结果类别。我们为各种分类任务合成数据集,包括活动识别、场景解析、事件分类和情感/意图分析。对于每个样本,模型识别其类别并生成语义相关的负标签。
- 视频问答:查询qqq包含视频和问题,文档ddd是答案。我们生成涵盖事实识别、时间定位、主题推理和电影分析的多样化QA对。在指定任务类型的指导下,模型制定问题并提供正确响应和具有欺骗性的干扰项。
- 视频检索:查询qqq是文本描述,文档ddd是视频。我们在语义粒度谱上合成检索查询,从实体和动作中心搜索到时间-事件描述、主题/情感发现和教程本地化。模型生成捕获视频主要事件和主题内容的搜索查询。
- 片段检索:查询qqq是文本查询(可选包含关键帧),文档ddd是特定视频片段。片段检索任务旨在进行细粒度时间定位。模型识别特定目标------如动作、对象或角色------并定位相关时间片段。同时,它识别具有明显时间差距的不相关片段作为负面对比。
在合成特定任务标注之前,我们要求模型为每个图像或视频生成描述性标题,以提供必要的上下文。这种两步法确保了后续标注生成的更高质量和一致性。特定任务合成的选定提示示例在附录B中提供。
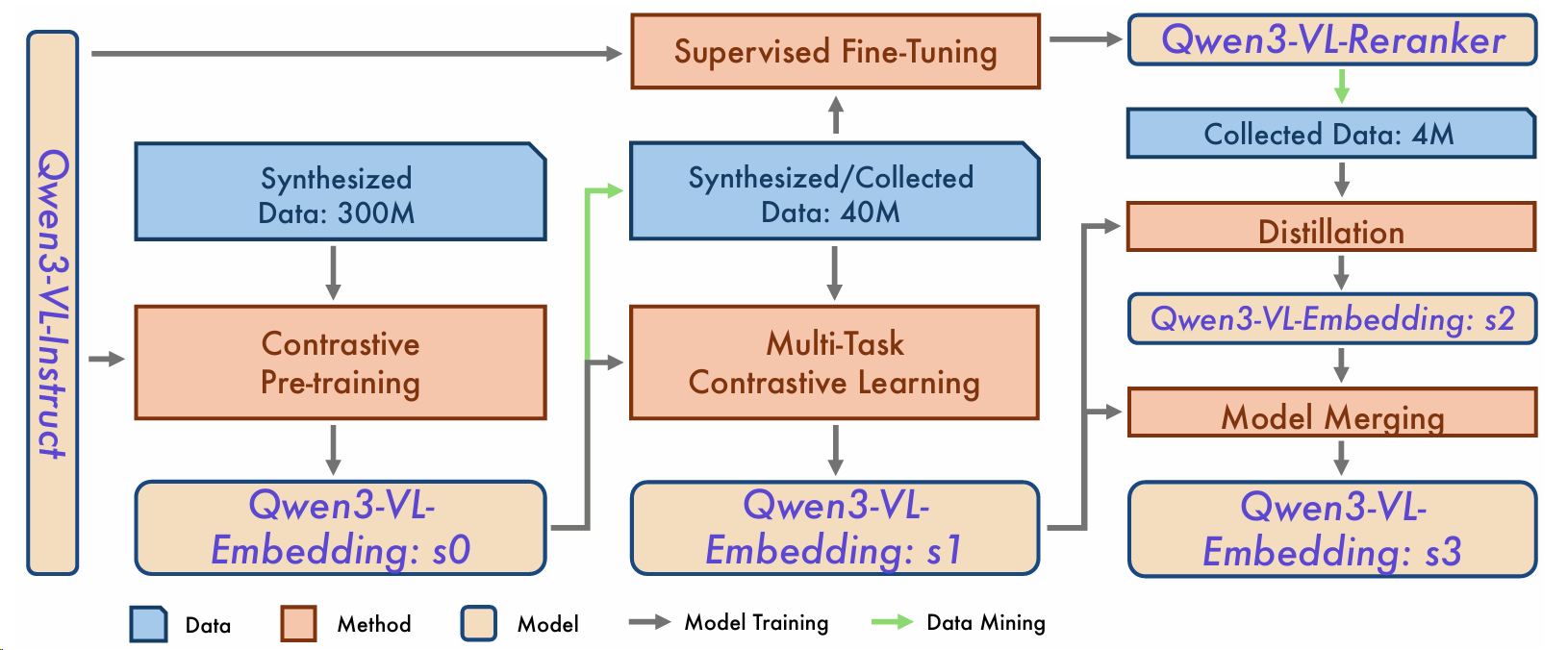
图5:Qwen3-VL-Embedding和Qwen3-VL-Reranker的多阶段训练流水线。
3.3 正样本细化和困难负样本挖掘
困难负样本在对比表示学习中起着至关重要的作用(Robinson等,2021)。为了提高正样本对的质量并识别有效的困难负样本,我们实施了一个自动化的两阶段挖掘流水线:召回和相关性过滤。
召回 对于每个子数据集DiD_{i}Di,我们使用嵌入模型提取所有查询qj∈Qiq_{j} \in Q_{i}qj∈Qi和文档dk∈Cid_{k} \in C_{i}dk∈Ci的表示。对于每个查询qjq_{j}qj,我们基于余弦相似度检索前K个最相关的候选{dk}k=1K\{d_{k}\}{k=1}^{K}{dk}k=1K,表示为相关性分数S={sj,k}k=1KS = \{s{j,k}\}_{k=1}^{K}S={sj,k}k=1K。
相关性过滤 最后,我们根据相关性分数SSS细化相关性标签RiR_{i}Ri,以消除噪声:
• 正样本细化:我们仅当至少一个正文档d+∈{dk}k=1Kd^{+} \in \{d_{k}\}{k=1}^{K}d+∈{dk}k=1K达到分数s>t+s > t^{+}s>t+时才保留qjq{j}qj,其中t+t^{+}t+是作为分数阈值的超参数。如果不存在这样的候选,查询qjq_{j}qj将被丢弃。
• 困难负样本选择:对于有效查询qjq_{j}qj,我们计算其细化正样本的平均分数sˉ+\bar{s}^{+}sˉ+。任何非正文档d∈{dk}k=1Kd \in \{d_{k}\}_{k=1}^{K}d∈{dk}k=1K仅当其分数满足s<sˉ++δ−s < \bar{s}^{+} + \delta^{-}s<sˉ++δ−时才被选为困难负样本,其中δ−\delta^{-}δ−是一个小的安全边际,以防止包含"假负样本"。
4 训练策略
为了训练我们的Qwen3-VL-Embedding和Qwen3-VL-Reranker,我们采用了多阶段训练流水线,如图5所示。这种方法旨在缓解大量弱监督数据和稀缺高质量样本之间的数据不平衡问题(Wang等,2022;Li等,2023;Chen等,2024;Zhang等,2025c)。模型首先在大量的弱监督、噪声数据上进行预训练,以建立相关性理解的基线并提高泛化能力。然后,我们在高质量、任务特定数据集上进行微调,以指导模型进行更精确的相关性评分和细粒度交互。除了上述原因外,多阶段训练策略的另一个目标是引导数据质量和模型性能。随着训练通过连续阶段进行,模型的能力不断得到增强。这种改进反过来促进了更有效的数据挖掘,从而提高了训练数据的质量。这种迭代循环最终导致模型整体性能的显著提升。
4.1 多阶段训练
我们实施了三阶段训练策略,如下所示:
阶段1:对比预训练 在预训练阶段,我们首先在嵌入模型上使用大规模、多模态和多任务合成数据进行对比学习。此阶段使用的合成数据是使用第3.3节中描述的方法挖掘的,使用现有开源模型(Zhang等,2025b)作为嵌入模型。
训练期间使用的优化目标在公式1中定义。完成此阶段后,我们获得初始模型版本Qwen3-VL-Embedding:s0。
阶段2:多任务对比学习和监督微调 在此阶段,我们主要利用精选的公共数据集和专有的内部数据,辅以采样的合成数据来解决现有数据集中的任务不平衡问题。得益于Qwen3-VL-Embedding:s0改进的多任务性能,我们使用此模型执行数据挖掘,从而确保各种任务的高质量数据。然后,我们使用多任务对比学习训练嵌入模型,为不同任务类型实施量身定制的对比目标(详见第5.1节)。这产生Qwen3-VL-Embedding:s1。
同时,我们通过在新挖掘数据的检索特定子集上训练Qwen3-VL-Reranker,该子集涵盖各种任务,包括图像检索、视频检索、片段检索和视觉文档检索。生成的模型在这些以检索为中心的任务上表现出卓越性能,使用公式4作为优化目标。
阶段3:蒸馏和模型合并 在最后阶段,我们通过从先前训练的Qwen3-VL-Reranker中提取相关性判别专业知识,进一步增强嵌入模型。为此,我们从公共和专有来源中精选一个紧凑子数据集,确保多个检索类别之间的平衡分布。然后,我们使用Qwen3-VL-Reranker为该子集生成细粒度相关性分数,作为在公式3定义的目标下训练嵌入模型的监督信号。这种蒸馏过程产生Qwen3-VL-Embedding:s2。
