
VLM+机器人,这次又统一了什么?
------首次量化具身推理能力
目录
[01 关键设计](#01 关键设计)
[具身推理基准 ERIQ(Embodied Reasoning Intelligence Quotient)](#具身推理基准 ERIQ(Embodied Reasoning Intelligence Quotient))
[02 实验](#02 实验)
[03 结语](#03 结语)
VLM 的泛化性真能无损传递到动作吗?这一核心疑问正是 VLA 模型发展的深层桎梏。当前的 VLA 模型主要沿着两个方向发展,但均未能破解这一传递难题:
- **一是侧重高层空间推理与多模态感知:**能解析指令、生成合理操作步骤,但长时间任务中执行精度不足、偏差累积;
- **二是侧重低层高精度动作执行:**特定任务下轨迹稳定,但泛化能力弱,环境或指令变化后易 "知行割裂"。
更根本的挑战在于:当任务失败时,系统无法明确归因------
究竟是 VLM 的泛化性未有效转化为正确的高层推理(如任务分解不合理、空间关系理解有误),还是推理本身正确但泛化性在向动作传递中受损,被低层执行中的累积误差所破坏?
针对这一诊断困境,智元 AgiBot 聚焦通用机器人系统在开放世界环境中的核心挑战,提出了 "推理 - 精度协同优化" 的完整框架,为 VLA 模型提供了 "推理能力诊断工具",无需依赖端到端任务执行即可评估核心能力。
架核心包含三大核心组件 和一套系统验证体系:
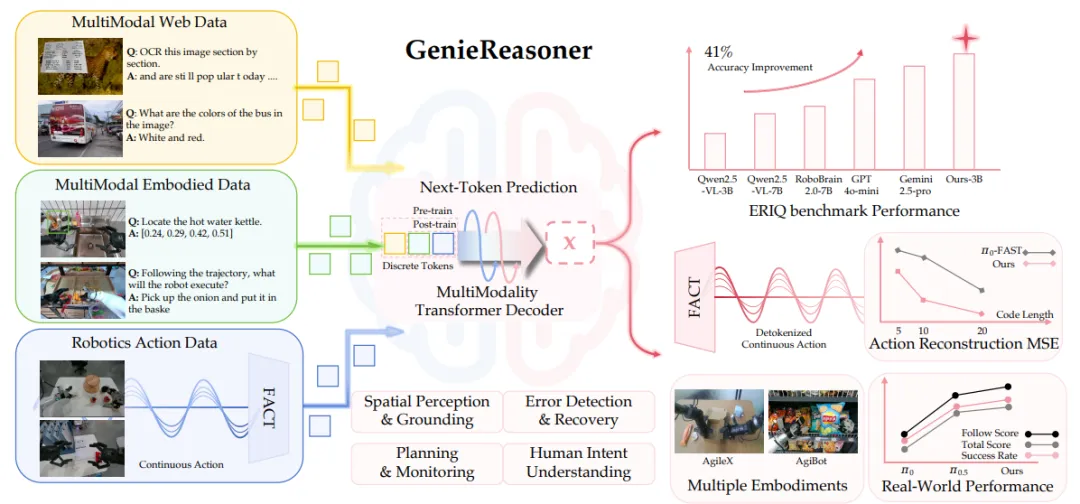
ERIQ 具身推理基准:解耦推理与执行的评估工具,量化 VLM 的具身推理能力(含空间感知、规划监控等四大维度);
FACT 动作分词器:离散 - 连续适配桥梁,通过流匹配技术实现紧凑 token 与高精度动作轨迹的双向转换;
GenieReasoner 统一 VLA 系统:推理 - 执行协同框架,将 VLM 推理与动作生成纳入同一自回归模型,实现联合优化。
下面我们逐一了解。
01 关键设计
具身推理基准 ERIQ(Embodied Reasoning Intelligence Quotient)
