一、理解UDP
1.传输层
在传输层中包含两个重要协议:UDP和TCP
传输层主要负责把数据从一台主机传输到另一台主机
2.端口号
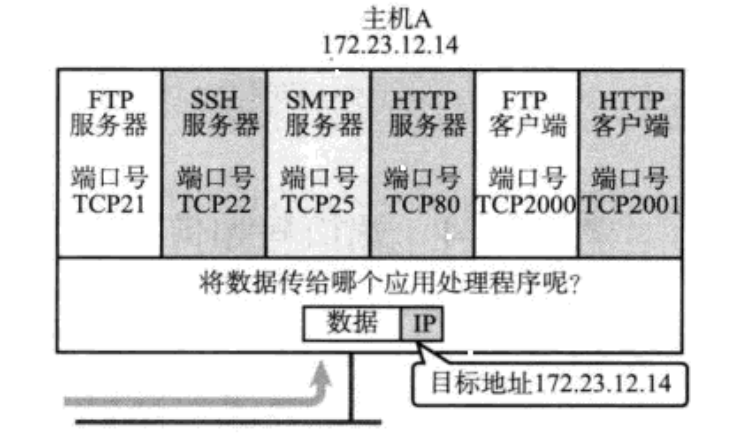
端口号标识了一个主机上进行通信的不同的应用程序
IP地址标识将数据发送给哪一个主机,端口号表示将报文交付给哪一个应用
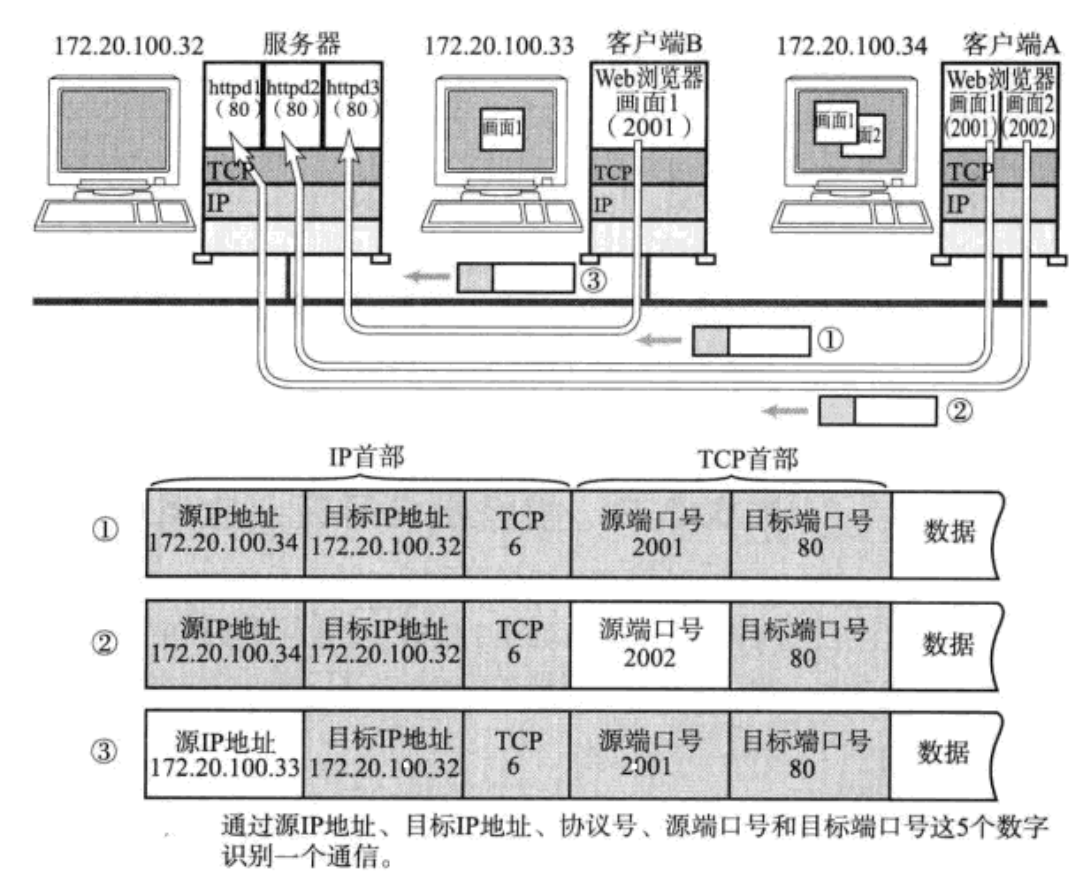
在TCP/IP协议中,用"源IP"、"源端口号"、"目的IP"、"目的端口号"、"协议号"这样五个组来标识一个通信
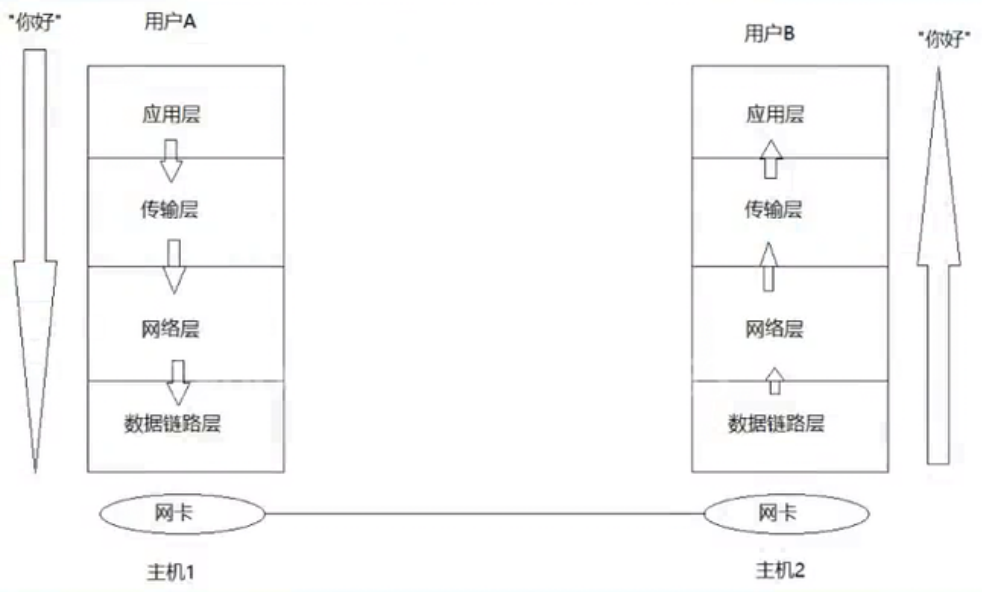
