如果把大模型推理想成一家"无限续杯"的奶茶店:Prefill 是点单+做糖度(一次性但很重) ,Decode 是一杯一杯出货(很碎但要不停)。你要做的不是"把奶茶师傅骂得更快",而是把整条链路里真正拖后腿的那段揪出来:是前台收银慢(CPU/调度)?是后厨搬货慢(HBM/KV cache)?还是出杯流程太串行(decoding)?
本路线图的核心打法:先证据链(Profiling)→ 再换发动机(Runtime)→ 再修水电煤(Attention/KV)→ 再做减肥(Quant)→ 再改排队规则(Decoding)→ 最后做店面分区(Prefill/Decode 解耦) 。每部分都配一句 insight,一个信息流示意图(便于理解),并且按 基础 / 进阶 / 高级 (BASIC / INTER / ADV) 三个层次展开,便于系统学习。同时,为了检验是否理解,给出验收标准 。其中,主要内容(内容中的配图是为了快速浏览,篇幅有限并未详细解释,只为产生感性认识。 )的选择标准是最新并且尽量"经典"的内容。部分内容需要在不同维度进行解读(并不是重复)!
资料分类mark : P Paper T Tutorial/Doc C Code/Repo B Benchmark S System/Stack
一屏总览:
S0 从"测"到"拆"的 7 站路线S0 先测:指标/Profiling → 证据链
S1 选栈:vLLM / SGLang / TRT-LLM → 运行时决定上限
S2 攻坚:Attention/KV cache → 解决"搬不动"
S3 量化:W8A8 / INT4 / KV-Quant → 用比特换带宽/显存
S4 解码:Speculative / Medusa / EAGLE-2 / BlockVerify → 少串行
S5 架构:Prefill/Decode 解耦(DistServe/Splitwise/TaiChi)→ 去互扰
S6 回归:GenAI-Perf / MLPerf → 没有回归就没有优化
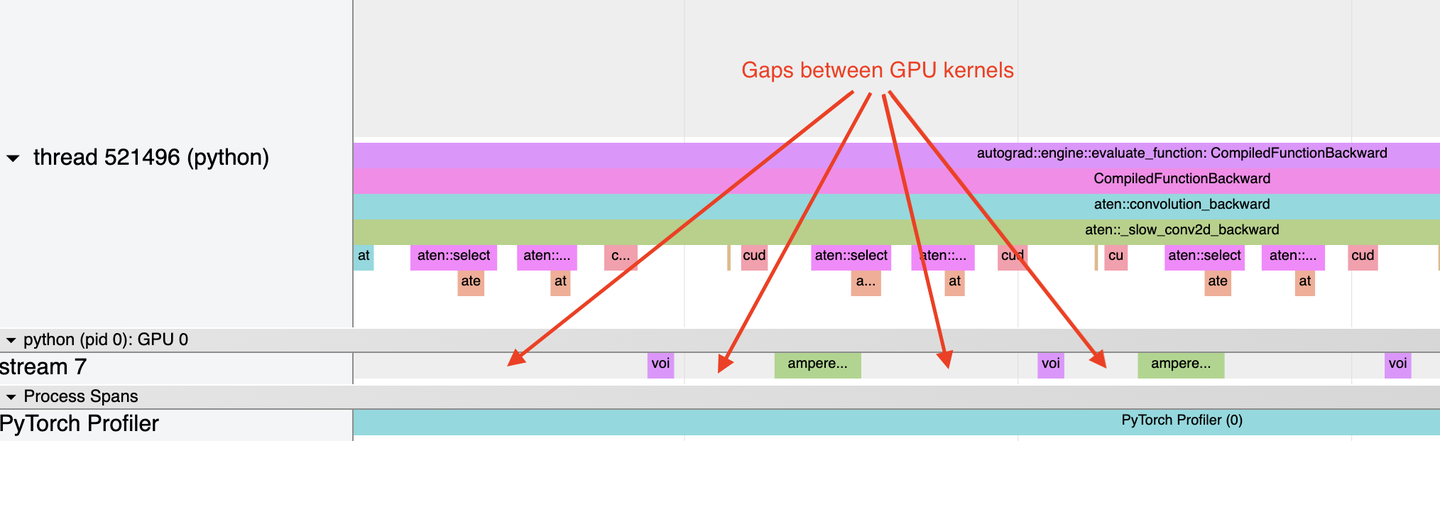
S0:Profiling 与指标("抓现行")
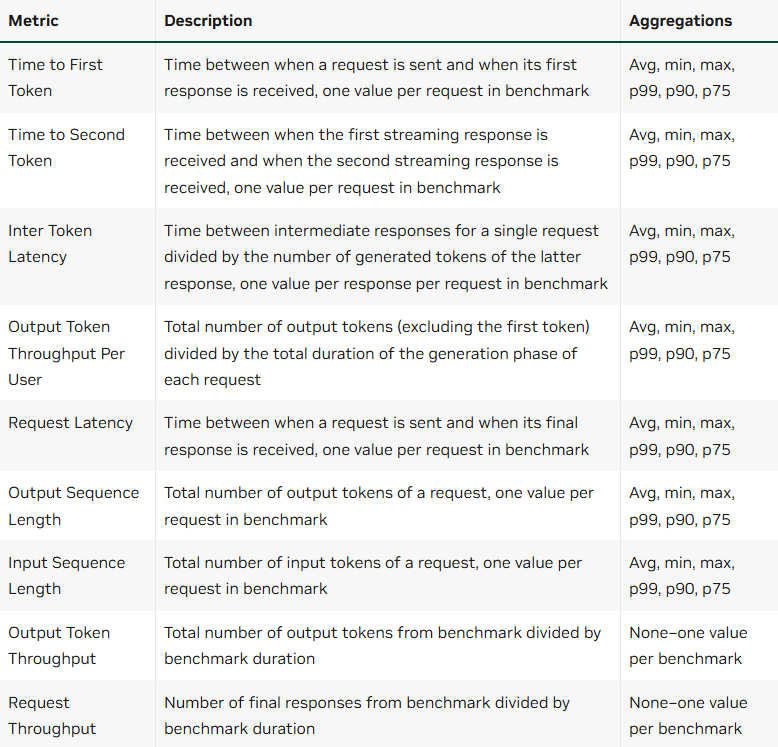
一句 insight:你优化的不是"token/s",而是TTFT(第一口)+ TPOT(续杯速度)+ tail latency(最难伺候的那 5% 用户) ;GenAI-Perf 这类工具把口径直接打包好了。
