目录
- [Upstash Vector 简介](#Upstash Vector 简介)
- 创建索引
- 操作指令介绍
-
- [连接 Index](#连接 Index)
-
- 方式一:使用环境变量(推荐)
- 方式二:直接在代码中指定
- [Index 和 Namespace 的区别](#Index 和 Namespace 的区别)
- [Upsert 插入向量](#Upsert 插入向量)
- [Query 查询向量](#Query 查询向量)
- [Resumable Query 可恢复查询](#Resumable Query 可恢复查询)
- [Range 范围查询](#Range 范围查询)
- [Fetch 按 ID 获取向量](#Fetch 按 ID 获取向量)
-
- 基本用法
- [Fetch vs Query vs Range](#Fetch vs Query vs Range)
- [Delete 删除向量](#Delete 删除向量)
- [Update 更新向量](#Update 更新向量)
- [Reset 重置索引](#Reset 重置索引)
- [Info 获取索引信息](#Info 获取索引信息)
Upstash Vector 简介
Upstash Vector 是一个托管式向量数据库服务,专为 AI 应用提供高性能的向量存储和相似性搜索能力。
什么是索引?
在 Upstash Vector 中,索引(Index) 是一个独立的向量数据库实例。你可以把它理解为一个容器,用来存储你的向量数据及其关联的元数据。每个索引需要指定:
- 维度数:向量的维度大小(例如 OpenAI 的 text-embedding-3-small 模型使用 1536 维)
- 距离度量:用于相似性搜索的算法(如余弦相似度)
你可以为不同的应用或用途创建多个索引,例如一个用于产品搜索,另一个用于文档检索。
免费版容量限制
- 索引数量:每个账户可创建 1 个索引
- 向量维度:最大维度 1536
- 向量数量:最大 2 亿(向量数 × 维度数,例如:130 万向量 × 1536 维度)
- 元数据和数据存储:最大 1GB(每个向量最多 48KB 元数据,1MB 数据)
- 每日查询/更新限制:10,000 次
核心功能
- 支持的功能
- ✅ 元数据过滤:支持基于元数据字段进行过滤查询
- ✅ 批量操作:支持批量插入,建议每次最多 1000 个向量
- ✅ 自动 ID 管理:需要手动指定 ID(不能为空字符串)
- 暂不支持的功能
- ❌ 混合搜索:目前不支持,但已在路线图中。混合搜索结合向量搜索和关键词搜索,能提供更精准的搜索结果
付费版信息
如需了解付费版(按需付费版、固定版、Pro 版)的详细定价和功能,请查看 Upstash Vector 官方定价页面。
创建索引
进入Upstash Vector 页面后,点击Create Vector Index,显示如下:
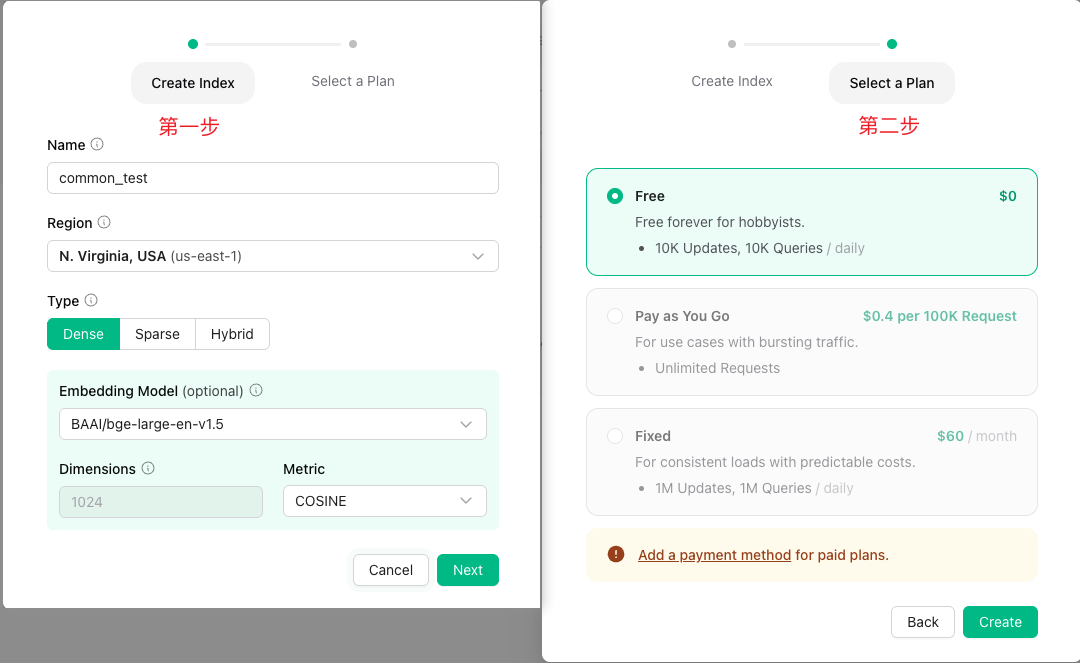
- 输入索引名称
- 选择数据库所在区域(仅支持几个区域,随便选一个就行)
- 向量检索类型,包括 稠密向量/稀疏向量/混合向量
- 选择embedding模型,你可以选择Custom自己配置模型,也可以使用upstash预置的几个模型。
- 输入向量维度,如果选择预置模型,会根据模型类型自动匹配向量维度,否则需要自己输入。
- 向量检索方式:包括 cosine(余弦相似度)、euclidean(欧氏距离)、dot_product(点积)
- Cosine:通过计算两个向量之间的夹角余弦值来衡量相似度,取值范围为 -1 到 1。值越接近 1 表示向量方向越相似,不受向量长度影响。适合用于文本相似度搜索,因为更关注向量的方向而非大小。
- Euclidean:计算两个向量在空间中的直线距离,距离越小表示越相似。这是最直观的距离度量方式,适合用于需要精确距离测量的场景,如图像相似度搜索。
- Dot Product:计算两个向量的内积,值越大表示越相似。点积同时考虑了向量的方向和大小,适合用于归一化后的向量,或者需要同时考虑向量方向和长度的场景。
- 选择付费方式,直接免费版就行了。
操作指令介绍
Python 使用要先安装 upstash-vector 包,运行 pip install upstash-vector
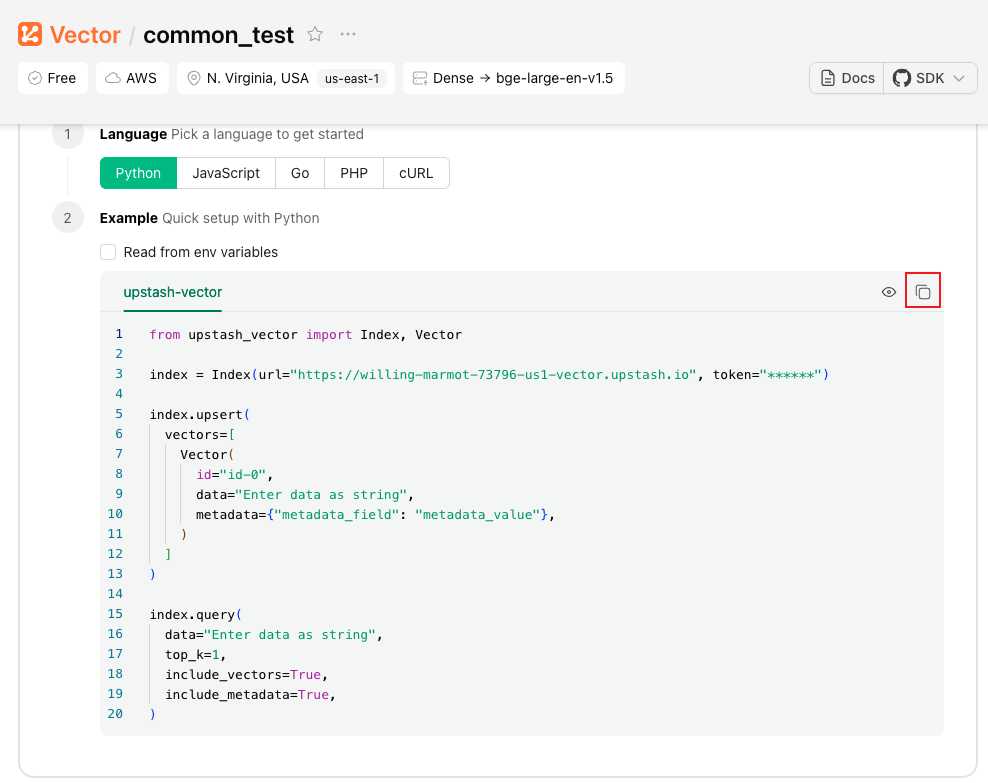
点击创建的索引,可以进入索引详情页,这里给了使用示例,直接复制代码,可以自动填充url和token。
连接 Index
连接 Index 有两种方式:使用环境变量或直接在代码中指定 URL 和 Token。
