"Human-robot facial coexpression" (人机面部共表情) 由哥伦比亚大学的 Yuhang Hu 等人发表在 Science Robotics 上。该研究提出了一种能够让机器人与人类同时做出面部表情(coexpression)的系统,而不仅仅是延迟模仿。
文章目录
- 核心问题
- 核心思想
- 方法
-
- [硬件设计:Emo 机器人](#硬件设计:Emo 机器人)
- 软件算法:双神经网络框架
-
- [1. 逆向模型 (Inverse Model / Self-Model):让机器人"了解自己"。](#1. 逆向模型 (Inverse Model / Self-Model):让机器人“了解自己”。)
- [2. 预测模型 (Predictive Model / Conversant Model):让机器人"预判他人"。](#2. 预测模型 (Predictive Model / Conversant Model):让机器人“预判他人”。)
- 实验
- 贡献
核心问题
目前的人形机器人在非语言交流(特别是面部表情)方面存在两个主要障碍,导致其难以与人类建立真正的共鸣:
- 机械执行的挑战:制造一个能够进行多功能表达、机械结构复杂的机器人面部是非常困难的 。
- 表情生成的时机与自然度 :传统的机器人通常是被动的,它们先感知人类的情绪,然后在处理后做出反应。这种"感知-处理-行动"的循环会导致明显的延迟 。
- 延迟的模仿(Delayed Mimicry)往往被认为是虚伪、做作或不自然的,无法建立真诚的情感联系。
- 只有当两个人同时微笑时,这种"同步性"才能让对方感觉到真诚和相互理解。
核心思想
该论文的核心思想是 "预测即共鸣" 。
作者认为,为了让机器人看起来真诚,它必须具备 预测能力 ,即在人类完全做出表情之前,预判其意图并同步执行表情。
- 从模仿转向共表情(Coexpression) :机器人不应等待人类做完表情后再模仿,而应通过观察人类面部肌肉的微小变化,预测未来的表情,并与人类同时达到表情的"峰值" 。
- 预测时间窗 :研究发现,机器人可以在人类微笑前约 839 毫秒 预测到这一行为,利用这段时间差来同步生成表情。
方法
为了实现这一目标,作者在硬件设计和软件算法两方面进行了创新。

硬件设计:Emo 机器人
作者开发了一个名为 Emo 的拟人化面部机器人:

- 高自由度 :拥有 26 个致动器(自由度),相比前代 Eva 机器人的 10 个大幅提升,支持不对称表情 。
- 软体皮肤与磁力连接 :使用硅胶皮肤,并通过 30 个磁铁 与机械结构连接,便于更换和维护,同时提供更精确的皮肤变形控制。
- 眼部摄像头:在每个眼球瞳孔处嵌入了高分辨率 RGB 摄像头,使机器人能够进行自然的目光接触并捕捉对话者的面部 。
软件算法:双神经网络框架
该系统包含两个核心神经网络模型,协同工作以实现共表情:
1. 逆向模型 (Inverse Model / Self-Model):让机器人"了解自己"。

