O-Researcher:多智能体蒸馏与强化学习打造开源深度研究新标杆
一句话总结:OPPO提出O-Researcher框架,通过多智能体协作自动合成高质量研究数据,结合监督微调与GRPO强化学习,让72B开源模型在深度研究任务上超越GPT-5和OpenAI O3等商业巨头。
📖 引言:开源模型如何挑战闭源巨头?
在当前的AI研究领域,闭源大语言模型(如GPT-5、OpenAI O3)与开源模型之间存在着显著的性能差距。这种差距的根本原因是什么?高质量训练数据的获取能力。
想象一下,你是一名新手厨师,想要做出米其林级别的菜品。闭源模型就像那些拥有顶级食材供应链的高级餐厅,而开源模型则像家庭厨房------即使厨艺相当,食材的差距也会导致最终成品的巨大差异。
O-Researcher正是要打破这种困境。它来自OPPO Personal AI Lab,提出了一套完整的解决方案:
- 自动化数据合成:用多智能体协作生成高质量研究数据
- 两阶段训练:监督微调(SFT) + 强化学习(RL)双管齐下
- 最终成果:72B参数的开源模型在深度研究任务上达到SOTA,超越商业闭源模型
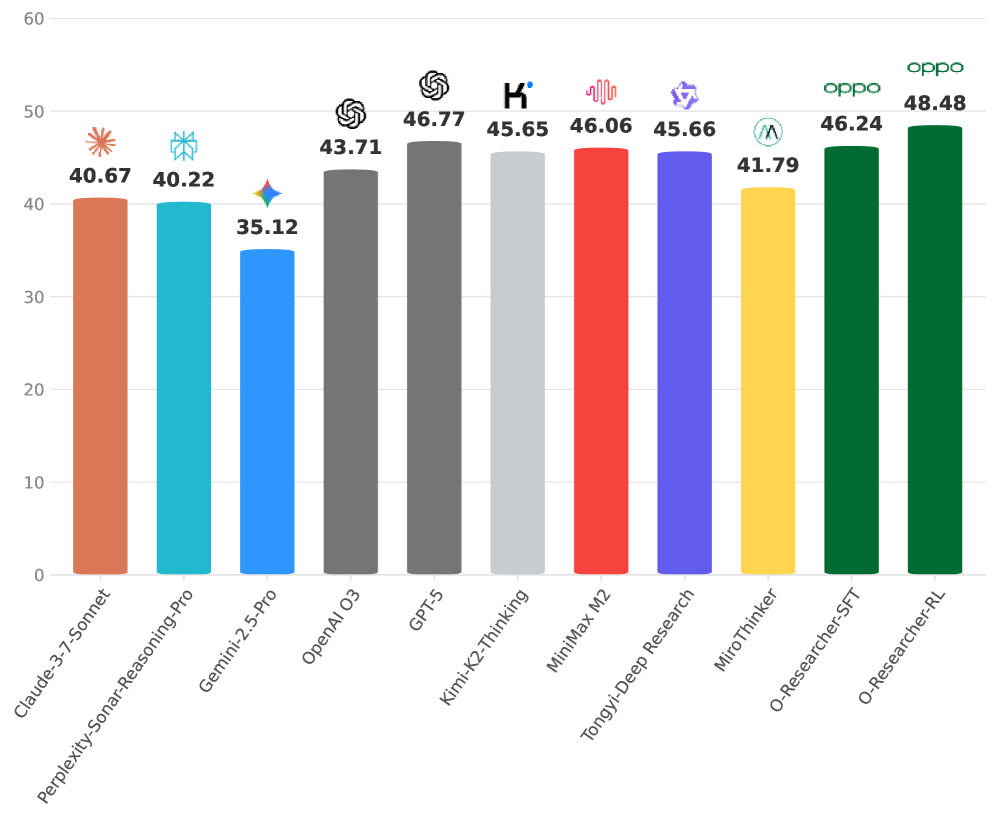
图1:O-Researcher与主流深度研究模型的性能对比。O-Researcher-RL(橙色)以48.48分在开源模型中登顶,并显著超越GPT-5(45.65)、OpenAI O3(46.06)等商业模型。
🎯 核心问题:深度研究任务到底难在哪?
什么是"深度研究"任务?