方式一:使用环境变量(推荐)
首先设置环境变量:
bash
export UPSTASH_VECTOR_REST_URL="https://xxx.upstash.io"
export UPSTASH_VECTOR_REST_TOKEN="xxx"或者在 Python 代码中设置:
python
import os
from upstash_vector import Index
os.environ["UPSTASH_VECTOR_REST_URL"] = "https://xxx.upstash.io"
os.environ["UPSTASH_VECTOR_REST_TOKEN"] = "xxx"
# 从环境变量创建 Index
index = Index.from_env()方式二:直接在代码中指定
python
from upstash_vector import Index
# 直接传入 URL 和 Token
index = Index(
url="https://xxx.upstash.io",
token="xxx"
)Index 和 Namespace 的区别
- Index:类似 MySQL 的数据库,是顶层容器,每个 Index 有固定的配置(维度数、距离度量等)
- Namespace:类似 MySQL 的表,是在同一个 Index 内的逻辑分区,用于组织不同类型的数据
如果不指定 namespace,则使用默认 namespace(空字符串 "")。所有操作(插入、查询、删除等)都可以通过 namespace 参数指定目标命名空间。
python
from upstash_vector import Index
# 创建一个 Index 连接(相当于连接一个数据库)
index = Index(url="https://xxx.upstash.io", token="xxx")
# 在同一个 Index 中,使用不同的 namespace 组织数据
index.upsert(vectors=[...], namespace="products") # 产品数据
index.upsert(vectors=[...], namespace="documents") # 文档数据
# 查询时也需要指定 namespace
results = index.query(vector=[...], namespace="products")Upsert 插入向量
upsert 是 Upstash Vector 中最常用的操作,用于插入或更新向量。如果向量 ID 已存在则更新,不存在则插入。
Upstash Vector 支持三种方式插入向量:使用 Vector 对象、元组(tuple)或字典(dictionary)。
python
from upstash_vector import Index, Vector
index = Index.from_env() # 从环境变量读取 URL 和 Token
# 1. 使用 Vector 对象
vectors = [
Vector(
id="vector-1", # 向量 ID(必填,不能为空字符串)
vector=[0.1, 0.2, 0.3, ...], # 向量数据(条件必填,根据是否选择了upstash的预置模型)
metadata={"category": "tech"}, # 元数据(可选,字典格式,最多 48KB)
data="这是原始文本数据" # 原始数据(可选,字符串格式,最多 1MB)
)
]
# 2. 使用元组, 顺序为:`(id, vector, metadata, data)`,其中 metadata 和 data 可以省略。
vectors = [
(
"vector-1", # id
[0.1, 0.2, 0.3, ...], # vector
{"category": "tech"}, # metadata
"这是原始文本数据" # data
)
]
# 3. 使用字典
vectors = [
{
"id": "vector-1",
"vector": [0.1, 0.2, 0.3, ...],
"metadata": {"category": "tech"},
"data": "这是原始文本数据"
}
]
index.upsert(
vectors=vectors,
namespace="test1" # 可选,指定命名空间,默认 default
)字段说明:
- id(必填):向量的唯一标识符,字符串类型,不能为空。如果已存在相同 ID 的向量,则会更新该向量
- vector (条件必填):向量数据,列表格式,每个元素是浮点数。维度必须与创建索引时指定的维度一致