信息流示意图(S0)
请求 → tokenize → prefill(大矩阵) → decode(循环) → sampling/输出
| | |
v v v
TTFT相关 GPU算子/带宽 TPOT/尾延迟
\______________ Profiling ______________/
nsys(系统级) + ncu(kernel级)BASIC
- T (BASIC) torch.profiler:PyTorch 官方剖析,定位算子、shape、trace 的起点。
- T (BASIC) Nsight Systems User Guide:看 CPU→GPU 提交、Memcpy、并发,判断"是不是 host 在拖后腿"。
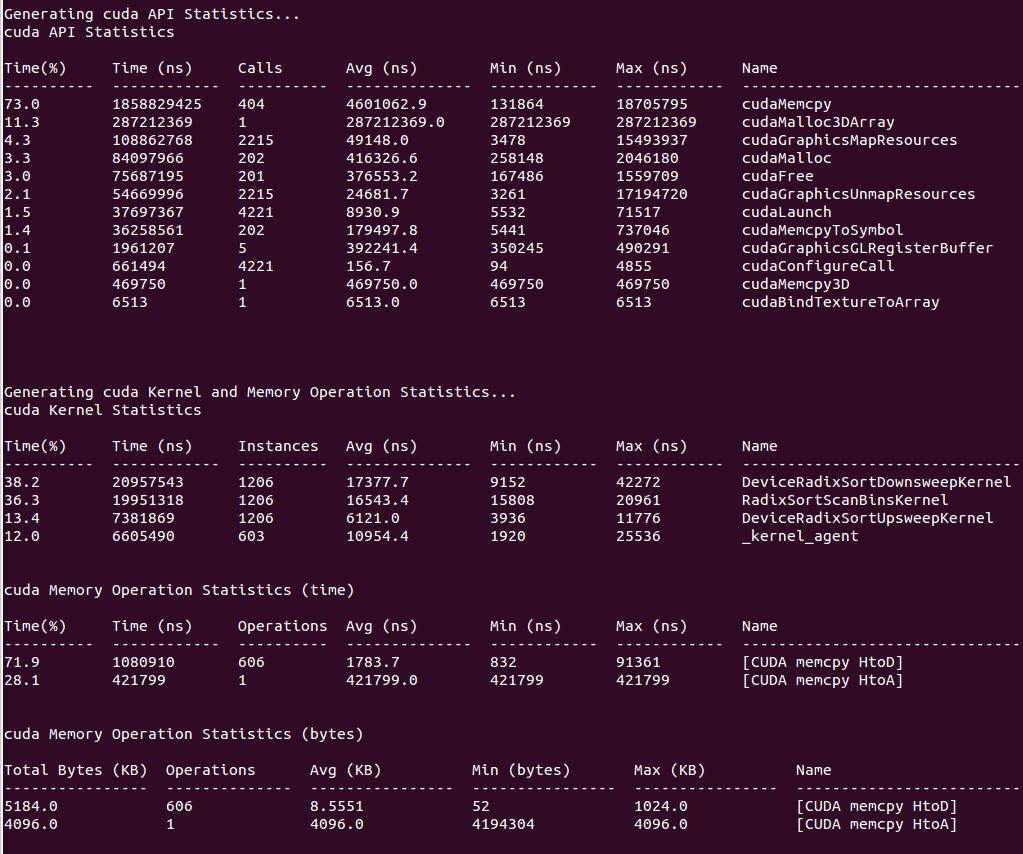
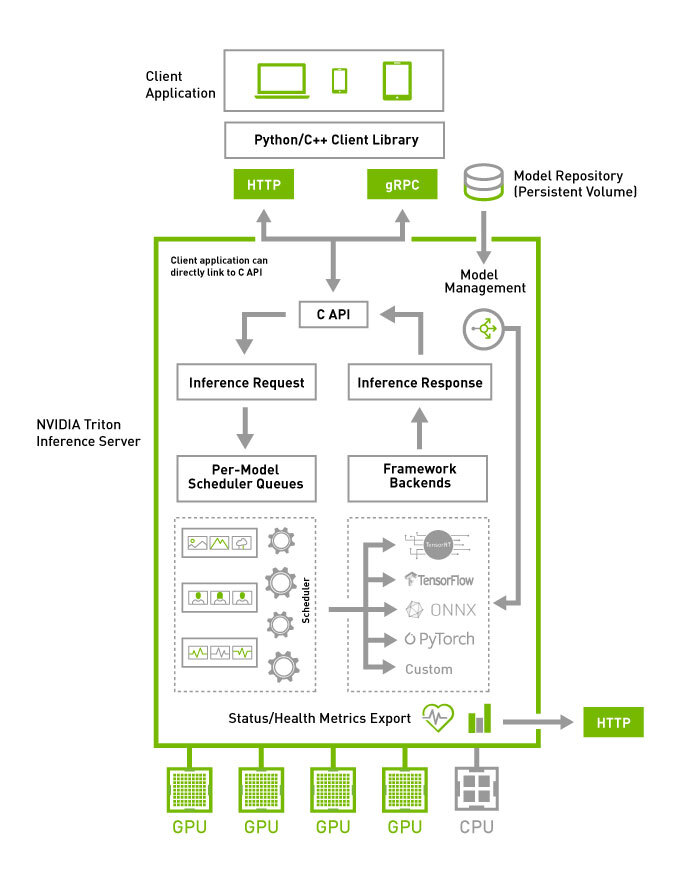
- T (BASIC) Triton Inference Server Quickstart:最标准的在线推理"容器化基线"。
INTER
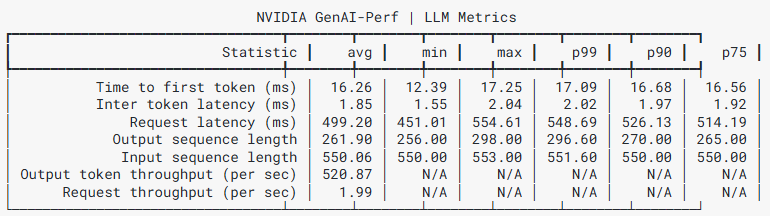
- T (INTER) GenAI-Perf:直接给出 TTFT / TPOT / token throughput 等 LLM 关键指标,适合做压测回归。
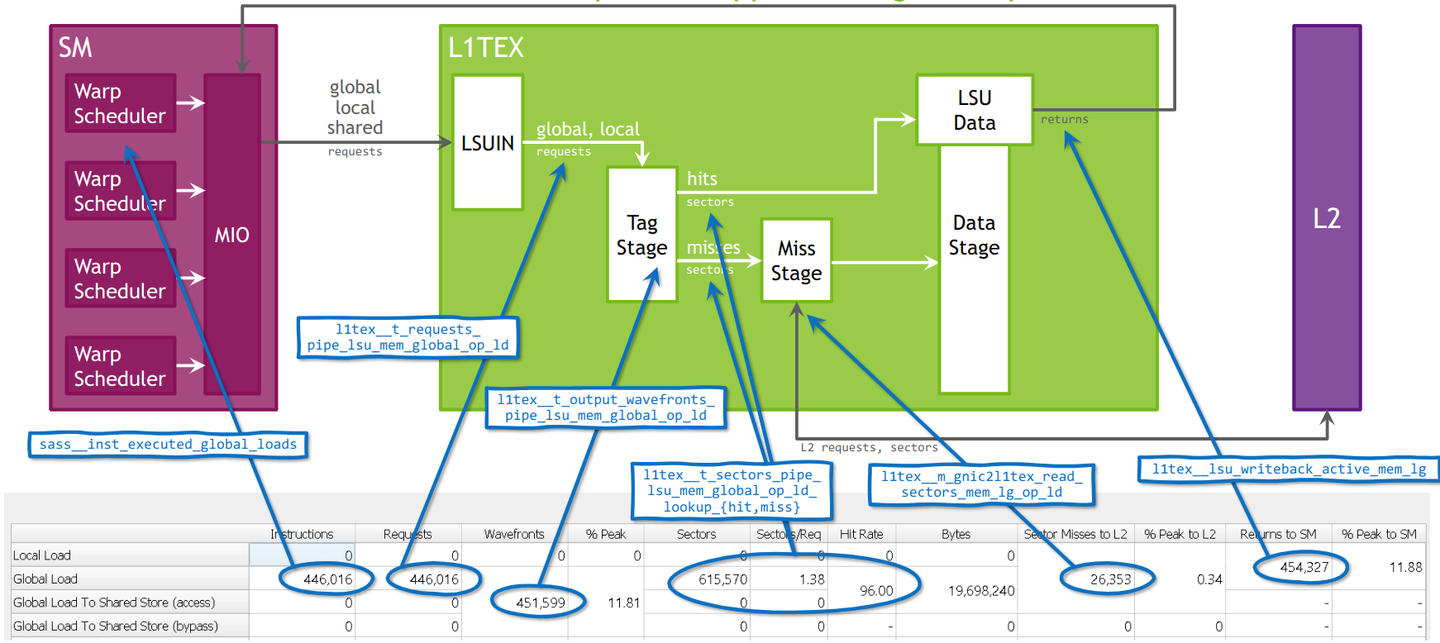
- T (INTER) Nsight Compute Profiling Guide:下钻到 kernel 级别,知道 SM、Memory、Tensor Core 谁在摆烂。
- T (INTER) PyTorch "profiling torch.compile performance":专门用来抓 graph break、编译收益与损耗。
ADV
- B (ADV) MLPerf Inference(Datacenter):最权威的"别人怎么测、你也怎么测"的基准入口。
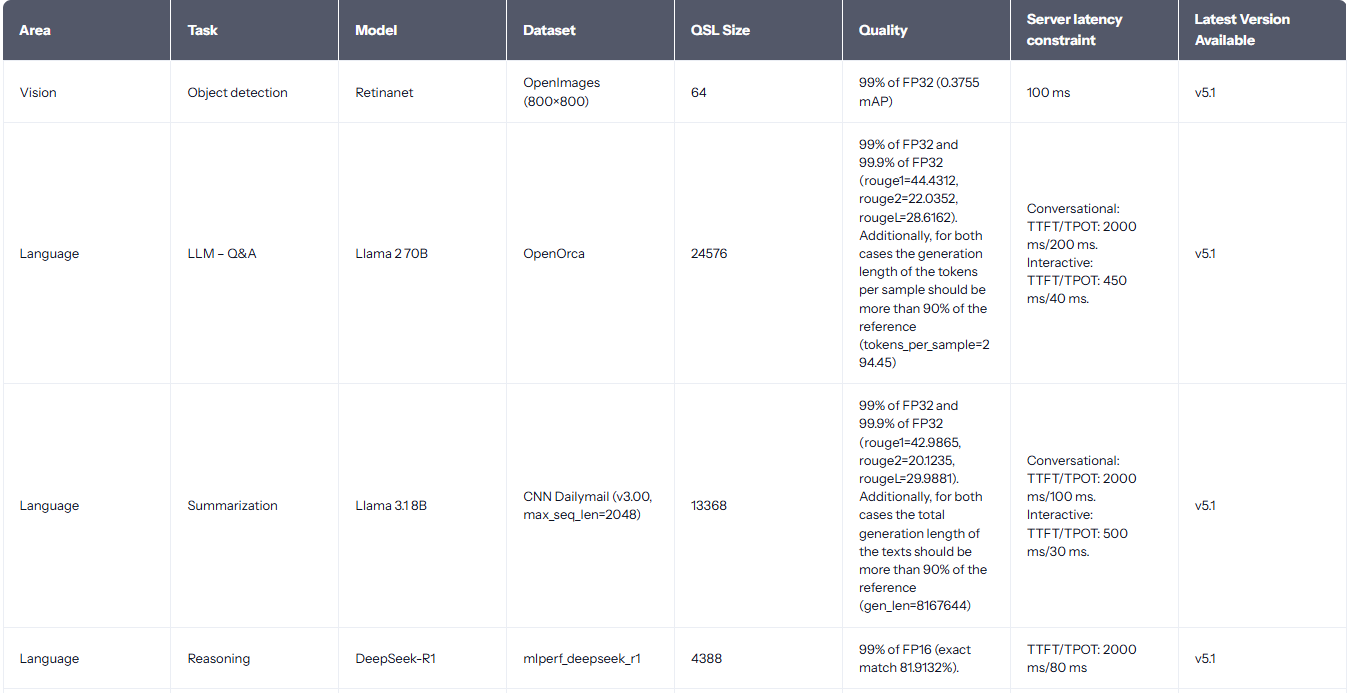
- T (ADV) MLPerf Inference v5.0 LLM 任务解读:理解低延迟 LLM benchmark 的新口径与趋势。
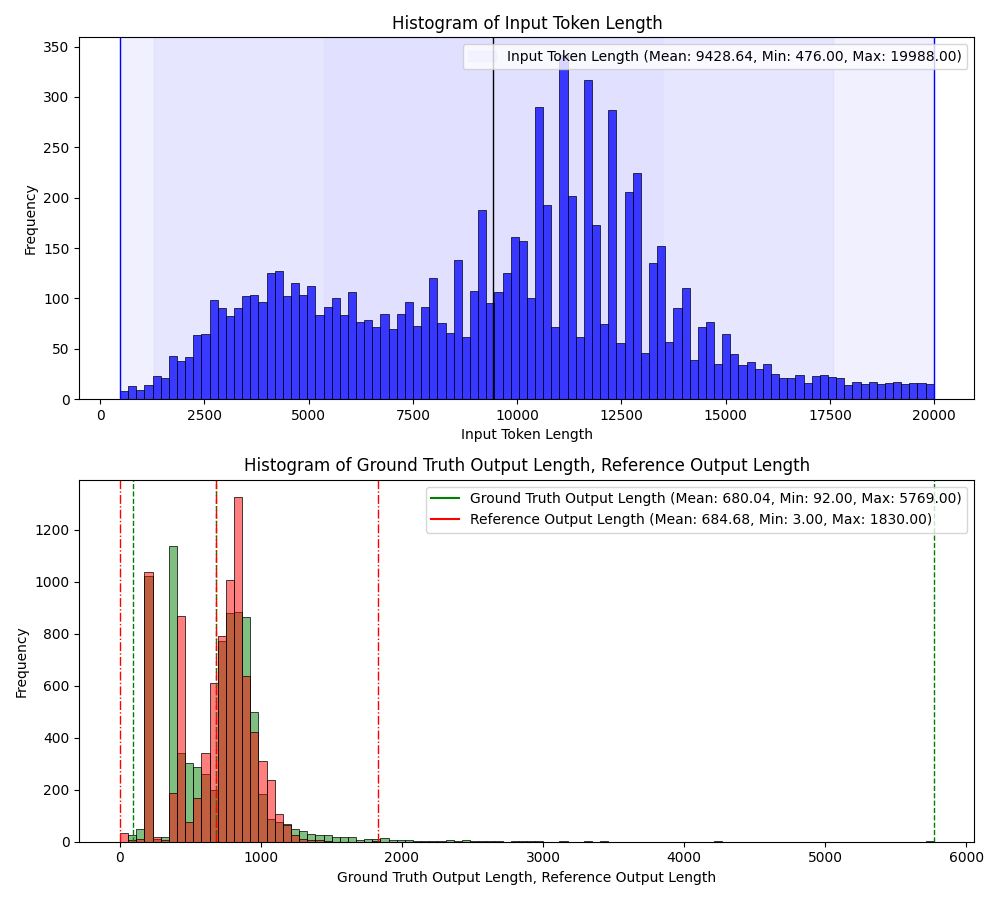
- C (ADV) GenAI-Perf analyze/sweep:把"单点测量"升级为"参数扫描+自动报告"。
