文章目录
- 摘要
- Abstract
- 一、PageIndex项目
-
- [1. 主运行脚本](#1. 主运行脚本)
- [2. PDF目录提取与结构化处理](#2. PDF目录提取与结构化处理)
-
- [2.1 PDF文件预处理](#2.1 PDF文件预处理)
- [2.2 检测并提取目录](#2.2 检测并提取目录)
-
- [2.2.1 find_toc_pages(检测)](#2.2.1 find_toc_pages(检测))
- [2.2.2 toc_extractor(提取)](#2.2.2 toc_extractor(提取))
- [2.3 适配不同目录场景做转换](#2.3 适配不同目录场景做转换)
- [2.4 验证并修复错误目录](#2.4 验证并修复错误目录)
- [2.5 构建层级树形结构](#2.5 构建层级树形结构)
-
- [2.5.1 为扁平目录项补充起止页码](#2.5.1 为扁平目录项补充起止页码)
- [2.5.2 尝试将扁平列表转换为层级树形结构](#2.5.2 尝试将扁平列表转换为层级树形结构)
- [2.5.3 判断树形转换结果,分支处理返回结果](#2.5.3 判断树形转换结果,分支处理返回结果)
- [2.6 补充节点信息](#2.6 补充节点信息)
- [3 无向量RAG实现](#3 无向量RAG实现)
-
- [3.1 步骤一:树生成](#3.1 步骤一:树生成)
-
- [3.1.1 递交PDF文档](#3.1.1 递交PDF文档)
- [3.1.2 生成PDF文档的树结构](#3.1.2 生成PDF文档的树结构)
- [3.2 步骤二:基于推理的树搜索检索](#3.2 步骤二:基于推理的树搜索检索)
-
- [3.2.1 使用大语言模型进行树搜索并且识别节点可能包含的相关内容](#3.2.1 使用大语言模型进行树搜索并且识别节点可能包含的相关内容)
- [3.2.2 解析 LLM 节点筛选结果和推理过程](#3.2.2 解析 LLM 节点筛选结果和推理过程)
- [3.3 步骤三:生成答案](#3.3 步骤三:生成答案)
-
- [3.3.1 检索节点获取的额外内容](#3.3.1 检索节点获取的额外内容)
- [3.3.2 基于检索内容获取答案](#3.3.2 基于检索内容获取答案)
- 二、项目疑问解答
-
- [1. 异步调用相关疑问解答](#1. 异步调用相关疑问解答)
- 总结
摘要
本周主要对PageIndex项目进行解读和梳理。PageIndex 是面向长文档与复杂版式文档的视觉无向量 RAG 解决方案,核心是通过 VLM 生成文档层级目录树,以"索引构建 - 推理检索 - 视觉生成"的流程,实现轻量化、高精度的文档问答。
Abstract
This week, I mainly interpreted and organized the PageIndex project. PageIndex is a visual vector-free RAG solution for long documents and documents with complex layouts. Its core lies in generating a document-level directory tree via VLM, and it realizes lightweight and high-precision document question answering through the workflow of "index construction - inference and retrieval - visual generation".