- 如果创建索引时选择了 Custom (自定义模型),则必须提供
vector - 如果创建索引时选择了 Upstash 预置模型 ,可以不提供
vector,只需提供data,Upstash 会自动使用创建索引时选择的 embedding 模型将data中的文本转换为向量
- 如果创建索引时选择了 Custom (自定义模型),则必须提供
- data (条件必填):原始的非结构化数据,字符串格式,最多 1MB
- 如果创建索引时选择了 Upstash 预置模型 ,必须提供
data(文本),Upstash 会根据创建索引时选择的模型自动将文本转换为向量 - 如果创建索引时选择了 Custom ,
data是可选的,通常用于存储原始文本、图片 URL 等
- 如果创建索引时选择了 Upstash 预置模型 ,必须提供
- metadata(可选):元数据字典,用于存储额外的结构化信息,最多 48KB。常用于存储过滤条件,如分类、标签等
使用场景示例:
python
# 场景1:使用 Upstash 预置模型(创建索引时选择了预置模型)
# 只需提供 data,不需要提供 vector
vectors = [
Vector(
id="text-1",
data="这是一段需要搜索的文本内容", # Upstash 会自动转换为向量
metadata={"category": "tech"}
)
]
# 场景2:使用自定义模型(创建索引时选择了 Custom)
# 必须提供 vector,data 可选
vectors = [
Vector(
id="vector-1",
vector=[0.1, 0.2, 0.3, ...], # 自己生成的向量
data="这是原始文本数据", # 可选,用于存储原始文本
metadata={"category": "tech"}
)
]Query 查询向量
query 是 Upstash Vector 中用于检索向量的核心操作,根据相似度搜索返回最匹配的向量。
基本用法
python
from upstash_vector import Index
index = Index.from_env()
# 使用向量查询
query_result = index.query(
vector=[0.1, 0.2, 0.3, ...], # 查询向量
top_k=5, # 返回前 5 个最相似的结果
include_metadata=True, # 包含元数据
include_data=True, # 包含原始数据
include_vectors=False, # 不包含向量本身(节省带宽)
namespace="products" # 指定命名空间
)
# 遍历结果
for result in query_result:
print(f"ID: {result.id}")
print(f"相似度分数: {result.score}") # 0-1 之间,1 表示完全匹配
print(f"元数据: {result.metadata}")
print(f"数据: {result.data}")参数说明
-
查询方式(三选一)
- vector:使用向量进行相似度搜索,传入与索引维度相同的向量列表
- data :使用文本进行查询(需要索引配置了 Upstash 内置的 embedding 模型),与
vector互斥 - sparse_vector:使用稀疏向量进行查询(用于稀疏向量索引)
-
返回结果控制
- include_metadata (布尔值):是否在结果中包含元数据,默认为
False - include_vector (布尔值):是否在结果中包含向量本身,默认为
False。设置为True会增加响应大小 - include_data (布尔值):是否在结果中包含原始数据,默认为
False
- include_metadata (布尔值):是否在结果中包含元数据,默认为
-
其他参数:
- top_k (整数):返回最相似的前 k 个结果,例如
top_k=5返回前 5 个最匹配的向量 - filter (字符串):元数据过滤条件,用于缩小查询范围。例如:
filter="category = 'electronics' and price > 100" - namespace(字符串):指定查询的命名空间,不指定则使用默认 namespace
- top_k (整数):返回最相似的前 k 个结果,例如
-
返回结果字段
- id:向量的唯一标识符
- score:相似度分数,范围 0, 1,1 表示完全匹配
- metadata :元数据字典(如果
