文章目录
- [一. RDB](#一. RDB)
-
- [1. 定期生成快照的两种方式](#1. 定期生成快照的两种方式)
-
- [(1) 手动](#(1) 手动)
- [(2) 自动](#(2) 自动)
- [2. RDB的特点](#2. RDB的特点)
- [二. AOF](#二. AOF)
-
- [1. 开启AOF与文件存储位置](#1. 开启AOF与文件存储位置)
-
- [(1) AOF的开启](#(1) AOF的开启)
- [(2) AOF的存储位置](#(2) AOF的存储位置)
- [2. AOF性能考虑](#2. AOF性能考虑)
-
- [**(1) AOF执行过程中, 既要写入内存, 又要写入硬盘, 是否会严重影响Redis的性能?**](#(1) AOF执行过程中, 既要写入内存, 又要写入硬盘, 是否会严重影响Redis的性能?)
- [**(2) 极端情况下, 内存缓冲区的数据是否会丢失?**](#(2) 极端情况下, 内存缓冲区的数据是否会丢失?)
- [3. AOF的重写机制](#3. AOF的重写机制)
-
- [(1) 触发方式](#(1) 触发方式)
- [(2) 重写流程](#(2) 重写流程)
- [三. 事务](#三. 事务)
-
- [1. Redis的事务特性](#1. Redis的事务特性)
- [2. Redis事务的执行流程和应用场景](#2. Redis事务的执行流程和应用场景)
- [3. 事务相关命令](#3. 事务相关命令)
-
- [(1) 开启事务](#(1) 开启事务)
- [(2) 执行事务](#(2) 执行事务)
- [(3) 丢弃事务](#(3) 丢弃事务)
- [(4) watch](#(4) watch)
- [4. watch的实现原理](#4. watch的实现原理)
在前面的章节中我们已经学过了Redis的基本命令, 了解了一些重要的特性, 从这里开始, 我们开始学习Redis在分布式中的重要作用
我们已经知道Redis的数据是存储在内存中的, 我们不免机会担心, 当遇到不可避免的突发情况时, 数据会不会丢失?其实Redis在写入数据时, 会在内存和硬盘上都存储一份, 当读取数据时会从内存中读取, 当遇到断电这种情况时, Redis重启会先从硬盘中读取数据写入到内存中, 从而恢复内存中的数据
Redis这里提供了两种持久化策略:
1. RDB -> Redis DataBase 定期备份, 即每个一段时间之后, 整体备份到硬盘中
2. AOF -> Append Only File 实时备份, 有新的数据下载后, 立即备份到硬盘中