下图是数据传输的过程用传输层传输源端口和目的端口,网络层传输IP地址,两层共同作用就能决定传给哪个主机的哪个应用
二、UDP结构
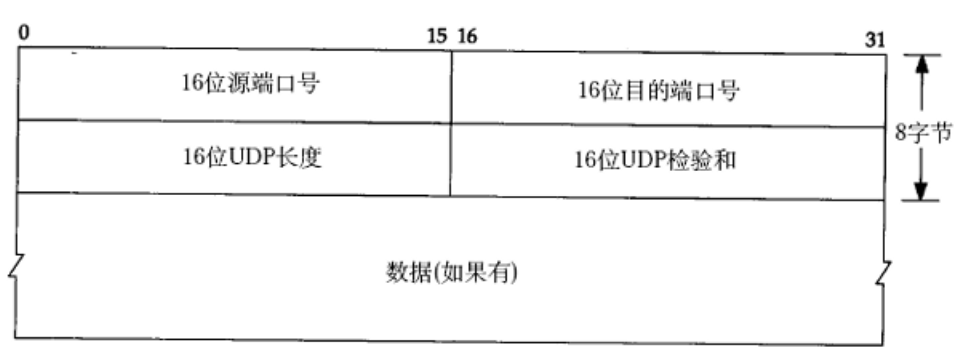
1.各部分含义
源端口号:发送端的端口号
目的端口:目标端口号
UDP长度:报头+数据的长度
校验和:在传输过程中可能会出现错误,所以需要对报文进行校验和
数据:要发送给接收端的数据
2.UDP如何将报头和有效载荷分离?
UDP使用8位定长报头,直接提取8字节剩下的就是有效载荷
3.如何将有效载荷交给上层应用层?
根据目标端口号
4.端口号为什么是16位?