include_metadata=True) - vector :向量本身(如果
include_vector=True) - data :原始数据(如果
include_data=True)
使用文本查询(需要内置 Embedding 模型)
如果创建索引时选择了 Upstash 预置的 embedding 模型,可以直接使用文本进行查询:
python
# 使用文本查询(自动转换为向量)
query_result = index.query(
data="查找相似的产品描述", # 直接传入文本
top_k=5,
include_metadata=True,
include_data=True
)使用元数据过滤
可以通过 filter 参数对元数据进行过滤,支持多种条件:
python
query_result = index.query(
vector=[0.1, 0.2, 0.3, ...],
top_k=10,
filter="category = 'electronics' and price > 100 and brand = 'Apple'",
include_metadata=True
)过滤语法:
- 等于:
field = 'value' - 不等于:
field != 'value' - 大于/小于:
field > 100、field < 100 - 逻辑运算:
AND、OR - 字符串匹配:使用单引号包裹字符串值
批量查询
使用 query_many 方法可以一次性执行多个查询,减少网络往返:
python
query_results = index.query_many(
queries=[
{
"vector": [0.1, 0.2, 0.3, ...],
"top_k": 5,
"include_metadata": True,
"filter": "category = 'electronics'"
},
{
"vector": [0.4, 0.5, 0.6, ...],
"top_k": 3,
"include_metadata": False,
"filter": "category = 'books'"
}
]
)
# 遍历每个查询的结果
for i, query_result in enumerate(query_results):
print(f"查询 {i+1} 的结果:")
for result in query_result:
print(f" ID: {result.id}, 分数: {result.score}")Resumable Query 可恢复查询
resumable_query 是一种懒加载的查询方式,运行分批返回结果,防止一次性加载到内存中,导致内存压力过大。
例如在用户手机搜索时,先展示前10个相关的内容,用户滚动时,可再加载10个。
基本用法
python
from upstash_vector import Index
index = Index.from_env()
# 开始一个可恢复查询,返回初始结果和句柄
# resumable_query参数与query相同
results, handle = index.resumable_query(
data="今天是个好日子",
top_k=10, # 初始批次返回 10 个结果
include_metadata=True,
include_vectors=False,
namespace="test1"
)
all_results = []
with handle:
# 获取第一页
all_results.extend(results)
# 继续获取后续页面
while True:
next_batch = handle.fetch_next(10)
if not next_batch: # 没有更多结果
break
all_results.extend(next_batch)
print(f"总共获取了 {len(all_results)} 个结果")
# 退出 with 块后,句柄会自动停止工作原理
-
初始调用 :
resumable_query返回一个元组(results, handle),其中:results:第一批查询结果(列表)handle:ResumableQueryHandle对象,用于获取更多结果
-
获取更多结果 :使用
handle.fetch_next(n)获取接下来的n个结果- 如果还有更多结果,返回结果列表
- 如果没有更多结果,返回空列表
-
关闭句柄:必须在使用完毕后关闭句柄:
- 使用
with handle:上下文管理器(推荐) - 或手动调用
handle.stop()
- 使用
Range 范围查询