一. RDB
RDB机制: Redis定期把内存中所有数据生成一个快照, 即一个文件, 写入到硬盘中, 如果遇到Redis重启等特殊情况, 就会通过快照把数据重新写入到内存中
1. 定期生成快照的两种方式
(1) 手动
1. save 通过该命令来触发快照生成, 当执行该命令时, Redis服务器会全力执行该操作, 从而阻塞其他请求, 可能会导致崩溃
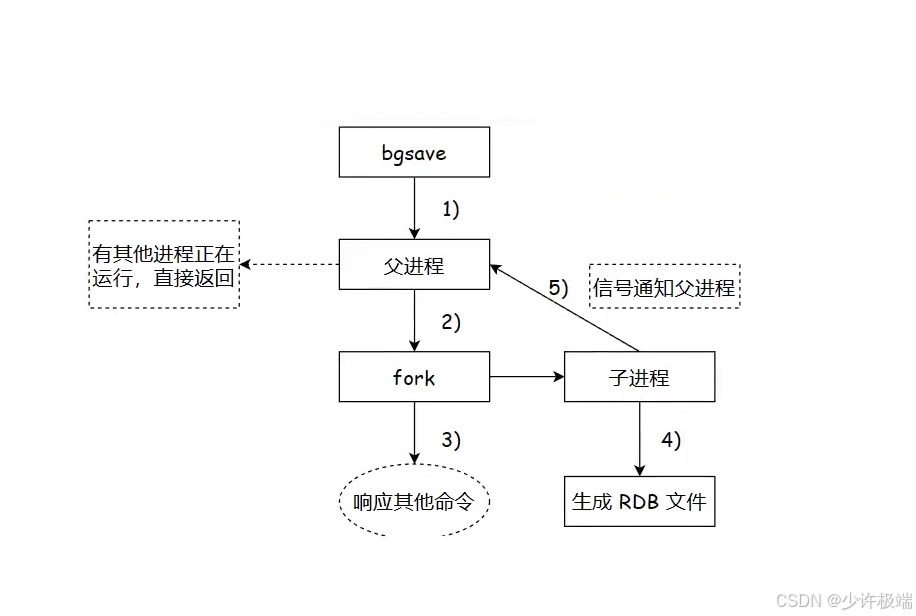
2. bgsave 采用多进程的方式, 在后台进行快照生成, 不影响其他操作的进行
1. 当执行bgsave时, 先判断是否有其他子进程正在进行bgsave操作, 如果有, 直接返回
2. 如果没有, 就通过Linux提供的一个创建子进程的api -> fork ,来创建一个与父进程一模一样的子进程, 父子进程之间采用的是写时拷贝, 只有当子进程与父进程数据不一样时, 子进程会重新开辟一块内存来保存修改的数据。
3. 之后子进程会进行持久化操作, 父进程继续处理客户端发来的请求, 直到子进程完成整体的持久化之后, 会生成一个临时文件来保存生产的快照数据, 然后删除之前的rdb文件, 再把新的临时文件重命名为dump.rdb文件(快照数据默认放在dump.rdb中)
(2) 自动
通过修改Redis的配置文件, 可以设置让Redis每隔固定时间或者每进行多少次修改自动触发一次快照生成操作
2. RDB的特点
1. RDB是一个压缩后的二进制文件, 是Redis某个时间点上的数据快照
2. 正因为RDB采用二进制方式组织数据, 因此Redis加载RDB来恢复数据远远快于AOF, AOF是通过文本形式来组织数据的
3. bgsave执行过程中需要通过fork创建子进程, 是一个重量级操作, 开销较大, 因此无法做到实时持久化
二. AOF
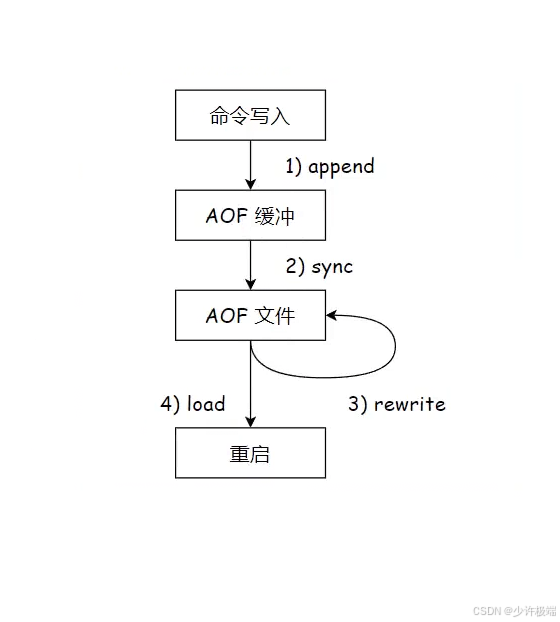
AOF存储每一次的操作记录, 不再每次全量复制, 采用文本形式来组织数据
1. 开启AOF与文件存储位置
(1) AOF的开启
在/etc/redis/redis.conf 文件中修改配置, 来打开AOF功能, 默认是关闭状态, 后面的no 改为 yes 即为开启, 开启AOF功能后, RDB不再生效
(2) AOF的存储位置
AOF的文件默认在 /var/lib/redis 中, 与RDB一致, 同时这是可配置的

2. AOF性能考虑
(1) AOF执行过程中, 既要写入内存, 又要写入硬盘, 是否会严重影响Redis的性能?