深度研究(Deep Research)是指需要LLM进行复杂、多步骤信息检索与综合分析的任务。这不是简单的问答,而是需要:
- 规划能力:将复杂问题分解为多个子任务
- 工具使用:调用搜索引擎、爬取网页等外部工具
- 信息综合:整合多源信息形成连贯报告
- 事实验证:确保引用准确、论据有据可查
举个例子:如果你问"比较主流AI对齐技术的优缺点并给出实用建议",模型需要:
- 识别出RLHF、RLAIF、DPO等主要技术
- 搜索每种技术的最新研究进展
- 爬取相关论文和技术博客
- 对比分析各自的优劣势
- 综合形成结构化的研究报告
为什么现有方法不够好?
| 方法类型 | 代表系统 | 主要局限 |
|---|---|---|
| 深度研究Agent | OpenAI Deep Research, Perplexity | 依赖复杂提示工程和人工设计工作流 |
| 闭源模型 | GPT-5, Gemini-2.5-Pro | 训练数据不透明,无法复现 |
| 开源模型 | MiroThinker, WebWeaver | 缺乏高质量研究数据,性能落后 |
O-Researcher的目标就是:开发一个端到端的开源模型,最小化对复杂提示工程和手工设计工作流的依赖。
🏗️ 方法论:三阶段训练管道
O-Researcher的核心方法可以概括为三个阶段:数据合成 → 监督微调 → 强化学习。
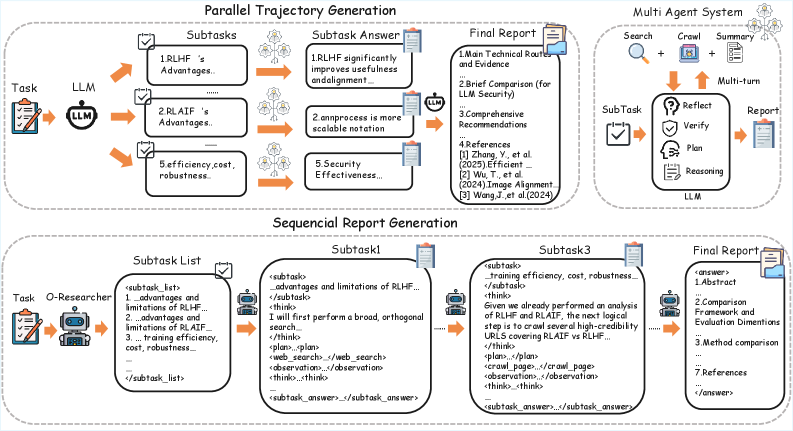
图2:O-Researcher整体框架。上半部分展示多智能体并行轨迹生成流程,下半部分展示单一模型的顺序报告生成对比。关键创新在于将多智能体协作的能力"蒸馏"到单一模型中。
3.1 高质量轨迹生成:让AI团队协作
核心思想:模拟研究团队的分工协作
想象一个高效的研究团队是如何工作的:
- 项目经理(规划器)负责分解任务
- 多个研究员(执行智能体)各自负责不同子课题
- 主编(汇总模型)整合所有人的工作
O-Researcher正是模拟了这种协作模式:
输入:复杂研究问题
↓
[规划器] → 分解为N个正交子任务
↓
[执行智能体1] → 子任务1 → 子报告1
[执行智能体2] → 子任务2 → 子报告2 (并行执行)
[执行智能体3] → 子任务3 → 子报告3
↓
[汇总模型] → 综合所有子报告 → 最终研究报告并行执行的优势
论文通过实验验证,并行执行显著优于顺序执行:
| 执行方式 | 整体分数 | 综合性 | 洞察力 |
|---|---|---|---|
| 顺序执行 | 42.92 | 较低 | 较低 |
| 并行执行 | 49.60 | +15.6% | +12.3% |
这说明:结构化的任务分解是性能提升的关键驱动因素。
查询合成与数据收集
数据来源分为两部分:
- 成熟开源数据集:Zhihu-KOL、WideSearch、ELI5等
- LLM合成主题:让模型生成多样化的研究问题
从5000个种子查询出发,经过严格过滤,最终得到3500+高质量指令响应对。
3.2 质量保证管道:多阶段拒绝采样
高质量数据的关键在于严格的质量把控。O-Researcher采用了四层过滤机制:
原始轨迹
↓
┌──────────────────────────────────────────┐
│ 第1层:多样性驱动生成 │
│ • 每个查询生成3个候选轨迹 │
└──────────────────────────────────────────┘
