1.单表查询
1.1基础查询
语法:SELECT 字段名1,字段名2 FROM 表名;
SELECT * FROM user1; -查询user1所有字段
SELECT id,name FROM user1; -查询user1指定字段
SELECT name AS "姓名" FROM user1; -查询name字段以"姓名"显示1.2条件查询WHERE
普通查询
SELECT 字段1,字段2.. FROM 表名 WHERE 条件; -条件查询
SELECT 字段1,字段2.. FROM 表名 WHERE 条件1 AND 条件2; -AND条件查询
SELECT 字段1,字段2.. FROM 表名 WHERE 条件1 OR 条件2; -OR条件查询
SELECT 字段1,字段2.. FROM 表名 WHERE 字段1=条件1; -=精确条件查询
SELECT id FROM user1 WHERE id>5; -查询id大于5的值
SELECT id,name FROM user1 WHERE id>=5 AND name="jack"; -查询id大于等于5且name等于jack的值
SELECT id,name FROM user1 WHERE id<=5 OR name!="jack"; -查询id小于等于5或者name不等于jack的值模糊查询
通配符:
%:匹配任意多个字符(包括0)
_:匹配单个字符
SELECT 字段1,字段2.. FROM 表名 WHERE 字段1 LIKE "x__x"; -_匹配单个字符
SELECT 字段1,字段2.. FROM 表名 WHERE 字段1 LIKE "x%"; -%配比任意多个字符
SELECT id,name FROM user1 WHERE name LIKE "j__K"; -模糊查询name字段形如"j__k"的值
SELECT id,name FROM user1 WHERE name LIKE "j%"; -模糊查询name字段以j开头的值正则查询
^:以什么开头
$:以什么结尾
+:前导符出现一次或多次
|:或者
SELECT 字段1,字段2.. FROM 表名 WHERE 字段1 RLIKE "^x"; -^以x开头
SELECT 字段1,字段2.. FROM 表名 WHERE 字段1 RLIKE "x"; -以x结尾
SELECT 字段1,字段2.. FROM 表名 WHERE 字段1 RLIKE "x+"; -+前导符出现任意次
SELECT 字段1,字段2.. FROM 表名 WHERE 字段1 RLIKE "x|y"; -|或
SELECT id,name FROM user1 WHERE name RLIKE "^j"; -正则查询以j开头的值
SELECT id,name FROM user1 WHERE name RLIKE "K$"; -正则查询以k结尾的值
SELECT id,name FROM user1 WHERE name RLIKE "ja+ck"; -正则查询以j开头,任意a个数,ck结尾的值
SELECT id,name FROM user1 WHERE name RLIKE "jack|tom"; -正则查询jack或者tom去重
SELECT DISTINCT 字段1,字段2.. FROM 表名; -去除字段重复值
SELECT DISTINCT name FROM user1; -去重查询name字段1.3范围查询BETWEEN AND|IN
BETWEEN查询
SELECT 字段1,字段2.. FROM 表名 WHERE 字段1 BETWEEN 值1 AND 值2;
SELECT 字段1,字段2.. FROM 表名 WHERE 字段1 NOT BETWEEN 值1 AND 值2;
