目录:导读
前言
1、负载、并发、压力测试区别
1)负载测试
定义:负载测试是通过逐步增加系统负载,测试系统性能的变化,并最终确定在满足性能指标的情况下,系统所能承受的最大负载量的测试。
目的:不把系统搞挂的测试,使系统能够在最大的压力下可以正常运行。从而获取系统指标。
方法:不断增加请求压力,直到服务器某个资源项达到饱和(比如CPU使用率达到90%+)或某个指标达到安全临界值(比如运维的监控告警阈值or拐点)。系统负载压力包含并发用户数、持续运行时间、数据量等。其中并发用户数是负载压力的重要指标。
2)并发测试
定义:检查系统是否有并发问题,例如内存泄漏、线程锁、资源争用等问题。
目的:确定用户并发数,必须知道系统所承载的在线用户数。然后在单位时间内(S)同时发起一定量的请求。
确定并发用户数的方法:
例如:
公司OA系统账号或者总用户有2000人;
最高峰在线500人;
但是这500人并不是作为并发用户存在的概念。即并不表示服务器实际承载的压力;有可能40%关注的是首页新闻公告板之类(注意看新闻这个阶段是不能造成服务器的压力);
20%用户在查询资料或者操作表格;20%用户在发呆;20%在页面之间跳转;在这种情况下,只有真正20%用户在对服务器造成实质的影响。
我们将这个查询、操作表格作为一个业务范畴来说;直接将这部分业务并发用户称为并发用户数:
计算平均并发用户数:C=NL/T
并发用户峰值数:C' ≈ C+3根号C
公式(1)中,C是平均的并发用户数;n是login session的数量;L是login session的平均长度;T指考察的时间段长度。