一、PageIndex项目
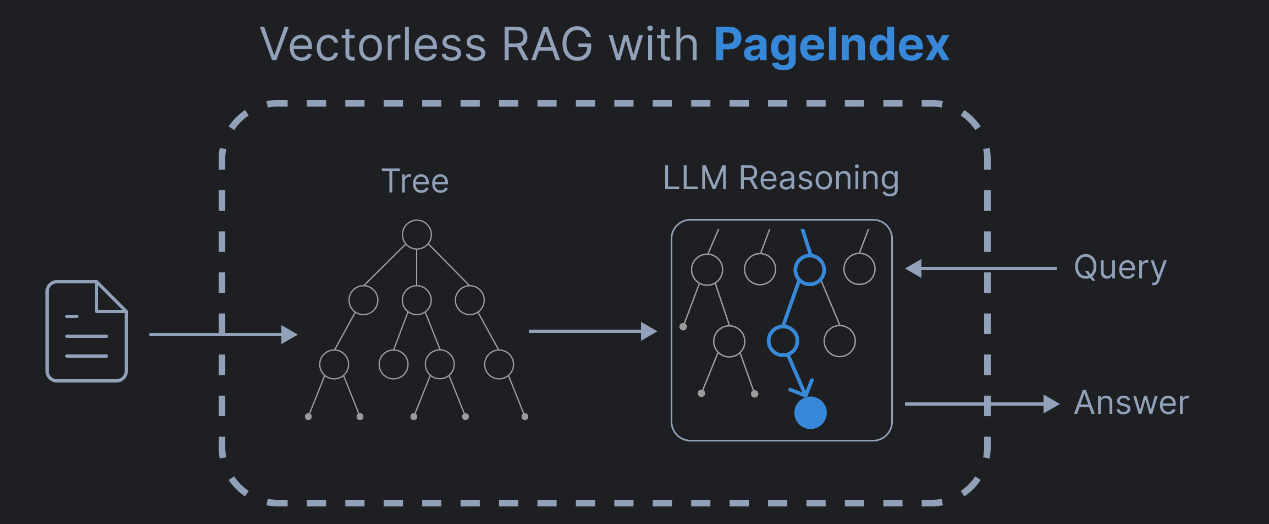
PageIndex是一个基于推理的无向量RAG 框架,专门用来查 PDF 文档里的内容。
它通过将PDF文档转换为语义化的层次树结构,就像阅读书籍的顺序:一级标题,二级标题,小节、段落,最后才是具体句子。使大型语言模型能够以类似人类的方式导航和检索文档内容(比如先定位到某一章,再钻进某一节,最后精准找到想要的那句话)。无需传统的向量数据库或文档分块技术( "把书撕成碎片再找碎片"),而是 "直接拿着带目录的整本书,按目录导航找内容",速度快,准确度高,同时还保持了文档内容的完整性和上下文关系。
1. 主运行脚本
项目提供命令行交互入口,支持针对不同的 PDF/Markdown 文档的输入,根据两种文档格式的特性,分别完成解析、层级提取、生成统一结构的树形数据,最后将结构化结果持久化保存为 JSON 文件。
2. PDF目录提取与结构化处理
本段代码是能自动处理PDF目录的工具核心部分。主要通过六个关键环节(PDF文件预处理、检测并提取目录、适配不同目录场景做转换、验证并修复错误目录、构建层级树形结构、补充节点信息)形成完整处理流程,能从解析PDF开始,最终输出清晰的结构化目录。
2.1 PDF文件预处理
先校验输入是否为有效PDF(文件路径或流),再解析PDF每页的文本内容并统计令牌数,为后续处理整理好原始数据
1,page_index_main(输入验证与初始化)
校验输入文件类型是否为有效 PDF通过判断文件路径或者BytesIO 流。
(1)page_index_builder:异步构建函数
作用:在 tree_parser 生成基础树形结构后,根据配置参数(opt)完成节点信息增强,并最终组装返回标准化的 PDF 处理结果
(2)structure = await tree_parser(page_list, opt, doc=doc, logger=logger) 获取基础树形结构
-
write_node_id :补充节点唯一 ID
当配置 if_add_node_id 为 yes 时,为树形结构中的每个节点生成并添加唯一标识 ID,方便后续对节点进行定位、关联、检索等操作,保证每个节点的唯一性。
-
add_node_text : 补充节点正文文本
当配置 if_add_node_text 为 yes 时,将每个节点对应的 PDF 正文文本提取并填充到节点中,为后续生成 AI 摘要提供原始文本数据,也方便直接查看节点对应的完整内容。
-
generate_summaries_for_structure : 生成节点 AI 摘要
若未配置添加节点文本(if_add_node_text == 'no'),先临时添加正文文本(因为生成摘要需要原始文本支撑);
调用 await 执行异步方法,调用指定的 AI 模型(opt.model,默认 gpt-4o),为每个节点生成简洁摘要;
若未配置添加节点文本,摘要生成完成后立即调用 remove_structure_text 移除正文文本,仅保留摘要,达到节省存储空间、精简结果数据的目的。
-
create_clean_structure_for_description、generate_doc_description : 生成文档整体描述
当配置 if_add_doc_description 为 yes 时,先清理树形结构中的冗余字段,生成干净的结构数据,再调用 AI 模型生成整个 PDF 文档的整体描述,概括文档核心内容。
补充:
- Await:异步函数内部若要调用其他异步函数,必须使用 await 关键字,await 会暂停当前协程的执行,等待被调用的异步任务完成并返回结果后,再继续执行后续代码,保证逻辑的有序性。
- 配置参数:opt
2,get_page_tokens(PDF内容解析与提取)
解析 PDF 每页文本内容并统计令牌数,整理成标准化page_list原始数据,为后续所有处理环节打下基础。
(1)pdf_parser == "PyPDF2",pdf_parser == "PyMuPDF":
使用PyPDF2或PyMuPDF解析PDF文档
(2)使用for循环提取每页的文本内容:页号,内容,每页的token数量
返回 page_list 结构: (page_text_1, token_count_1), (page_text_2, token_count_2), ...