虽然Qwen3-VL-Embedding:s2在以检索为中心的任务上表现出显著提升,但在分类和QA任务上略有性能下降。为了解决这个问题,我们使用Li等(2024)提出的方法将Qwen3-VL-Embedding:s2与Qwen3-VL-Embedding:s1合并。此过程产生我们的最终模型Qwen3-VL-Embedding:s3,在所有评估任务上实现了最优且平衡的性能。
4.2 实现
我们采用低秩适应(LoRA)(Hu等,2022)进行模型训练,模型参数从Qwen3-VL-Instruct初始化。这种方法提供了几个关键优势:1)减少内存占用,允许更大的有效批大小;2)增强泛化性能;3)为模型合并显著提高超参数搜索效率(Li等,2024)。此外,我们采用动态分辨率和帧率。对于图像模态,我们保持原始纵横比,同时将最大token消耗限制在1,280(约1.3×1061.3 \times 10^{6}1.3×106像素)。对于视频,我们首先以1 FPS采样,最多64帧。对于每帧,保持纵横比,所有帧的总token预算限制在4,500(约9.2×1069.2 \times 10^{6}9.2×106像素)。
5 训练目标
本节概述了Qwen3-VL-Embedding和Qwen3-VL-Reranker的训练目标。对于Qwen3-VL Embedding模型,我们将Qwen3 Embedding模型(Zhang等,2025c)的损失函数扩展到处理更广泛的数据类型。我们还集成了两种关键技术:Matryoshka表示学习(MRL)(Kusupati等,2022)以生成可变维度嵌入,以及量化感知训练(QAT)(Esser等,2020)以支持多种数值精度。这些方法共同减少了存储和计算成本,提高了推理效率。Qwen3-VL-Reranker采用与Qwen3 Reranker(Zhang等,2025c)相同的损失函数。每个模型的具体损失函数在下面详细说明。
5.1 嵌入模型的损失函数
Qwen3-VL-Embedding的训练涉及多个阶段的多种数据类型。为适应这一点,我们为每种数据类别的特定特性采用不同的损失函数。
检索数据的损失 此类别包括来自各种多模态和跨模态检索任务的数据,如文本到文本(T2T)、文本到图像(T2I)和图像+文本到图像+文本(IT2IT)检索。在阶段1,我们使用与Qwen3-Embedding相同的InfoNCE损失(Oord等,2018)公式:
Lretrieval=−1N∑iNloge(s(qi,di+)/τ)Zi, \mathcal{L}{\mathrm{retrieval}}=-\frac{1}{N}\sum{i}^{N}\log\frac{e^{\left(s\left(q_{i},d_{i}^{+}\right)/\tau\right)}}{Z_{i}}, Lretrieval=−N1i∑NlogZie(s(qi,di+)/τ),
其中s(⋅,⋅)s(\cdot,\cdot)s(⋅,⋅)是相似度函数(我们使用余弦相似度),τ\tauτ是温度参数,ZiZ_{i}Zi聚合了正样本对和各种类型负样本对的分数:
Zi=e(s(qi,di+)/τ)+∑kKmike(s(qi,di,k−)/τ)+∑j≠imije(s(qi,qj)/τ)+∑j≠imije(s(di+,dj)/τ)+∑j≠imije(s(qi,dj)/τ) Z_{i}=e^{(s(q_{i},d_{i}^{+})/\tau)}+\sum_{k}^{K}m_{ik}e^{(s(q_{i},d_{i,k}^{-})/\tau)}+\sum_{j\neq i}m_{ij}e^{(s(q_{i},q_{j})/\tau)}+\sum_{j\neq i}m_{ij}e^{(s(d_{i}^{+},d_{j})/\tau)}+\sum_{j\neq i}m_{ij}e^{(s(q_{i},d_{j})/\tau)} Zi=e(s(qi,di+)/τ)+k∑Kmike(s(qi,di,k−)/τ)+j=i∑mije(s(qi,qj)/τ)+j=i∑mije(s(di+,dj)/τ)+j=i∑mije(s(qi,dj)/τ)
对应于与(1)正文档di+d_{i}^{+}di+,(2)K个困难负样本{di,k−}k=1K\{d_{i,k}^{-}\}{k=1}^{K}{di,k−}k=1K,(3)其他批次内查询{qj}j≠i\{q{j}\}{j\neq i}{qj}j=i,(4)其他批次内文档{dj}j≠i\{d{j}\}{j\neq i}{dj}j=i与di+d{i}^{+}di+对比,以及(5)其他批次内文档{dj}j≠i\{d_{j}\}{j\neq i}{dj}j=i与qiq{i}qi对比的相似度。mijm_{ij}mij是掩码因子,以减轻假负样本的影响:
mij={0,ifsij>s(qi,di+)+0.1ordj=di+,1,otherwise, m_{ij}=\begin{cases}0,&if s_{ij}>s(q_{i},d_{i}^{+})+0.1or d_{j}=d_{i}^{+},\\1,&otherwise,\end{cases} mij={0,1,ifsij>s(qi,di+)+0.1ordj=di+,otherwise,