↓
┌──────────────────────────────────────────┐
│ 第2层:基于规则的硬拒绝 │
│ • 完整性检查(工具调用、标签闭合) │
│ • 上下文长度 < 64k tokens │
│ • 复杂度阈值:>10步推理,>5次工具调用 │
│ • 一致性验证 │
└──────────────────────────────────────────┘
↓
┌──────────────────────────────────────────┐
│ 第3层:基于模型的语义过滤 │
│ • 使用Qwen3作为LLM-as-a-Judge │
│ • 评估逻辑连贯性、工具相关性、证据基础 │
└──────────────────────────────────────────┘
↓
┌──────────────────────────────────────────┐
│ 第4层:人工验证 │
│ • 分层抽样检查 │
│ • 质量不达标触发重新生成 │
└──────────────────────────────────────────┘
↓
高质量SFT数据3.3 结构化数据表示
为了让模型学会规范的推理流程,所有轨迹都使用XML风格标签进行序列化:
xml
<subtask_list>
<subtask>分析RLHF的优缺点</subtask>
<subtask>分析RLAIF的优缺点</subtask>
<subtask>对比两者的训练效率</subtask>
</subtask_list>
<think>
首先需要搜索RLHF相关的最新研究...
</think>
<plan>
1. 搜索RLHF核心论文
2. 爬取技术博客中的实践经验
3. 总结优缺点
</plan>
<web_search>RLHF alignment technique advantages</web_search>
<observation>搜索结果显示...</observation>
<crawl_page>https://example.com/rlhf-analysis</crawl_page>
<observation>页面内容:...</observation>
<subtask_answer>
RLHF的主要优势包括...
主要局限在于...
</subtask_answer>
<suggested_answer>
[最终综合报告]
</suggested_answer>这种结构强制模型遵循 思考(Think) → 行动(Action) → 观察(Observation) → 回答(Answer) 的循环,确保推理过程的可解释性和规范性。
🔧 强化学习阶段:GRPO精调
为什么需要强化学习?
监督微调(SFT)虽然能让模型学会基本的研究流程,但存在一个问题:模型可能过拟合于训练数据的特定模式,而非真正理解什么是"好的研究报告"。
这就像学生背诵范文 vs 理解写作原则的区别。强化学习的目的是让模型学会内化"好报告"的评判标准。
GRPO:无需价值网络的高效强化学习
O-Researcher采用了 GRPO(Group Relative Policy Optimization,群组相对策略优化) 算法,这是由DeepSeek团队提出的高效RL方法。
GRPO vs PPO的核心区别
| 特性 | PPO | GRPO |