因为内核协议定的是16位
5.UDP凭什么叫用户数据报?
因为知道报文总长度,而且报头又是8字节定长,所以就可以知道数据部分是多长,报文和报文之间是有边界的!!!就算报文粘在一起我也能知道每个报文里的内容。
6.UDP报头本质
UDP报头本质是一个结构体
cppstruct udphdr{ __u16 source; __u16 dest; __u16 len; __u16 check; }结构体内容分别对用源端口、目的端口、报文长度、检验和
三、UDP的特点
1.无连接
在实际操作过程中,TCP想要发送先要进行connect,而UDP是不需要的,知道对端的IP和端口号就直接能进行传输,不需要建立连接
2.不可靠
没有确认机制,没有重传机制,在传输过程中,丢了就丢了,不会因为丢了就重新传一份,比如直播大部分使用的就是UDP,在观看直播的过程中,如果突然卡顿,数据丢失,恢复网络时不会播放卡顿时刻的画面。不可靠不是缺点,是特点!!!
3.面向数据报
应用层交给UDP多长的报文,UDP原样发送,既不会拆分,也不会合并;
用UDP传输100个字节的数据:如果发送端调⽤⼀次sendto, 发送100个字节, 那么接收端也必须调⽤对应的⼀次recvfrom, 接收100个字节; ⽽不能循环调⽤10次recvfrom, 每次接收10个字节;
面向数据报就像寄信,不管我寄多少信,信和信之间都是分开的,也就是说我一次发送多长你就能看到多长。
4.缓冲区
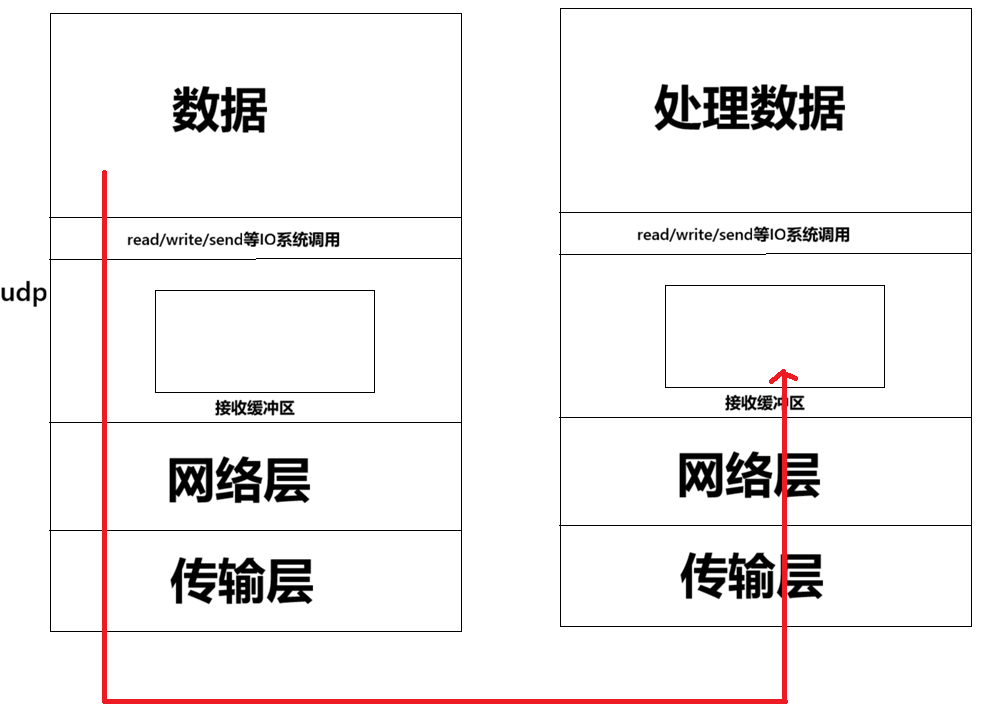
UDP没有发送缓冲区,但有接收缓冲区
发送缓冲区可以有,但是没有意义,发送缓冲区的目的是为了报文丢失后能够重新传数据,而UDP不保证可靠性,丢了就丢了,不需要发送缓冲区
那为啥要有接收缓冲器呢?应用层也挺忙的,当上层在读取处理数据的时候,我们也要有接收数据的能力,所以要有接收缓冲区,出于效率的考虑。
接收缓冲区满了的时候,还继续发送数据,数据会丢,毕竟是不可靠报文。
四、UDP使用注意事项