其中sijs_{ij}sij表示相应的相似度分数(例如,s(qi,dj)s(q_{i}, d_{j})s(qi,dj)或s(qi,qj)s(q_{i}, q_{j})s(qi,qj))。
在阶段2,我们通过从ZiZ_{i}Zi中移除查询-查询和文档-文档项进一步修改目标。经验上,这种调整在高质量多模态检索数据上产生更好的性能。
分类数据的损失 对于文本或图像分类任务,我们同样将训练公式化为对比学习。具体而言,要分类的实例被视为查询qqq,其类别标签被视为相应的文档d+d^{+}d+。与检索相比,负样本仅限于同一查询的明确不正确标签,而忽略批次中的其他标签,以避免引入假负样本。
语义文本相似度(STS)数据 STS数据集是对称的,因此不具有自然的查询-文档不对称性。此外,监督通常以实值相似度分数的形式提供。为了利用这种细粒度信号,我们使用CoSent损失(Huang等,2024)优化模型,该损失鼓励成对嵌入之间的余弦相似度保持由真实相似度分数诱导的排序:
Lsts=log(1+∑s^(qi,dj)>s^(qm,dn)exp(cos(qm,dn)−cos(qi,dj)τ)), \mathcal{L}{\mathrm{sts}}=\log\left(1+\sum{\hat{s}(q_{i},d_{j})>\hat{s}(q_{m},d_{n})}\exp\left(\frac{\cos(q_{m},d_{n})-\cos(q_{i},d_{j})}{\tau}\right)\right), Lsts=log 1+s^(qi,dj)>s^(qm,dn)∑exp(τcos(qm,dn)−cos(qi,dj)) ,
其中s^(qi,dj)\hat{s}(q_{i},d_{j})s^(qi,dj)表示对(qi,dj)(q_{i},d_{j})(qi,dj)的真实分数。
蒸馏数据 在最后训练阶段,我们通过知识蒸馏进一步改进嵌入模型。我们从所有训练数据的并集中采样高质量子集,并使用强大的重排序器提供监督。具体而言,对于每个查询qqq,我们离线预计算其正文档和k个负样本的重排序器相关性logits。在训练期间,我们使用余弦相似度在线计算基于嵌入的分数,并最小化分布匹配目标(交叉熵),以使嵌入模型的分数分布与重排序器对齐:
Ldistill=−∑i=1k+1Preranker(di∣q)logPembedding(di∣q), \mathcal{L}{\mathrm{distill}}=-\sum{i=1}^{k+1}P_{\mathrm{reranker}}(d_{i}\mid q)\log P_{\mathrm{embedding}}(d_{i}\mid q), Ldistill=−i=1∑k+1Preranker(di∣q)logPembedding(di∣q),
其中P(di∣q)P(d_{i} \mid q)P(di∣q)是查询q的(k+1)(k+1)(k+1)个候选文档(一个正样本和k个负样本)上的softmax分布。
5.1.1 高效推理的附加技术
在实际检索系统中,索引构建需要离线存储大量嵌入。为了减少存储开销并提高检索效率,我们结合了以下辅助训练目标。
Matryoshka表示学习(MRL) 在优化上述目标时,我们不仅在完整维度嵌入上计算每个损失,还在同一表示的截断低维前缀上计算(Kusupati等,2022)。经验上,在足够密集的MRL维度集上训练会产生强大的泛化能力,使模型能够在训练过程中未明确包含的中间维度上实现竞争性能。
量化感知训练(QAT) 以较低数值精度(int8或二进制)存储嵌入可以进一步减少存储和计算开销。为了在低精度表示下保持嵌入质量,我们采用量化感知训练(QAT)策略。具体而言,在训练期间,我们使用完整精度嵌入及其低精度(量化)对应物计算优化目标,使模型学会生成对量化具有鲁棒性的嵌入。这允许学习的表示更好地适应低位嵌入格式,减轻了在部署时可能发生的性能下降。我们使用学习步长量化(LSQ)(Esser等,2020)实例化QAT。LSQ将量化比例(步长)视为可学习参数,并通过反向传播与其模型权重联合优化。此外,它使用直通估计器(STE)(Bengio等,2013)通过不可微的舍入操作传播梯度,实现模拟量化下的端到端训练。
5.2 重排序模型的损失函数
我们将重排序作为二元分类问题:给定查询-文档对,模型预测特殊yes token(相关)或no token(不相关)。
Lreranking=−logp(l∣I,q,d), \mathcal{L}_{\mathrm{reranking}}=-\log p(l|I,q,d), Lreranking=−logp(l∣I,q,d),
其中p(⋅∣∗)p(\cdot|*)p(⋅∣∗)表示VLM分配的概率。标签l对于正样本对是"yes",对于负样本是"no"。此损失函数鼓励模型为正确标签分配更高概率,从而提高排序性能(Dai等,2025)。
在推理期间,最终相关性分数通过将sigmoid函数应用于'yes'和'no'token的logits差值计算:
s=sigmoid(logit(yes)−logit(no)). s=\mathrm{sigmoid}(\mathrm{logit}(\mathrm{yes})-\mathrm{logit}(\mathrm{no})). s=sigmoid(logit(yes)−logit(no)).
