在跨语言交流日益频繁的今天,阅读外语菜单、处理多语言邮件、与不同语言背景的人沟通,已经成为很多人日常工作与生活的一部分。过去,这类需求往往依赖联网翻译工具,而如今,在端侧完成多语言互译正在成为可行选项 ------ 一部设备即可支持多达 33 种语言的相互翻译。
当 AI 不再只是"逐字直译",而是开始理解语境、风格与语言之间的细微差异,机器翻译就真正具备了工程级可用性与语义深度。
今天为大家介绍一款高质量、多语言、支持端侧部署的机器翻译模型 ------ 腾讯混元 HY-MT1.5-1.8B,现已上线 AtomGit AI 社区,支持在线体验与调用。
👉 在线体验入口:https://ai.gitcode.com/tencent_hunyuan/HY-MT1.5-1.8B/model-inference
01|多语言强互译,覆盖真实业务场景
HY-MT1.5-1.8B 是腾讯推出的一款面向真实业务场景的多语言机器翻译模型,主打高质量互译能力与端侧可部署特性。模型在保证翻译效果的同时,对体量与推理性能进行了针对性优化,适合在移动端与边缘设备上使用。
其核心特性可以从几个关键指标中直观体现:
-
**1.8B 参数规模:**在轻量化模型中兼顾翻译质量与语义理解能力
-
**约 1GB 模型体量:**支持端侧部署,降低对网络与算力环境的依赖
-
**约 0.18 秒推理延迟:**在常见输入长度下实现快速响应
-
**覆盖 33 种语言:**支持中、英、法、德等主流语言,以及冰岛语、爱沙尼亚语等小语种互译
通过多语言覆盖与低时延推理能力,HY-MT1.5-1.8B 能够更好地适配跨语言沟通、移动翻译、出海业务等实际应用场景。
02|小模型,也有大能量
HY-MT1.5-1.8B 的核心优势,在于在模型体积、推理速度与翻译体验之间实现了较为难得的平衡。在参数规模相对克制的前提下,该模型依然能够在手机、平板乃至边缘设备上,提供接近云端大模型的翻译效果,其关键并不在于"更大",而在于更有针对性的训练与优化。
🌟 体积更小,跑得更快
-
模型只有 18 亿参数,体积比常见的 7B 模型小近 3 倍,量化后最低只需 1GB 内存,几乎和一部高清电影差不多大。
-
提供多种量化版本(FP8、INT4),可根据设备性能自由选择,既要速度也能保质量。
💻 本地运行,真正离线
-
不依赖网络,翻译过程完全在设备本地完成,适合出差、旅行、展会等网络不稳或无法联网的场景。
-
实测在普通手机上翻译 50 个词只需 0.18 秒,比很多在线翻译接口还快,真正做到了"边说边翻"。
📱 适配多类终端设备
-
已验证可在手机、车载系统、安卓工控盒、甚至树莓派上稳定运行。
-
对于需要快速响应的场景,如输入法实时翻译、客服对话、浏览器划词翻译等,体验提升非常明显。
03|小参数,也能有好表现
尽管 HY-MT1.5-1.8B的参数规模相对克制,其训练过程并不简化。腾讯混元团队围绕机器翻译任务,设计了一套多阶段、分层次的训练流程,使模型不仅具备多语言理解能力,也具备稳定、可靠的翻译表现。
🔧 五段式训练流程,层层递进
-
**通用预训练:**先让模型在多语言大语料上"广泛阅读",建立语言基础。
-
**翻译定向训练:**再用翻译专用语料进行任务强化,学会语言之间的转换逻辑。
-
**有监督精调:**引入高质量双语数据,提升翻译准确度,减少"机器味"。
-
**大模型带小模型(蒸馏):**用更大的 7B 模型当老师,手把手教 1.8B 如何"翻译得更地道"。
-
**强化学习优化:**最后通过策略优化,让模型在表达自然度、术语一致性等方面更贴近人类偏好。
✍️ 翻译质量不输大模型
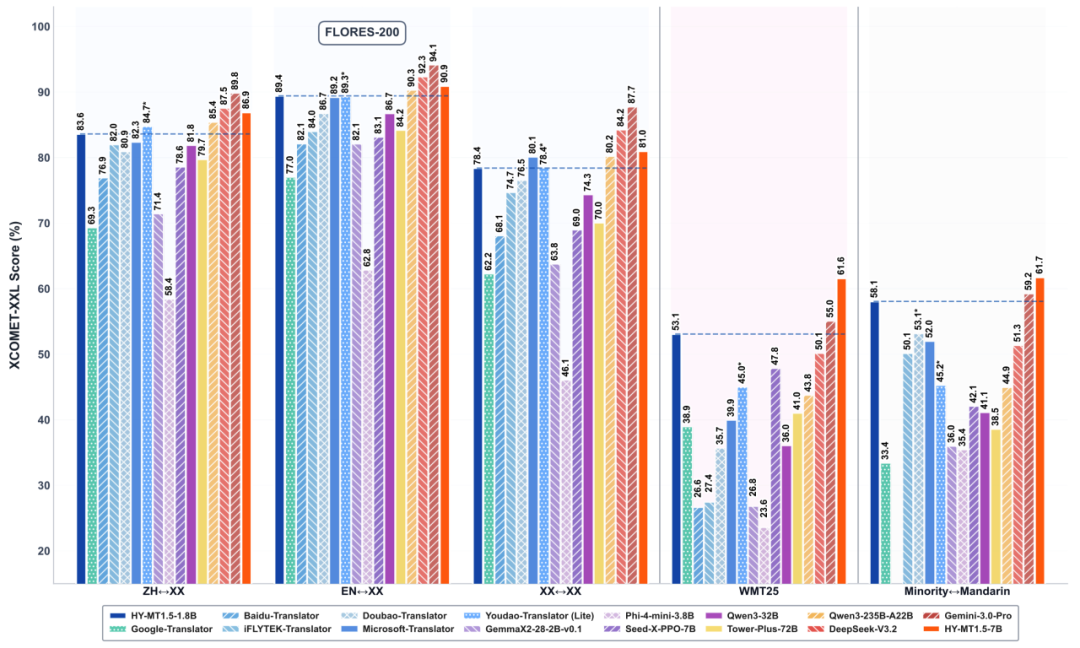