验收标准 checklist
- 能同时报告:QPS、TTFT、TPOT、token/s、P50/P95(至少 5 个指标)。
- 能用 nsys 说明:瓶颈在 host、PCIe/NVLink、kernel、mem 哪一层。
- 能用 ncu 说清:关键 kernel 的 memory bound vs compute bound。
- 能写出一份"一页纸"性能报告模板。
- 能给出优化优先级排序(不是"我觉得",是"证据链")。
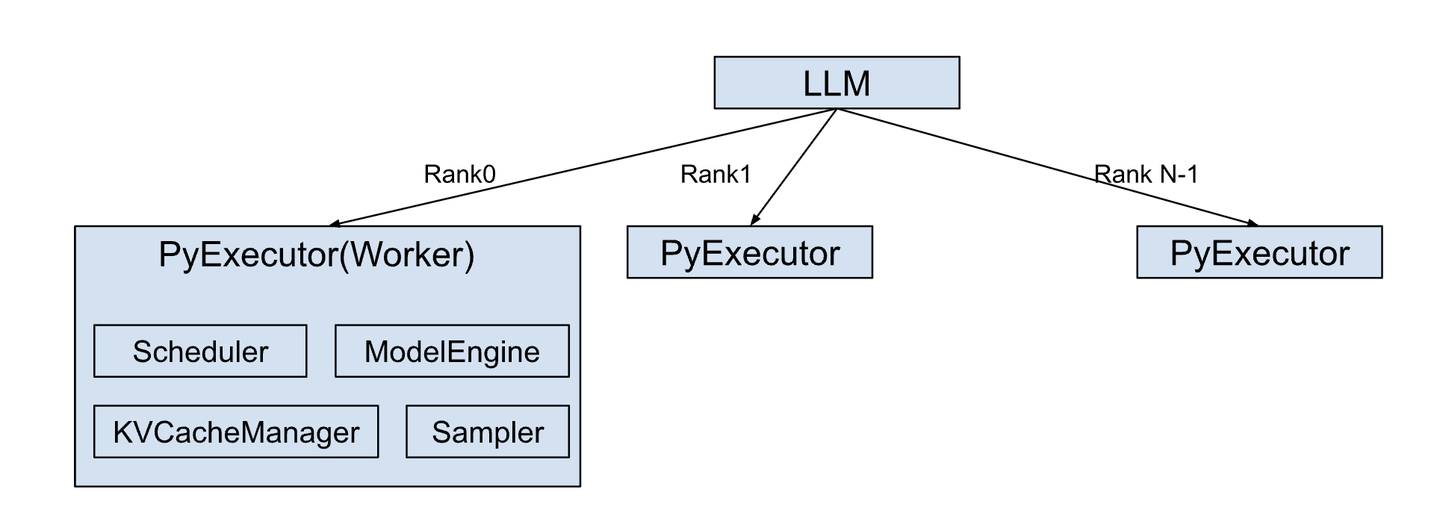
S1:Serving Runtime("发动机"选型)
一句 insight:运行时的差异很多不在"算得更快",而在KV 管理、调度、continuous batching这些"像操作系统"的能力;例如 vLLM 的 PagedAttention 把 KV cache 做到近似"零碎片"的系统化管理。
信息流示意图(S1)
用户请求流
↓
[Scheduler/Batcher] ------ 决定并发与排队策略
↓
[KV Cache Manager] ------ 决定显存占用/碎片/复用
↓
[Kernel Backend] ------ FlashAttention/FlashInfer/TRT 等决定单步效率
↓
输出指标:TTFT/TPOT/吞吐/稳定性推理框架的差别,很多时候不在"算得快",而在"缓存、调度、批处理"这些"脏活累活"谁做得更像操作系统。
BASIC
- P (BASIC) vLLM / PagedAttention:把 KV cache 当"虚拟内存分页"来管,显著降低碎片与浪费。
- C (BASIC) vLLM repo:连续 batching、paged KV、speculative、chunked prefill 等实战特性全集。
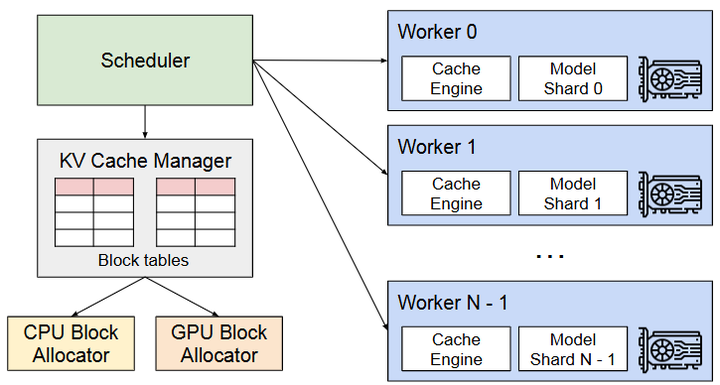
- T (BASIC) vLLM 官方博客(PagedAttention 入门):用最少背景理解"为什么吞吐能起来"。
INTER
- P (INTER) SGLang:前端语言 + 运行时,靠 RadixAttention(KV 复用) 和 cFSM(结构化输出加速) 提升吞吐。

- C (INTER) SGLang repo:把"复杂 agent/多次生成/JSON 输出"从工程灾难变成可控系统。