不同于传统基于模拟环境的视觉--语言代理评估------
ERIQ 并不以整体任务完成度为衡量目标,而是致力于解耦并量化具体任务中的具身推理能力,从而刻画支撑泛化所必需的抽象认知水平。
通过构建这一基于真实机器人数据的评估套件,ERIQ 首次实现了在排除低层控制误差干扰的前提下,对预训练模型的高层推理能力进行独立、客观的检验。

▲图1 | ERIQ基准测试说明。来自四个主要具身推理类别的示例样本。
- 在实现上:
ERIQ 完全基于真实机器人数据,并统一采用确定性的视觉问答(VQA)形式(选择题或判断题),以消除开放式生成带来的评估歧义。
评测不关注任务是否被执行完成,而聚焦模型是否能够形成、维持并在必要时修正正确的任务结构。
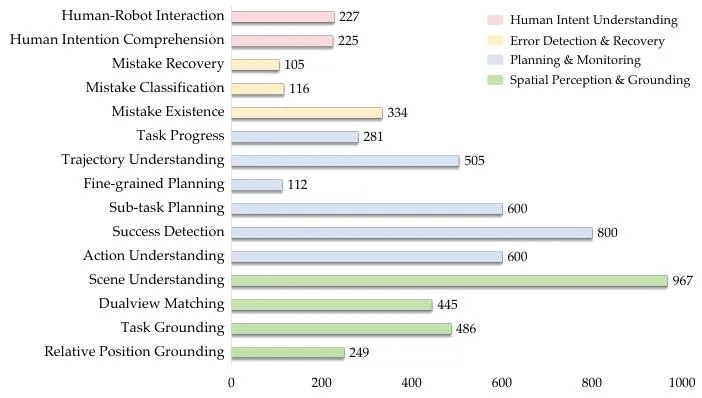
▲图2 | ERIQ基准在其15个细分子任务中的分布。
- 在能力划分上:
ERIQ 覆盖四类与实际操作直接相关的认知要素:
空间感知与定位、规划与过程监控、错误检测与恢复,以及人类意图理解。

整体包含 15 个子任务和 100余个真实场景,既考察静态理解能力,也系统评估模型在序列输入与图文交错语境下保持推理一致性的能力。
这一设计使具身推理首次成为一个可比较、可诊断的中间指标,为后续模型训练与系统迭代提供了更清晰的定位依据。
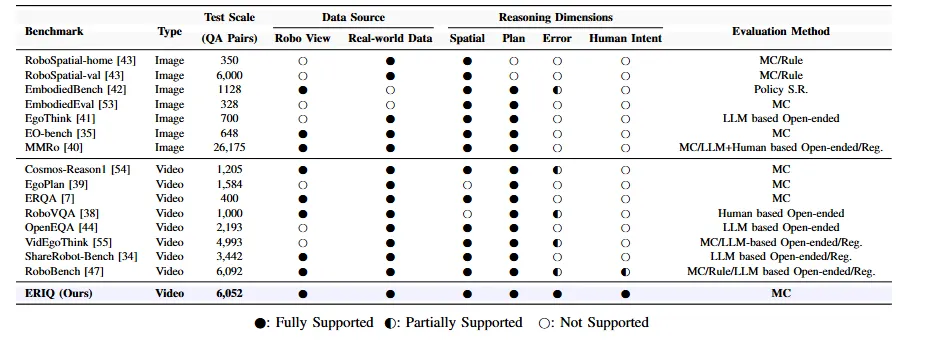
▲表1 | ERIQ与其他具身推理基准的比较相比,ERIQ在所有推理维度和物理数据属性上都实现了全面支持。
如表 1 所示,无论是大规模基准(如 MMRo)还是专门面向规划的基准(如 EgoPlan),评测重点仍集中在空间或规划能力上,对错误恢复与人类意图理解仅提供零散支持甚至完全缺失。
ERIQ 是目前唯一同时全面覆盖 "空间感知、规划监控、错误恢复、人类意图" 四大核心推理维度的基准,填补了现有基准对 "高阶认知能力"(如错误恢复、人机协作)评估的空白。

FACT解码器