答案是不会的, 下面我们来细细讨论
1. AOF执行过程中, 会现将数据存储到内存缓冲区, 当到达一定程度会统一写入到硬盘, 大大减少了与硬盘的交互次数
2. AOF是将上一次操作记录写入到原来文件的末尾, 这样读写硬盘时, 会确保顺序读写, 而在硬盘上顺序读写的速度也是比较快的
(2) 极端情况下, 内存缓冲区的数据是否会丢失?
答案是肯定的, 遇到断电或者服务崩溃等特殊情况, 内存缓冲区的数据来不及写入到硬盘上, 这时候操作记录就会丢失, 而AOF为了不影响Redis整体性能, 又需要缓冲区来减少与硬盘的交互次数, 因此性能与数据安全很难兼得.
但不必慌张, Redis提供了多种AOF缓冲区同步数据的策略, 由appendfsync来控制⬇️
| 配置项 | 作用 |
|---|---|
| always | 数据写入到缓冲区后, 立即写入到硬盘中, 同步频率最高, 性能最低, 数据可靠性最高 |
| everysec | 秒级写入, 每秒进行一次同步一次缓冲区内的数据, 是Redis的默认配置项, 同步频率一般, 性能较高, 数据可靠性一般 |
| no | 数据写入到缓冲区后, 交由操作系统来控制向硬盘的同步, 同步频率最低, 性能最低, 数据可靠性较低 |
3. AOF的重写机制
AOF是将所有数据都存储到一个文件中, 当一个键创建并销毁或者键对应的值被覆盖时, 所有操作过程都会被记录, 这样就会导致数据的冗余, 同时当数据过多时会导致文件臃肿, 在Redis重启时, 过大的文件Redis读取耗时更长, 消耗资源更多, 因此为了解决上述问题, Redis提供了一个重写机制, 能够针对aof文件进行整理, 对一些冗余操作进行删除与合并, 达到给文件瘦身的效果
(1) 触发方式
1. 手动触发: 调用bgrewriteaof命令
2. 自动触发:
①auto-aof-rewrite-min-size: 表示触发重写时AOF的文件最小空间, 默认是64MB