- T (INTER) SGLang 文档站:把 runtime 能力、部署方式、特性讲清楚。
ADV
- C (ADV) TensorRT-LLM:NVIDIA 官方"重装机甲",含 paged KV、inflight batching、量化、speculative 等。
- T (ADV) TensorRT-LLM 文档:工程落地导向(部署、serve、API)。
- T (ADV) MLC LLM + microserving:把 prefill-decode 解耦 等"跨引擎编排"做成可编程 API。
验收标准 checklist
- 能用同一模型在 vLLM 与 SGLang 跑出可对比的 TTFT/TPOT。
- 能解释:continuous batching 与传统 batching 的差异与收益点。
- 能说清楚:KV cache 的生命周期、碎片问题、以及框架如何缓解(PagedAttention/RadixAttention)。
- 能把推理链路拆成:tokenize→prefill→decode→sampling→postprocess(并标出每段耗时)。
- 能给出"选型建议":低延迟、长上下文、多并发、结构化输出,各用哪个栈更合理。
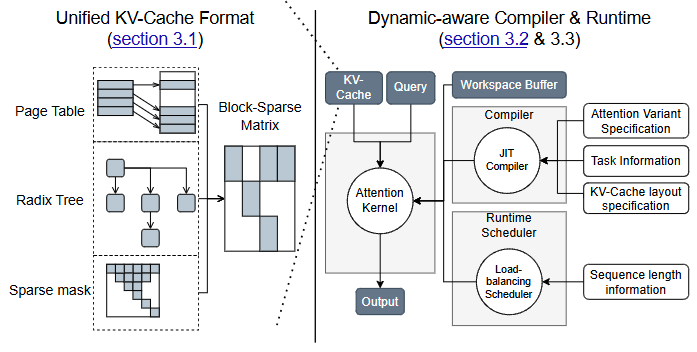
S2:Attention & KV Cache("水电煤")
一句 insight:很多 decode 不是"算不动",而是"搬不动",KV cache 的读写把你卡在带宽上;FlashAttention-3/FlashInfer 这类工作本质是在把 attention 这段"搬砖流水线"改造成更少停顿、更高利用率。
信息流示意图(S2)
每步 decode:
token → Q
历史 → K,V (KV cache 读取) ←------ 真正的大头:带宽/布局/碎片
↓
Attention(Q,K,V) (FlashAttention-3 / FlashInfer 等优化这里)
↓
写回新的 K,V 到 KV cacheBASIC
- P (BASIC) PagedAttention(vLLM):KV cache 管理的系统化范式。
- P (BASIC) FlashAttention-3:在 Hopper 上把 attention 利用率拉高,主打"又快又准"。

- T (BASIC) vLLM 中对 FlashAttention/FlashInfer 的集成说明:知道"框架如何吃到 kernel 红利"。