range 方法允许你按顺序检索索引中的向量 ,而不是基于相似度搜索。这对于遍历所有向量 、按 ID 前缀查找 或数据导出等场景非常有用。
python
from upstash_vector import Index
index = Index.from_env()
next_cursor = 'first'
while next_cursor != "":
# 执行范围查询
next_cursor if next_cursor != 'first' else ""
range_result = index.range(
cursor=next_cursor, # 游标,从空字符串开始
limit=10, # 每次返回的最大向量数量
include_vectors=False, # 是否包含向量本身
include_metadata=True, # 是否包含元数据
include_data=True, # 是否包含原始数据
namespace="products" # 可选,指定命名空间
)
next_cursor = res.next_cursor
for vector_info in res.vectors:
print(f"游标: {next_cursor}")
print(f"ID: {vector_info.id}")
print(f"数据: {vector_info.data}")
print(f"元数据: {vector_info.metadata}")-
参数说明
- cursor (字符串):游标位置,用于分页。第一次查询使用空字符串
"",后续使用上次返回的next_cursor - limit(整数):单次查询返回的最大向量数量
- prefix (字符串,可选):ID 前缀过滤,只返回 ID 以该前缀开头的向量,例如
prefix="product-"
- cursor (字符串):游标位置,用于分页。第一次查询使用空字符串
-
返回结果
- next_cursor :下一个查询的游标位置。如果为空字符串
"",表示没有更多结果了 - vectors:向量列表,每个向量包含:
id:向量 IDvector:向量数据(如果include_vectors=True)metadata:元数据(如果include_metadata=True)data:原始数据(如果include_data=True)
- next_cursor :下一个查询的游标位置。如果为空字符串
Fetch 按 ID 获取向量
fetch 方法允许你根据向量 ID 直接获取向量,不需要进行相似度搜索。这对于已知 ID 需要获取完整向量信息的场景非常有用。
基本用法
python
from upstash_vector import Index
index = Index.from_env()
# 方式1:获取多个向量(传入列表)
ids_to_fetch = ["id-1", "id-2", "id-3"]
fetch_result = index.fetch(
ids=ids_to_fetch,
include_vectors=True,
include_metadata=True,
include_data=True,
namespace="products" # 可选,指定命名空间
)
# 遍历结果
for vector_info in fetch_result:
print(f"ID: {vector_info.id}")
print(f"向量: {vector_info.vector}")
print(f"元数据: {vector_info.metadata}")
print(f"数据: {vector_info.data}")
# 方式2:获取单个向量(直接传入字符串)
vector_info = index.fetch("id-4", namespace="products")
print(f"ID: {vector_info[0].id}")-
参数说明
- ids(字符串或列表):要获取的向量 ID,可以是单个字符串或字符串列表
- prefix (字符串,可选):ID 前缀过滤,获取所有 ID 以该前缀开头的向量,例如
prefix="product-"
-
返回结果
- vectors:向量列表,每个向量包含:
id:向量 IDvector:向量数据(如果include_vectors=True)sparse_vector:稀疏向量(如果适用)metadata:元数据(如果include_metadata=True)data:原始数据(如果include_data=True)
Fetch vs Query vs Range