②auto-aof-rewrite-percentage: 当前AOF占用的空间大小与上次重写时相比较, 增加的比例, 例如数值是50% 时, 上一次是1MB触发重写的, 下一次就是1.5MB触发重写
(2) 重写流程
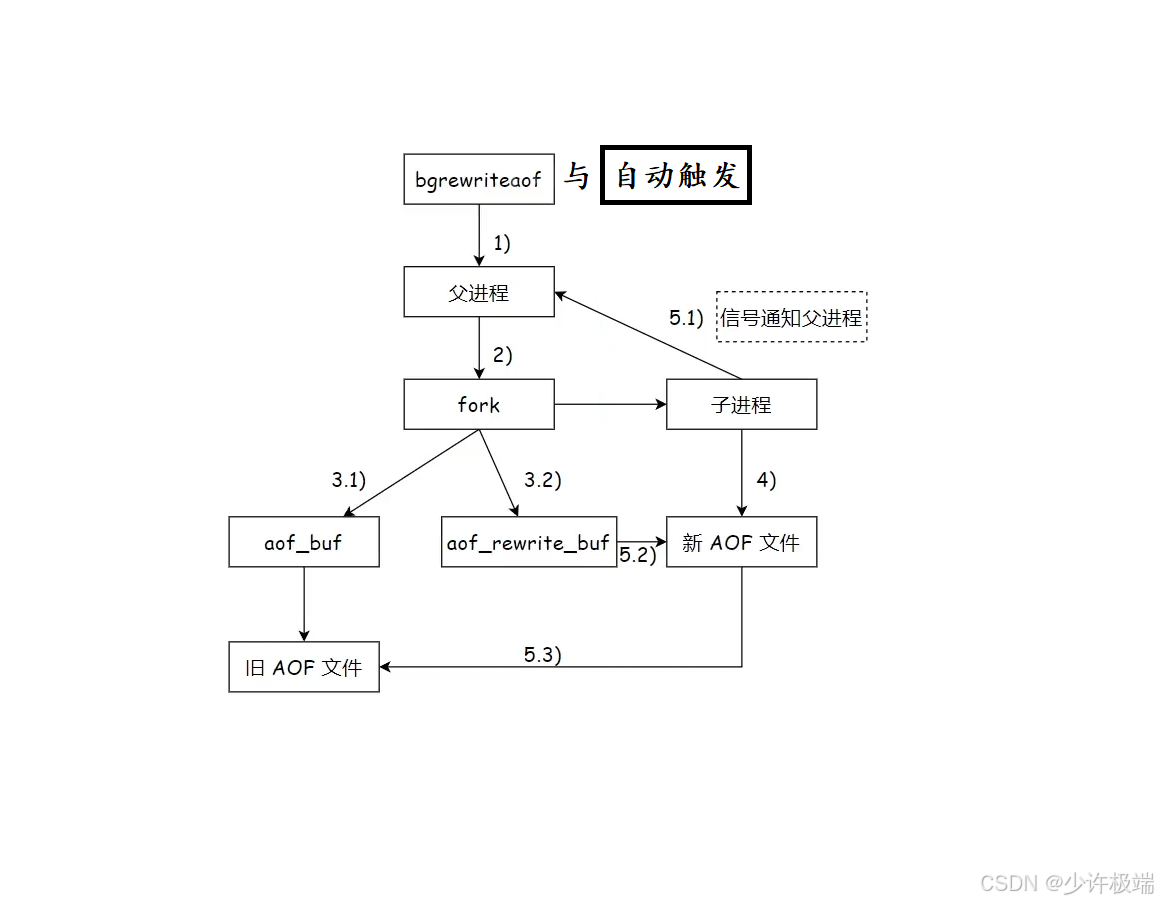
1. 与上面RDB的bgsave执行流程有点类似, 先判断当前是否有子进程进行重写操作, 确认没有后再通过fork创建一个子进程, 子进程完全复制父进程当前的内存状态, 因为这时内存中的数据就是已经整理后的, 因此子进程会将内存中所有数据读写到新的AOF文件中
2. 父进程仍继续接受客户端发来的请求, 并且将数据写到原来的内存缓存区aof_buf中进而写到旧的AOF文件, 但这时新接收的请求数据已经和子进程无关, 子进程也无法观测到在其读取内存数据的过程中父进程产生的新数据, 因此父进程会创建一个aof_rewrite_buf缓冲区, 用来专门存放fork创建子进程之后接收到的数据, 相当于aof_buf和aof_rewrite_buf两个缓冲区都会存在新数据
3. 当子进程读写完内存中的数据后, 会通过信号来通知父进程, 这时父进程再把aof_rewrite_buf缓冲区的数据写入到新的AOF文件的末尾, 最后删除旧的AOF文件这样就确保了数据的一致
4. 执行bgrewriteaof时, 发现Redis正在进行aof重写操作, 会直接返回, 不会再次执行重写, 而如果当前正在进行RDB快照的生成, 会等待快照生成完毕之后, 再次执行aof的重写
5. 在子进程写入新AOF文件期间, 父进程继续坚持往旧AOF文件写入数据的意义是, 为了应对一些突发和极端情况导致服务器突然宕机/崩溃, 导致新的AOF文件数据残缺不全无法使用, 重启Redis时可以从旧的AOF文件读取到完整数据, 因此可以起到兜底的作用, 这个过程是不可或缺的