2.2 检测并提取目录
核心是找到 PDF 中的目录页面并提取目录内容
2.2.1 find_toc_pages(检测)
主要功能:从 PDF 首页开始遍历,直到达到 toc_check_page_num(最大检测页数),连续检测到目录页面则加入 toc_page_list,一旦检测到非目录页面且之前已找到目录,则停止遍历(认为目录结束)。
参数说明:
- start_page_index :指定 PDF 页面遍历的起始索引(即从哪一页开始检测目录)
- page_list:PDF 文档解析后的标准化页面数据列表,是目录检测的原始数据来源
列表中的每个元素对应 PDF 的一页,page_list[i][0] 取到第 i 页的纯文本内容(传入 toc_detector_single_page 进行目录判断的核心数据)。
注:toc_detector_single_page:调用判断是否为目录页,排除摘要、图表列表等
- logger:用于记录函数运行过程中的关键日志信息,方便后续问题排查、流程追溯和结果统计
某一页包含目录(Page {i} has toc)、找到最后一页目录(Found the last page with toc: {i-1})、未找到任何目录(No toc found)
last_page_is_yes = False #上一页检测结果是不包含目录detected_result = toc_detector_single_page(page_listi0,model=opt.model):判断「单页是否包含目录」判断的核心执行语句
2.2.2 toc_extractor(提取)
提取目录文本并统一格式(省略号转冒号),若首次目录无页码,还会继续遍历寻找完整目录
返回值:一个结构化字典,包含两个核心字段:
toc_content:格式化后的完整目录文本(统一分隔符格式)。
page_index_given_in_toc:目录是否包含页码的检测结果(仅 "yes" 或 "no")。
补充:
正则表达式:
(1):r'.{5,}':. 匹配单个点(转义避免被当作正则通配符),{5,} 匹配 5 次及以上,对应「连续省略号」。
(2):r'(?:. ){5,}.?':(?:. ) 是非捕获组,匹配「点 + 空格」组合;{5,} 匹配 5 次及以上;.? 匹配末尾可选的单个点,对应「点 + 空格间隔的省略号」(如「. . . . .」)。
2.3 适配不同目录场景做转换
适配不同目录场景做转换:针对三种常见场景处理------有目录带页码时,计算目录页码与实际正文页码的偏移量并修正;有目录无页码时,匹配目录标题与正文内容补充页码;无明显目录时,直接从正文提取章节标题构建目录
场景 1:PDF 有目录且包含页码(最优场景):process_toc_with_page_numbers
参数说明:
toc_content:由 toc_extractor 返回的格式化完整目录文本;
toc_page_list:目录页面索引列表,标记目录所在页码;
page_list:PDF 解析后的标准化页面数据列表(纯文本 + 令牌数);
toc_check_page_num:目录后续正文的最大检测页数,用于提取匹配页码的正文内容;
model:指定用于文本分析的 AI 模型(如 gpt-4o);
logger:可选日志对象,记录处理过程中的关键数据,方便追溯排查步骤:
(1)toc_transformer :目录文本转 JSON 层级结构
(2)复制目录并移除原有页码(用于后续物理页码匹配)
copy.deepcopy(toc_with_page_number):深拷贝(1)生成的目录结构,避免后续修改影响原始数据(保证数据独立性);
remove_page_number:移除拷贝后目录中的 page 字段(原有目录页码),得到仅包含「层级 + 标题」的干净目录结构。(3)提取目录后续的正文内容(用于物理页码匹配)
确定正文起始索引:toc_page_list[-1] + 1(目录最后一页的下一页,即正文开始页码);