很多人把 FACT 里的流匹配理解成:又一次把 Flow Matching 用在机器人动作上。
但从这张结构图里可以看得很清楚:并不是在用流匹配"生成动作",而是在刻意改造它的系统位置,让它只承担一个受控、单一的职责。
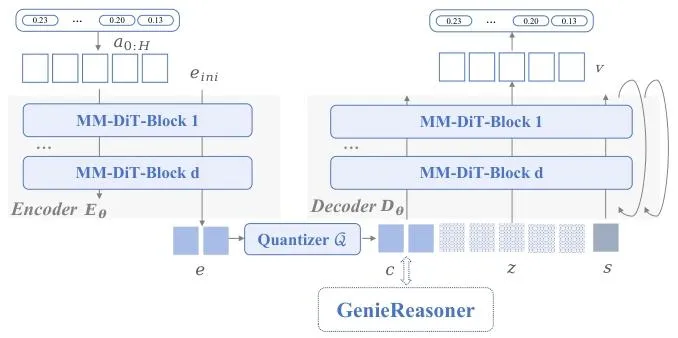
▲图3 | FACT动作分词器。VQ编码器将连续的机器人动作离散化为紧凑的标记,从而使视觉语言模型能够进行自回归建模。为了保持控制精度,解码器利用流匹配从量化标记和高斯噪声z中重建平滑、连续的轨迹。
在传统用法中,Flow Matching 通常是整条链路的终点:
模型从噪声出发,直接生成一段完整的连续动作,既决定"动作是什么",也决定"动作怎么走"。
而在 FACT 中,这个角色被拆解了。
图中左半部分的 Encoder 先把连续动作 压缩成连续变量
,再经过 Quantizer 变成离散的动作 token
。
真正的"动作决策"发生在这里:将连续的动作片段压缩为简洁的离散标记, 这将复杂的物理动力学转化为与 VLM 模型兼容的统一词汇。
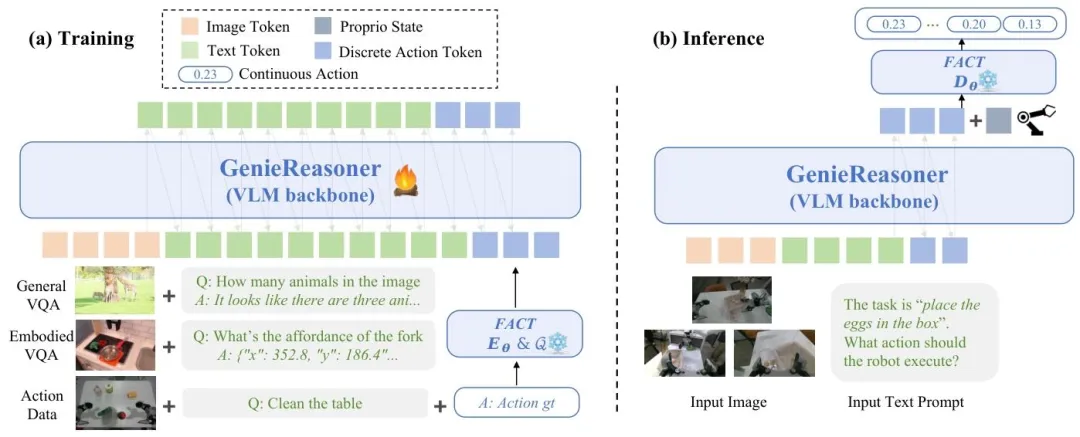
▲图4 | GenieReasoner系统架构。(a)训练:我们的统一管道通过将连续动作 token 化到离散潜在空间中,联合优化用于多模态推理和机器人控制的VLM主干。(b)推理:VLM主干生成的离散动作代码通过FACT解码器解码为连续控制信号,确保高精度操作在任务指令中具有语义基础。
右半部分的 Decoder 才引入流匹配。
Flow Matching 在这里被从"生成器"降级为一个还原器:它不能决定动作语义, 只能在既定语义下补足物理精度。
这一推理过程连接了高层推理和低层电机控制:Encoder部分生成离散且基于语义的动作标记,而decoder部分则确保高保真度和物理可行的运动重建。
02 实验
实验验证不同载体(AgiBot G01、AgiBot Genie仿真、AgileX、ARX)的空间推理、子任务规划和思维链(CoT)推理。
在零样本条件下,模型展示了无需特定任务适配的强大空间和因果推理能力。

