PSO的Precompile与Shader编译的关系
提问:在UE4游戏运行时中,PSO的Precompile 是否会去编译Shader?
回答:不会,也会。我们得先理清楚 "Shader编译" 这个概念。
在 "着色器(Shader)的编译" 和 "管线状态对象(PSO)的创建" 这两个发生在不同阶段、不同层级的操作下,有着不同的 "Shader编译" 的概念。下图清晰地展示了从源代码到GPU机器码的完整流程,以及PSO预编译在其中的精确位置。
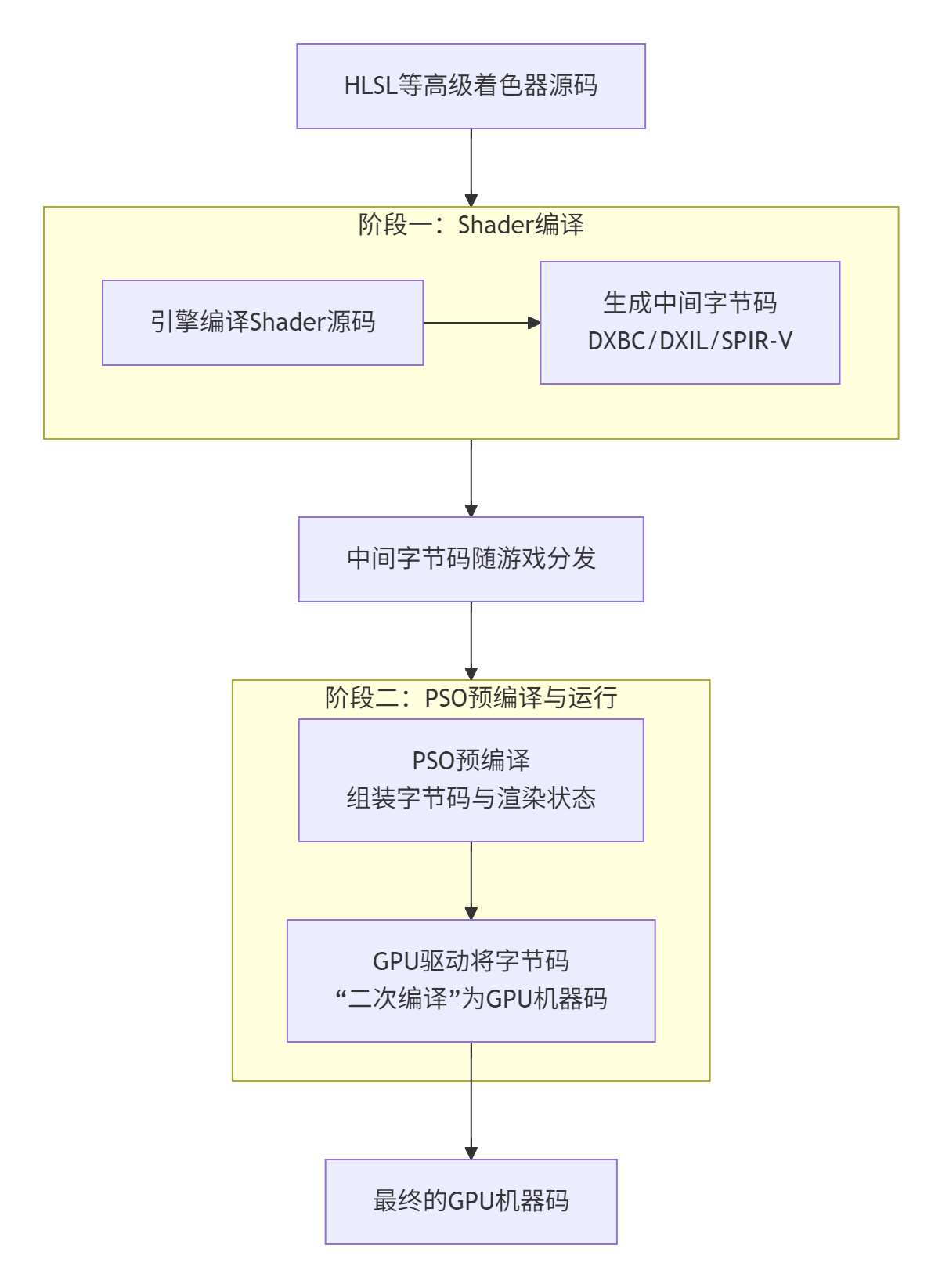
阶段一:项目打包时 -- 生成"半成品"
在打包游戏时(构建时 ),UE4的着色器编译器会将项目中所有的材质节点网络、.usf源码文件等,编译为特定图形API(如DX12、Vulkan)所需的中间字节码 (例如DXBC、SPIR-V)。可以把这个过程理解为生产一种"半成品 "或"通用零件 "。这种字节码是平台相关的,但依然是GPU厂商都能识别的"通用指令",还不是当前电脑上特定GPU的"母语"。这些"半成品"会被打包进游戏文件(如 .ushaderbytecode)。
在很多语境之下,"Shader编译" 其实是指阶段一。
阶段二:游戏运行时 -- 加工为"成品"并组装
当玩家运行游戏时(运行时),两个关键进程在同时或先后发生:
-
PSO预编译(组装"配方")
这是PSO预缓存系统的核心工作。它利用阶段一准备好的"半成品"字节码,再结合所有的渲染状态(混合模式、深度测试等),组装成一个完整的"渲染配方",也就是PSO。这个步骤本身并不生产新的"零件"(不编译Shader),而是将已有的"零件"按照"配方"组合起来。
-
驱动的最终编译(翻译成"母语")
然而,GPU驱动程序在接收到这个"配方"后,并不能直接执行。它需要将"配方"中的通用字节码"零件",实时地翻译(编译)成当前玩家GPU硬件能够直接执行的本地机器码。这个过程是不可避免的,因为世界上有太多不同架构的GPU,无法预先为每一种都准备好机器码。
回到问题本身,在UE4游戏运行时中,PSO的Precompile 是否会去编译Shader?回答是"会发生第二阶段的编译"。多说一句:"驱动的最终编译"本身是具有缓存的,因此只有第一次打开游戏时,相对较慢。第二次打开游戏时,会相对较快。
时序
提问:"GPU驱动将中间字节码编译成当前GPU专属机器码的最终编译(阶段二的工作)" 发生在pso预热、precompile、set pso 这个流程以后吗?