确定正文结束索引:min(start_page_index + toc_check_page_num, len(page_list))(避免超出 PDF 总页数,防止索引越界);
拼接正文内容:遍历指定范围的正文页面,为每页文本添加 <physical_index_X> 标记(标注该页的实际物理页码),拼接成完整的正文文本 main_content(4)提取正文对应的物理页码(匹配标题与实际页码)
调用 toc_index_extractor 函数,传入干净目录(层级 + 标题)和带物理页码标记的正文,借助 AI 模型完成「章节标题→正文物理页码」的匹配,返回包含 physical_index(正文实际页码)的目录结构。(5)物理页码格式转换(字符串转整数,方便计算)
调用 convert_physical_index_to_int 函数,将 AI 提取的格式化物理页码(如 <physical_index_5>)转换为整数(如 5),消除格式标记,得到纯数字页码(6)提取匹配样本对(用于计算页码偏移量)
调用 extract_matching_page_pairs 函数,对比「原始目录(带目录页码)」和「匹配结果(带物理页码)」,提取两者中「标题一致」的章节,形成「标题 + 目录页码 + 物理页码」的匹配样本对(7)计算页码偏移量(解决目录页码与物理页码不一致问题)
调用 calculate_page_offset 函数,基于匹配样本对,计算「物理页码 - 目录页码」的差值,统计出现频率最高的差值作为全局 offset(页码偏移量)(8)批量修正所有目录页码(应用偏移量)
调用 add_page_offset_to_toc_json 函数,将全局偏移量 offset 应用到原始目录的所有 page 字段,计算得到准确物理页码(physical_index = 目录页码 + offset),并移除原有 page 字段,保留 physical_index 字段。(9)补全无有效页码的章节(处理边缘情况)
调用 process_none_page_numbers 函数,针对(8)中仍无有效 physical_index 的章节(如边缘章节、匹配失败章节),缩小检索范围,重新调用 AI 模型匹配物理页码,补全无效或缺失的页码。场景 2:PDF 有目录但无页码:process_toc_no_page_numbers
先通过 toc_transformer 转换目录为层级 JSON 结构。
再通过 add_page_number_to_toc 调用 AI 模型,将目录标题与 PDF 正文内容匹配,提取每个章节对应的物理页码,填充到目录结构中。
场景 3:PDF 无明显目录:process_no_toc
直接从 PDF 正文中提取章节标题,通过 generate_toc_init 生成初始目录结构,generate_toc_continue 遍历后续页面分组,延续构建完整目录。
全程依赖 AI 模型分析文本层级(如标题格式、章节划分),构建具有物理页码的目录结构。
2.4 验证并修复错误目录
验证并修复错误目录:随机或全量检查目录标题与对应页码正文是否匹配,计算准确率,对不匹配的目录项,缩小检索范围重新匹配页码,支持多次重试修复,同时过滤超出PDF实际页数的无效目录
目录验证:verify_toc 函数(异步)
随机 / 全量抽取目录项,调用 check_title_appearance 异步校验目录标题与对应页码的正文内容是否匹配(模糊匹配,忽略空格差异)。
计算匹配准确率(accuracy),收集不匹配的目录项(incorrect_results),为后续修复提供依据。
步骤:
1,查找最后一个有效物理页码
反向遍历目录列表 list_result,找到第一个(即整个目录中最后一个)包含有效 physical_index2,筛选待校验的目录项索引
3,构建带原始索引的待校验目录列表
①遍历筛选出的索引 sample_indices,获取对应目录项。
②跳过无有效 physical_index 的目录项(已被前置流程标记为无效)。
③拷贝目录项并添加 list_index 字段(记录该目录项在原始 list_result 中的索引),避免修改原始数据,同时④方便后续定位异常项。