6. 重写操作执行完成后, 再次查看aof文件, 会发现当前文件内容是用二进制形式组织起来的, 这时因为Redis默认开启了混合持久化, 即重写后的数据刚开始是按照RDB那种二进制写入, 后续的AOF持久化都是采用文本形式来组织数据, 这样可以加快Redis重启时对AOF文件的加载, 我们可以通过修改配置文件(aof-use-rdb-preamble yes)来关闭混合持久化
三. 事务
1. Redis的事务特性
谈到事务, 相信大家对MySQL深有体会, 毕竟在学习MySQL中最难的章节应该就是事务了, 下面我们来介绍在Redis中事务原本的特性会发生什么改变:
1. 原子性: 将多个操作打包成一块, 保证他们要么全都执行, 要么全都都不执行
这里和MySQL中的原子性还有点不同, MySQL是就爱那个多个操作打包到一块, 要么全都执行成功, 要么全都不执行, 这里差一点就体现出来了, 相比于Redis, MySQL中的原子性规范性更强, 当有一个操作失败会整体回滚, 而Redis中多个操作是一块执行了, 但是成不成功就全靠造化
2. 一致性: Redis中没有回滚机制, 也没有约束, 因此当事务中有的操作失败时, 就可能会引起数据的不一致
3. 持久性: 刚开始我们学习Redis就知道, 它是一个内存数据库, 数据存在内存中, 因此就和持久性不搭噶, 即使Redis也有持久化机制, 但是和事务没什么直接关系, 持久化机制主要目的是为了可以将之前的数据恢复到内存中
4. 隔离性: Redis是单线程模型, 所有操作是串行执行, 自然就不存在多线程环境下所谓的脏读/幻读/不可重复读这些东西
2. Redis事务的执行流程和应用场景
Redis事务的实现流程是在服务器中引入了队列, 每个客户端都可以创建事务队列, 当开启事务时, 当下所输入的所有命令发给服务器后会先存储到队列中, 而不是立即执行, 当输入执行事务的命令时, Redis服务器才会执行队列中的任务, 在事务工作中, 其他客户端发来的请求会先放到一边, 优先执行完队列中的所有任务后才会继续接收, 确保其他客户端的请求不会干扰到事务的进行