SELECT num FROM user1 WHERE num BETWEEN 5000 AND 6000; -查询num字段值在5000-6000的值
SELECT num FROM user2 WHERE num NOT BETWEEN 5000 AND 6000; -查询num字段值不在5000-6000的值条件取反
SELECT 字段1,字段2.. FROM 表名 WHERE NOT 字段1 比较符号 值;
SELECT num FROM user1 WHERE NOT num > 5000; -查询num不大于5000的值IN集合查询
SELECT 字段1,字段2.. FROM 表名 WHERE 字段1 IN (值1,值2,值3...);
SELECT 字段1,字段2.. FROM 表名 WHERE 字段1 NOT IN (值1,值2,值3...);
SELECT num FROM user1 WHERE num IN (100,300,700); -查询num值为100,300,700的值
SELECT num FROM user1 WHERE num NOT IN (100,300,700); --查询num值不为100,300,700的值1.4空值查询
SELECT 字段名1,字段名2 FROM 表名 WHERE 字段名 IS NULL;
SELECT 字段名1,字段名2 FROM 表名 WHERE 字段名 IS NOT NULL;
SELECT num FROM user1 WHERE num IS NULL; -查询num字段为NULL的值
SELECT num FROM user1 WHERE num IS NOT NULL; -查询num字段不为NULL的值1.5排序查询
SELECT 字段名 FROM 表名 ORDER BY 字段名 ASC; -ASC升序
SELECT 字段名 FROM 表名 ORDER BY 字段名 DESC; -DESC降序
单列排序
SELECT num FROM user1 ORDER BY num ASC; -ASC升序
SELECT num FROM user1 ORDER BY num DESC; -DESC降序多列排序
在对多列进行排序的时候,首先排序的第一列必须有相同的列值,才会对第二列进行排序。如果第 一列数据中所有值都是唯一的,将不再对第二列进行排序
SELECT * FROM user1 ORDER BY num1 DESC,num2 ASC; -多列排序num1降序,num2升序别名排序
SELECT *,(对字段计算)AS 别名 FROM 表名 ORDER BY 别名 ASC/DESC; -别名不能加引号,写中文
SELECT *,(salary * 0.1) AS salary_bonus FROM employees ORDER BY salary_bonus ASC;1.6限制-LIMIT
SELECT 字段名 FROM 表名 LIMIT 显示行数;
SELECT 字段名 FROM 表名 LIMIT a,b; -从第a行开始(不包含第a行),向下显示b行
SELECT * FROM employee LIMIT 5; -只显示5行
SELECT * FROM employee5 ORDER BY salary DESC LIMIT 4,5;
-降序排序salary字段从第四行开始(不包含第四行),向下显示五行1.7分组查询-GROUP BY
SELECT 字段名 FROM 组名 GROUP BY 字段名 -以字段分组
1.补充COUNT()-统计函数
SELECT COUNT(字段名) FROM 表名; -统计该字段名的行数
SELECT COUNT(name) FROM user WHERE salary > 5000; -以salary分组查询大于5000的人数2.补充COALESEC(字段名,'取代空值的名')&IFNULL(字段名,'取代空值的值') 来设置一个可以取代 NUlLL的名称
