****论文题目:****AXIAL ATTENTION IN MULTIDIMENSIONAL TRANSFORMERS(多维变压器的轴向注意)
****链接:****arXiv:1912.12180v1
****摘要:****我们提出轴向变压器,一个自关注为基础的自回归模型的图像和其他数据组织为高维张量。现有的自回归模型要么对高维数据有过大的计算资源需求,要么为了减少资源需求而在分布表达性或易于实现方面做出妥协。相比之下,我们的架构在数据的联合分布上保持了充分的表现力,并且易于使用标准深度学习框架实现,同时需要合理的内存和计算,并在标准生成建模基准上实现最先进的结果。我们的模型基于轴向注意,这是一种自注意力机制的简单概括,在编码和解码设置中自然地与张量的多个维度保持一致。值得注意的是,所提出的层结构允许在解码期间并行计算绝大多数上下文,而不引入任何独立性假设。这种半并行结构对于从一个非常大的轴向变压器进行解码有很长的路要走。我们在ImageNet-32和ImageNet-64图像基准测试以及BAIR机器人推送视频基准测试上展示了轴向变压器的最新结果。我们开源了轴向变压器的实现。
深入理解Axial Transformer------让自注意力高效处理高维数据
引言
Transformer凭借自注意力机制在NLP领域取得巨大成功,但在图像和视频建模中却面临计算爆炸的难题:一张小小的32×32图像展平后就有3072个token,标准自注意力的O(N²)复杂度让计算成本高不可攀。
今天要介绍的这篇来自UC Berkeley和Google Brain的论文《Axial Attention in Multidimensional Transformers》提出了一个优雅的解决方案------Axial Transformer,在ImageNet和视频建模任务上实现了SOTA性能,同时保持实现简单、无需定制硬件内核。
一、问题背景:自注意力的困境
1.1 自注意力的计算瓶颈
标准自注意力层的计算公式为:
Q = XW_Q, K = XW_K, V = XW_V
A = softmax(QK^T/√D), Y = AV核心问题在于计算注意力矩阵A和加权求和Y:
- 计算所有query-key对的相似度:O(N²)时间和空间
- 对于32×32×3的图像,N=3072,N²≈940万!
1.2 现有方法的权衡

如表1所示,现有方法面临艰难取舍:
| 方法 | 完整感受野 | 计算优化 | 无需定制内核 | 半并行采样 |
|---|---|---|---|---|
| Image Transformer | ❌ | ✅ | ✅ | ❌ |
| Strided Sparse Transformer | ✅ | ✅ | ❌ | ❌ |
| Axial Transformer | ✅ | ✅ | ✅ | ✅ |
二、Axial Attention:核心创新
2.1 轴向注意力的基本思想