| 特性 | Fetch | Query | Range |
|---|---|---|---|
| 用途 | 按 ID 获取 | 相似度搜索 | 按顺序遍历 |
| 输入 | 向量 ID | 查询向量 | 游标 |
| 排序 | 无排序 | 按相似度排序 | 按 ID 顺序 |
| 适用场景 | 已知 ID 获取数据 | 相似度搜索 | 遍历所有数据 |
总结:Fetch 是直接按 ID 获取向量的方法,适合已知向量 ID 需要获取完整信息的场景,与 Query(相似度搜索)和 Range(顺序遍历)形成互补。
Delete 删除向量
delete 方法允许你根据向量 ID、ID 前缀或元数据过滤条件删除向量 。删除操作是不可逆的,请谨慎使用。
基本用法
python
from upstash_vector import Index
index = Index.from_env()
# 方式1:删除多个向量(传入列表)
ids_to_delete = ["id-1", "id-2", "id-3"]
delete_result = index.delete(
ids=ids_to_delete,
namespace="products" # 可选,指定命名空间
)
# 显示删除的向量数量
print(f"删除了 {delete_result.deleted} 个向量")
# 方式2:删除单个向量(直接传入字符串)
delete_result = index.delete("id-4", namespace="products")
print(f"删除了 {delete_result.deleted} 个向量")- 参数说明(三选一,不可同时使用)
- ids(字符串或列表):要删除的向量 ID,可以是单个字符串或字符串列表
- prefix (字符串):ID 前缀过滤,删除所有 ID 以该前缀开头的向量,例如
prefix="product-" - filter (字符串):元数据过滤条件,删除所有匹配过滤条件的向量,例如
filter="age > 30"
- 返回结果
- deleted(整数):被删除的向量数量
注意事项
- 不可逆操作 :删除操作是永久性的,无法恢复,请谨慎使用
- 批量删除 :使用
prefix或filter删除大量向量时,建议先使用fetch或range确认要删除的向量 - 命名空间:删除操作会作用于指定的 namespace,如果不指定则使用默认 namespace
安全删除示例
python
# 先查询要删除的向量,确认后再删除
vectors_to_delete = index.fetch(prefix="temp-", namespace="products")
print(f"找到 {len(vectors_to_delete)} 个临时向量")
# 确认后删除
if len(vectors_to_delete) > 0:
delete_result = index.delete(prefix="temp-", namespace="products")
print(f"已删除 {delete_result.deleted} 个向量")
else:
print("没有需要删除的向量")Update 更新向量
update 方法允许你更新已存在向量的向量数据、元数据或原始数据。如果向量不存在,更新操作不会创建新向量。
基本用法
python
from upstash_vector import Index
index = Index.from_env()
# 更新向量的元数据和原始数据
updated = index.update(
id="id-1",
metadata={"category": "electronics", "price": 999}, # 更新元数据
data="更新后的产品描述", # 更新原始数据
namespace="products" # 可选,指定命名空间
)
print(updated)-
参数说明
- id(字符串,必填):要更新的向量 ID
- vector(列表,可选):新的向量数据,维度必须与索引配置一致
- metadata (字典,可选):新的元数据,会完全替换原有的元数据
- data(字符串,可选):新的原始数据
- metadata_update_mode (可选):元数据更新模式,默认为
REPLACE(完全替换),可选PATCH(部分更新) - namespace(字符串,可选):指定操作的命名空间,不指定则使用默认 namespace
-
返回结果
- 返回更新后的向量信息
更新模式
Update 支持两种元数据更新模式:
1. REPLACE 模式(默认)