回答:"最终编译"并非发生在PSO流程之后,而是深度嵌入在PSO的创建(预热/预编译)过程之中 ,是Set PSO操作能够瞬间完成的前提。
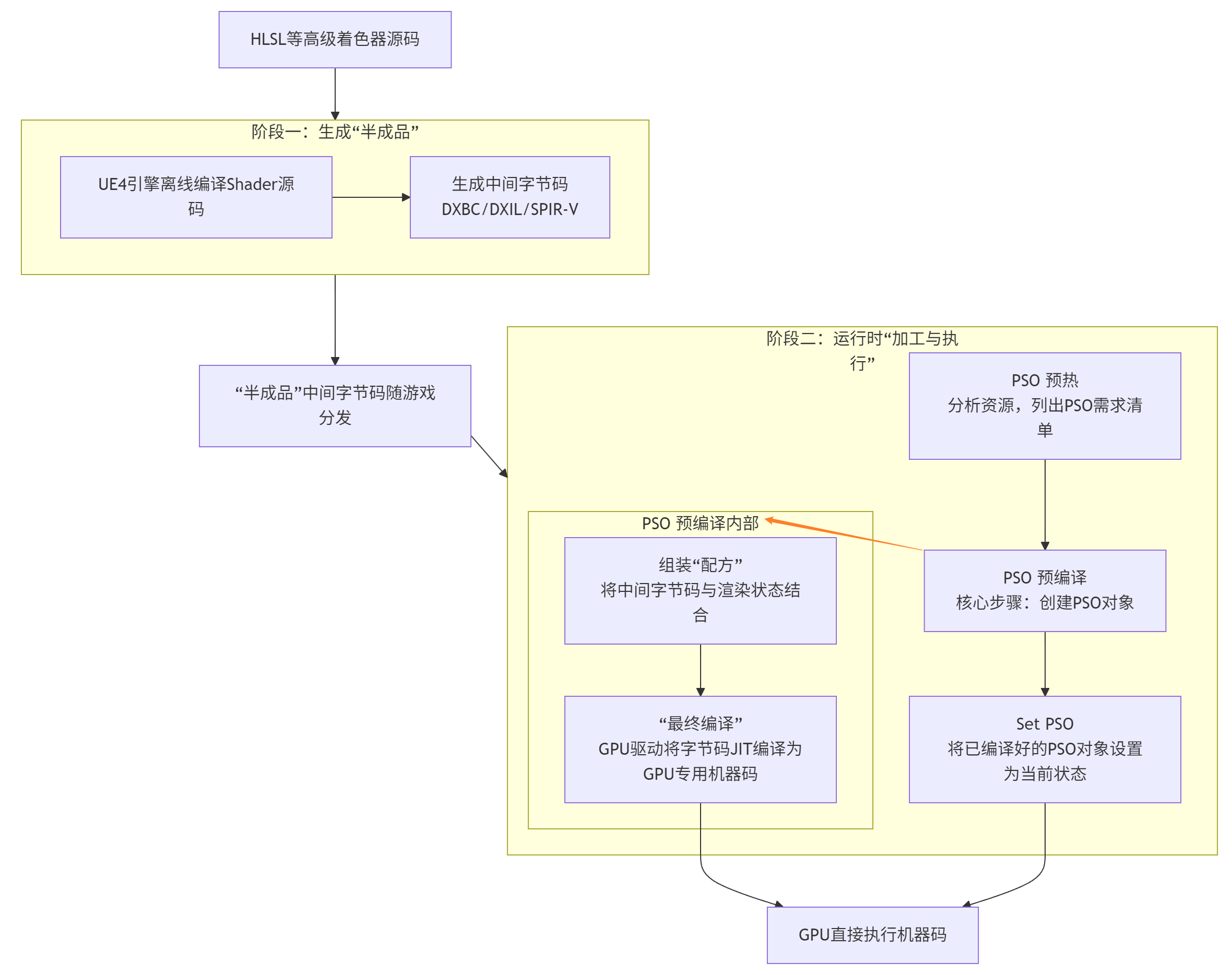
这个流程揭示了几个重要结论:
-
PSO预编译是载体 :PSO的预热(Warm-up)是识别需求,预编译(Precompile)则是实际执行创建PSO对象的步骤。而这个创建过程,必然触发GPU驱动将中间字节码进行最终的JIT编译。没有这个步骤,PSO对象本身是无法创建的。
-
Set PSO是消费 :Set PSO命令的作用,是将一个已经创建(即已经完成最终编译)的、立即可用的PSO对象 绑定到当前的渲染状态。正因为最耗时的编译工作已经在预编译阶段完成,Set PSO才能成为一个高效、瞬时完成的操作,从而避免在提交绘制指令时产生卡顿。