关键洞察 :不要展平整个张量,而是沿单个轴进行注意力计算。
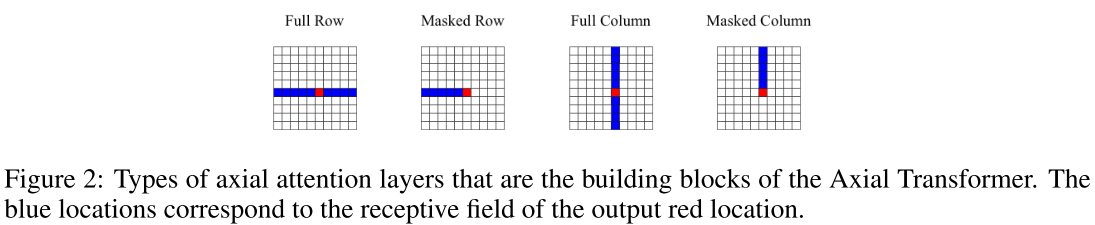
如图2所示,对于2D图像,定义四种基本操作:
- Full Row:未掩码行注意力,每个位置关注整行
- Masked Row:掩码行注意力,只关注当前位置及之前(自回归)
- Full Column:未掩码列注意力,每个位置关注整列
- Masked Column:掩码列注意力,只关注当前位置及之上
2.2 计算复杂度分析
对于S×S的方形图像(N=S²):
- 标准注意力:O(N²) = O(S⁴)
- 轴向注意力:对S个长度为S的序列做注意力 → O(S·S²) = O(S³) = O(N^(3/2))
- 节省因子:O(√N)
通用公式:对于d维张量N=S^d,节省O(N^(d-1)/d)
三、Axial Transformer架构设计
3.1 整体架构
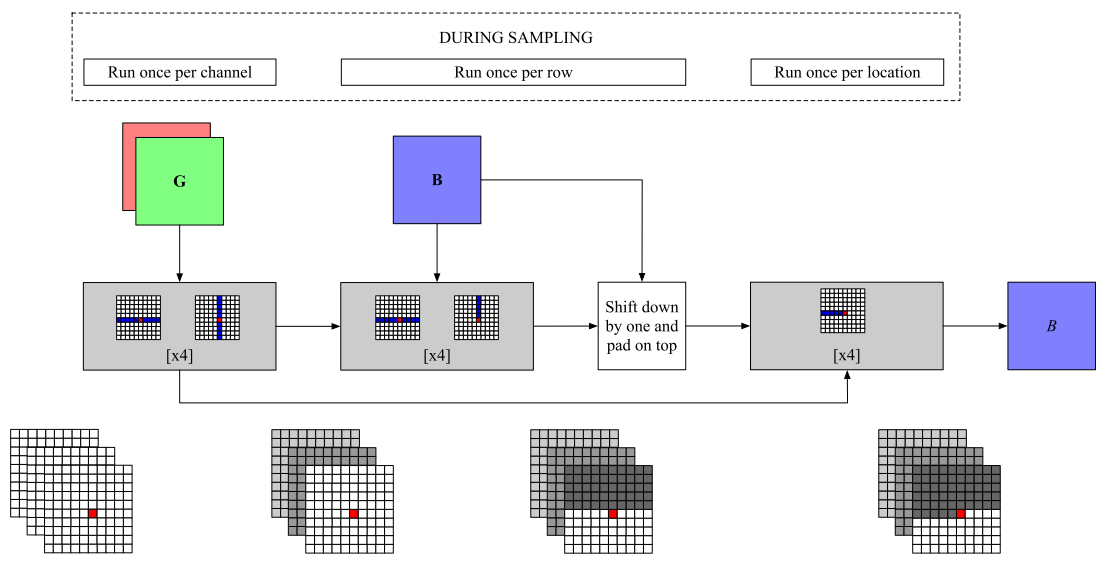
Fig.1:二维张量的轴向变压器模型。在采样通道之前,我们用8块未掩码的行和未掩码的列(左)对所有先前的通道和帧进行编码。然后,对于每一行,我们应用4块未掩码行和掩码列的注意力,将之前采样的活动通道行整合到我们的编码表示中(中间)。最后,我们将编码表示向上移动,以确保条件信息满足因果关系,并且我们运行由4块被屏蔽的行注意力组成的内部解码器,对图像中的新行进行采样(右)。
如图1所示,Axial Transformer采用三阶段设计:
阶段1:Channel Encoder(每个通道运行一次)
处理之前所有通道/帧,使用8个未掩码行+未掩码列注意力块:
u ← h + PositionEmbeddings
u ← [TransformerBlock_2(TransformerBlock_1(u))] × 4阶段2:Outer Decoder(每行运行一次)
整合已采样的行到编码表示,使用4个未掩码行+掩码列注意力块:
u ← [MaskedTransformerBlock_1(TransformerBlock_2(u))] × 4
h ← ShiftDown(u) + ShiftRight(h) + PositionEmbeddings阶段3:Inner Decoder(每个位置运行一次)
在单行内自回归生成,使用4个掩码行注意力块:
h ← [MaskedTransformerBlock_2(h)] × 43.2 多通道/视频的处理
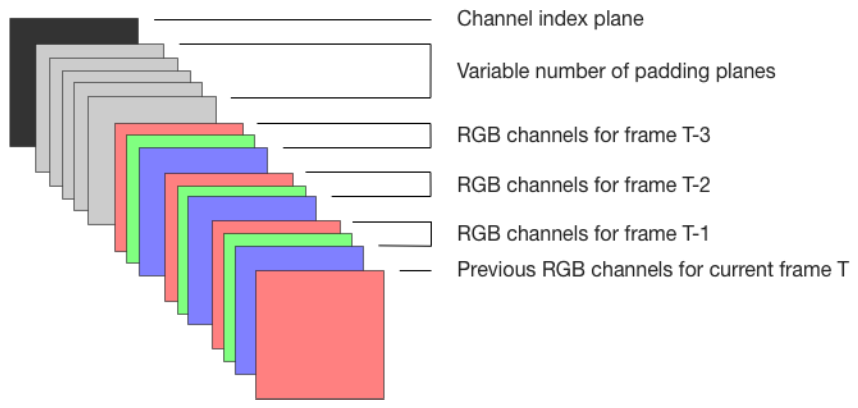
如图3所示,对于H×W×C的数据:
- 将之前的通道顺序堆叠为输入
- 使用填充平面作为未来通道的占位符
- 添加整数平面标识当前生成的通道
训练时随机选择一个通道切片,最大化其条件对数似然:
p(x_{:,:,c} | x_{:,:,<c})四、半并行采样:速度的秘密
4.1 为什么可以半并行?