公式(2)则给出了并发用户数峰值的计算方式中,其中,C'指并发用户数的峰值,C就是公式(1)中得到的平均的并发用户数。该公式的得出是假设用户的login session产生符合泊松分布而估算得到的。
假设有一个OA系统,该系统有3000个用户,(可以看注册信息)平均每天大约有400个用户要访问该系统,(日志文件查看)对一个典型用户来说,一天之内用户从登录到退出该系统的平均时间为4小时,在一天的时间内,用户只在8小时内使用该系统。
则根据公式(1)和公式(2),可以得到:
C = 4004/8 = 200
C'≈200+3根号200 = 242
但是一般的做法是把每天访问系统用户数的10%作为平均的并发用户数。最大的并发用户数乘上一个值,2或者3。
假如说用户要求系统每秒最大可以处理100个登陆请求,10/25/50/75/100 个并发用户来执行登陆操作,然后观察系统在不同负载下的响应时间和每秒事务数。如果用户数在100的时候,响应时间还在允许范围呢,就要加大用户数,例如120 等 。个人理解这个用户数就是我们经常说的等价类和边界值法来设定。
压力测试
定义:是给软件不断加压,强制其在极限的情况下运行,观察它可以运行到何种程度,从而发现性能缺陷。
目的:把系统搞挂的测试。
方法:以负载测试或者并发测试为依据,给软件不断加压,强制其在极限的情况下运行,观察它可以运行到何种程度,从而发现性能缺陷。
2、性能测试遇到问题怎么办
1)内存溢出
堆内存溢出
现象:
压测执行一段时间后,系统处理能力下降。这时用JConsole、JVisualVM等工具连上服务器查看GC情况,每次GC回收都不彻底并且可用堆内存越来越少。