6 评估
6.1 多模态基准测试
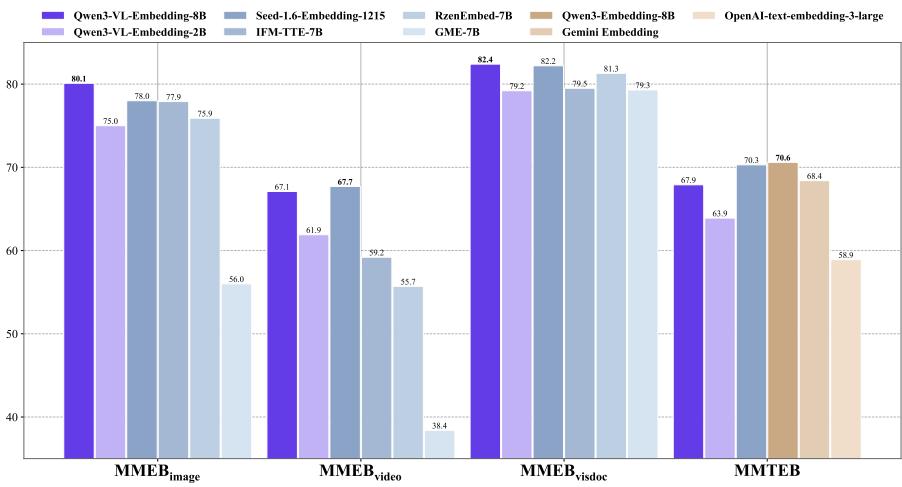
为了评估Qwen3-VL-Embedding在多模态和多任务表示学习中的整体性能,我们在MMEB-v2基准测试(Meng等,2025)上报告其结果。MMEB-v2提供了涵盖三个主要领域------图像、视频和视觉文档------的全面评估,包括九个任务类别和总共78个数据集。我们将模型与几个突出的开源和专有基线进行比较。在评估期间,上下文长度限制为16,384个token。对于基于图像的任务,最大token消耗设置为1,800,而对于基于视频的任务,我们将总token数限制在15,000,帧数限制在64。如表2总结,结果表明我们的模型在所有三个领域都达到了最先进的(SOTA)平均性能并表现出卓越能力。具体而言,Qwen3-VL-Embedding-8B在MMEB-v2上达到77.8的平均分数,比之前最好的开源模型提高了6.7%。
6.2 视觉文档基准测试
除了MMEB-V2中的评估数据集外,我们还在最新的JinaVDR(Günther等,2025)和Vidore-v33^{3}3基准测试上对视觉文档检索任务进行了进一步测试。我们将模型与当前最先进的ColPali风格模型进行比较,结果如表3所示。如图所示,我们的嵌入模型实现了与ColPali风格模型相当的性能,而后者需要显著更高的计算成本。此外,我们的重排序模型在相似参数规模下大幅超过了ColPali模型。
表2:MMEB-V2基准测试(Meng等,2025)上的结果。CLS:分类,QA:问答,RET:检索,GD:定位,MRET:片段检索,VDR:ViDoRe,VR:VisRAG,OOD:分布外。\\dagger:链接到模型主页。除IFM-TTE外,所有模型都在更新的VisDoc OOD\^{2}分割上重新评估。
|--------------------------|----|------|------|------|------|------|------|------|------|------|------|-------|-------|------|------|------|------|---|---|----|
| 模型 | 规模 | 图像 |||||| 视频 |||||| VisDoc |||||| 全部 |
| 模型 | 规模 | CLS | QA | RET | GD | 总体 | CLS | QA | RET | MRET | 总体 | VDRv1 | VDRv2 | VR | OOD | 总体 | |
| # 数据集 → | 10 | 10 | 12 | 4 | 36 | 5 | 5 | 5 | 3 | 18 | 10 | 4 | 6 | 4 | 24 | 78 |
| 开源模型 ||||||||||||||||||||
| VLM2Vec (Jiang等,2025) | 2B | 58.7 | 49.3 | 65 | 72.9 | 59.7 | 33.4 | 30.5 | 20.6 | 30.7 | 28.6 | 49.8 | 13.5 | 51.8 | 48.2 | 44 | 47.7 |
| VLM2Vec-V2 (Meng等,2025) | 2B | 62.9 | 56.3 | 69.5 | 77.3 | 64.9 | 39.3 | 34.3 | 28.8 | 36.8 | 34.6 | 75.5 | 44.9 | 79.4 | 62.2 | 69.2 | 59.2 |
| GME (Zhang等,2025b) | 2B | 54.4 | 29.9 | 66.9 | 55.5 | 51.9 | 34.9 | 42.0 | 25.6 | 31.1 | 33.6 | 86.1 | 54.0 | 82.5 | 67.5 | 76.8 | 55.3 |
| Ops-MM-embedding-v1† | 2B | 68.1 | 65.1 | 69.2 | 80.9 | 69.0 | 53.6 | 55.6 | 41.8 | 33.7 | 47.6 | 76.4 | 53.2 | 77.6 | 64.2 | 70.8 | 64.6 |
| RzenEmbed (Jian等,2025) | 2B | 68.5 | 66.3 | 74.5 | 90.3 | 72.3 | 50.4 | 49.7 | 46.6 | 38.9 | 47.3 | 87.1 | 55.1 | 87.2 | 43.4 | 74.5 | 67.2 |
| VLM2Vec (Jiang等,2025) | 8B | 62.7 | 56.9 | 69.4 | 82.2 | 65.5 | 39.1 | 30.0 | 29.0 | 38.9 | 33.7 | 56.9 | 9.4 | 59.1 | 54.0 | 49.1 | 53.1 |
| GME (Zhang等,2025b) | 8B | 57.7 | 34.7 | 71.2 | 59.3 | 56.0 | 37.4 | 50.4 | 28.4 | 37.0 | 38.4 | 89.4 | 55.6 | 85.0 | 68.3 | 79.3 | 59.1 |
| Ops-MM-embedding-v1† | 8B | 69.7 | 69.6 | 73.1 | 87.2 | 72.7 | 59.7 | 62.2 | 45.7 | 43.2 | 53.8 | 80.1 | 59.6 | 79.3 | 67.8 | 74.4 | 68.9 |
| RzenEmbed (Jian等,2025) | 8B | 70.6 | 71.7 | 78.5 | 92.1 | 75.9 | 58.8 | 63.5 | 51.0 | 45.5 | 55.7 | 89.7 | 60.7 | 88.7 | 69.9 | 81.3 | 72.9 |
| 闭源模型 ||||||||||||||||||||
| IFM-TTE† | 8B | 76.7 | 78.5 | 74.6 | 89.3 | 77.9 | 60.5 | 67.9 | 51.7 | 54.9 | 59.2 | 85.2 | 71.5 | 92.7 | 53.3 | 79.5 | 74.1 |
| Seed-1.6-embedding-0615† | - | 76.1 | 74.0 | 77.9 | 91.3 | 77.8 | 55.0 | 60.8 | 51.3 | 53.5 | 55.3 | 85.3 | 56.6 | 84.7 | 68.6 | 77.7 | 72.6 |
| Seed-1.6-embedding-1215† | - | 75.0 | 74.9 | 79.3 | 89.0 | 78.0 | 85.2 | 66.7 | 59.1 | 54.8 | 67.7 | 90.0 | 60.3 | 90.0 | 70.7 | 82.2 | 76.9 |
| Qwen3 VL Embedding模型 ||||||||||||||||||||
