本文会开始介绍目前机器学习中常用的自动化编码工具。
大家可能有疑问,既然有自动化编码,为什么之前还要将手动编码呢?原因在于目前的自动化编码封装的非常好,以至于是完全的黑盒,不理解基础原理的人用起来就不知道它在做什么,因此还是希望大家能掌握了解自动编码在做什么。
值得一提的是,自动编码几乎和训练是无法分开的,没有训练的编码和随机分布没什么区别(也就是编码没什么意义)但考虑到本专题的连续性,文本会尽可能淡化训练这一部分。
加州住房数据集
加载数据集
python
from sklearn.datasets import fetch_california_housing
from pandas import DataFrame
house = fetch_california_housing()
pd = DataFrame(data=house.data, columns=house.feature_names)
pd["MedHouseVal"] = house.target
print(pd.head())输出如下
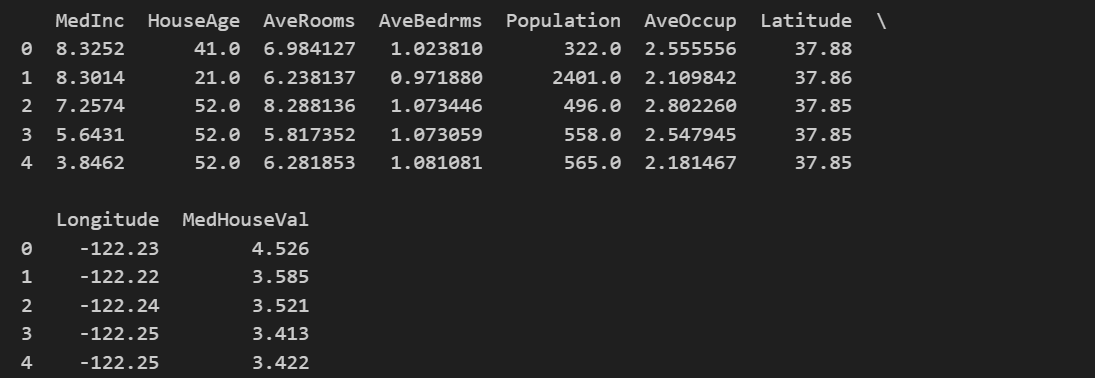
当然,对于自动编码来说,我们不太需要关注标签名称,只需要知道数据维度即可,因此也可以不通过pd直接打印
python
X = house.data[:5] # 仅取5条样本,维度:(5, 8)
print("原始数字数据(5条样本,8维特征):")
print(f"数据维度:{X.shape}")
print(f"前2条原始数据:\n{X[:2]}\n")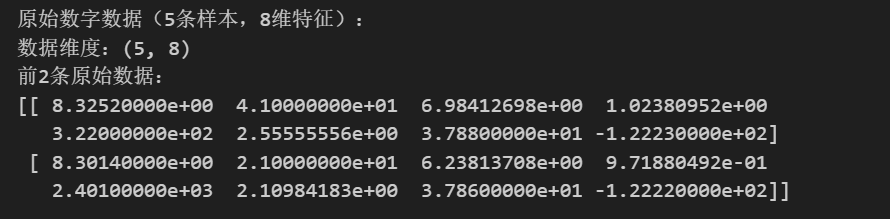
数据归一化
自动编码器对编码器对数值尺度非常敏感,因此归一化是必要的,归一化的原理并不复杂,简单理解就是按相对大小把数据变到区间 0 , 1 之间,例如列表0, 1, 2, 3, 4归一化之后就是0, 0.25, 0.5, 0.75, 1,当然,Min-Max 归一化实际上可以把数据变到任意区间上,对自动编码器来说,只要不同的标签都在同一区间即可。
python
# 归一化
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler(feature_range=(0, 1))
X_scaled = scaler.fit_transform(X)
print("归一化后的数字数据(0-1区间):")
print(f"数据维度:{X_scaled.shape}")
print(f"前2条归一化数据:\n{X_scaled[:2]}\n")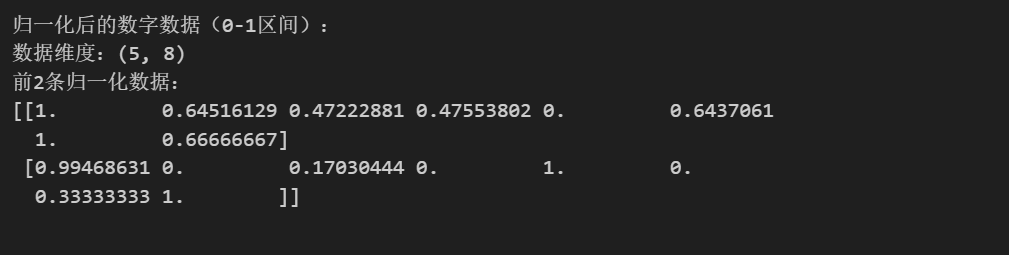
这一步还可以做标准化,但不是必须步骤,所以不再赘述
转为张量
编码器仅支持张量作为输入,因此需要把列表转为张量(初学者把张量理解成多维向量即可,其实我也不觉得它们有什么区别)
python
# 转为张量
import torch
X_tensor = torch.tensor(X_scaled, dtype=torch.float32)
print("转为张量后的输入:")
print(f"张量维度:{X_tensor.shape}")
print(f"前2条张量数据:\n{X_tensor[:2]}\n")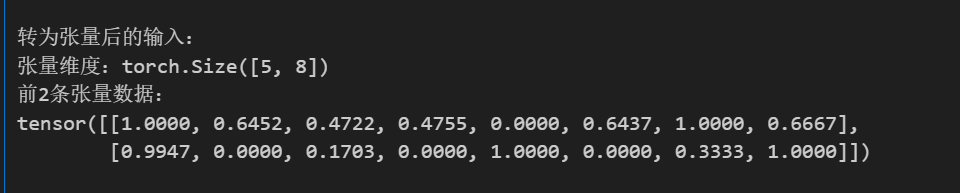
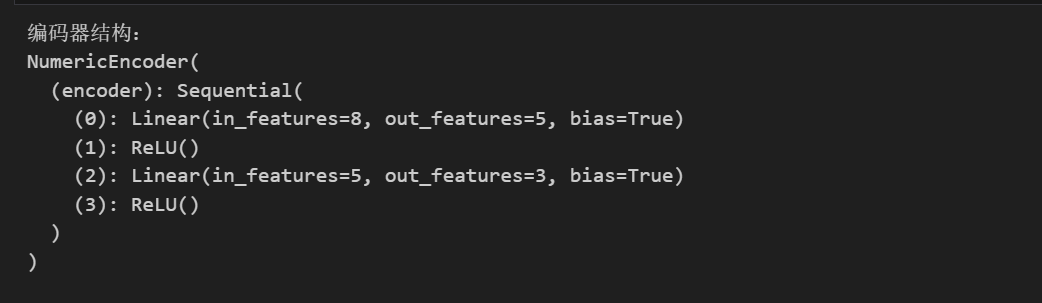
