SQL慢查询常见优化步骤
SQL慢查询优化是一个系统性的工程,通常遵循"定位→分析→优化→验证"的闭环流程。以下是完整的优化步骤体系:
一、定位慢查询(发现问题)
- 开启慢查询日志
bash
-- 查看慢查询配置
SHOW VARIABLES LIKE '%slow_query_log%';
SHOW VARIABLES LIKE '%long_query_time%';
-- 临时开启(重启失效)
SET GLOBAL slow_query_log = 'ON';
SET GLOBAL long_query_time = 2; -- 超过2秒记录
-- 永久配置(修改my.cnf)
slow_query_log = ON
slow_query_log_file = /var/log/mysql/slow.log
long_query_time = 2
log_queries_not_using_indexes = ON -- 记录未使用索引的查询二、分析慢查询原因(诊断问题)
- 使用EXPLAIN分析执行计划
bash
EXPLAIN SELECT * FROM users WHERE age > 30;重点关注EXPLAIN的关键字段:
• type:访问类型(const > ref > range > index > ALL)
• key:实际使用的索引
• rows:扫描行数(越少越好)
• Extra:额外信息(Using filesort、Using temporary需要警惕)
- 分析执行计划问题

- 使用PROFILING分析执行细节
bash
-- 开启性能分析
SET profiling = 1;
-- 执行查询
SELECT * FROM large_table WHERE condition;
-- 查看分析结果
SHOW PROFILES;
SHOW PROFILE FOR QUERY 1; -- 查看具体查询的耗时分布三、常见优化手段(解决问题)
- 索引优化(最核心的优化手段)
① 添加缺失索引
bash
-- 为频繁查询的字段添加索引
CREATE INDEX idx_age ON users(age);
CREATE INDEX idx_name_age ON users(name, age); -- 复合索引
-- 为排序、分组字段添加索引
CREATE INDEX idx_created_at ON orders(created_at);② 优化索引设计
• 遵循最左前缀原则:复合索引(a,b,c)只能用于a、a,b、a,b,c的查询
• 避免冗余索引:删除重复或很少使用的索引
• 选择高选择性字段:区分度高的字段更适合建索引
• 覆盖索引优化:让索引包含查询所需的所有字段,避免回表
③ 索引使用注意事项
bash
-- 避免索引失效的常见情况:
-- 1. 对索引列进行函数操作
SELECT * FROM users WHERE DATE(created_at) = '2024-01-01'; -- 索引失效
SELECT * FROM users WHERE created_at >= '2024-01-01' AND created_at < '2024-01-02'; -- 正确
-- 2. 使用不等于(!=、<>)
SELECT * FROM users WHERE status != 1; -- 可能全表扫描
-- 3. 使用OR连接条件(除非所有字段都有索引)
SELECT * FROM users WHERE name = '张三' OR age = 30; -- 可能全表扫描
-- 4. 隐式类型转换
SELECT * FROM users WHERE phone = 13800138000; -- phone是varchar,索引失效- SQL语句优化
① 避免SELECT *
bash
-- 不推荐:返回所有字段,可能造成回表
SELECT * FROM users WHERE age > 30;
-- 推荐:只返回需要的字段
SELECT id, name FROM users WHERE age > 30;② 优化WHERE条件
• 避免在WHERE子句中对字段进行运算或函数操作
• 使用EXISTS代替IN(子查询数据量大时)
• 避免使用NOT IN(可用NOT EXISTS或LEFT JOIN替代)