| Qwen3-VL-Embedding-2B | 2B | 70.3 | 74.3 | 74.8 | 88.5 | 75.0 | 71.9 | 64.9 | 53.9 | 53.3 | 61.9 | 84.4 | 65.3 | 86.4 | 69.4 | 79.2 | 73.2 |
| Qwen3-VL-Embedding-8B | 8B | 74.2 | 81.1 | 80.2 | 92.3 | 80.1 | 78.4 | 71.0 | 58.7 | 56.1 | 67.1 | 87.2 | 69.9 | 88.7 | 73.3 | 82.4 | 77.8 |
表3:视觉文档检索基准测试上的结果。所有结果均来自我们的实验运行。
|-----------------------------------------------|----|--------|-----------|-----------|-----------|-----------|---------|------|
| 模型 | 规模 | VisRAG | VisDocOOD | Vidore-v1 | Vidore-v2 | Vidore-v3 | JinaVDR | 平均 |
| llama-nemoretriever-colexbed-1b-v1 (Xu等,2025) | 1B | 82.4 | 65.6 | 90.5 | 62.1 | 55.5 | 66.4 | 70.4 |
| llama-nemoretriever-colexbed-3b-v1 (Xu等,2025) | 3B | 85.5 | 69.7 | 91.0 | 55.5 | 57.1 | 67.8 | 71.1 |
| colnomic-embed-multimodal-3b (Team,2025) | 3B | 86.8 | 71.0 | 89.7 | 63.5 | 56.4 | 77.6 | 74.2 |
| colqwen2.5-v0.2 (Faysse等,2025) | 3B | 86.6 | 70.9 | 89.5 | 59.3 | 52.4 | 75.6 | 72.4 |
| tomoro-colqwen3-embed-4b (Huang & Tan,2025) | 4B | 89.0 | 75.9 | 90.6 | 66.0 | 60.2 | 76.2 | 76.5 |
| colnomic-embed-multimodal-7b (Team,2025) | 7B | 88.7 | 75.6 | 90.0 | 62.0 | 57.6 | 78.9 | 75.5 |
| tomoro-colqwen3-embed-8b (Huang & Tan,2025) | 8B | 90.2 | 76.8 | 90.8 | 67.7 | 61.6 | 79.2 | 77.7 |
| Qwen3 VL Embedding模型 |||||||||
| Qwen3-VL-Embedding-2B | 2B | 86.3 | 74.3 | 84.4 | 65.3 | 52.9 | 71.0 | 72.2 |
| Qwen3-VL-Embedding-8B | 8B | 88.8 | 78.3 | 87.2 | 69.9 | 59.0 | 76.9 | 76.7 |
| Qwen3 VL 重排序模型 |||||||||
| Qwen3-VL-Ranker-2B | 2B | 89.7 | 77.5 | 90.3 | 62.5 | 60.8 | 80.9 | 77.0 |
| Qwen3-VL-Ranker-8B | 8B | 91.1 | 80.4 | 91.7 | 71.3 | 66.7 | 83.6 | 80.8 |
6.3 文本基准测试
表4将我们的Qwen3-VL-Embedding模型与标准纯文本嵌入模型在MMTEB(Enevoldsen等,2025b)基准测试上进行比较。与类似规模的纯文本Qwen3嵌入模型相比,Qwen3-VL-Embedding模型系列表现略低。尽管如此,Qwen3-VL-Embedding在纯文本任务上保持了有竞争力的性能。具体而言,Qwen3-VL-Embedding-8B在MMTEB上达到了67.9的平均任务得分,与类似规模的其他纯文本嵌入模型表现相当。
6.4 重排序模型评估
表5展示了各种重排序任务的评估结果。对于多模态检索,我们使用MMEB-v2套件,涵盖图像、视频(包括片段检索)和视觉文档任务。文本检索使用MMTEB进行评估,而视觉文档检索在MMEB-v2、JinaVDR和ViDoRe v3上进一步评估。为确保公平比较,我们使用Qwen3-VL-Embedding-2B检索前100个候选,然后应用重排序模型进行细化。我们的结果表明,所有三个Qwen3-VL-Reranker模型始终优于基础嵌入模型和基线重排序器,其中8B变体在大多数任务上实现了最佳性能。
表4:MTEB多语言(Enevoldsen等,2025a)上的性能。对于比较模型,分数从2025年12月25日的MTEB在线排行榜获取。
|----------------------------------------------|------|--------|--------|-------|------|------|------|-------|------|------|------|------|
| 模型 | 规模 | 平均(任务) | 平均(类型) | 双文本挖掘 | 分类 | 聚类 | 实例检索 | 多标签分类 | 对分类 | 重排序 | 检索 | STS |
| 开源模型 |||||||||||||
| KaLM-Embedding-Gemma3-12B-2511 (Zhao等,2025) | 12B | 72.3 | 62.5 | 83.8 | 77.9 | 55.8 | 5.5 | 33.0 | 84.7 | 67.3 | 75.7 | 79.0 |
| llama-embed-nemotron-8b (Babakhin等,2025) | 8B | 69.5 | 61.1 | 81.7 | 73.2 | 54.4 | 10.8 | 29.9 | 84.0 | 67.8 | 68.7 | 79.4 |
| NV-Embed-v2 Lee等 (2024) | 7B | 56.3 | 49.6 | 57.8 | 57.3 | 40.8 | 1.0 | 18.6 | 78.9 | 63.8 | 56.7 | 71.1 |
| GritLM-7B (Muennighoff等,2024) | 7B | 60.9 | 53.7 | 70.5 | 61.8 | 49.8 | 3.5 | 22.8 | 80.9 | 63.8 | 58.3 | 73.3 |
| BGE-M3 (Chen等,2024) | 0.6B | 59.6 | 52.2 | 79.1 | 60.4 | 40.9 | -3.1 | 20.1 | 80.8 | 62.8 | 54.6 | 74.1 |
| multilingual-e5-large-instruct (Wang等,2024a) | 0.6B | 63.2 | 55.1 | 80.1 | 64.9 | 50.8 | -0.4 | 22.9 | 80.9 | 62.6 | 57.1 | 76.8 |