- 这是一个自我监督学习过程。机器人对着镜子进行随机的"运动牙牙学语"(motor babbling),学习原本的运动指令与最终生成的面部地标(facial landmarks)之间的关系 。
- 功能:输入想要达到的面部表情(地标),输出控制电机的指令 。
2. 预测模型 (Predictive Model / Conversant Model):让机器人"预判他人"。
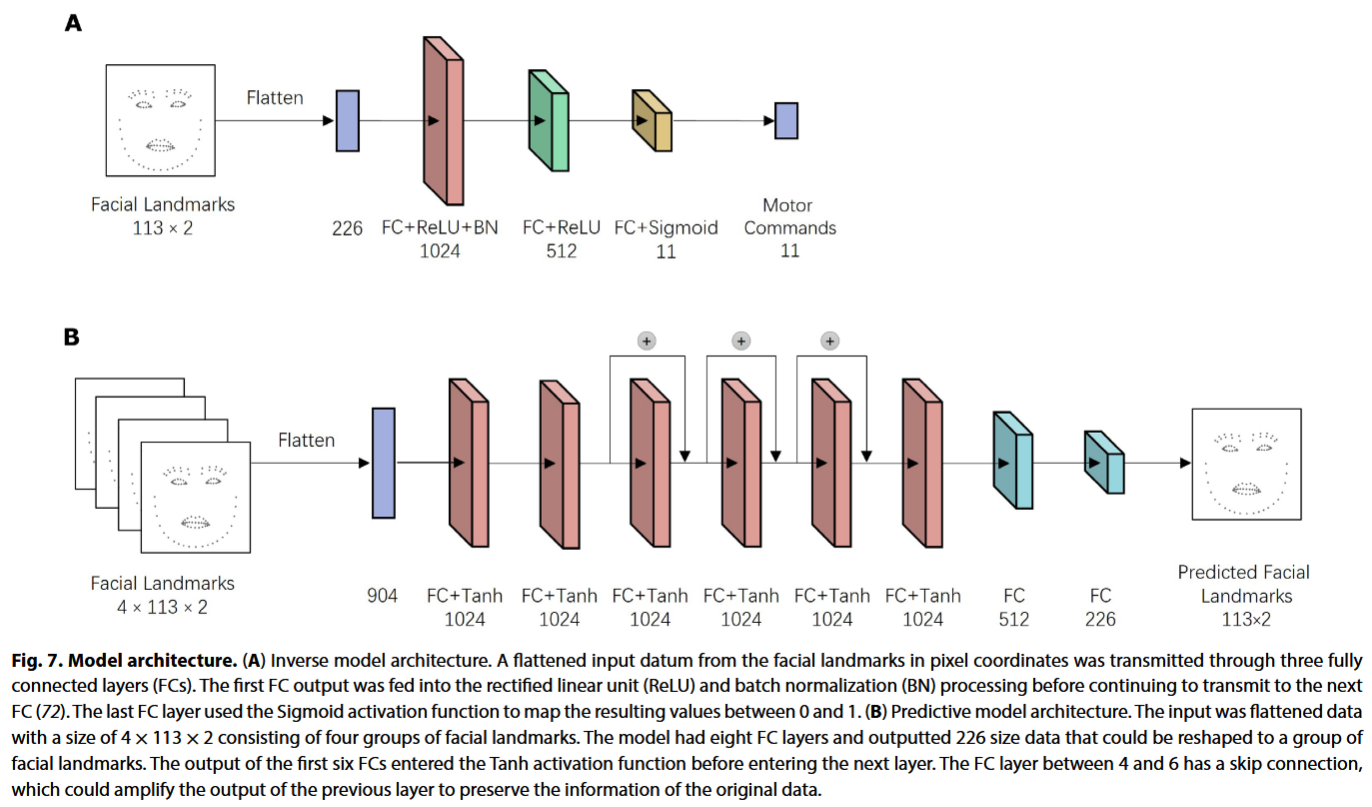
- 基于人类视频数据训练。该模型观察人类面部表情的初始微妙变化(如嘴角微动),预测即将发生的"目标表情" 。
- 功能:输入当前人类面部的连续几帧图像,输出预测的人类未来面部地标 。
- 工作流 :
- 检测到人类面部微动。
- 预测模型推断出人类即将展示的表情。
- 将预测的人类表情通过归一化映射到机器人的面部空间 。
- 逆向模型计算出电机指令。
- 机器人执行指令,与人类同时完成微笑 。
实验
作者通过定量分析和物理演示验证了系统的有效性。
模型性能评估
-
逆向模型精度:在生成准确的电机指令方面,该模型显著优于随机搜索和最近邻搜索等基线方法 。
-
预测模型精度 :与"模仿基线"(即简单复制上一帧表情)相比,预测模型在预测未来面部地标方面的误差更小,证明了它确实学到了面部动态变化的规律,而不仅仅是复制 。

-
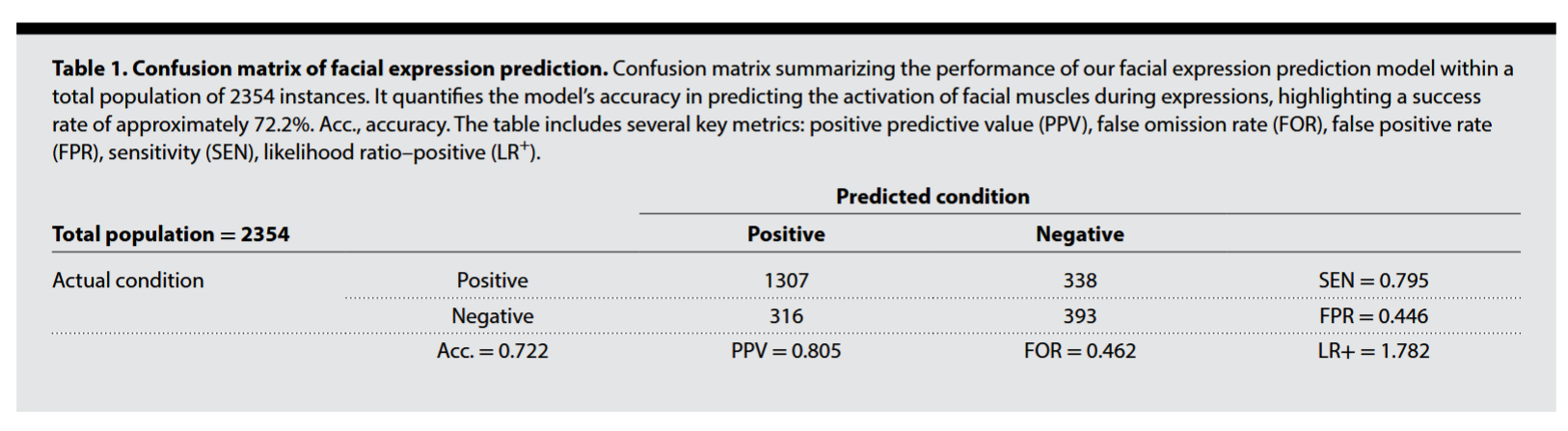
混淆矩阵分析 :模型预测面部肌肉激活的准确率约为 72.2% ,阳性预测值(PPV)达到 80.5% 。