关键观察 :Inner Decoder(掩码行注意力层)在行之间是独立的------它们只通过Outer Decoder计算的上方上下文u相互依赖。
4.2 采样算法
for 每一行 i in [1, H]:
# 并行计算:处理所有 i 之前的行
u = compute_upper_context(x_{<i,:}) # O(N√N·L_upper)
for 每一列 j in [1, W]:
# 自回归:只需重新运行当前行的Inner Decoder
x_{i,j} = sample_pixel(u, x_{i,<j}) # O(N·L_row)4.3 复杂度对比
- 朴素实现:每个位置重新评估整个网络 → O(N²√N(L_upper+L_row))
- 半并行采样:O(N²(L_upper+L_row))
- 加速倍数:√N(对于32×32图像,约5.7倍;64×64约8倍)
五、实验结果:全面的SOTA
5.1 ImageNet图像生成
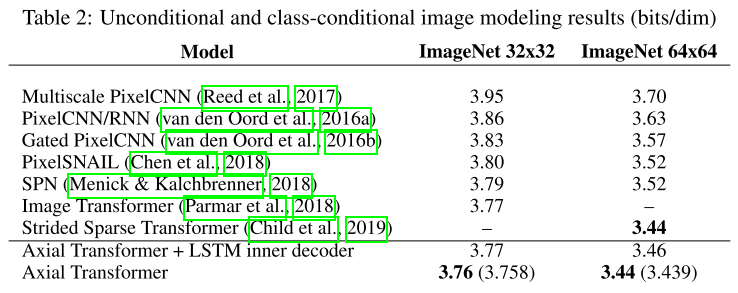
关键发现:
- 在两个分辨率上都达到SOTA
- 无需定制内核,比Strided Sparse Transformer更易实现
- 完整感受野,优于Image Transformer
5.2 视频生成

突破性成果:
- 显著优于专门设计的视频模型
- 仅通过将视频帧堆叠到通道维度,无需架构修改
5.3 生成样本质量


生成的样本展现出:
- 全局连贯性和可识别的场景
- 成功捕获数千维度上的长程依赖
- 无架构相关伪影

视频样本特点:
- 高质量的细节保真度
- 在温度1.0下的巨大多样性
- 物理运动的合理性
六、消融实验:验证设计选择
6.1 LSTM Inner Decoder变体
实验设置:用单层2048单元LSTM替换4层Inner Decoder
结果:
- ImageNet-32: 3.77 bits/dim(仅略降0.01)
- ImageNet-64: 3.46 bits/dim(略降0.02)
- 训练时间:32上慢20%,64上慢80%
结论:
- Outer Decoder的上下文捕获非常有效
- 完整的4层Inner Decoder带来性能提升和训练加速
- 对于更大张量,LSTM会因训练慢而不实用
七、实现细节与技巧
7.1 模型配置
所有实验统一配置:
- 编码器:8层
- Outer Decoder:8层
- Inner Decoder:4层
- 隐藏维度:2048
- 注意力头:16个(每个128维)
- 训练步数:约200k
7.2 位置编码
使用加性分解位置嵌入提高参数效率:
PositionEmbeddings = RowEmbeddings[H×1×D] + ColEmbeddings[1×W×D]广播求和,而非H×W×D的完整参数化
7.3 实现优势
- 纯标准操作:主要是dense-dense矩阵乘法(MatMul)
- 无冗余拷贝:不像Image Transformer需要提取窗口
- 硬件友好:在GPU和TPU上都能高效运行
- 开源实现:代码公开可用
结语
Axial Transformer通过一个简单而深刻的想法------沿轴注意力------优雅地解决了自注意力机制在高维数据上的计算瓶颈。它在保持完整表达能力的同时,实现了√N的加速,并且实现简单、无需定制硬件。
在ImageNet和BAIR视频基准上的SOTA结果证明了这一方法的有效性。更重要的是,这种设计思路可能启发更多高效的多维Transformer架构,推动生成模型在图像、视频和其他高维领域的进一步发展。