在多个权威测试集(如 Flores-200、WMT25)中,HY-MT1.5-1.8B 的表现不仅领先于同量级开源模型,也超过了不少商业翻译接口,整体水平已接近超大闭源模型的 90% 水准。
04|不只是翻译,更是"翻译+"
在实际业务场景中,机器翻译的要求并不仅限于语言转换本身,还需要同时兼顾**术语一致性、上下文连贯性以及原始格式的完整保留。**这些因素,往往决定了一款翻译模型能否直接进入生产环境。
围绕上述需求,HY-MT1.5-1.8B在翻译能力之外,引入了多项面向实际应用的增强机制,使其更适合在真实业务中落地。
📖 术语干预:保障专业表达一致性
模型支持用户自定义术语表,可指定特定词汇的固定译法。例如,在专业文档或品牌场景中,关键术语将优先按预设规则翻译,避免自由发挥。这一能力在法律、医疗、企业品牌内容等场景中尤为重要。
👀 上下文感知:提升长文本翻译稳定性
模型支持结合上下文进行翻译,有效减少同一词语在不同句子中出现歧义或译法不一致的问题。在客服对话、多轮交互及长文档翻译中,可显著提升整体连贯性与风格统一性。
📚 格式保留:结构不变,内容可用
在翻译 HTML、Markdown、表格、代码注释等结构化文本时,模型能够保留原有标签与排版结构,仅对文本内容进行翻译,降低后续人工校对与格式整理成本。
🌟|推理 API 即开即用
无需复杂部署,通过 推理 API 即可快速体验HY-MT1.5-1.8B的翻译能力。
进入AtomGit AI社区工作台,按以下步骤完成配置即可调用模型:
-
进入工作台,点击 API 密钥;
-
新建 API 密钥,支持选择「仅创建时可见」或「支持多次查看」;
-
密钥创建完成后,即可在代码中直接调用HY-MT1.5-1.8B 进行文本翻译。
👉 工作台入口: https://ai.gitcode.com/dashboard?tab=created&subtab=all
🪄|性能与优势一览
在轻量化参数规模下,HY-MT1.5-1.8B在翻译质量、响应速度与工程可用性之间实现了良好平衡。在多项公开测试中,其整体表现已接近更大体量模型,在部分民汉翻译场景中表现尤为突出。
🤖 模型体积
模型量化后约1 GB,可直接部署于手机及边缘设备。在无网络或网络受限环境下,依然能够稳定提供翻译能力。
🔍 语言覆盖
支持 33 种语言互译,覆盖中文、英语、日语、法语、德语、西班牙语、俄语、阿拉伯语、印地语、泰语、越南语、印尼语、马来语、菲律宾语、葡萄牙语、意大利语、荷兰语、波兰语、捷克语、北欧语言等,同时支持 藏语、维吾尔语、蒙古语、壮语、粤语 等民族语言与方言,满足更广泛的跨语言需求。
👍 翻译质量
在公开测试集中,中英互译、英外互译及民族语言翻译等多个方向上,模型得分高于多数同类商业接口,整体表现接近更大规模的旗舰模型。
🔢 工程落地能力
支持术语表约束、上下文连续翻译以及结构化文本格式保留,可直接应用于技术文档、网页内容、表格与业务系统翻译,减少后处理成本,提升实际使用效率。
👋|快速体验模型能力
1️⃣ 方式一:在线体验
立即访问:https://ai.gitcode.com/tencent_hunyuan/HY-MT1.5-1.8B/model-inference
上传文本,选择目标语言,即可获得翻译结果,支持直观对比与多语言输入。
2️⃣ 方式二:调用推理 API
-
支持批量翻译
-
输出格式结构清晰
-
易集成到产品线、工作流、客户端等
欢迎前往AtomGit AI社区 模型广场 ,即刻体验 HY-MT1.5-1.8B 的翻译能力:https://ai.gitcode.com/tencent_hunyuan/HY-MT1.5-1.8B/model-inference