⑤组装成最终的待校验列表 indexed_sample_list。4,构建异步任务并并发执行
① 构建任务列表:遍历 indexed_sample_list,为每个目录项创建一个 check_title_appearance 异步任务(该函数负责校验单个章节标题与对应页码正文的匹配度),组装成 tasks 列表。
② await asyncio.gather(*tasks):启动所有异步任务并等待全部完成,将每个任务的返回结果按任务顺序组装成 results 列表。补充说明:
check_title_appearance 是异步函数,核心职责是调用 AI 模型,判断目录标题是否出现在 physical_index 对应的正文页面中,返回 {"answer": "yes/no", ...} 格式结果。
asyncio.gather() 支持并发执行多个协程任务,在等待某个 AI 接口响应的间隙,可执行其他任务的网络请求,大幅减少整体等待时间。返回值:二元组,(accuracy, incorrect_results)
accuracy:目录匹配准确率(0~1 之间的浮点数),反映目录整体有效性。
incorrect_results:匹配失败的异常项列表,包含失败章节的详细信息,用于后续修复。
目录修复:fix_incorrect_toc 与 fix_incorrect_toc_with_retries 函数(异步)
对不匹配的目录项,查找其前后正确的页码范围,缩小检索范围,调用 single_toc_item_index_fixer 重新匹配物理页码。
支持最大重试次数(max_attempts,默认 3 次),修复后重新验证,直到准确率达标或达到重试上限。
包含边界校验,防止页码超出 PDF 实际页数,对无效页码进行置空处理。
额外校验:validate_and_truncate_physical_indices 函数过滤超出 PDF 实际页数的目录项,避免后续处理出现索引越界错误。
2.5 构建层级树形结构
层级树形构建:
- post_processing 函数将扁平的目录列表转换为分层树形结构,根据章节层级(structure,如 1 → 1.1 → 1.1.1)构建父子节点关系,补充 start_index/end_index(节点对应的起止页码)。
- process_large_node_recursively 函数递归处理超大节点(超出 max_page_num_each_node/max_token_num_each_node),对超大节点进行二次拆分,构建更细粒度的子树形结构,保证树形结构的合理性。
2.5.1 为扁平目录项补充起止页码
将目录项的 physical_index(准确物理页码)赋值给新字段 start_index,作为该章节的起始页码
2.5.2 尝试将扁平列表转换为层级树形结构
list_to_tree 核心功能:
①解析每个目录项的 structure 字段(章节层级,如「1」「1.1」「1.1.1」)。
②按照层级关系构建树形结构,父节点包含子节点列表,形成「根节点→一级节点→二级节点→...」的层级嵌套。
③保留每个节点的 start_index、end_index、title 等核心字段,返回标准化树形结构。
2.5.3 判断树形转换结果,分支处理返回结果
①分支 1:树形转换成功,返回层级树形结构
②分支 2:树形转换失败,返回清理后扁平目录列表
遍历扁平目录列表 structure,使用 dict.pop() 方法移除两个冗余字段:
appear_start:仅用于补充起止页码,后续流程无需使用。
physical_index:已被 start_index 替代,无保留价值。
pop(key, None) 设计:第二个参数 None 表示若字段不存在,不抛出 KeyError 异常,提升代码健壮性。
返回清理冗余字段后的扁平目录列表,保证流程不中断。
2.6 补充节点信息
补充节点信息:根据配置需求,为节点添加唯一ID、对应正文文本、AI生成的摘要等,生成摘要后还可选择移除文本节省空间。整体能从解析PDF开始,最终输出清晰的结构化目录,支持无目录、目录没页码等特殊情况,处理速度快、可灵活配置,还有重试、降级等机制保证处理稳定。