③ 分页优化
bash
-- 传统分页(大数据量时性能差)
SELECT * FROM orders ORDER BY id LIMIT 1000000, 20;
-- 优化方案1:使用覆盖索引+子查询
SELECT * FROM orders
WHERE id >= (SELECT id FROM orders ORDER BY id LIMIT 1000000, 1)
ORDER BY id LIMIT 20;
-- 优化方案2:记录上一页的最大ID
SELECT * FROM orders WHERE id > last_max_id ORDER BY id LIMIT 20;④ JOIN优化
• 小表驱动大表:将数据量小的表放在前面
• 为JOIN字段添加索引:ON条件的字段必须有索引
• 避免多表JOIN:超过3个表JOIN时考虑拆分成多个查询
⑤ 子查询优化
bash
-- 不推荐:相关子查询(外层每行都要执行子查询)
SELECT * FROM users u
WHERE EXISTS (SELECT 1 FROM orders o WHERE o.user_id = u.id AND o.amount > 1000);
-- 推荐:使用JOIN或IN(数据量大时)
SELECT DISTINCT u.* FROM users u
JOIN orders o ON u.id = o.user_id
WHERE o.amount > 1000;- 表结构优化
① 字段类型优化
• 使用合适的数据类型:能用INT不用BIGINT,能用VARCHAR(20)不用VARCHAR(255)
• 避免使用TEXT/BLOB:如果必须使用,考虑分表存储
• 使用NOT NULL:可减少存储空间,优化查询
② 范式与反范式
• 适当冗余:在查询频繁但更新少的场景,可适当冗余字段减少JOIN
• 垂直拆分:将大字段、不常用字段拆分到扩展表
• 水平拆分:数据量过大时考虑分表分库
③ 字符集优化
• 使用utf8mb4代替utf8(支持表情符号)
• 对于纯数字、英文字段,可使用latin1减少存储空间
五、常见慢查询场景与解决方案
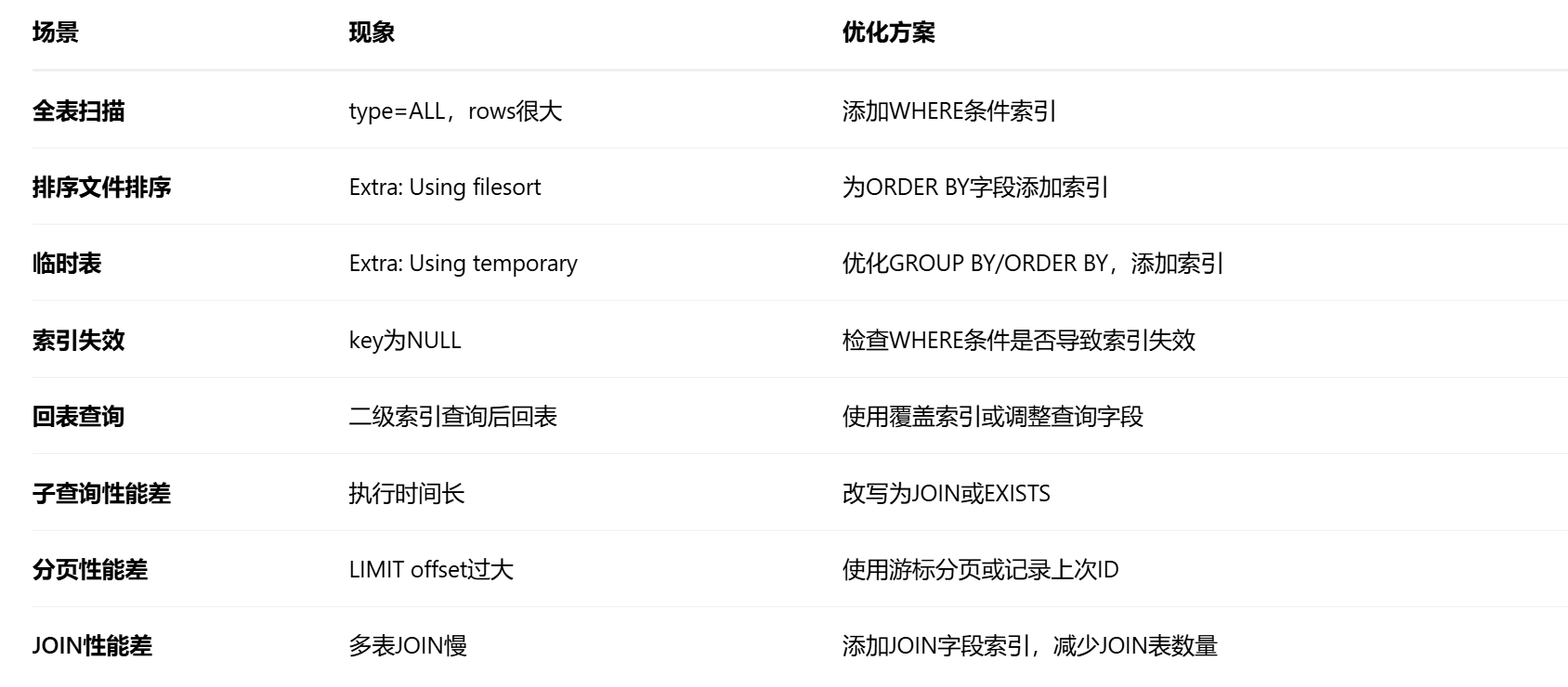
四、架构层面优化(除SQL优化外的方法)
- 读写分离
主从复制:主库写,从库读
实现方式:MySQL原生复制、MHA、MGR
应用层:使用中间件(MyCat、ShardingSphere)或客户端路由 - 分库分表
垂直分表:按业务拆分(用户表、订单表)
水平分表:按数据量拆分(按用户ID取模)
分库:多个数据库实例
工具:ShardingSphere、MyCat、Vitess - 缓存层优化
Redis缓存:缓存热点数据,减少数据库压力
多级缓存:本地缓存(Guava Cache)+ 分布式缓存(Redis)
缓存策略:缓存穿透、缓存击穿、缓存雪崩防护 - 表结构优化
字段类型选择:使用合适的数据类型(INT vs BIGINT)
避免NULL:设置NOT NULL DEFAULT,减少存储空间
范式与反范式:适当冗余减少JOIN
分区表:按时间或范围分区(MySQL 5.7+) - 硬件与系统优化
SSD硬盘:提升IO性能
RAID配置:RAID 10提升读写性能
CPU与内存:根据负载配置
文件系统:使用XFS或ext4 - 连接池优化
连接池配置:合理设置最大连接数、最小空闲连接
连接复用:避免频繁创建连接
超时设置:设置合理的连接超时和查询超时
五、优化流程总结
- 标准优化步骤
监控发现:通过慢查询日志、监控系统发现慢SQL
定位分析:使用EXPLAIN分析执行计划,定位瓶颈
索引优化:检查索引使用情况,添加或调整索引
SQL改写:优化SQL写法,避免全表扫描
配置调优:调整数据库参数,优化内存和IO
架构优化:读写分离、分库分表、缓存等
验证测试:压力测试验证优化效果
六、总结
SQL慢查询优化是一个系统性的工作,需要从定位→分析→优化→监控形成闭环。核心优化手段包括:索引优化(最有效)、SQL改写、表结构优化、配置调优、架构升级。建议建立规范的优化流程,避免盲目优化,确保每次优化都能真正解决问题。
记住:优化前一定要先定位问题,不要凭感觉优化;优化后一定要验证效果,确保没有引入新问题。