INTER
- P (INTER) FlashInfer:可定制 attention engine + 调度,面向 serving 的"可组合格式/异构 KV 存储"。
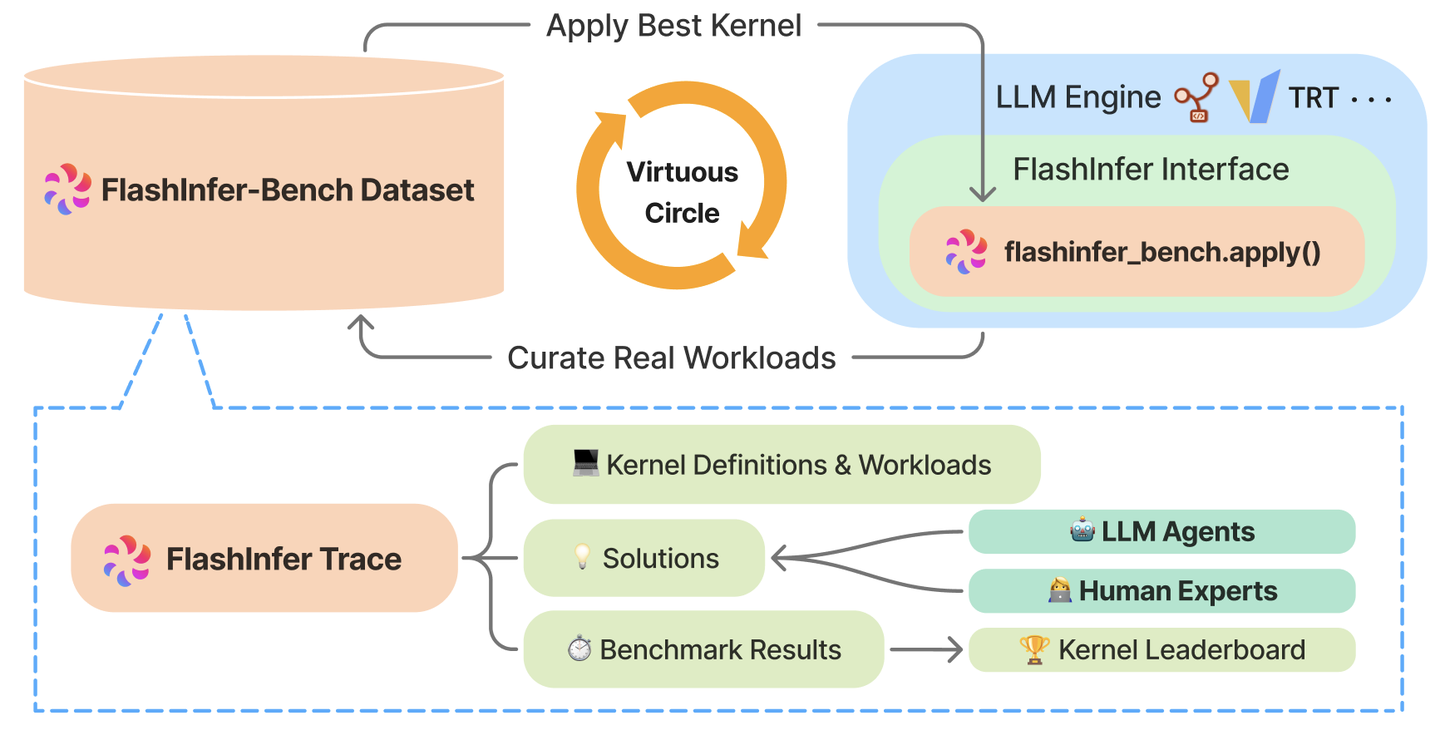
- P (INTER) FlashInfer-Bench:用真实 trace 把"AI 生成 kernel→基准→替换上线"做成闭环。
- T (INTER) FlashInfer 官方文章(bench 介绍):理解为什么基准要贴近真实 serving trace。
ADV
- P (ADV) KIVI(2-bit KV cache 量化):把 KV cache 的 key/value 分别按更合理粒度量化,释放显存换吞吐。
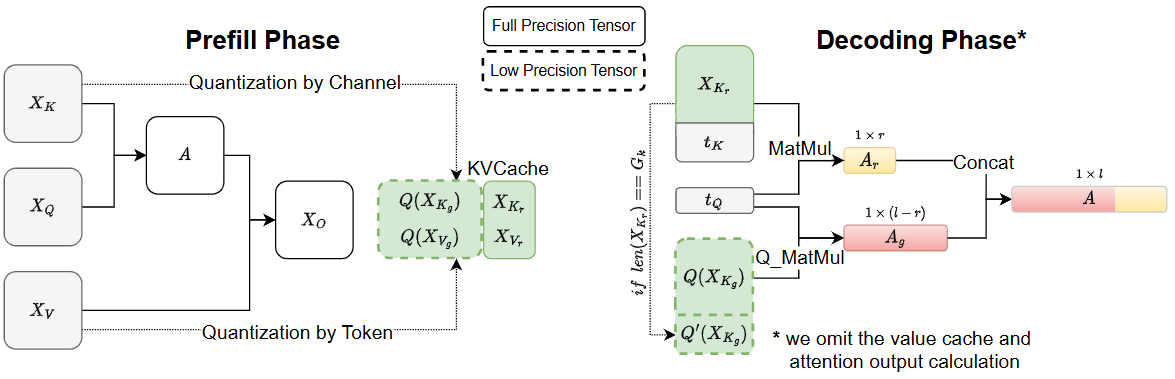
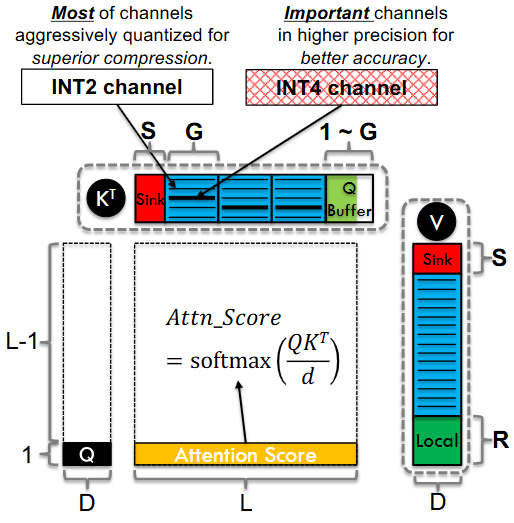
- P (ADV) Kitty(2-bit KV cache,动态精度提升):进一步追求"2-bit 也要稳"。
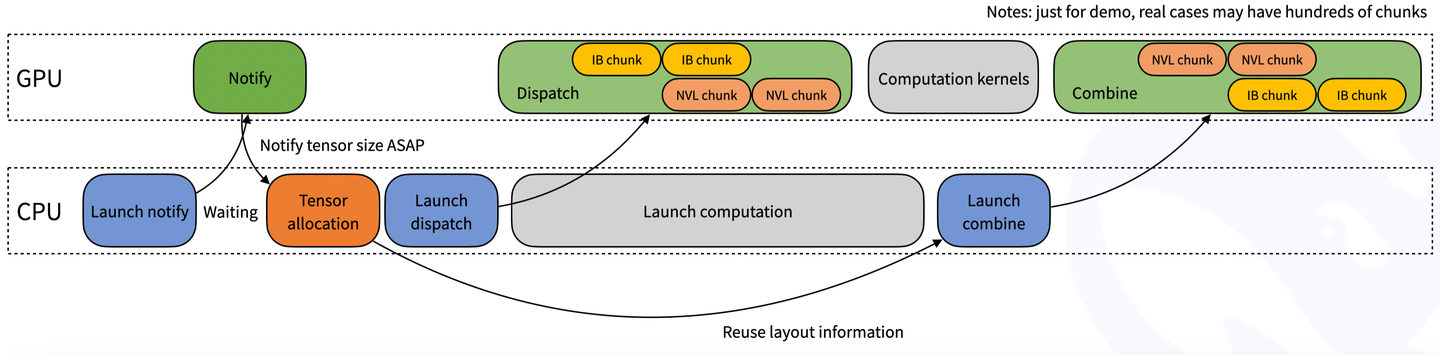
- C (ADV) DeepGEMM(FP8 GEMM kernels):当你需要更底层的 GEMM 能力(尤其 Hopper/新架构)。同时,需要优化通讯能力(参考DeepEP)
验收标准 checklist
- 能解释 attention 推理时的主要数据流:Q/K/V、KV cache、softmax、写回。
- 能在长上下文场景下,复现实测:FlashAttention/FlashInfer 带来的收益(至少一个指标提升)。
- 能用"带宽/算力"两句话说明:为什么 decode 往往更 memory-bound。
- 能给出 KV cache 的显存占用公式,并据此估算 batch 上限。
- 能提出 2 个"KV cache 相关"的优化动作,并说明副作用(精度/延迟/工程复杂度)。
S3:Quantization("减肥,但别减成贫血")
一句 insight:量化是把瓶颈从"HBM/带宽/显存"搬到"算子实现/数值误差";典型路线是 SmoothQuant(W8A8)、AWQ/GPTQ(weight-only INT4/INT3),以及更激进的 KV cache 量化(KIVI)。
信息流示意图(S3)
模型(权重/激活/KV)
↓ 选择目标:省显存?省带宽?提吞吐?