压测持续下去,最终在日志中有报错信息:java.lang.OutOfMemoryError.Java heap space。
排查手段:
使用jmap -histo pid > test.txt命令将堆内存使用情况保存到test.txt文件中,打开文件查看排在前50的类中有没有熟悉的或者是公司标注的类名,如果有则高度怀疑内存泄漏是这个类导致的。
如果没有,则使用命令:jmap -dump:live,format=b,file=test.dump pid生成test.dump文件,然后使用MAT进行分析。
如果怀疑是内存泄漏,也可以使用JProfiler连上服务器在开始跑压测,运行一段时间后点击"Mark Current Values",后续的运行就会显示增量,这时执行一下GC,观察哪个类没有彻底回收,基本就可以判断是这个类导致的内存泄漏。
解决方式:优化代码,对象使用完毕,需要置成null。
2)永久代 / 方法区溢出
现象:压测执行一段时间后,日志中有报错信息:java.lang.OutOfMemoryError: PermGen space。
产生原因:由于类、方法描述、字段描述、常量池、访问修饰符等一些静态变量太多,将持久代占满导致持久代溢出。
解决方法:修改JVM参数,将XX:MaxPermSize参数调大。尽量减少静态变量。
3)栈内存溢出
现象:压测执行一段时间后,日志中有报错信息:java.lang.StackOverflowError。
产生原因:线程请求的栈深度大于虚拟机所允许的最大深度,递归没返回,戒者循环调用造成。