完全替换元数据,原有的元数据字段会被新值覆盖:
python
# 假设原向量有元数据:{"category": "electronics", "price": 100, "brand": "Apple"}
# 使用 REPLACE 模式(默认)
updated = index.update(
id="id-1",
metadata={"category": "phones", "price": 200} # 只保留这两个字段,brand 会被删除
)2. PATCH 模式(部分更新)
根据 JSON Merge Patch 算法,可以部分更新、添加或删除元数据字段:
python
from upstash_vector import Index
from upstash_vector.types import MetadataUpdateMode
index = Index.from_env()
# 假设原向量有元数据:{"category": "electronics", "price": 100, "brand": "Apple"}
# 使用 PATCH 模式
updated = index.update(
id="id-1",
metadata={
"price": 200, # 更新现有字段
"brand": None, # 删除字段(设置为 None)
"color": "black" # 添加新字段
},
metadata_update_mode=MetadataUpdateMode.PATCH
)PATCH 模式规则:
- 存在的字段:更新为新值
- 不存在的字段:添加新字段
- 设置为
None的字段:删除该字段 - 未在 metadata 中出现的字段:保持不变
Reset 重置索引
reset 用来清空索引中的数据,可以清空默认命名空间、指定命名空间,或者整个 Index 下的所有命名空间(相当于把这个向量库重置为"刚创建"的状态)。
python
from upstash_vector import Index
index = Index.from_env()
# 1. 重置默认 namespace(不传参数)
index.reset()
# 2. 只重置某个命名空间
index.reset(namespace="products")
# 3. 重置整个索引下的所有 namespace,慎用!
index.reset(all=True)Info 获取索引信息
info 方法用于获取索引的统计信息和元数据,包括向量数量、索引大小、维度、相似度函数等。这对于监控索引状态、了解数据规模非常有用。
python
from upstash_vector import Index
index = Index.from_env()
# 获取索引的统计信息
info_result = index.info()
# 显示索引整体信息
print(f"向量总数: {info_result.vector_count}")
print(f"待处理向量数: {info_result.pending_vector_count}")
print(f"索引大小: {info_result.index_size} 字节")
print(f"向量维度: {info_result.dimension}")
print(f"相似度函数: {info_result.similarity_function}")
# 遍历所有 namespace 的统计信息
for ns_name, ns_info in info_result.namespaces.items():
print(f"\n命名空间: {ns_name}")
print(f" 向量数量: {ns_info.vector_count}")
print(f" 待处理向量数: {ns_info.pending_vector_count}")返回结果字段
- vector_count(整数):索引中向量的总数量
- pending_vector_count(整数):当前待处理的向量数量(尚未完全处理/索引的向量)
- index_size(整数):索引在磁盘上的大小(字节)
- dimension(整数):索引配置的向量维度数
- similarity_function(字符串):索引使用的相似度函数(如 "cosine"、"euclidean"、"dot_product")
- namespaces (字典):所有命名空间的统计信息映射,键为命名空间名称,值为包含以下字段的对象:
vector_count:该命名空间中的向量数量pending_vector_count:该命名空间中待处理的向量数量