|---|---|---|
| 价值网络 | 需要(与策略网络同规模) | 不需要 |
| 内存占用 | 高 | 减少50% |
| 训练速度 | 基准 | 提升30% |
| 优势估计 | 通过价值网络 | 通过组内相对比较 |
GRPO的核心思想非常直观:不需要单独训练一个"评判员"网络,而是让同一问题的多个答案互相比较,好的答案获得正奖励,差的答案获得负奖励。
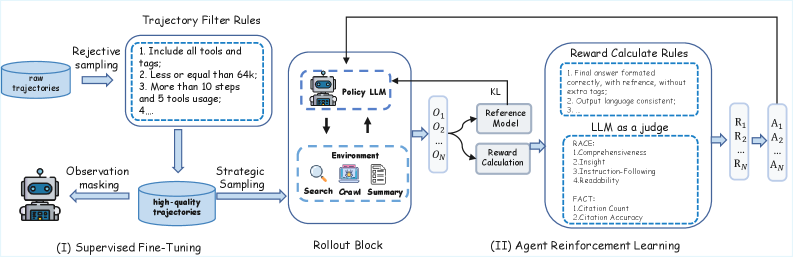
图3:O-Researcher的两阶段训练流程。(I) 监督微调阶段:通过多阶段拒绝采样获得高质量轨迹;(II) Agent强化学习阶段:使用GRPO算法优化策略,奖励函数包含RACE(报告质量)和FACT(事实正确性)两个维度。
偏好数据策划:找到"最佳难度区间"
一个关键洞察是:太简单或太难的问题对模型学习都没有帮助。
O-Researcher使用SFT模型的性能方差来筛选问题:
- 方差太低 → 模型已经掌握,学不到新东西
- 方差太高 → 问题太难,模型无法有效学习
- 方差适中 → "最佳学习区间",最大化学习信号
奖励函数设计
奖励函数是强化学习的核心,O-Researcher设计了一个多维度的复合奖励:
R = w 1 R b a s e + w 2 R t o o l + w 3 R f o r m a t R = w_1 R_{base} + w_2 R_{tool} + w_3 R_{format} R=w1Rbase+w2Rtool+w3Rformat
其中权重分配为: w 1 = 0.6 , w 2 = 0.2 , w 3 = 0.2 w_1=0.6, w_2=0.2, w_3=0.2 w1=0.6,w2=0.2,w3=0.2
1. 基础质量奖励 R b a s e R_{base} Rbase(权重0.6)
使用LLM作为评判员,评估报告的四个维度:
- 综合性(Comprehensiveness) :是否全面覆盖了问题的各个方面
- 洞察力(Insight) :是否提供了深入的分析和见解
- 指令遵循(Instruction Following) :是否准确回应了用户的问题
- 可读性(Readability) :报告是否结构清晰、易于理解
2. 工具使用奖励 R t o o l R_{tool} Rtool(权重0.2)
鼓励合理的证据收集:
- 工具调用次数 < 2次:惩罚(收集证据不足)
- 工具调用次数 2-8次:奖励(合理范围)
- 工具调用次数 > 8次:惩罚(过度搜索,效率低下)
3. 格式奖励 R f o r m a t R_{format} Rformat(权重0.2)
检查输出格式的规范性:
- XML标签是否正确闭合
- 是否包含必需的
<suggested_answer>标签
🧪 实验设置与评估
基准测试
论文使用了两个主要的评估基准:
| 基准 | 描述 | 任务特点 |
|---|---|---|
| DeepResearch Bench | 100个博士级研究任务 | 涵盖科技、金融、软件工程等领域 |
| DeepResearchGym | 开源评估框架 | 可重现搜索API + 严格多维评估 |
评估指标
评估分为两大维度:
RACE(报告质量)
- 综合性:内容是否全面
- 洞察力/深度:分析是否深入
- 指令遵循:是否准确回应问题
- 可读性:表达是否清晰
FACT(事实正确性)