解决方法:修改JVM参数,将Xss参数改大,增加栈内存。栈内存溢出一定是做批量操作引起的,减少批处理数据量。
4)系统内存溢出
现象:压测执行一段时间后,日志中有报错信息:java.lang.OutOfMemoryError: unable to create new native thread。
产生原因:操作系统没有足够的资源来产生返个线程造成的。系统创建线程时,除了要在Java堆中分配内存外,操作系统本身也需要分配资源来创建线程。因此,当线程数量大到一定程度以后,堆中或许还有空间,但是操作系统分配不出资源来了,就出现这个异常了。
解决方法:
减少堆内存
减少线程数量
如果线程数量不能减少,则减少每个线程的堆栈大小,通过-Xss减小单个线程大小,以便能生产更多的线程。
3、CPU过高
1)us cpu高
现象:压测过程中,使用top命令查看系统资源占用情况,us cpu过高,超过50%以上。
排查手段:
使用top命令是哪个进程消耗CPU高
再找到CPU消耗高的线程:top -H -p 进程号
把线程号转换成16进制:printf "%x\n" 线程号
再用jstack命令分析这个线程是在干什么:jstack 进程号 | grep 16进制的线程号
通过JProfiler的CPU Views视图的层层分析,可以清楚的找到造成CPU高的原因
2)sy cpu高
现象:压测过程中,使用top命令查看系统资源占用情况,sy cpu过高,超过50%以上。
排查手段:
首先查看磁盘繁忙程度、磁盘的队列(iostat、nmon)
如果磁盘没有问题,则使用strace查看系统内核调用情况
4、TPS上不去