write_node_id:为每个节点生成唯一 ID,方便节点定位和关联。
add_node_text/remove_structure_text:为节点添加对应的 PDF 正文文本,支持后续摘要生成,生成完成后可选择移除文本以节省存储空间。
generate_summaries_for_structure:异步调用 OpenAI 模型,为每个节点生成摘要,提升后续检索效率。
generate_doc_description:基于完整树形结构,生成整个 PDF 文档的总描述,概括文档核心内容。
3 无向量RAG实现
3.1 步骤一:树生成
3.1.1 递交PDF文档
流程:定义 PDF 地址→构建本地路径→创建存储目录→下载 PDF→保存到本地→提交到 pageindex 服务→获取文档 ID。
发送网络请求下载 PDF 文件
response = requests.get(pdf_url)
说明:
该请求会获取完整的 PDF 二进制数据,存储在 response.content 中(处理二进制文件必须用 content,而非 text,text 适用于文本响应)。
将二进制数据写入本地文件(保存 PDF)
with open(pdf_path, "wb") as f:
f.write(response.content)
说明:
with open(...) as f:使用上下文管理器打开文件,无需手动调用 f.close(),文件操作完成后自动关闭,避免文件句柄泄露。
打开模式 "wb":w 表示「写入模式」(文件不存在则创建,存在则覆盖),b 表示「二进制模式」(必须使用该模式处理 PDF、图片等二进制文件,否则会导致文件损坏无法打开)。
f.write(response.content):将 requests 响应的二进制数据写入本地文件,完成 PDF 保存。
提交本地 PDF 到 pageindex 服务并获取文档 ID
doc_id = pi_client.submit_document(pdf_path)"doc_id"
说明:
submit_document(pdf_path):客户端核心方法,接收本地 PDF 文件路径作为参数,内部会完成「读取本地 PDF→上传到 pageindex 服务→服务处理文档→返回响应结果」的流程。
3.1.2 生成PDF文档的树结构
(1)检查文档是否可检索:
is_retrieval_ready():PageIndexClient 提供的文档状态查询方法
返回 True:文档处理完成,已生成结构化数据(如目录树、摘要等),可正常进行检索和结果获取操作。
返回 False:文档仍在处理中(如 PDF 解析、页码校准、层级结构提取等),暂无法获取有效结果,需要等待后续处理完成。
(2)获取文档结构化层级目录树:
pi_client.get_tree(doc_id, node_summary=True)'result'
第二个参数 node_summary=True:可选参数(布尔类型),核心作用是指定「是否为每个目录节点生成摘要信息」。
'result':get_tree() 方法的返回值是一个 字典类型(dict),其中包含响应状态、结果数据、元信息等字段,result 字段对应核心的「文档层级树形目录数据」,其余字段可能为 status(响应状态)、message(提示信息)等。
3.2 步骤二:基于推理的树搜索检索
流程:定义查询问题→清理目录树冗余字段→构建结构化 Prompt→异步调用 LLM→获取节点筛选结果→构建节点映射表→解析LLM JSON结果→打印推理过程→遍历打印筛选节点信息。
3.2.1 使用大语言模型进行树搜索并且识别节点可能包含的相关内容
Query:需求
(1)清理目录树中的冗余 text 字段
tree_without_text = utils.remove_fields(tree.copy(), fields='text')
说明:
utils.remove_fields(...):模块封装的字段移除工具函数,接收两个核心参数:
第一个参数:需要处理的数据对象(此处为 tree 的拷贝)。
fields='text':需要移除的字段列表,此处仅移除 text 字段。
text 字段的特性:原始 tree 中的 text 字段通常存储节点对应的完整文本内容,数据量较大,可能包含大量冗余信息,且本次任务仅需节点 ID、标题、摘要(无需完整文本)。
(2)构建结构化 LLM 提示词
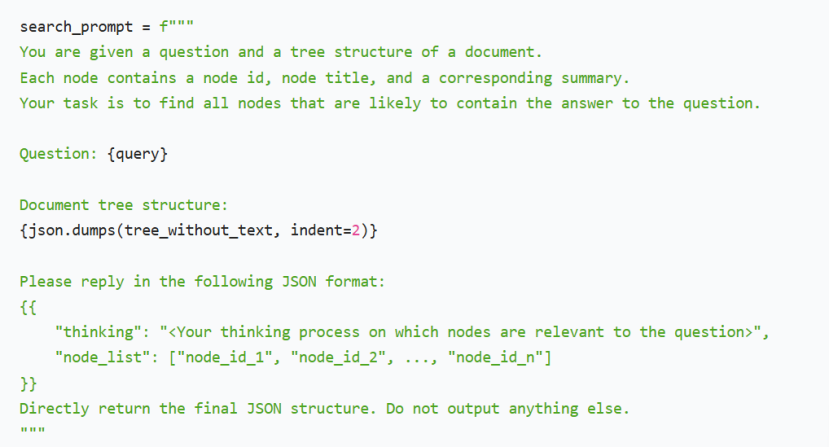

(3)异步调用 LLM 并获取节点筛选结果
tree_search_result = await call_llm(search_prompt)
3.2.2 解析 LLM 节点筛选结果和推理过程
(1)构建文档节点映射表
node_map = utils.create_node_mapping(tree)
说明:
utils.create_node_mapping():utils 模块封装的节点映射构建函数,核心逻辑是遍历原始 tree 中的所有层级节点,以节点的 node_id 作为字典的 key,以节点的完整信息(包含 node_id、page_index、title、summary、text 等字段)作为字典的 value,最终返回一个扁平的映射字典(而非嵌套结构)
(2)解析 LLM 返回的 JSON 格式字符串结果
json.loads():将JSON 格式字符串转换为 Python 可操作的字典 / 列表对象(与前文 json.dumps() 功能相反,dumps() 是将 Python 对象转为 JSON 字符串,loads() 是将 JSON 字符串转为 Python 对象)。
tree_search_result:前文 await call_llm(search_prompt) 获取的返回值,是 LLM 输出的 JSON 格式字符串,符合预设的 {"thinking": "...", "node_list": ...} 结构。
(3)打印 LLM 推理过程
utils.print_wrapped(tree_search_result_json'thinking')
搜索提示词的输出为:字典格式,内容为:推理过程+相关节点序号
说明:
utils.print_wrapped():utils 模块封装的文本格式化打印函数,核心作用是对长文本进行自动换行处理(按终端宽度拆分),避免长文本超出终端窗口导致换行混乱,同时可能包含文本缩进、换行符优化等功能,提升长文本的可读性。
tree_search_result_json'thinking':提取解析后字典中的 thinking 字段值
(4)打印筛选出的有效节点信息,并结构化展示
node = node_mapnode_id
由于上述2(1)中将层级节点变为扁平的映射字典,因此通过节点序号在node_map内快速获取该节点的完整信息。
后面将节点信息格式化输出,如下:

3.3 步骤三:生成答案
提取节点 ID 列表→遍历映射表提取节点文本→拼接统一上下文→格式化预览核心内容→构建结构化问答 Prompt→打印答案提示→异步调用 LLM 生成答案→格式化打印最终结果
3.3.1 检索节点获取的额外内容
(1)提取筛选结果中的节点 ID 列表
(2)拼接所有相关节点的完整文本内容
"\n\n".join(node_map[node_id]["text"] for node_id in node_list)说明:
"text":提取节点信息中的 text 字段值,该字段存储节点对应的完整原始文本内容(是文档中该章节 / 段落的全部文本,也是回答用户问题的核心数据来源)。
3.3.2 基于检索内容获取答案
(1)构建结构化问答提示词
(2)打印答案提示标题
(3)异步调用 LLM 生成最终答案
二、项目疑问解答
1. 异步调用相关疑问解答
疑问1:async 是什么?
async 是 Python 中用于定义异步函数(也叫协程函数) 的关键字,被 async 修饰的函数不会直接执行并返回结果,而是会返回一个协程对象。
疑问2:协程对象是什么?