[W8A8: SmoothQuant] ------ 更通用、工程友好
[INT4 weight-only: AWQ/GPTQ] ------ 更省显存/带宽,但看kernel与batch
[KV Quant: KIVI] ------ 长上下文/大并发时更"对症"
↓
上线前必须:质量/稳定性 + 性能回归(TTFT/TPOT)BASIC
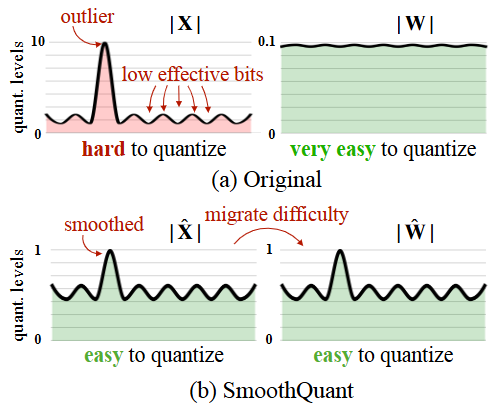
- P (BASIC) SmoothQuant(W8A8):把 activation outlier 难题"搬家"到 weights,工程可落地。
- P (BASIC) GPTQ:经典 PTQ weight-only(3/4bit)路线,精度与速度的常用起点。
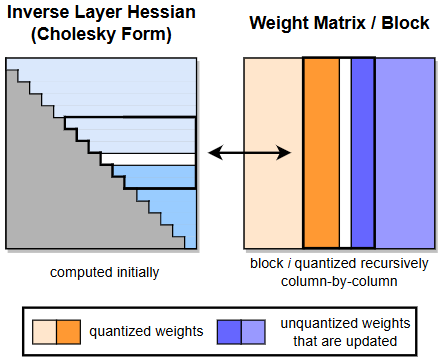
- P (BASIC) AWQ:用 activation 分布找"关键权重通道",4-bit 更稳更硬件友好。
INTER
- C (INTER) TensorRT-LLM 的量化能力概览:把 FP8/INT4/AWQ/SmoothQuant 等做成可用工具链。
- P (INTER) Marlin(FP16×INT4 matmul):让 INT4 真正"吃满 4x 理论收益"的核武器之一。
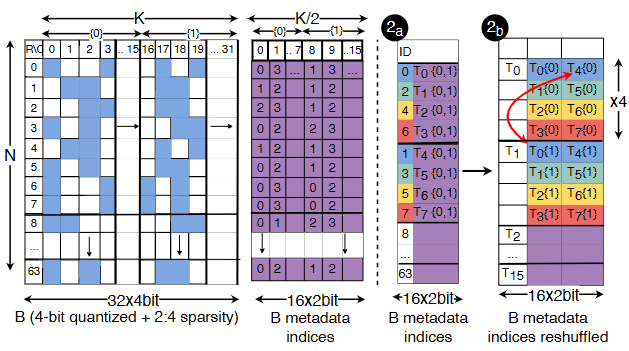
- C (INTER) MARLIN 实现:工程上理解为什么"batch=1 很难快,但 batch=16~32 能接近理想"。
ADV
- P (ADV) KIVI /Kitty(KV cache 量化):当你的瓶颈是 KV cache 而不是 weights 时,别只盯 weight-only。
- C (ADV) vLLM 的多种量化接入(GPTQ/AWQ/FP8/INT8 等):关注"能不能稳定跑 + 能不能服务化"。
- T (ADV) Nsight Compute 指标体系:量化后别只看 token/s,要看 memory/load/TC utilization 怎么变。
验收标准 checklist
- 能区分并选择:W8A8 vs weight-only INT4(场景、代价、收益)。
- 能在同模型上跑通:FP16 baseline 与 INT4(至少一种)并输出精度对比。
- 能解释:为什么有时"更低 bit 反而更慢"(kernel/packing/带宽/并行度)。
- 能给出"量化失败排查清单"(数值爆炸、输出退化、吞吐无提升)。
- 能写出一个可复用的"量化评测脚本"(吞吐+延迟+简单质量指标)。
S4:Decoding("把串行改成少串行")
一句 insight :Speculative 的关键不是"猜",而是"猜一串、验证一串":Speculative Sampling 给了经典无偏加速框架;Medusa 用多头直接预测多 token;EAGLE-2 用动态 draft tree 更激进;Block Verification 在验证侧继续抠出 5--8% 的稳定增益。
信息流示意图(S4)
Target模型(慢但准) : 负责验证
Draft/Heads(快但糙) : 负责批量提案
循环:
Draft 生成 token1..k → Target 一次性验证 → 接受前缀 → 继续
| |
v v
提案越准/越快 验证越"成块"越省(Block Verification)BASIC
- P (BASIC) Speculative Sampling:经典 speculative decoding,2--2.5× 解码加速的起点。
- P (BASIC) Medusa:不用外部 draft model,通过多 decoding heads 预测多 token,再并行验证。
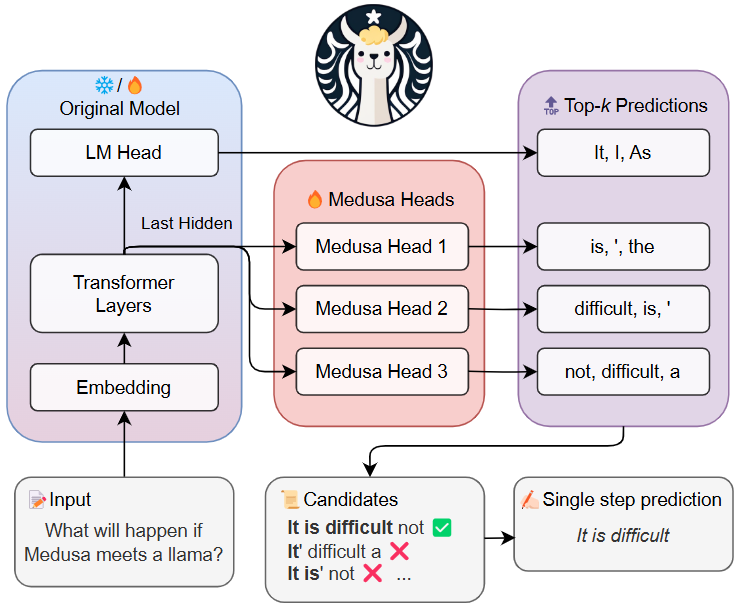
- C (BASIC) Medusa repo:快速复现"多头解码"的工程入口。
INTER
- P (INTER) EAGLE-2:动态 draft tree,靠校准的置信度更激进地产生可接受 token。
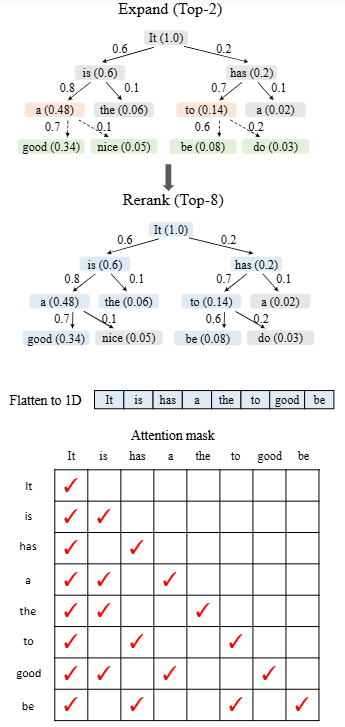
- P (INTER) Block Verification:把 token-level 验证升级为 block-level 联合验证,稳定榨出额外速度。

- C (INTER) vLLM / TensorRT-LLM 对 speculative 的支持:关注"能不能在 serving 上稳定收益"。
ADV