1)网络带宽
在压力测试中,有时候要模拟大量的用户请求,如果单位时间内传递的数据包过大,超过了带宽的传输能力,那么就会造成网络资源竞争,间接导致服务端接收到的请求数达不到服务端的处理能力上限。
2)连接池
最大连接数太少,造成请求等待。连接池一般分为服务器中间件连接池(比如Tomcat)和数据库连接池(或者理解为最大允许连接数也行)。
3)垃圾回收机制
从常见的应用服务器来说,比如Tomcat,如果堆内存设置比较小,就会造成新生代的Eden区频繁的进行Young GC,老年代的Full GC也回收较频繁,那么对TPS也是有一定影响的,因为垃圾回收时通常会暂停所有线程的工作。
4)数据库
高并发情况下,如果请求数据需要写入数据库,且需要写入多个表的时候,如果数据库的最大连接数不够,或者写入数据的SQL没有索引没有绑定变量,抑或没有主从分离、读写分离等,就会导致数据库事务处理过慢,影响到TPS。
5)硬件资源
包括CPU(配置、使用率等)、内存(占用率等)、磁盘(I/O、页交换等)。
6)压力机
比如Jmeter和Loadrunner,单机负载能力有限,如果需要模拟的用户请求数超过其负载极限,也会间接影响TPS(这个时候就需要进行分布式压测来解决其单机负载的问题)。
7)业务逻辑
业务解耦度较低,较为复杂,整个事务处理线被拉长也会导致TPS上不去。
8)系统架构
比如是否有缓存服务,缓存服务器配置,缓存命中率、缓存穿透以及缓存过期等,都会影响到测试结果。
性能问题分析流程
查看服务器的CPU、内存 、负载等情况,包括应用服务器和数据库服务器
查看数据库健康状态,数据库死锁、连接池不释放