▲图5 | 视觉语言模型(VLM)多任务推理能力的定性可视化。
在相同的压缩代码长度下,FACT实现了比FAST+低一个数量级的均方误差(MSE)。
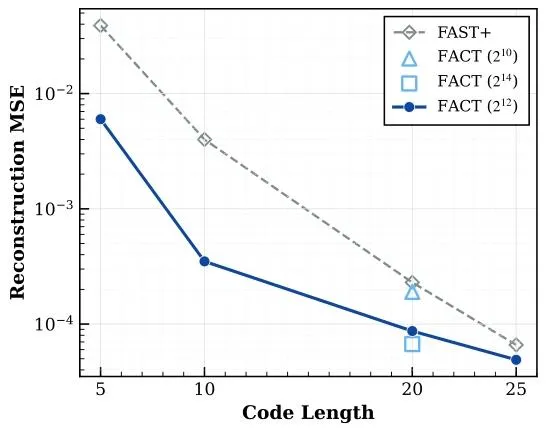
▲图6 | 重建保真度分析。
这证实了流匹配解码器提供了从离散标记回到连续动作的更具表现力且更稳定的映射,从而实现了更紧凑、更准确的动作表征。
通过利用FACT动作分词器来连接离散推理和连续控制,GenieReasoner在指令遵循能力上优于离散基线模型(如π0-FAST),同时在任务成功率上超过连续模型(如π0.5),最终实现了最先进的综合性能。
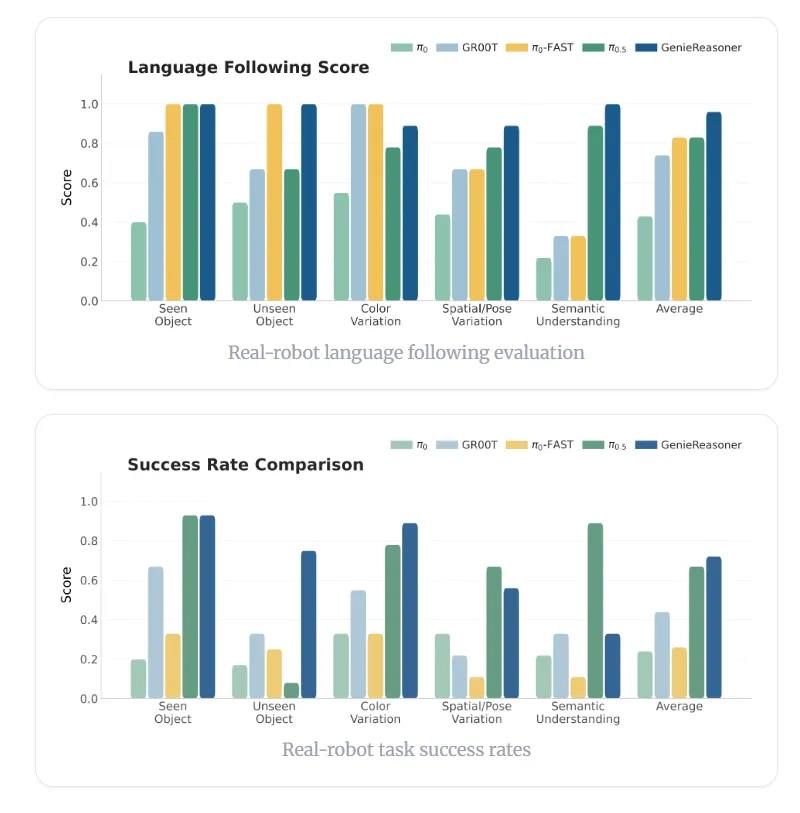 ▲图7 | 真实机器人语言遵循评估与成功率对比。
▲图7 | 真实机器人语言遵循评估与成功率对比。
03 结语
这篇工作把 VLA 里最容易"失控"的部分重新分配了责任:
- VLM 负责维护离散动作结构(计划稳定性);
- 生成式解码器负责恢复连续轨迹(控制精度);
- ERIQ 负责把"推理问题"从"控制问题"里剥离出来(可诊断性)。
基于这一分工,GenieReasoner 不再让推理与控制相互干扰,而是在单一自回归框架下实现协调而非混合的优化。
ERIQ 与 FACT 共同构成了一个有原则的框架,用于诊断并缓解推理与精度之间的结构性权衡。
为更稳健、更通用的机器人操作系统提供了清晰的工程路径。

论文题目:Unified Embodied VLM Reasoning with Robotic Action via Autoregressive Discretized Pre-training
论文作者:Yi Liu, Sukai Wang, Dafeng Wei, Xiaowei Cai, Linqing Zhong, Jiange Yang, Guanghui Ren, Jinyu Zhang, Maoqing Yao, Chuankang Li, Xindong He, Liliang Chen, Jianlan Luo