- P (ADV) "Decoding Speculative Decoding"系统化研究:当你要在产线上挑 draft 模型时,这类研究更值钱。

- T (ADV) SGLang的结构化输出加速(cFSM):很多场景不是"生成文本",而是"生成可解析结构"。
- T (ADV) GenAI-Perf:把 speculative 的收益拆成 TTFT/TPOT/acceptance 等可对比指标。
验收标准 checklist
- 能解释 speculative 的正确性保证(分布不变)与实现要点。
- 能在同模型上跑出:baseline vs speculative 的 TPOT 改善,并说明 TTFT 变化。
- 能给出"什么时候 speculative 不赚"的判断(任务、温度、draft 质量、batch)。
- 能输出一个"acceptance length/ratio"的统计图或表。
- 能提出 1 个"与量化/批处理/长上下文耦合"的风险点,并给规避策略。
S5:系统架构(Prefill/Decode 解耦:把"互相拖后腿"分手)
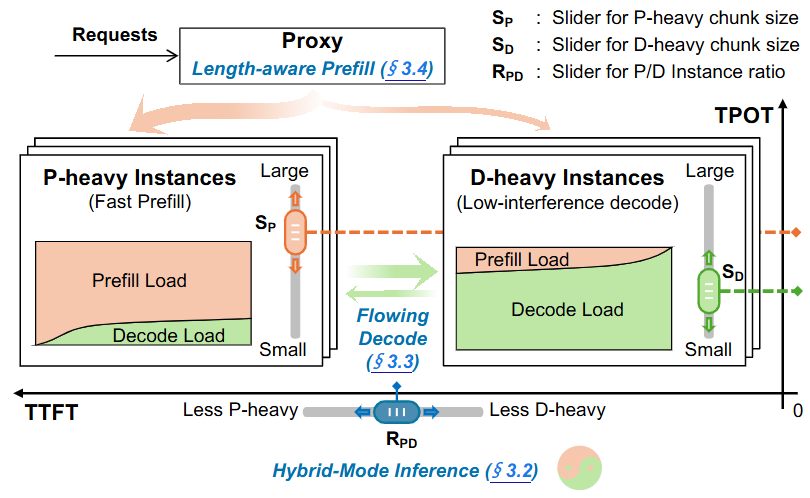
一句 insight: 把 prefill 与 decode 放一起做 batching,会造成强互扰与资源耦合;DistServe 从系统角度证明并实现了"拆开更好",Splitwise 把"提示处理/生成"分机器做成本与吞吐优化,而 TaiChi 则进一步给出"聚合与解耦统一、按 SLO 做 goodput 最优"的框架。这一块近两年非常关键:prefill-decode disaggregation 已经快速成为主流的"剧本"(尤其在大规模 serving)。
信息流示意图(S5)
(传统聚合)
请求 → [同一组GPU] prefill + decode 交织 → 互扰、尾延迟上天
(解耦 / 混合)
请求 → Prefill GPU池(擅长大矩阵) → KV/状态转移 → Decode GPU池(擅长循环出token)
↑
调度器按 SLO 做 goodput 优化(TaiChi 思路)BASIC
- P (BASIC) DistServe(OSDI'24):系统化论证并实现 prefill/decode 解耦,围绕 goodput 做调度。
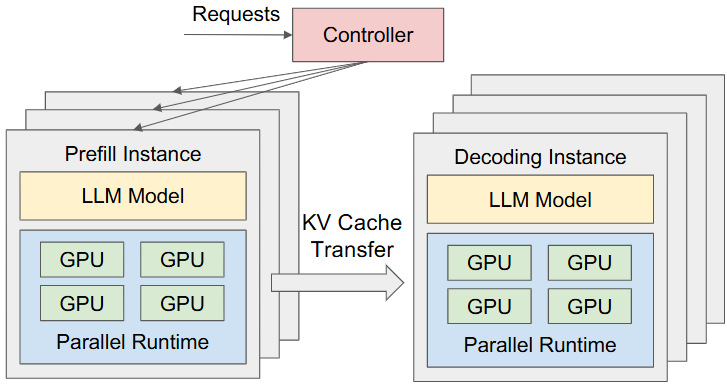
- P (BASIC) Splitwise(ISCA):用 phase splitting 设计同/异构集群,优化吞吐/成本/功耗。
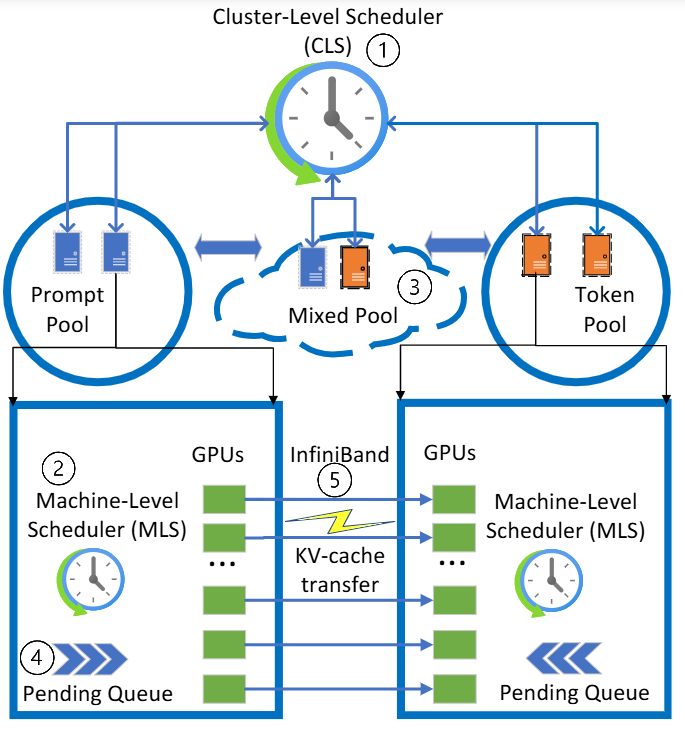
- T (BASIC) "Disaggregated Inference: 18 Months Later"总结:了解最近为何"突然变默认配置"。
INTER
- P (INTER) TaiChi(2025):把 prefill-decode 的"聚合/解耦"统一起来,面向不同 SLO 组合做最优 goodput。
- T (INTER) DistServe 公开视频、课件:适合把论文落到"怎么配资源、怎么调度"的细节。
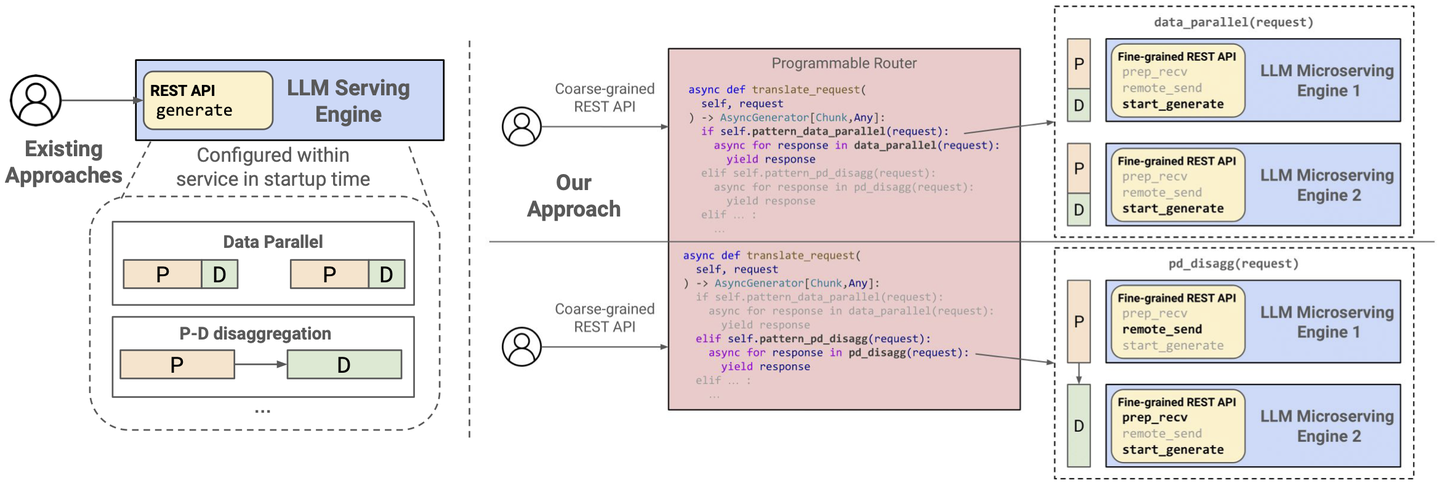
- T (INTER) MLC microserving:把解耦、跨引擎编排做成"几行 Python 可表达"。
ADV
- P (ADV) 从 "goodput" 视角重读 DistServe/TaiChi:把系统目标从 QPS 升级为"满足 SLO 的有效吞吐"。
- C (ADV) SGLang / vLLM 的 kernel & runtime 生态:关注"解耦之后的 KV、batch、graph、kernel"如何协同。
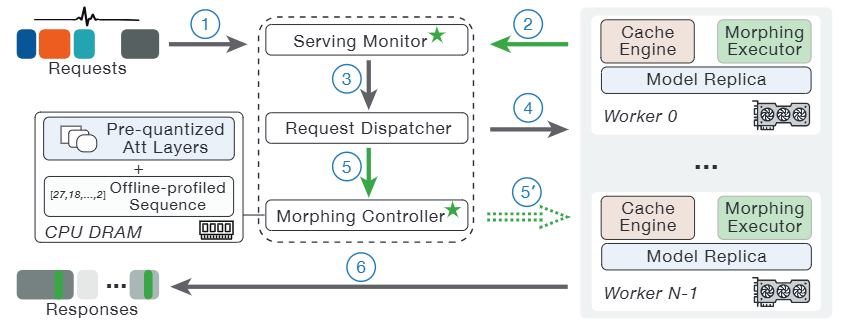
- B (ADV) 用真实 trace 做仿真/回放(参考 Splitwise/FlashInfer-Bench,Inference Perf,VIDUR,MorphServe,Mooncake):你的系统最终要对抗真实分布。
验收标准 checklist
- 能清楚定义并计算:TTFT SLO、TPOT SLO、goodput(满足 SLO 的吞吐)。
- 能解释 prefill/decode 互扰来自哪里(batch/资源耦合/调度)。
- 能给出一个简化的资源配置方案:prefill-heavy vs decode-heavy 的配比(并解释依据)。
- 能复现一个"小规模解耦"实验(哪怕 2 机/2 卡),并报告 goodput 变化。
- 能列出 3 个系统风险点(KV 迁移、网络、尾延迟、队列震荡)及缓解手段。