物理机器人演示
- 对比实验 :作者让 Emo 机器人分别使用"共表情模式"(预测)和"模仿模式"(延迟)与人类互动,突出了共表情模式的同步性和真实感,以及模仿模式中滞后反应的人工感 。
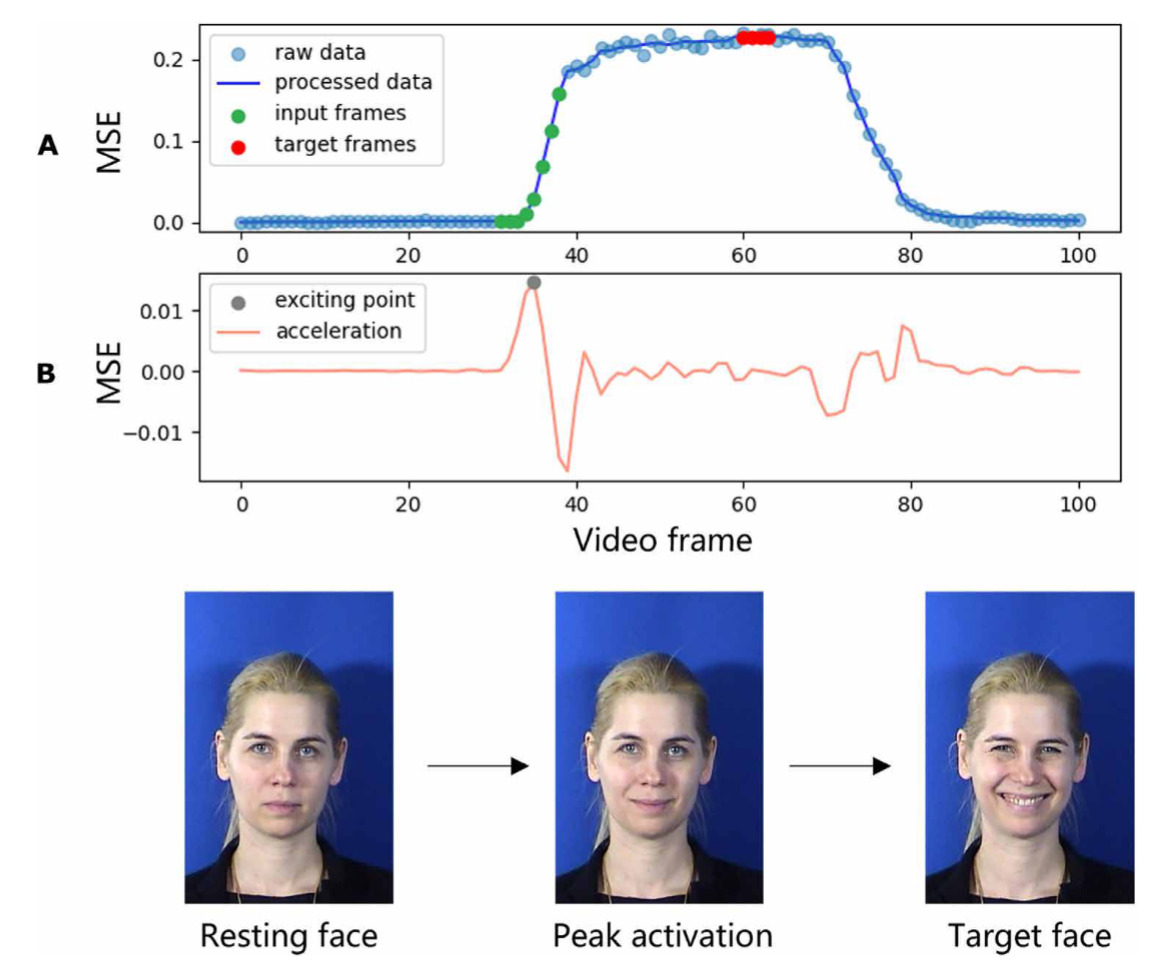
- 结果 :
- 在共表情模式下,机器人能够在人类微笑开始后的极短时间内(预测耗时仅 0.002秒,留出 0.839秒给机械执行)同步做出微笑动作,视觉上几乎完全同步 。
- 在模仿模式下,机器人会有明显的滞后,看起来是在人类笑完之后才笑 。
贡献
- 硬件创新:设计了具有 26 个自由度、眼部嵌入摄像头且易于维护(磁性皮肤)的高级面部机器人 Emo 。
- 算法框架:提出了结合"自我模型"(逆向运动学)和"对话者模型"(表情预测)的学习框架,无需人工标记数据即可实现复杂的表情控制。
- 交互范式转变:证明了机器人可以通过学习面部微表情来预测人类意图,从而实现从"被动模仿"到"主动共情/共表情"的跨越,为更自然的人机交互(HRI)奠定了基础 。