定义编码器
python
# 定义编码器
# 可修改参数input_dim和latent_dim来调整输入和输出维度
import torch.nn as nn
class NumericEncoder(nn.Module):
def __init__(self, input_dim=8, latent_dim=3):
super(NumericEncoder, self).__init__()
# 编码器结构:8维 → 5维(隐藏层) → 3维(核心特征)
self.encoder = nn.Sequential(
nn.Linear(input_dim, 5), # 第一层:8→5
nn.ReLU(), # 激活函数
nn.Linear(5, latent_dim), # 第二层:5→3
nn.ReLU() # 激活函数
)
def forward(self, x):
return self.encoder(x) # 仅返回编码结果
# 初始化编码器
encoder = NumericEncoder(input_dim=8, latent_dim=3)
print("【步骤2】编码器结构:")
print(encoder)
print()这里我们可修改参数input_dim和latent_dim来调整输入和输出维度,当然input_dim是我们之前查看数据集得到的8个标签,因此最好不要修改。
至于编码器中间的结构,涉及到神经网络如何搭建,不是本文的重点(其实就像搭积木一样一层一层拼好,每一层根据想要的效果接上对应的层就行,不过想要设计一个好的网络还是很需要相关知识的)
编码器输出
正如前面所说,自动编码几乎和训练是无法分开的,没有训练的编码和随机分布没什么区别,本文仅演示编码器的输入输出过程,因此跳过训练这一步。
python
# 设为评估模式(无梯度计算,仅前向传播)
print(f"编码前输入维度:{X_tensor.shape} (8维)")
print(f"编码前向量:{X_tensor[:2]}\n")
encoder.eval()
with torch.no_grad():
encoded_features = encoder(X_tensor) # 执行编码
print("编码后的核心特征:")
print(f"编码后输出维度:{encoded_features.shape} (3维)")
print(f"前2条编码结果:\n{encoded_features[:2]}\n")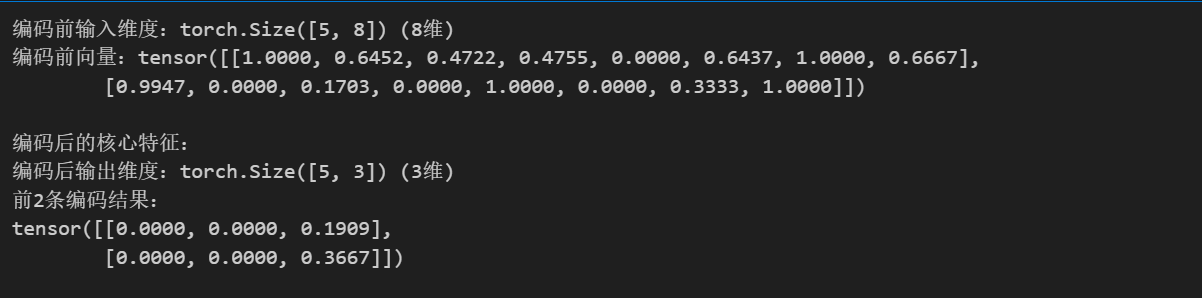
可以很明显的看到,经过编码器,两条八维的tensor成功被编码为两条三维的tensor。但是仍然要强调
- 未训练时,
nn.Linear(8,5)和nn.Linear(5,3)的权重、偏置都是随机值; - 此时输入 8 维的归一化数据,经过编码器得到的 3 维输出,只是随机的数值组合 ,和直接从均匀分布 / 正态分布中采样的结果没有本质区别,完全不包含原始数据的任何核心特征。
自动编码器的训练过程,是通过重构损失(原始输入和解码器输出的差异)来优化编码器 + 解码器的参数。没有训练的 "编码",只是一次无意义的数学变换;只有经过训练,编码器才能输出和数据内在结构匹配的特征。
本来计划这里再给一个本文数据集的例子,但是现在NLP基本上被transformers杀穿了,所以NLP的数据集基本上都是tokenizer来处理的,还是有一定的门槛,以后讲完transformers再补上吧