S6:Benchmark & 回归("没有回归,就没有优化")
一句 insight: 优化要能"上产线",核心是把 GenAI-Perf(TTFT/TPOT/吞吐) 与 MLPerf Inference 这类权威口径纳入回归;MLCommons 也在持续迭代 Inference 结果与规则。
信息流示意图(S6)
改动(量化/内核/调度/解耦)
↓
固定压测配置(模型/上下文/并发/温度)
↓
GenAI-Perf 输出 TTFT/TPOT/P50/P95/token吞吐
↓
对齐/参考 MLPerf 规则与结果(能比才有意义)
↓
上线门禁:回退就拦截BASIC
- T (BASIC) GenAI-Perf:LLM serving 指标一站式输出(TTFT/TPOT/token throughput)。
- B (BASIC) MLPerf Inference(Datacenter)入口:了解官方 workload/规则/提交节奏。
- T (BASIC) Triton perf analyzer quick start:把"压测"纳入日常工程工具链。
INTER
- B (INTER) MLPerf Inference v5.0 解读:理解 LLM serving 的基准为何要围绕低延迟与真实约束。
- T (INTER) Nsight Systems/Compute:把 regression 失败定位到"host vs device vs kernel"。
- C (INTER) SGLang release notes:跟进框架演进,避免你在"旧问题"上卷生卷死。

ADV
- B (ADV) FlashInfer-Bench(参考KernelBench,MLPerf Inference Rules,CUDA Runtime):把"真实 trace + leaderboards + 动态替换"作为长期能力建设。
- C (ADV) TensorRT-LLM(参考Orca,vAttention,CUDA Graphs):当你要追求极限性能/稳定部署时,参考其端到端能力组合。
- P (ADV) FlashAttention-3/FlashInfer(参考POD-Attention,KASCADE,SpecInfer):把 kernel 进步与系统指标绑定,形成"可解释的性能提升"。
验收标准 checklist
- 有一套固定的 benchmark 配置(模型、batch、context、并发、硬件)。
- 每次改动都能输出同一张"指标对比表"(至少 TTFT/TPOT/token/s)。
- 能把 1 次性能回退定位到具体 commit/配置/驱动变化。
- 能解释"为什么 MLPerf/GenAI-Perf 的指标口径与你线上一致/不一致"。
- 能写出"上线门禁":什么指标退化会阻止合并。
一页"选型决策树"(该先优化哪一刀)
你现在最痛的是哪一个?
├─ TTFT 很大(第一口慢)
│ ├─ prompt 很长/上下文很长 → 优先:Prefill 优化/Chunked Prefill/更快的 GEMM/更强 prefill GPU
│ ├─ CPU/调度慢 → 优先:nsys 找 host bottleneck;换更成熟 runtime(vLLM/TRT-LLM)
│ └─ 频繁重复前缀 → 优先:prefix/KV 复用(运行时能力)
│
├─ TPOT 很大(续杯慢)
│ ├─ decode 明显 memory-bound → 优先:Attention/KV(FlashAttention-3/FlashInfer)+ KV cache 管理
│ ├─ token-by-token 串行顶死 → 优先:Speculative / Medusa / EAGLE-2 + Block Verification
│ └─ batch 太小吃不到量化收益 → 优先:continuous batching + 合理并发;必要时上 Marlin 类 INT4 kernel
│
├─ 显存爆了(batch 上不去/长上下文撑不住)
│ ├─ 先看 KV cache 占用 → 优先:PagedAttention + KV Quant(KIVI)
│ └─ 再看权重占用 → INT4 weight-only(AWQ/GPTQ) 或 W8A8(SmoothQuant)
│
└─ 尾延迟/P95 爆炸("最难伺候那 5%")
├─ prefill/decode 互扰明显 → 直接考虑解耦(DistServe/Splitwise 思路)
└─ SLO 既要 TTFT 又要 TPOT → TaiChi 类"聚合+解耦统一"路线