协程对象就像一个待执行的任务清单,它只是描述了要做什么,并没有真正开始执行,需要通过特定方式触发执行。
疑问3:协程对象的执行方式?
方式 1:使用 await 关键字(仅能在其他协程函数内部使用),会触发协程对象执行,等待其完成并返回结果。
方式 2:使用 asyncio.run() 函数(顶层调用方式,用于启动整个异步程序),这是最常用的启动协程的方式,会创建一个异步事件循环,执行协程对象并返回最终结果。
疑问4:异步调用open ai的原因是提高cpu的利用率吗?什么时候需要异步调用?
异步调用 OpenAI 的核心目的不是提升 CPU 使用率,而是解决I/O 阻塞问题,让程序在等待网络请求响应的间隙,能执行其他任务,从而提升多任务 / 批量场景下的整体执行效率,而非单纯利用 CPU。
异步调用的核心适用场景是程序中存在「I/O 操作密集型任务」,且存在多个独立的 I/O 任务(如多次 API 调用),具体分为以下几类典型场景:
场景 1:批量调用 OpenAI API
多个 API 调用之间相互独立,此时异步调用能让这些请求「并发」执行
场景 2:程序中包含多个独立的 I/O 操作
读取本地文件、操作数据库、调用其他第三方 API、下载网络资源等 I/O 操作,且这些操作与 OpenAI 调用相互独立,异步调用能让这些 I/O 操作并行执行。
注:比如本业务流程:下载 PDF(网络 I/O) + 调用 OpenAI API(网络 I/O) + 读取本地 PDF(文件 I/O),异步可让这些操作在等待间隙彼此执行,避免单一线程被某一个 I/O 操作阻塞。
场景 3:需要保证主程序不被阻塞
场景 4:多任务协作,部分任务为非阻塞 I/O
补充:
I/O 任务的核心特征是程序不会持续占用 CPU 进行计算,而是大量时间花费在「等待外部数据传输 / 响应」上。
分类:
一、网络 I/O
调用第三方 API;下载 / 上传网络资源;网页爬取 / 请求;数据库远程连接
二、文件 I/O
本地文件读写;文件 / 目录操作(创建目录、删除文件 / 目录、重命名文件、遍历本地文件夹);大文件处理
三、设备 I/O
外设交互;硬件传感器数据读取;终端 / 控制台交互异步调用总结:
- 异步调用的核心语法是 async def(定义异步函数)和 await(等待异步结果),两者必须配合使用。
- 异步程序的运行依赖 asyncio 库,入口是 asyncio.run(),批量并发调用可使用 asyncio.gather()。
- 异步调用的关键前提是任务提供异步接口,核心价值是解决 I/O 阻塞问题,提升多 I/O 任务的整体执行效率。
- 完整流程:定义异步函数→组织主协程→通过 asyncio.run() 启动,批量场景可通过 asyncio.gather() 实现并发。
- 异步适合 I/O 密集型任务(如 API 调用、文件读写),不适合 CPU 密集型任务,同步任务转异步可使用 asyncio.to_thread()。
总结
PageIndex的核心优势:
- 无向量轻量化 :摒弃传统 RAG 的向量嵌入与相似度计算流程,以层级目录树为核心索引,无需向量库存储,大幅降低硬件与运维成本。
视觉驱动全信息保留:直接处理 PDF / 扫描件的页面图像,依托 VLM 捕获表格、公式、版式等视觉语义,规避 OCR 文本转换的信息丢失问题。 - 长文档高效适配:层级化索引将长文档拆解为「根节点 - 章节节点 - 段落节点」的树形结构,检索时仅遍历相关节点,效率随文档长度线性增长,支持千页级文档。
- 推理检索更精准:以 LLM 逻辑推理替代关键词匹配,结合节点标题与摘要的语义关联筛选内容,输出可解释的推理过程,提升问答准确性。
- 异步友好易集成:支持异步 API 调用,在批量文档处理、多查询并发场景下,有效解决 I/O 阻塞问题,提升系统吞吐量。