| gte-Qwen2-1.5b-instruct (Li等,2023) | 1.5B | 59.5 | 52.7 | 62.5 | 58.3 | 52.1 | 0.74 | 24.0 | 81.6 | 62.6 | 60.8 | 71.6 |
| gte-Qwen2-7b-instruct (Li等,2023) | 7B | 62.5 | 55.9 | 73.9 | 61.6 | 52.8 | 4.9 | 25.5 | 85.1 | 65.6 | 60.1 | 74.0 |
| Qwen3-Embedding-0.6B (Zhang等,2025c) | 0.6B | 64.3 | 56.0 | 72.2 | 66.8 | 52.3 | 5.1 | 24.6 | 80.8 | 61.4 | 64.6 | 76.2 |
| Qwen3-Embedding-4B (Zhang等,2025c) | 4B | 69.5 | 60.9 | 79.4 | 72.3 | 57.2 | 11.6 | 26.8 | 85.1 | 65.1 | 69.6 | 80.9 |
| Qwen3-Embedding-8B (Zhang等,2025c) | 8B | 70.6 | 61.7 | 80.9 | 74.0 | 57.7 | 10.1 | 28.7 | 86.4 | 65.6 | 70.9 | 81.1 |
| 闭源模型 |||||||||||||
| text-embedding-3-large\\dagger | - | 58.9 | 51.4 | 62.2 | 60.3 | 46.9 | -2.7 | 22.0 | 79.2 | 63.9 | 59.3 | 71.7 |
| Cohere-embed-multilingual-v3.0\\dagger | - | 61.1 | 53.2 | 70.5 | 63.0 | 46.9 | -1.9 | 22.7 | 79.9 | 64.1 | 59.2 | 74.8 |
| Gemini Embedding (Lee等,2025) | - | 68.4 | 59.6 | 79.3 | 71.8 | 54.6 | 5.2 | 29.2 | 83.6 | 65.6 | 67.7 | 79.4 |
| Seed-1.6-embedding-1215\\dagger | - | 70.3 | 61.3 | 78.7 | 76.8 | 56.8 | -0.0 | 46.2 | 85.5 | 66.2 | 66.1 | 75.9 |
| Qwen3 VL Embedding模型 |||||||||||||
| Qwen3-VL-Embedding-2B | 2B | 63.9 | 55.8 | 69.5 | 65.9 | 52.5 | 3.9 | 26.1 | 78.5 | 64.8 | 67.1 | 74.3 |
| Qwen3-VL-Embedding-8B | 8B | 67.9 | 58.9 | 77.5 | 72.0 | 55.8 | 4.5 | 28.6 | 81.1 | 65.7 | 69.4 | 75.4 |
表5:重排序模型和基线的评估结果。所有分数均来自我们的实验运行。
|----------------------------|----|------|------|------|--------|-----------|---------|------------|
| 模型 | 规模 | MMEB-v2(检索) |||| MMTEB(检索) | JinaVDR | ViDoRe(v3) |
| 模型 | 规模 | 平均 | 图像 | 视频 | VisDoc | MMTEB(检索) | JinaVDR | ViDoRe(v3) |
| Qwen3-VL-Embedding-2B | 2B | 73.4 | 74.8 | 53.6 | 79.2 | 68.1 | 71.0 | 52.9 |
| Jina-reranker-m0\\dagger | 2B | - | 68.2 | - | 85.2 | - | 82.2 | 57.8 |
| Qwen3-VL-Reranker-2B | 2B | 75.1 | 73.8 | 52.1 | 83.4 | 70.0 | 80.9 | 60.8 |
| Qwen3-VL-Reranker-8B | 8B | 79.2 | 80.7 | 55.8 | 86.3 | 74.9 | 83.6 | 66.7 |
7 分析
7.1 Matryoshka表示学习和嵌入量化的有效性
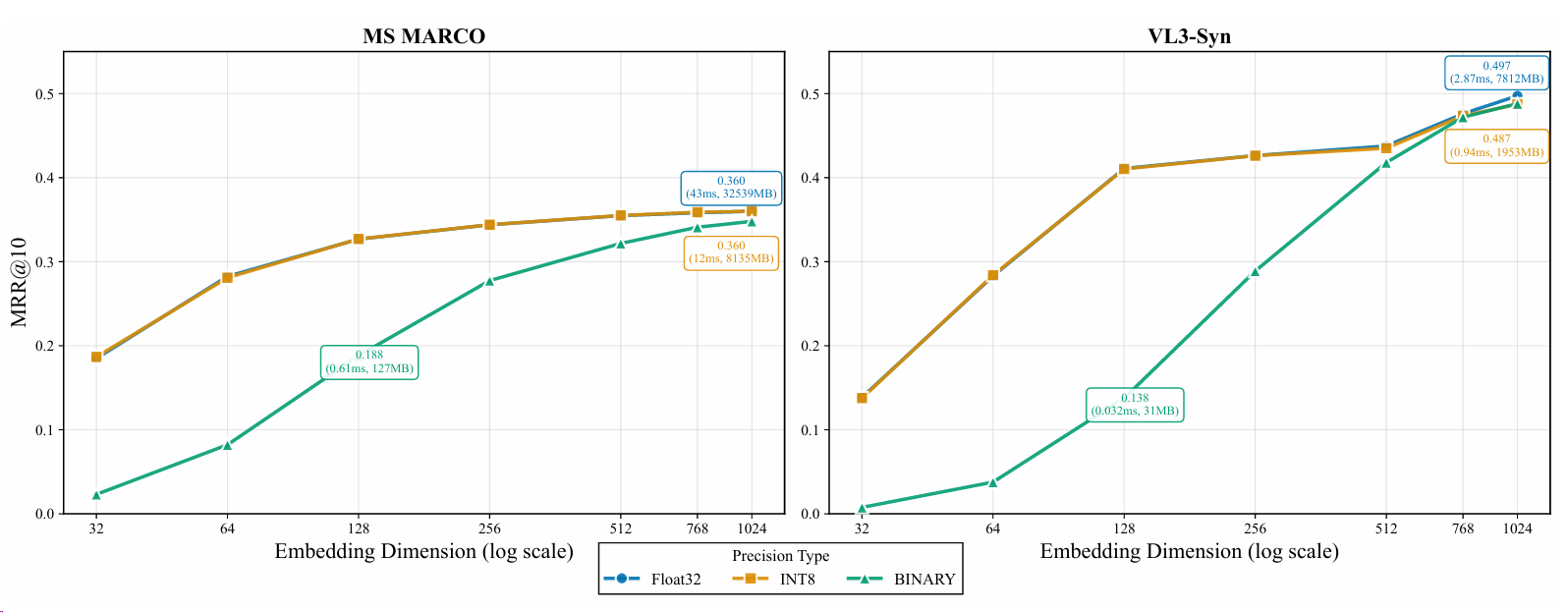
图6:不同嵌入维度和嵌入量化在MSMARCO Passage Dataset(文本到文本检索)和VL3-Syn Dataset(文本到图像检索)上的性能分析。
嵌入模型是现代检索系统的基础,涵盖单模态任务(例如,文本检索)和跨模态场景(例如,文本到图像检索)。在大规模生产环境中,语料库大小通常达到数百万甚至数十亿条目。因此,优化语料库存储需求并提高计算效率以减少检索延迟是关键挑战。Qwen3-VL-Embedding系列通过在训练流程中集成Matryoshka表示学习(MRL)和量化感知训练(QAT)来解决这些需求。
为了评估这些策略对检索性能的实际影响,我们在两个代表性任务上进行基准测试
表6:Qwen3-VL-Embedding-2B在不同训练阶段在MMEB-V2上的性能。
|------|------|------|------|------|------|------|------|------|------|------|-------|-------|------|------|------|------|
| 模型阶段 | 图像 ||||| 视频 ||||| VisDoc ||||| 全部 |
| 模型阶段 | CLS | QA | RET | GD | 总体 | CLS | QA | RET | MRET | 总体 | VDRv1 | VDRv2 | VR | OOD | 总体 | 全部 |
| s0 | 62.2 | 63.7 | 65.9 | 80.0 | 65.8 | 60.8 | 65.9 | 51.1 | 48.4 | 57.5 | 76.7 | 59.8 | 79.5 | 64.3 | 74.8 | 66.6 |
| s1 | 71.2 | 75.8 | 72.4 | 88.3 | 74.8 | 73.0 | 67.7 | 51.3 | 41.6 | 60.3 | 83.5 | 58.8 | 84.9 | 66.4 | 77.1 | 72.1 |
| s2 | 61.8 | 69.8 | 78.8 | 76.3 | 71.3 | 63.9 | 60.0 | 55.6 | 57.8 | 59.5 | 84.2 | 72.4 | 87.9 | 70.6 | 80.9 | 71.5 |
