【导语】随着人工智能从算法研究走向大规模工程化与产业化落地,计算负载呈现出算力需求激增与应用形态高度分化并存的特征。在这一背景下,传统通用处理器在性能功耗比、时延确定性以及系统可扩展性方面逐渐暴露出瓶颈,推动AI芯片架构向更高专用化程度演进。
从体系结构角度看,当前AI芯片的发展并非单一路线的线性替代,而是沿着不同抽象层次并行展开的两条专用化路径:一条是在指令集层面,由CPU/GPU向领域专用架构(DSA)演进;另一条发生在电路级层面,以FPGA代表的细粒度结构可配置与以CGRA代表的粗粒度算子/数据通路可配置并行发展,形成以空间映射与数据流调度为核心的另一类可编程加速形态。两条路径最终在异构计算体系中实现协同。
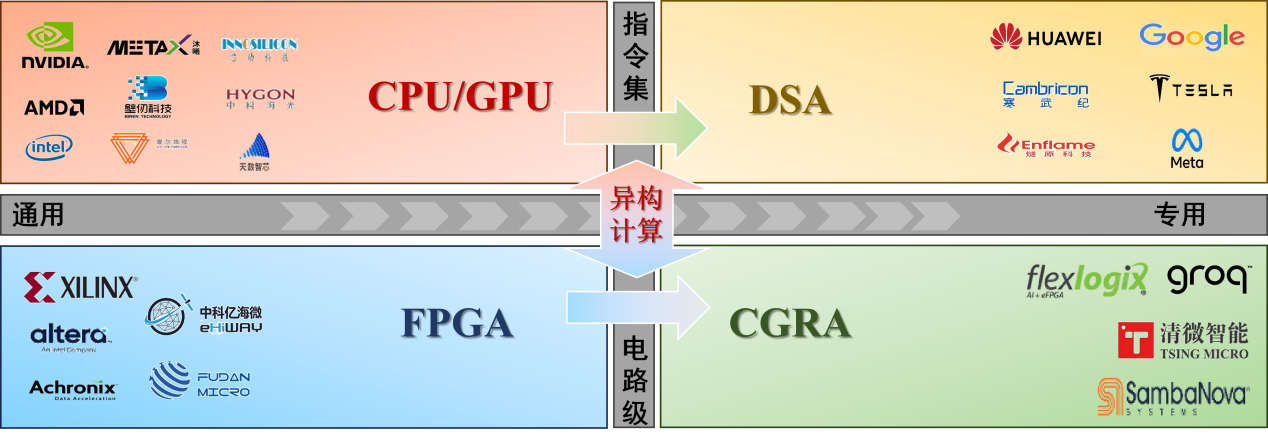
一、 指令集层面的专用化路径,从CPU/GPU到DSA
CPU与GPU构成了现代计算体系中最典型的通用处理架构。CPU以复杂控制逻辑和通用指令集为核心,适合控制密集与非规则计算;GPU依托大规模并行计算单元与SIMT式锁步执行,擅长数据并行的张量/向量计算,因此成为深度学习训练与推理的主力平台。
然而,随着AI算法逐渐稳定为以张量计算和数据流为主的模式,传统CPU/GPU在指令通用性上的优势,开始转化为能效与面积上的负担。在此背景下,DSA应运而生,其核心思想是围绕AI负载对执行单元、片上存储层级与数据流组织进行定向优化,并通过编译器/运行时将高层算子高效映射到专用硬件上,从而在典型AI负载下获得更优的性能功耗比与系统效率。
典型DSA通过引入张量指令、专用算子以及片上数据流调度机制,在性能功耗比方面显著优于通用处理器。Google TPU、华为昇腾、寒武纪等架构,均体现了这一指令集级专用化的发展方向。
二、电路级层面:从细粒度可重构走向粗粒度可重构(FPGA→CGRA)并协同发展
在指令流编程范式之外,另一条重要路径发生在可重构硬件结构与数据通路层面。以FPGA为代表的细粒度可重构器件,依托LUT/寄存器与可编程互连提供高度灵活的定制能力,特别适用于低时延、强接口适配、确定性数据通路与专用逻辑集成等场景。
为更贴近AI数据流特性,业界形成了以CGRA为代表的粗粒度可重构设计点:其可配置对象从"逻辑单元/门级拼装"提升到"算子级处理单元(PE)及其数据通路/互连"的空间映射,借助更规则的阵列结构与更受控的互连组织,在特定张量/流式计算上提升计算密度、降低映射碎片化并增强时序规划的可预测性。
需要强调的是,FPGA与CGRA并非线性替代关系,而是分别代表细粒度与粗粒度两类可重构形态,在灵活性、效率与软件栈复杂度之间取不同权衡,并常与CPU/GPU/DSA一起构成异构系统的互补单元。
三、异构计算:两条路径的交汇点
无论是指令集层面的DSA,还是可重构的CGRA,其设计目标都并非独立替代通用处理器,而是在系统层面作为异构计算单元参与协同。现代AI计算平台通常采用多种处理架构组合,通过高效的片上互连、存储一致性机制以及统一的软件栈,实现控制、通用计算与专用加速的分工协作。在这一体系中,CPU负责系统控制与任务调度,GPU或DSA承担高吞吐计算任务,而FPGA或CGRA则在低时延、定制化数据流处理方面发挥优势。异构计算已成为突破能效瓶颈、支撑复杂AI应用的核心系统范式。
四、产业趋势与结论
总体而言,AI芯片架构的演进并不存在唯一最优解,而是沿着不同抽象层次展开的专用化探索。指令集路径与电路级架构路径并行发展,AI芯片的发展遵循这样一个基本原则:当AI算法持续演变,芯片应朝着通用发展;当AI算法趋于收敛,芯片则应转向专用发展。 未来的核心竞争力不仅来自单一计算单元的性能提升,更取决于体系结构、软件栈与系统级协同能力的整体优化。这两条路径并非技术代际演进,而是在异构计算框架下,指令集优化与电路级重构协同塑造智能计算新生态。