由于UDP协议首部有一个16位的最大长度,所以UDP能传输的数据最大长度时2^16-1≈64kb
UDP 报文头中有一个 16 位的长度字段,这个字段的作用是描述 整个 UDP 报文(包含 UDP 头 + UDP 数据)的总长度,单位是字节。
16 位无符号整数的取值范围是
0 ~ 2^16 - 1,计算可得最大值为65535。因此,UDP 报文的总长度上限是 65535 字节。UDP 报文头的固定长度是 8 字节,所以 UDP 数据部分的最大长度为:65535−8=65527 字节这个数值约等于 64KB(因为 1KB=1024字节,64×1024=65536字节),这就是 "UDP 最大传输数据长度约 64KB" 说法的来源。
五、基于UDP的应用层协议
NFS: ⽹络⽂件系统
TFTP: 简单⽂件传输协议
DHCP: 动态主机配置协议
BOOTP: 启动协议(⽤于⽆盘设备启动)
DNS: 域名解析协议
六、报文的理解
应用层在进行报文的解析时,不会影响操作系统从网络中读取报文。这就意味着在操作系统内部,一定可能会存在大量的报文,而在操作系统中,必须要管理这些报文。
那么操作系统如何管理这些报文呢? 先描述,再组织!
在操作系统中,存在一个结构体struct sk_buff,这个结构体就是一个报文
cpp
struct sk_buff {
/* These two members must be first. */
struct sk_buff *next;
struct sk_buff *prev;
struct sock *sk;
struct skb_timeval tstamp;
struct net_device *dev;
struct net_device *input_dev;
union {
struct tcphdr *th;
struct udphdr *uh;
struct icmphdr *icmph;
struct igmphdr *igmph;
struct iphdr *ipiph;
struct ipv6hdr *ipv6h;