| s3 | 70.3 | 74.3 | 74.8 | 88.5 | 75.0 | 71.9 | 64.9 | 53.9 | 53.3 | 61.9 | 84.4 | 65.3 | 86.4 | 69.4 | 79.2 | 73.2 |
在两个代表性任务上。第一个是使用MSMARCO Passage Ranking数据集(Bajaj等,2016)的文本检索任务,我们采样10,000个查询,并使用训练数据集中的所有段落作为测试语料库。第二个是基于VL3-Syn(Zhang等,2025a)数据集的跨模态文本到图像检索任务,包含10,000个标题作为查询和2,000,000张图像的语料库。我们采用Qwen3-VL-Embedding-2B模型进行实验,并使用MRR@10作为主要评估指标。此外,我们对不同嵌入维度和量化方案下的索引存储开销和检索延迟进行全面分析,以展示准确性与效率之间的权衡。
如图6所示,我们在文本检索和文本到图像跨模态检索中观察到一致的模式。关于嵌入维度,检索性能随着维度减少而下降;然而,在合理范围内,考虑到存储和检索延迟的大幅节省,这种下降是可以接受的。例如,在文本检索任务中,将嵌入维度从1024减少到512仅导致检索性能下降1.4%,同时实现50%的存储减少并将检索速度提高一倍。关于嵌入量化,我们发现int8量化保持了检索性能,性能下降可忽略不计,而二进制量化显著损害了检索效果。此外,随着嵌入维度的减小,这种性能损失变得越来越明显。
7.2 空间和时间粒度的影响
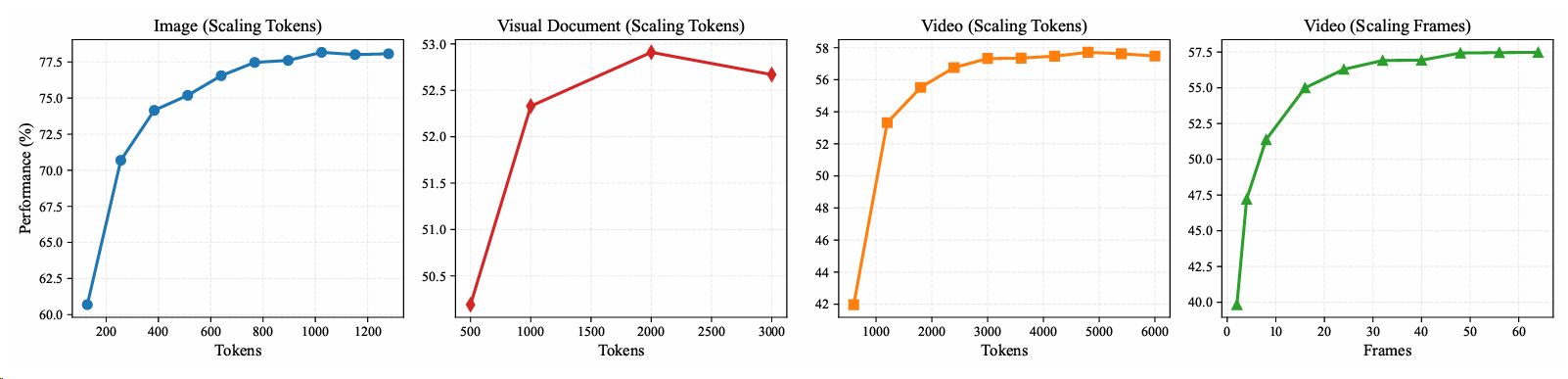
图7:视觉粒度对不同领域模型性能的影响。
在本节中,我们研究了模型性能如何随不同维度的视觉粒度扩展。具体而言,对于图像模态,我们检查了空间分辨率(以视觉token数量衡量)的影响。对于视频,我们将分析解耦为两个轴:(i)时间粒度,以帧数衡量,(ii)空间分辨率,以所有帧的总token预算量化。
我们首先分析了MMEB-v2基准测试中图像/视频分辨率和帧数的分布,从图像、视频和视觉文档领域中选择了几个高分辨率任务进行实验。结果如图7所示。我们的发现表明,在所有任务类别中,随着资源消耗的增加,性能都有所提高。然而,我们观察到随着资源分配的增长,收益递减明显,而在最高级别的消耗时,性能略有下降。这种下降的潜在解释是,当处理过长的上下文时,模型固有的性能下降。
7.3 不同训练阶段的性能
在我们的多阶段训练流水线中,总共产生了四个嵌入模型。表6详细描述了这四个2B规模模型的性能。结果表明,通过从重排序模型中蒸馏,嵌入模型在以检索为导向的任务上实现了显著的性能提升。
虽然在此过程中,其他任务类别略有下降,但最终的模型合并阶段成功地调和了这些权衡,在所有基准测试上实现了健壮和卓越的整体性能。
8 结论
在本工作中,我们介绍了Qwen3-VL-Embedding和Qwen3-VL-Reranker,这是用于多模态检索的最先进模型系列。通过将多阶段训练流水线与高质量多模态数据集成,同时最大限度地利用Qwen3-VL基础模型的多模态知识和通用理解能力,Qwen3-VL-Embedding和Qwen3-VL-Reranker模型系列在广泛的多模态检索基准测试中实现了前所未有的性能,同时保持了强大的纯文本能力。此外,通过matryoshka表示学习和量化感知训练,Qwen3-VL-Embedding系列提供了出色的实用部署特性,显著降低了下游任务的计算成本,同时保持了卓越的性能。展望未来,有前景的方向包括扩展对额外模态的支持、开发更高效的训练范式、增强组合推理能力以及建立更全面的评估协议。我们相信这些模型代表了多模态检索技术的重大进步,并希望它们将促进这一快速发展的领域的进一步创新。
A 数据集示例
表7:数据集格式示例:Docmatix\\dagger和MS-COCO (Lin等,2014)。
|------|------------------------------|
| 数据集 | Docmatrix |
| 指令 | 查找与用户问题相关的截图。 |
| 查询 (Q_{i}) ||
| q_01 | 2021年2月1日丹麦癌症协会宣布了什么类型的研究项目? |
| 语料库 (C_{i}) ||
| d_01 | |
| d_02 | |
| d_03 | |
|---------------|-------------------------------------------------|
| 相关性 (R_{i}) | {q_01: pos: d_01, neg: d_02, d_03} |
| ||
| 数据集 | MS-COCO |
| 指令 | 查找描述以下日常图像的图像标题。 |
| 查询 (Q_{i}) ||
| q_01 |  |
|
| 语料库 (C_{i}) ||
| d_01 | 一个男人在棒球场上挥舞棒球棒。 |
| d_02 | 这个男人正走在场上准备打一场棒球比赛。 |
| d_03 | 一个男孩在打棒球等待投球。 |
| 相关性 (R_{i}) | {q_01: pos: d_01, neg: d_02, d_03} |
B 数据合成提示示例
|---|---|
| 图像问答提示 ||
| 给你一张图像。你的工作是为图像问答(IQA)数据集创建一个高质量的多模态训练示例。最终答案必须是单个JSON对象,别无其他。 ||
步骤1 - 视觉描述(不超过500个{language}单词)
- 一般场景摘要和对象级细节(属性、位置、关系)。
- 上下文特征(环境、光线、动作)。
- 头脑风暴启用的推理类型(例如,空间、比较、预测)。
步骤2 - 任务选择
从下面的列表中选择一个最适合图像内容的任务类型: - 事实识别:关于特定实体、品牌或基本事实的问题
- (例如,"手表是什么品牌?")。
- 视觉推理:需要逻辑推理或分析的问题(例如,"有多少只老鼠被喂食了对照饮食?")。
- 基于OCR的数据提取:针对文本、表格或文档信息的问题(例如,"这本书的作者是谁?")。
- 领域特定知识查询:需要专业背景知识的问题
- (例如,"这是什么风格的建筑?")。
步骤3 - 填充示例
使用双引号填充下面的每个键。不要添加额外的键。
{
"description": "<步骤1输出>",
"task_type": "<步骤2中选择的任务>",
"question": "<一个以{language}表示的基于视觉的问题>",
"positive_answer": "<简洁、正确的答案,使用{language}>",
"hard_negative_answer": "<一个似是而非但具有欺骗性的错误答案,使用{language}>"
}
硬性约束: - "task_type"必须精确地从步骤2列表中选择。
- 确保问题可以直接从视觉或嵌入文本内容中回答。
- 仅输出JSON对象。
视频分类提示
给你一个视频。你的工作是为视频分类数据集创建一个高质量的多模态训练示例。
最终答案必须是单个JSON对象,别无其他。
步骤1 - 视觉分析(不超过300个{language}单词)
- 视频内容的一般概述。
- 识别主要动作、环境设置和整体事件类型。
- 头脑风暴该视频如何支持步骤2中列出的分类任务。
