共分为 6个阶段、18个关键步骤:
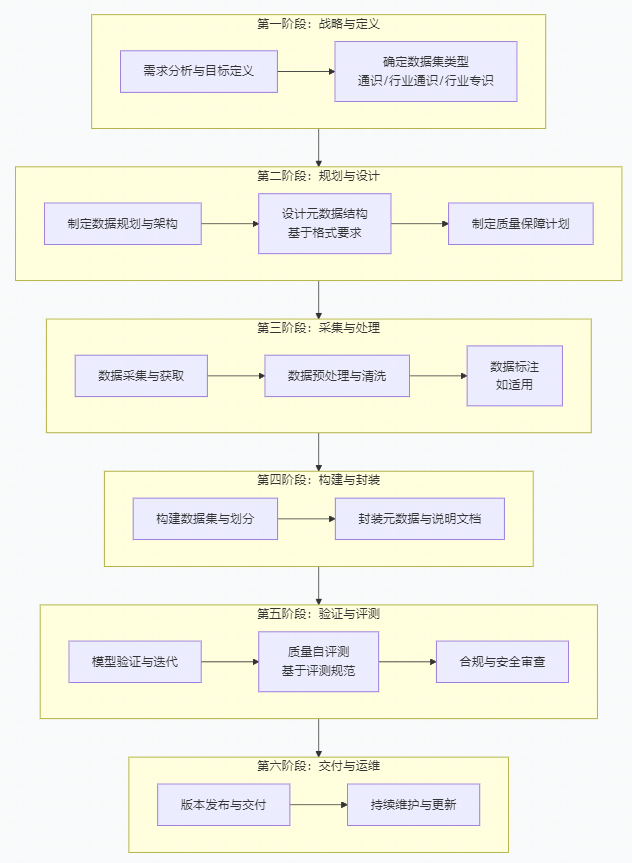
第一阶段:战略与定义
步骤1:需求分析与目标定义
-
明确AI应用场景:确定数据集将用于训练何种模型(如分类、检测、生成)。
-
定义数据需求:包括数据类型(文本、图像等)、规模、质量基线、覆盖范围。
-
识别关键利益方:业务方、技术团队、合规/法务部门。
步骤2:确定数据集类型
-
参考《分类指南》,明确数据集属于:
-
通识数据集(通用知识,如百科数据)
-
行业通识数据集(行业共性知识,如医疗影像公共数据集)
-
行业专识数据集(企业内部专业知识,如生产日志数据)
-
-
根据类型确定数据来源、标注要求、安全等级。
第二阶段:规划与设计
步骤3:制定数据规划与架构
-
设计数据架构:确定数据源、存储结构、数据流。
-
制定实施计划:包括时间表、资源(人力、工具、预算)、风险控制。
-
预估工作量:采集、清洗、标注、验证各阶段工作量评估。
步骤4:设计元数据结构
-
依据《格式要求》,设计数据集元数据字段,至少包括:
-
数据标识(ID)
-
来源、授权、版本
-
模态类型、内容路径
-
标注信息(如有)
-
时间戳
-
-
确定存储格式(如JSON、CSV、数据库表)。
步骤5:制定质量保障计划
-
基于《质量评测规范》,设定各阶段质量检查点。
-
明确质量阈值(如标注准确率≥95%、缺失值比例<5%)。
第三阶段:采集与处理
步骤6:数据采集与获取
-
选择采集方式:
-
获取现有数据集(公开/购买)
-
生成数据(合成、模拟)
-
采集新数据(传感器、爬虫、人工录入)
-
-
记录来源信息:严格记录每个数据的来源、授权、原始时间。
步骤7:数据预处理与清洗
-
数据清洗:去重、去噪、修正错误、处理缺失值。
-
格式标准化:统一文件格式、编码、分辨率、采样率等。
-
特征工程(如需要):提取、选择、构造特征。
步骤8:数据标注(如适用)
-
制定标注规范:定义标签体系、标注规则、边界情况处理。
-
选择标注方式:人工标注、自动标注、半自动标注。
-
标注质量管理:多人标注、交叉验证、专家审核。
第四阶段:构建与封装
步骤9:构建数据集与划分
-
数据集划分:按比例划分训练集、验证集、测试集。
-
确保分布均衡:各类别数据分布合理,避免偏差。
步骤10:封装元数据与说明文档
-
编写说明文档(必须完整):
-
基本信息(规模、格式、结构、访问方式)
-
内容特征(模态、分布、示例、局限性)
-
建设过程(来源、采集方法、标注规范、版本记录)
-
应用说明(许可、场景、评估方法、基准案例)
-
-
生成元数据文件:按《格式要求》生成JSON等格式的元数据文件。
第五阶段:验证与评测
步骤11:模型验证
-
使用数据集训练基线模型,评估性能。
-
若模型未达预期,溯源是否为数据问题,返回相应阶段优化。
步骤12:质量自评测
-
依据《质量评测规范》进行自评:
-
说明文档指标(≥90分)
-
数据质量指标(≥90分)
-
模型应用指标(≥90分)
-
-
记录评测结果,形成自评报告。
步骤13:合规与安全审查
-
检查数据是否符合:
-
安全规范(无违法、歧视、侵权内容)
-
隐私保护(如去标识化)
-
授权合规(版权、许可协议)
-
第六阶段:交付与运维
步骤14:版本发布与交付
-
版本号管理:遵循语义化版本规范(如1.0.0)。
-
打包交付:数据集 + 元数据 + 说明文档 + 评测报告。
-
发布渠道:内部共享、公开平台、数据市场。
步骤15:持续维护与更新
-
建立更新机制:定期更新数据、版本迭代。
-
收集使用反馈:跟踪数据集在使用中的问题,持续优化。
-
维护文档与元数据:随数据集变更同步更新。
关键成功要素
-
跨团队协作:业务、技术、法务、数据团队紧密合作。
-
工具链支持:使用数据标注平台、质量管理工具、版本控制系统。
-
标准化贯穿全程:始终以系列标准为纲,确保合规与互操作性。
-
迭代思维:数据集建设非一蹴而就,需多次验证与优化。