- 引用准确性:引用的信息是否正确
- 有效引用数:有多少引用是有价值的
上下文长度实验
论文还探索了不同上下文长度对性能的影响:
| 上下文长度 | 性能表现 | 结论 |
|---|---|---|
| 32k | 基准 | - |
| 64k | 显著提升 | 最佳性价比 |
| 128k | 提升有限 | 收益递减 |
最终选择64k作为默认配置。
📊 实验结果
主要性能对比
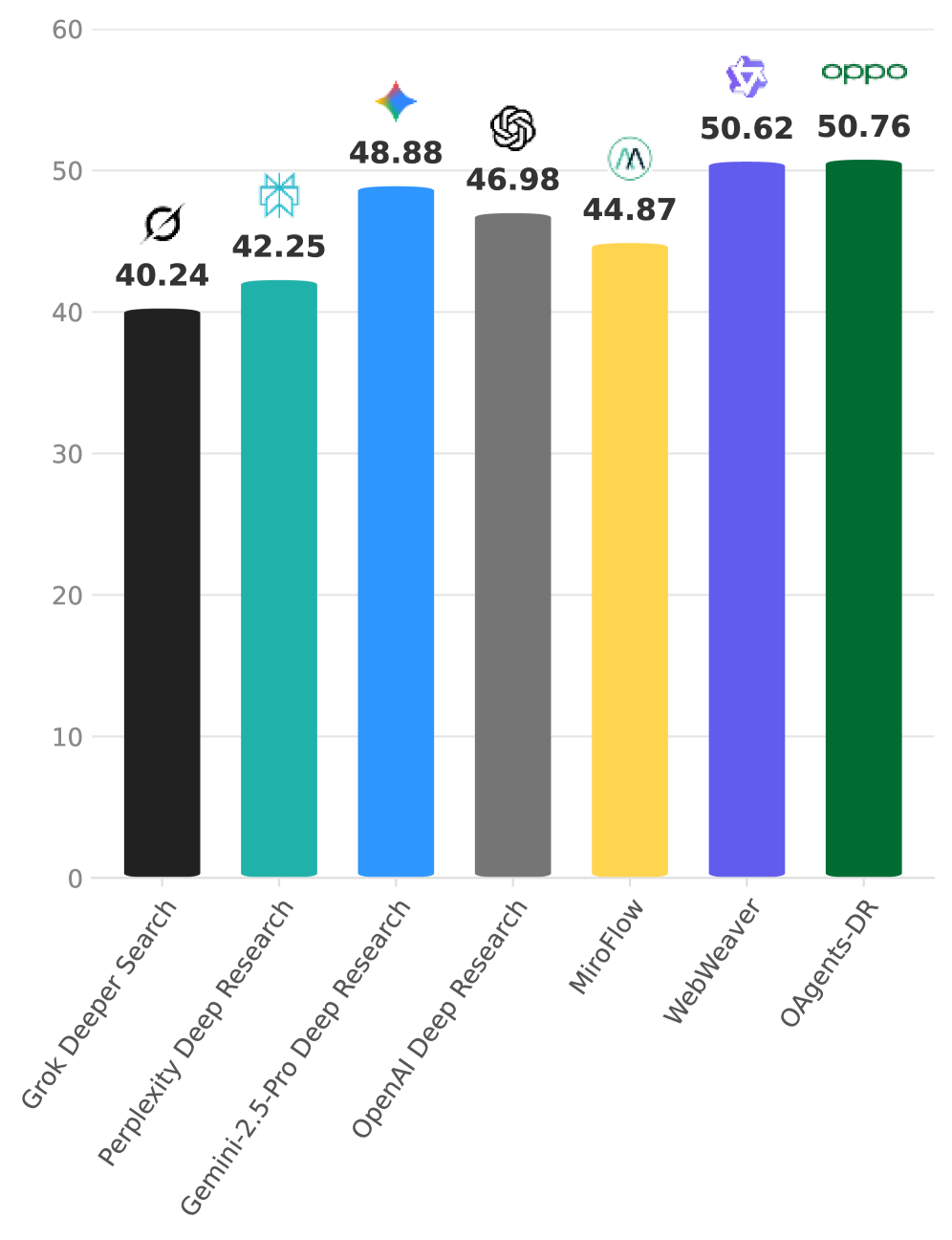
图4:O-Researcher与深度研究Agent系统的对比。O-Researcher-RL(50.62)和O-Researcher-SFT(50.76)显著领先于Perplexity Deep Research、Gemini-2.5-Pro Deep Research和OpenAI Deep Research等商业系统。
DeepResearch Bench结果
| 模型类型 | 模型名称 | 总分 | 排名 |
|---|---|---|---|
| 开源SOTA | O-Researcher-RL | 48.48 | #1 |
| 开源 | O-Researcher-SFT | 46.77 | #2 |
| 闭源 | OpenAI O3 | 46.06 | - |
| 闭源 | GPT-5 | 45.65 | - |
| 闭源 | Gemini-2.5-Pro | 45.66 | - |
| 开源 | MiroThinker | 40.22 | - |
| 开源 | MiniMax M2 | 41.79 | - |
关键发现:
- O-Researcher-RL在开源模型中建立了新的SOTA
- 超越了GPT-5、OpenAI O3等顶级闭源系统
- 相比基座模型Qwen-2.5-72B-Instruct,有效引用数量大幅增加(+13.67)
训练阶段效果分析
| 训练阶段 | 引用准确性 | 有效引用数 | 总分 |
|---|---|---|---|
| Qwen-2.5-72B(基座) | 较高 | 较低 | 35.12 |
| O-Researcher-SFT | 29.13% | 较高 | 46.77 |
| O-Researcher-RL | 31.99% | 26.01 | 48.48 |
有趣的发现:
- SFT阶段因为学习复杂轨迹,导致引用准确性略有下降
- RL阶段成功缓解了这个问题,引用准确性从29.13%提升至31.99%
DeepResearchGym评估
在更严格的DeepResearchGym基准上:
| 指标 | O-Researcher-72B | 竞争对手 |
|---|---|---|
| 清晰度 | 100.00 | - |
| 洞察力 | 99.3 | - |
| 引用精度 | 51.45(最高) | - |
引用精度51.45是所有类别中最高的,表明模型在保持高召回率的同时有效避免了幻觉引用。
🔬 深度分析:并行执行的威力
论文专门对比了GPT-5在不同执行模式下的表现:
| 执行模式 | 综合性 | 洞察力 | 整体分数 |
|---|---|---|---|
| 顺序执行 | 基准 | 基准 | 42.92 |
| 并行执行 | +15.6% | +12.3% | 49.60 |
这个实验揭示了一个重要结论:结构化的任务分解和并行执行是性能提升的关键驱动因素。
为什么并行执行更好?