步骤2 - 任务选择
从下面的列表中选择一个最适合视频的任务类型: - 活动识别:识别正在执行的主要活动或动作。
- 场景解析:确定视频的主要环境或设置。
- 事件分类:将视频分类为特定事件类型或预期目的。
- 情感/意图分析:识别主导的情感基调或表达的情感。
步骤3 - 填充示例
使用双引号填充下面的每个键。不要添加额外的键。
{
"description": "<步骤1输出>",
"task_type": "<步骤2中选择的任务>",
"label": "<正确的标签,使用{language}>",
"misleading_label": "<用于困难负样本挖掘的似是而非但错误的标签,使用{language}>",
}
}
硬性约束: - "task_type"必须精确地从步骤2列表中选择。
- "description"、"label"和"misleading_label"必须使用{language}。
- 仅输出JSON对象---没有额外文本或解释。
C 模型应用与示例
在本节中,我们介绍了几个真实应用场景,以展示Qwen3-VL-Embedding的实用价值。表8至表11中的展示说明了模型如何处理多样化查询和复杂视觉数据,提供了对其在下游任务中集成的更清晰理解。
表8:Qwen3-VL-Embedding评估的相似度分数(文本任务)。
|----|-----------------------------------------------------------------------------------------|----------------------------------------------------------------------------|------|
| 任务 | AG News (Zhang等,2015) | | |
| 指令 | 对新闻文章进行分类。 | | |
| 示例 | 查询 | 文档 | 相似度 |
| 1 | 文本:关于T N养老金的担忧,经过谈判后工会代表Turner Newall的工人表示他们对与陷入困境的母公司Federal Mogul的谈判感到"失望"。 | 文本:商业 | 0.55 |
| 2 | 文本:美国战斗机中队将于下个月部署到韩国(法新社)法新社- 一支驻扎在阿拉斯加的美国空军F-15E战斗机中队将于下个月飞往韩国进行临时部署,旨在增强韩国半岛上的美国火力... | 文本:世界 | 0.57 |
| 任务 | SQuAD (Rajpurkar等,2016) | | |
| 指令 | 检索回答此问题的段落。 | | |
| 示例 | 查询 | 文档 | 相似度 |
| 1 | 文本:哪支NFL球队代表AFC参加了第50届超级碗? | 文本:第50届超级碗是一场美式橄榄球比赛,旨在确定2015赛季国家橄榄球联盟(NFL)的冠军。美国橄榄球联合会(AFC)冠军丹佛野马队击败了... | 0.81 |
| 2 | 文本:谁担任了第50届超级碗的中场秀头条? | 文本:CBS在美国转播了第50届超级碗,并在比赛期间平均收费500万美元用于30秒的广告。第50届超级碗中场秀由英国摇滚乐队Coldpl... | 0.75 |
| 任务 | MS MARCO (Lin等,2014) | | |
| 指令 | 检索相关段落。 | | |
| 示例 | 查询 | 文档 | 相似度 |
| 1 | 文本:沃尔格林商店销售平均 | 文本:沃尔格林的平均工资范围从客户服务助理/收银员每年约15,000美元到地区经理每年179,900美元。沃尔格林的平均时薪范围从... | 0.77 |
| 2 | 文本:调酒师赚多少钱 | 文本:根据劳工统计局的数据,调酒师的平均时薪为10.36美元,平均年收入为21,550美元。调酒可以是很多东西。对一些人来说,它是令人兴奋的,... | 0.81 |
表9:Qwen3-VL-Embedding评估的相似度分数(图像任务)。
|------|-------------------------------|-------|------|
| 任务指令 | CIFAR-10 (Krizhevsky等,2009) 对此图像中的对象进行分类。 |||
| 示例 | 查询 | 文档 | 相似度 |
| 1 | 图像: | 文本:猫 | 0.67 |
| 2 | 图像: | 文本:卡车 | 0.69 |
| 任务指令 | VQAv2 (Goyal等,2017) 找出关于此图像问题的答案。 |||
| 示例 | 查询 | 文档 | 相似度 |
| 1 | 文本:他看向哪里?图像: | 文本:下方 | 0.54 |
| 2 | 文本:背景中的人在做什么?图像: | 文本:观看 | 0.67 |
| 任务指令 | MS COCO (Lin等,2014) 查找与此描述匹配的图像。 |||
| 示例 | 查询 | 文档 | 相似度 |
| 1 | 文本:一个戴着红色头盔的男人在泥土路上骑着一辆小型摩托车。 | 图像: | 0.52 |
| 2 | 文本:浴室干净整洁,可以使用。 | 图像: | 0.46 |
表10:Qwen3-VL-Embedding评估的相似度分数(视频任务)。
|-----------------------------------------------------|------------------------------------------------|--------------------|------|
| 任务指令 | UCF101 (Soomro等,2012) 对此视频中的动作进行分类。 |||
| 示例 | 查询 | 文档 | 相似度 |
| 1 |  | 文本:FloorGymnastics | 0.66 |
| 文本:FloorGymnastics | 0.66 |
| 任务指令 | NExTQA (Xiao等,2021) 找出关于此视频问题的答案。 |||
| 示例 | 查询 | 文档 | 相似度 |
| 1 | 文本:为什么女孩的指甲上涂了指甲油... | 文本:(E) 看起来好看 | 0.64 |
| 视频:  | | | |
| | | |
| 任务指令 | MST-VTT (Xu等,2016) 查找与此描述匹配的视频。 |||
| 示例 | 查询 | 文档 | 相似度 |
| 1 | 文本:棒球运动员击球 | 视频: 0.80 | |
表11:Qwen3-VL-Embedding评估的相似度分数(视觉文档任务)。
|----|---------------------------------------|-----|------|
| 任务 | ViDoRe_ArxivQA (Faysse等,2025) |||
| 指令 | 查找回答此问题的文档。 |||
| 示例 | 查询 | 文档 | 相似度 |
| 1 | 文本:根据图表,纠正fspec不等于1对表面密度趋势有什么影响? | 图像: | 0.63 |
| 2 | 文本:根据从JUL10到FEB11Q的进展,可以观察到线程参与的什么趋势? | 图像: | 0.55 |