unsigned char *raw;
} h;
union {
struct iphdr *iph;
struct ipv6hdr *ipv6h;
struct arphdr *arph;
unsigned char *raw;
} nh;
union {
unsigned char *raw;
} mac;
struct dst_entry *dst;
struct sec_path *sp;
/* These elements must be at the end, see alloc_skb() for details. */
unsigned int truesize;
atomic_t users;
unsigned char *head,
*data,
*tail,
*end;
};在struct sk_buff中有两个指针,prev和next,他们的作用是将报文连接起来方便管理
在struct sk_buff中还有四个指针head,data,tail,end 他们的作用如下图所示
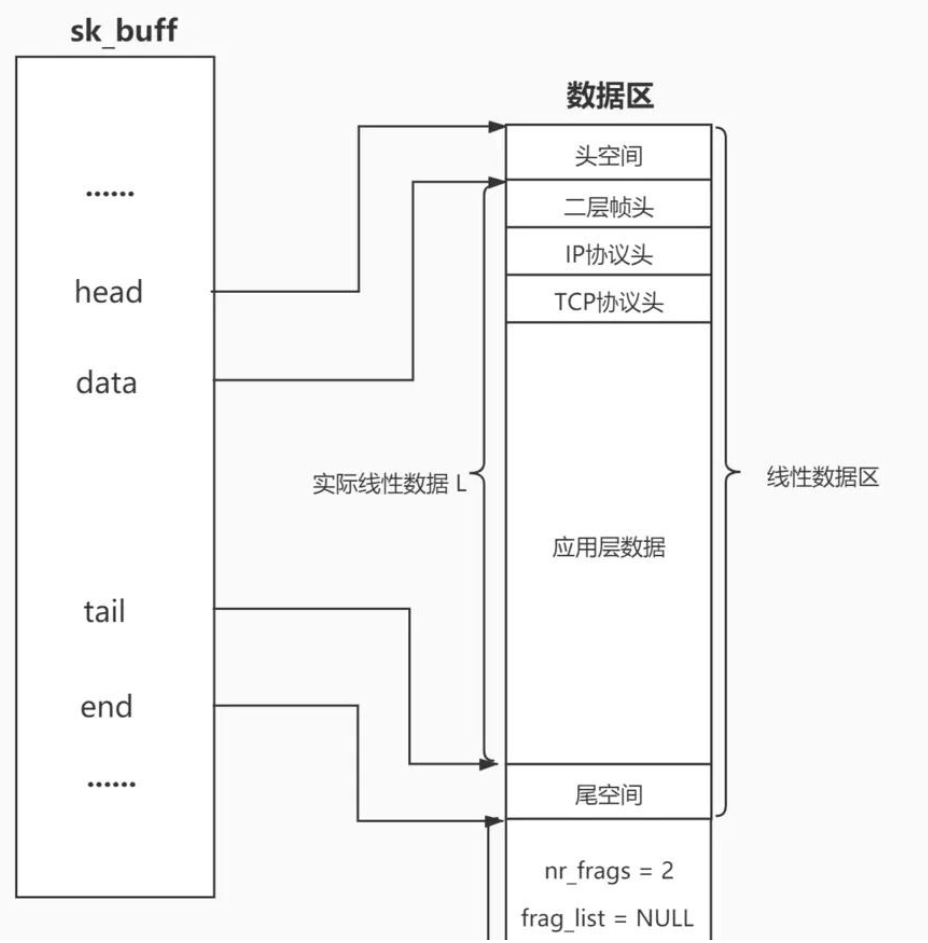
head和end分别表示整个缓冲区的开始和结束
报文=报头+有效载荷,data所指向的位置就是整个报文的开始位置
当报文位于传输层的时候,head指向TCP/UDP协议头位置,位于网络层的时候,head指向IP协议头位置,位于数据链路层的时候,head指向二层帧头位置
模拟传输
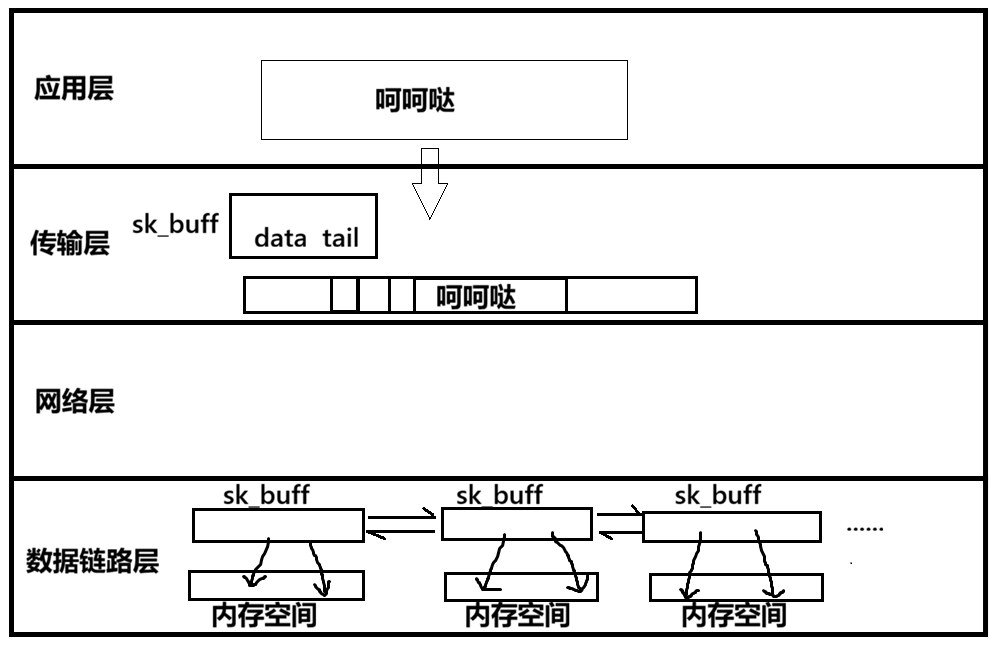
如图,在应用层有一个数据"呵呵哒",数据从应用层传输到传输层,刚开始data指针指向数据左侧,经过data-=sizeof(struct udphdr)预留出表头的位置,data就指向了协议头位置,再通过(struct udphdr*)data->... 填写表头数据;再向下传输到网络层进行同样的处理,填写IP。
注意:在传输的过程中是sk_buff往下走,不是缓冲区往下走
以上是对报文的简单理解,后续会继续深入解读!