- 减少信息损失:顺序执行时,后面的子任务容易受前面结果的偏见影响
- 增加覆盖面:不同智能体从不同角度探索,综合性更强
- 提高效率:实际应用中并行执行更快
推理步骤数的影响
| 推理步骤 | 性能 | 计算成本 |
|---|---|---|
| 5步 | 较低 | 低 |
| 10步 | 最优 | 中等 |
| 15步 | 略有提升 | 高 |
10步工作流提供了最佳的性能与计算成本平衡。
💡 案例展示

图5:O-Researcher在实际深度研究任务中的推理过程展示。左侧是用户查询(关于Netflix改编《百年孤独》的问题),模型将其分解为多个子任务,每个子任务包含思考(Think)、搜索(Search)、观察(Observation)和回答(Answer)的完整循环,最终生成结构化的综合报告。
上图展示了O-Researcher处理一个真实研究问题的过程:"Netflix如何成功将《百年孤独》这部出了名难以改编的小说搬上银幕?"
模型的处理流程:
- 任务分解:将问题拆分为叙事结构、技术挑战、文化真实性等子任务
- 并行研究:不同子任务独立进行搜索和分析
- 证据整合:爬取多个权威来源(The Guardian、制作团队采访等)
- 综合报告:形成包含执行摘要、多维度分析、参考文献的完整报告
🤔 思考与启示
1. 开源模型的希望之路
O-Researcher证明了一个重要观点:开源模型的落后不是能力问题,而是数据问题。通过精心设计的数据合成管道,开源模型完全可以达到甚至超越闭源模型的水平。
2. 多智能体蒸馏的价值
将多智能体协作的能力"蒸馏"到单一模型中,这个思路具有广泛的应用价值:
- 训练时使用复杂的多智能体系统生成数据
- 推理时只需要单一模型,降低部署成本
- 同时获得多智能体的协作优势和单模型的效率
3. 强化学习的精调作用
SFT让模型"知道怎么做",RL让模型"知道什么是好"。论文中RL阶段成功修复了SFT导致的引用准确性下降问题,说明两阶段训练各有不可替代的作用。
4. 可复现性的重要性
论文开源了代码和模型:
- GitHub: O-Researcher
- 模型: O-Researcher-72B-sft, O-Researcher-72B-rl
这种开放精神是推动开源社区进步的关键。
⚠️ 局限性与未来方向
当前局限
- 计算资源需求:72B参数模型的训练和推理成本较高
- 数据多样性:当前数据主要来自中英文源,多语言覆盖有限
- 实时性:依赖搜索引擎的信息可能存在时效性问题
未来方向
- 模型蒸馏:将能力迁移到更小的模型(7B/14B)
- 多模态扩展:支持图表、视频等多模态研究内容
- 领域专精:针对特定领域(医学、法律等)的专业化训练
- 交互式研究:支持用户在研究过程中的实时反馈和引导
📝 总结
O-Researcher为开源深度研究模型树立了新标杆。其核心贡献包括:
- 多智能体协作数据合成:模拟研究团队分工,自动生成高质量训练数据
- 两阶段训练策略:SFT学流程 + RL学标准,各有侧重
- GRPO强化学习:无需价值网络,高效且稳定
- SOTA性能:72B开源模型超越GPT-5、OpenAI O3等商业巨头
这项工作证明:通过精心设计的数据合成和训练方法,开源模型完全有能力在复杂任务上挑战闭源巨头。这为整个开源社区提供了一条可扩展、可复现的进步路径。
🔗 参考资料
- 论文链接 : arXiv:2601.03743
- 代码仓库 : GitHub - OPPO-PersonalAI/O-Researcher
- 模型下载 :
- 相关技术 :