查看项目日志(查看无报错现象)
查看jvm的gc等情况
完整版!企业级性能测试实战,速通Jmeter性能测试到分布式集群压测教程
|-------------------------------------|
| 下面是我整理的2025年最全的软件测试工程师学习知识架构体系图 |
一、Python编程入门到精通
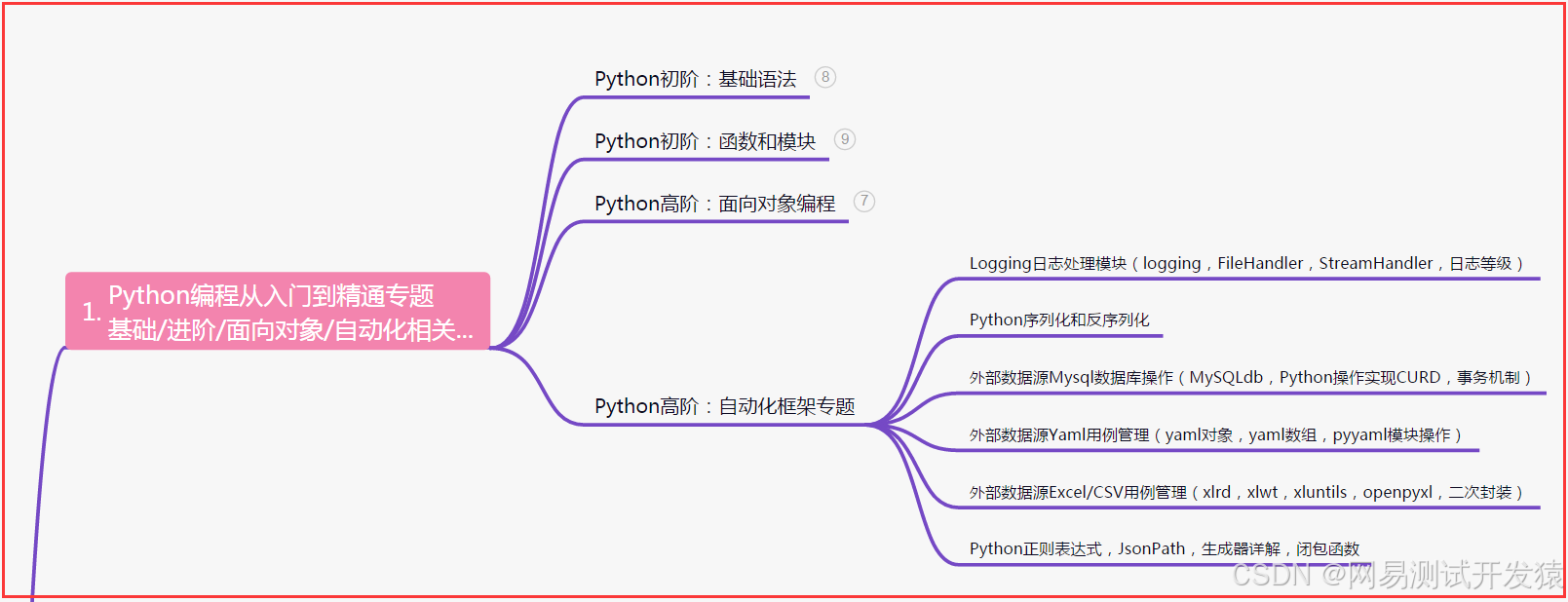
二、接口自动化项目实战
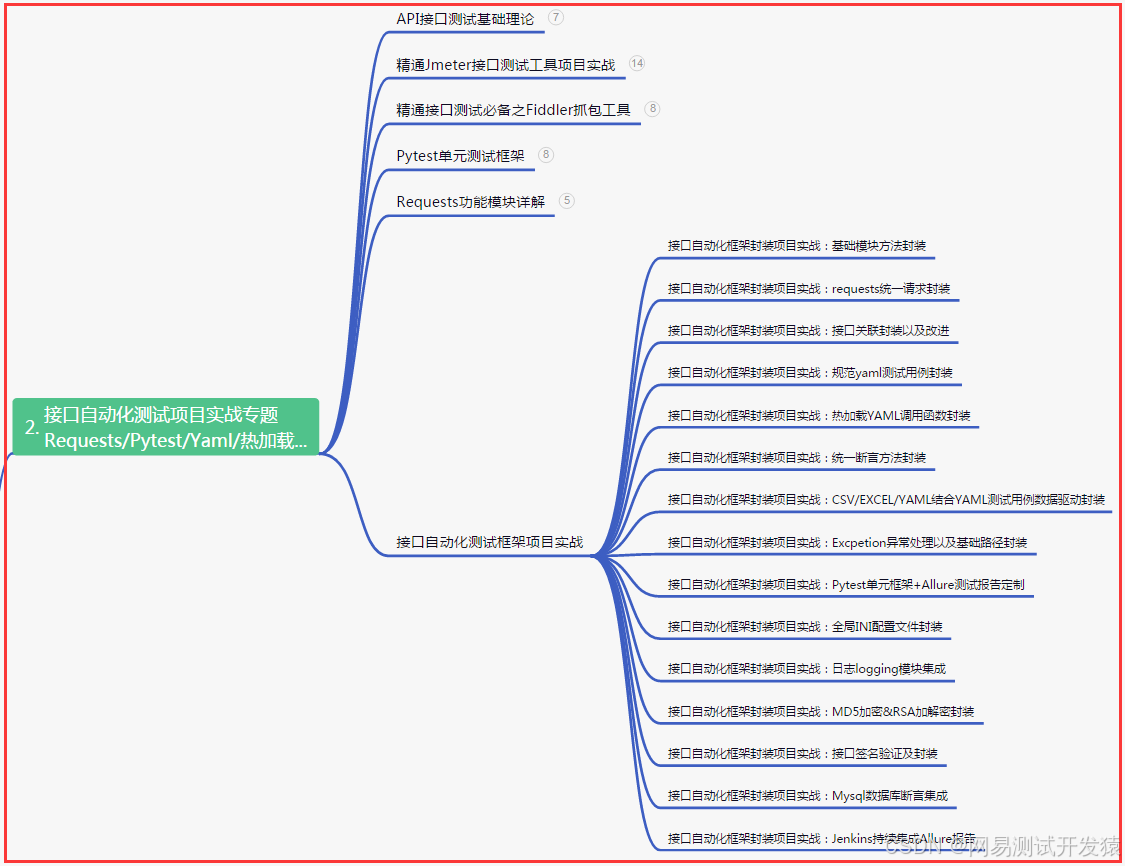
三、Web自动化项目实战
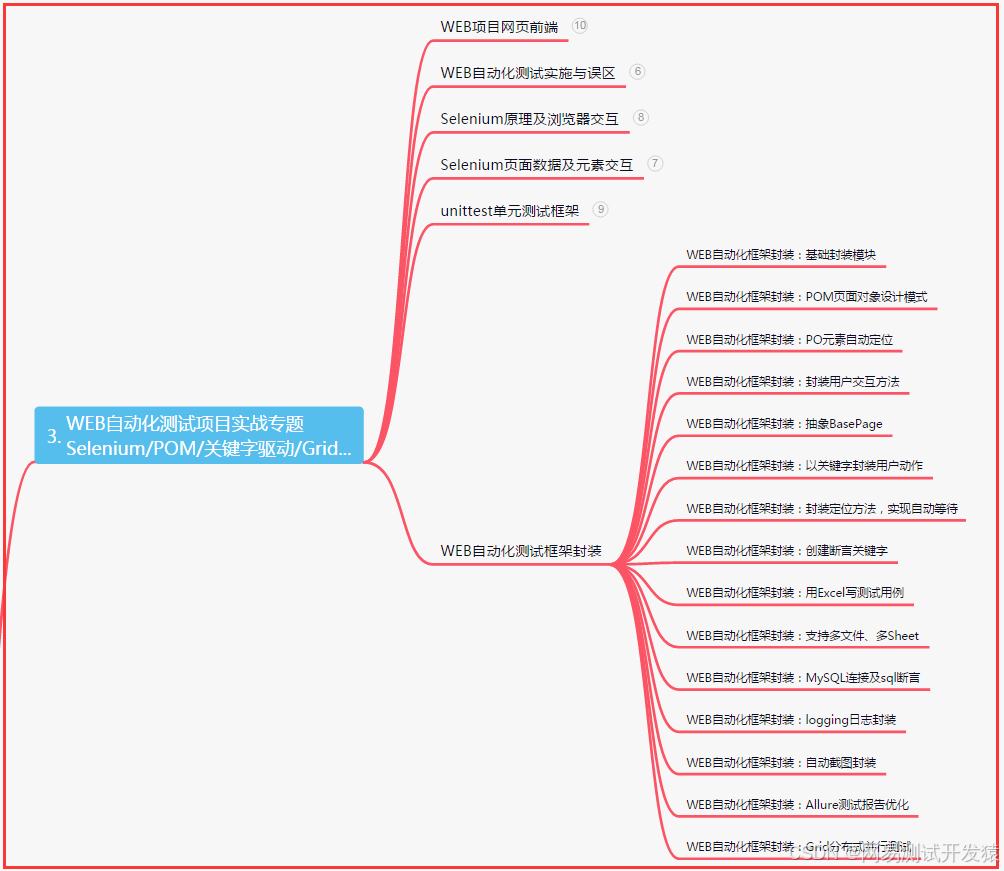
四、App自动化项目实战
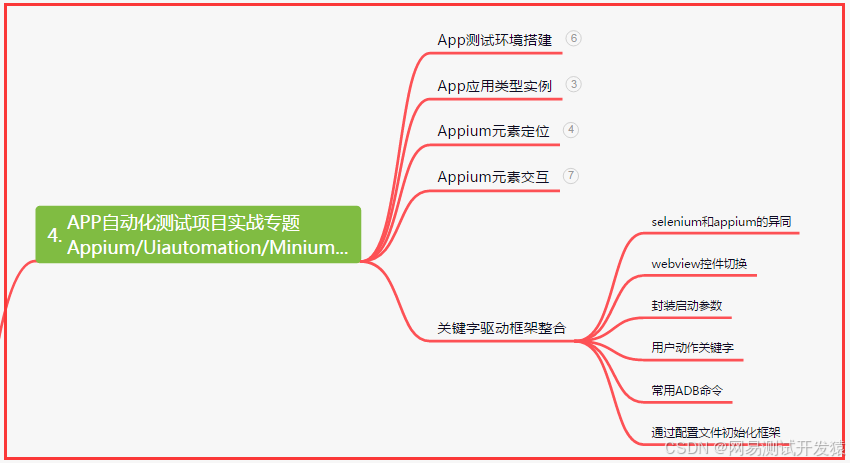
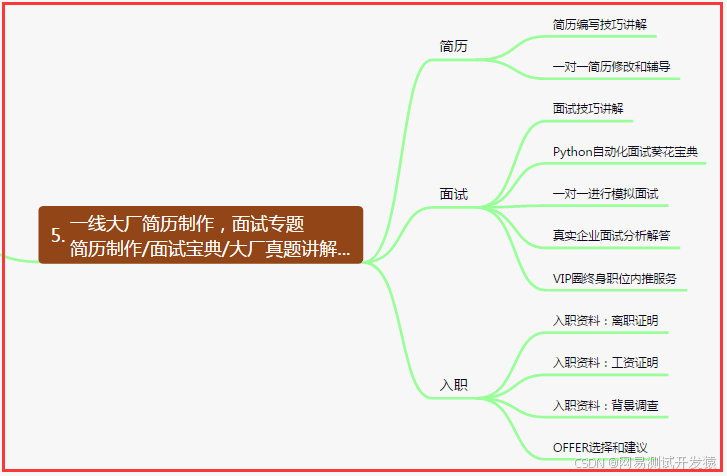
五、一线大厂简历
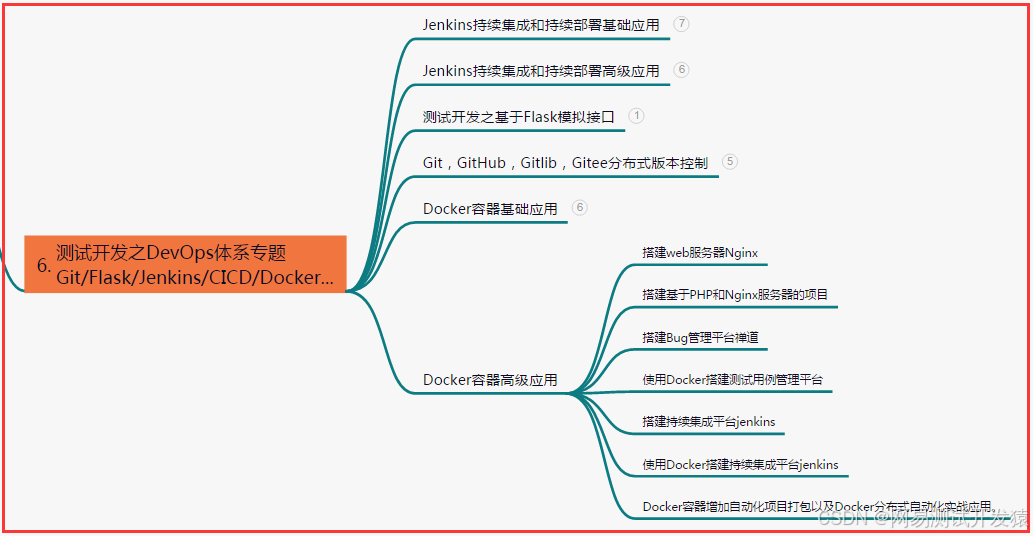
六、测试开发DevOps体系
七、常用自动化测试工具

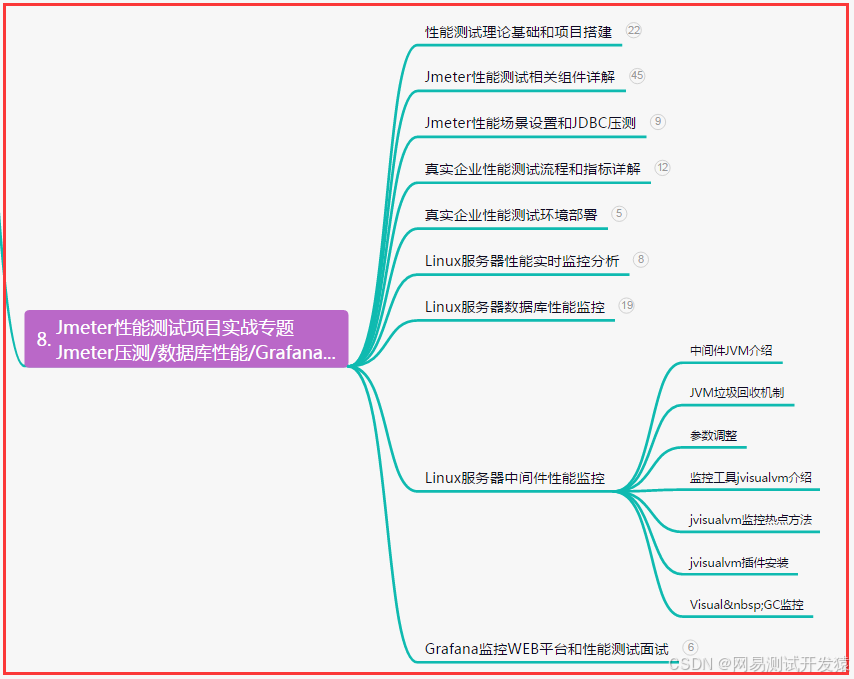
八、JMeter性能测试
九、总结(尾部小惊喜)
人生最动人的风景,往往藏在最难攀爬的高处。当你觉得力竭时,请记住:每一次坚持都在雕刻更强大的自己。别问路有多远,只管迈步向前;别怕山有多高,向上攀登就是答案!
你体内沉睡着改变世界的力量!每个清晨都是改写命运的新机会,每次挫折都是精心包装的礼物。当全世界都在说"不可能"时,正是你证明"可能"的最好时机!