分组查询表user1下的name字段的总和并将name字段空值改为total
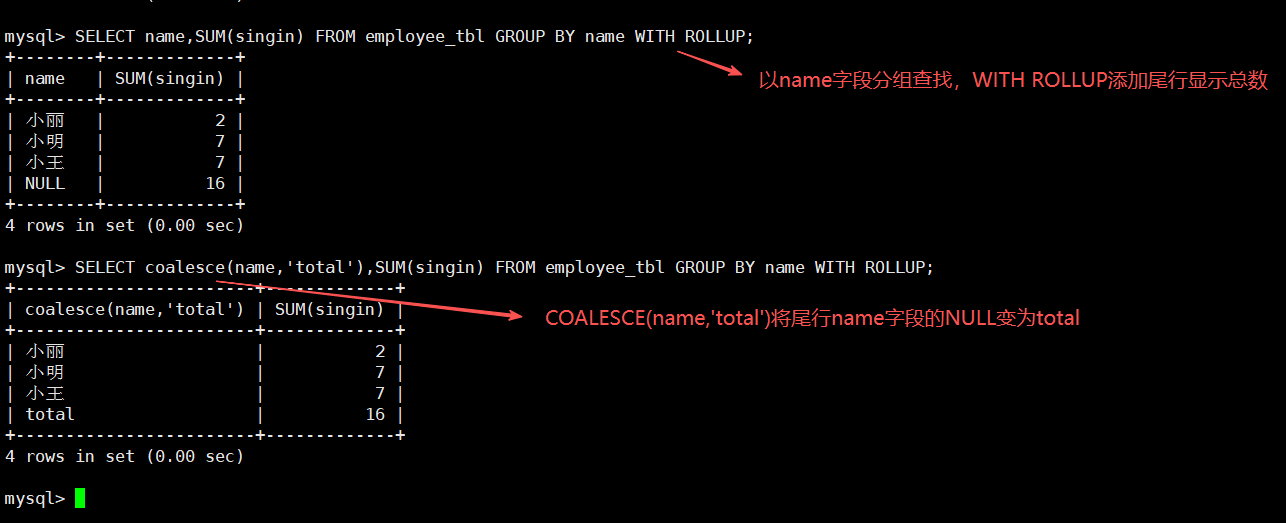
SELECT COALESCE(name,'total'),SUM(name) FROM user1 GROUP BY name WITH ROLLUP;
SELECT IFNULL(name,'total'),SUM(name) FROM user1 GROUP BY name WITH ROLLUP;1.7.1WITH ROLLUP(侧重点)
WITH ROLLUP 可以实现在分组统计数据基础上再进行相同的统(SUM,AVG,COUNT...)。
1.7.2GROUP BY和GROUP_CONCAT()函数结合
GROUP_CONCAT()-用于显示组中具体内容
SELECT dep_id,GROUP_CONCAT(name) FROM employee5 GROUP BY dep_id;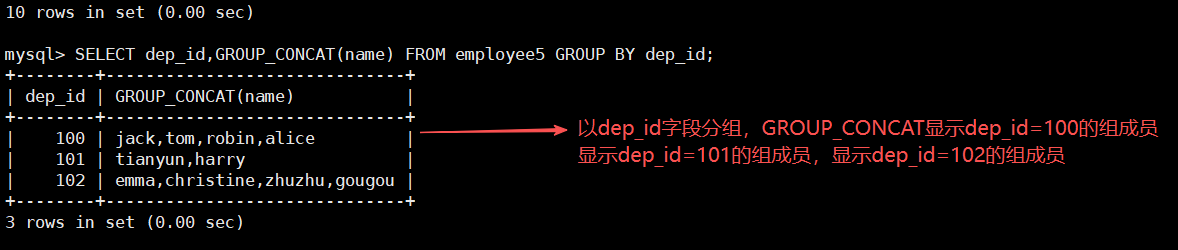
SELECT dep_id,COUNT(name),GROUP_CONCAT(name) FROM employee5 GROUP BY dep_id;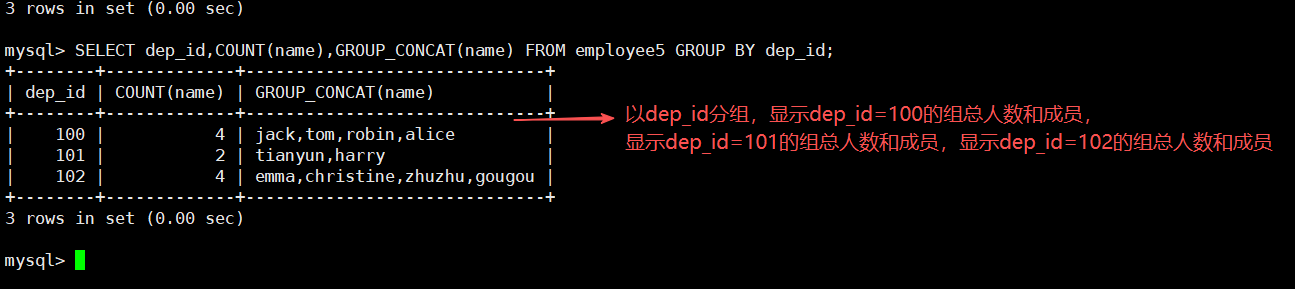
SELECT post,COUNT(name),GROUP_CONCAT(name) FROM employee5 GROUP BY post;
SELECT COUNT(name),GROUP_CONCAT(name) FROM employee5 WHERE salary>5000;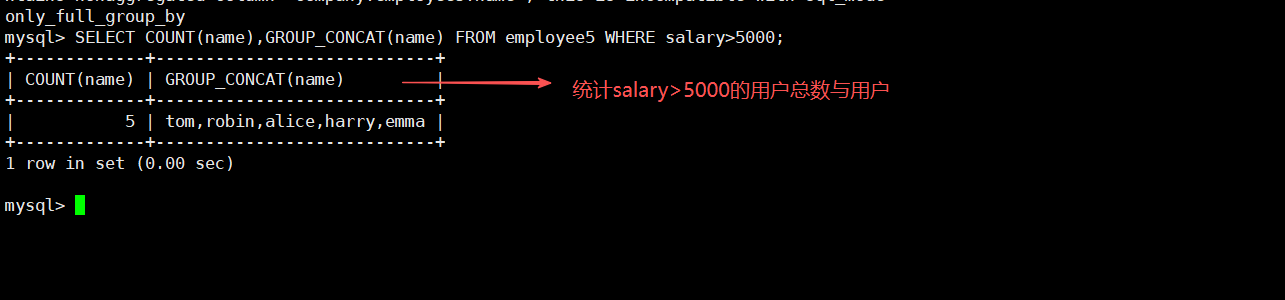
1.8函数应用
1.8.1数值函数
SELECT
ABS(-321) , -- 绝对值
SIGN(-10) , -- 符号(不常用)
PI() , -- 圆周率
ROUND(1.567, 2) , -- 四舍五入
TRUNCATE(3.1415,2) -- 截断小数(截断3.1415为3.14)
FROM employee5;
1.8.2字符串函数
SELECT
name,
salary,
CHAR_LENGTH(name) , -- 字符数
CONCAT(name, ' ', salary) -- 字符串连接(将两个字段显示在一起)
FROM employee5;
1.8.3日期和时间函数
SELECT
id,
name,
hire_date,
CURDATE() , -- 当前日期
YEAR(hire_date) , -- 入职年份
MONTH(hire_date), -- 入职月份
DATEDIFF(CURDATE(), 起始时间字段名) -- 全部天数(可能常用)
FROM employee5;
1.8.4聚合函数
SELECT
AVG(salary) , -- 平均值
SUM(salary) , -- 总和
MAX(salary), -- 最大值
MIN(salary) , -- 最小值
COUNT(*) -- 计数
FROM employee5; -- 员工薪资统计
示例
-- 只统计工资大于15000
select count(*) from employee5 where salary>15000;
示例
-- 分组统计
SELECT
id,
COUNT(*) AS num_employees,
AVG(salary) AS avg_salary,
MAX(salary) AS max_salary,
MIN(salary) AS min_salary
FROM employee5
GROUP BY id; -- 按部门分组统计员工信息