Redis的事务在电商的秒杀场景, 我们知道, 在双十一和618这些活动中, 用户的并发量是极其恐怖的, 如果不进行限制, 就会出现超卖的场景(即总商品n个, 但是实际下单成功的个数大于n), 学习Java过程中解决这种线程安全问题是通过加锁的方式, 将这里的查询商品数量、下单、商品数-1, 等多个操作进行打包, 在执行过程中其他线程拿不到锁就会等待, 这期间主要用到的还是原子性, 而Redis的事务机制就可以更好的实现这功能, 且更高效迅速
3. 事务相关命令
(1) 开启事务
bash
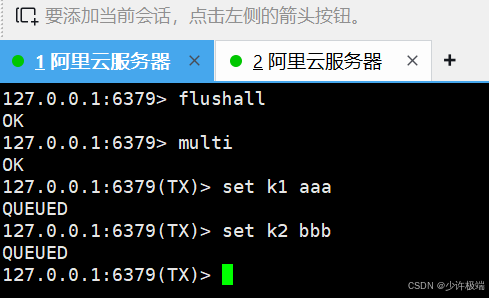
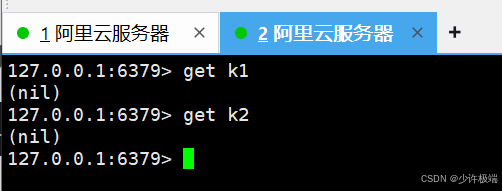
multi开启事务, 执行该命令后, 会在服务器为该客户端创建事务队列, 所有命令先加入到队列中, 不会立即执行
(2) 执行事务
bash
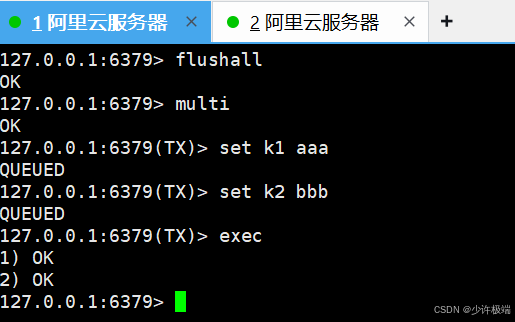
exec将事务队列中的任务按加入顺序执行
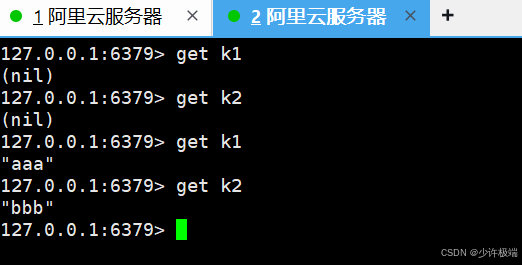
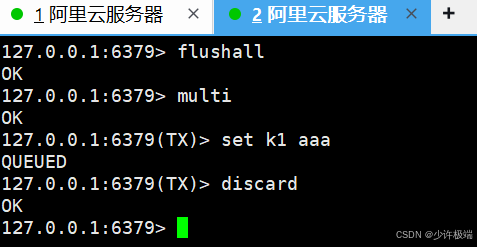
(3) 丢弃事务
bash
discard当前事务队列中的所有待执行的命令被丢弃, 不再执行
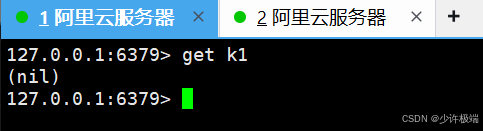
(4) watch
bash
watch key监视当前在开始事务multi和执行事务期间exec, 事务中的数据有没有被其他客户端二次修改过, 如果被修改了, 不再进行事务中对该key的修改操作
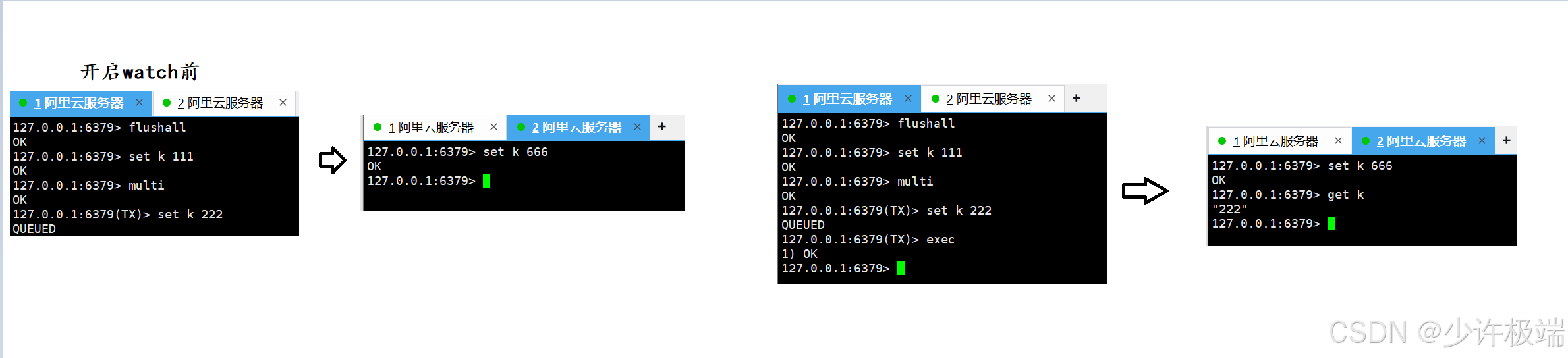
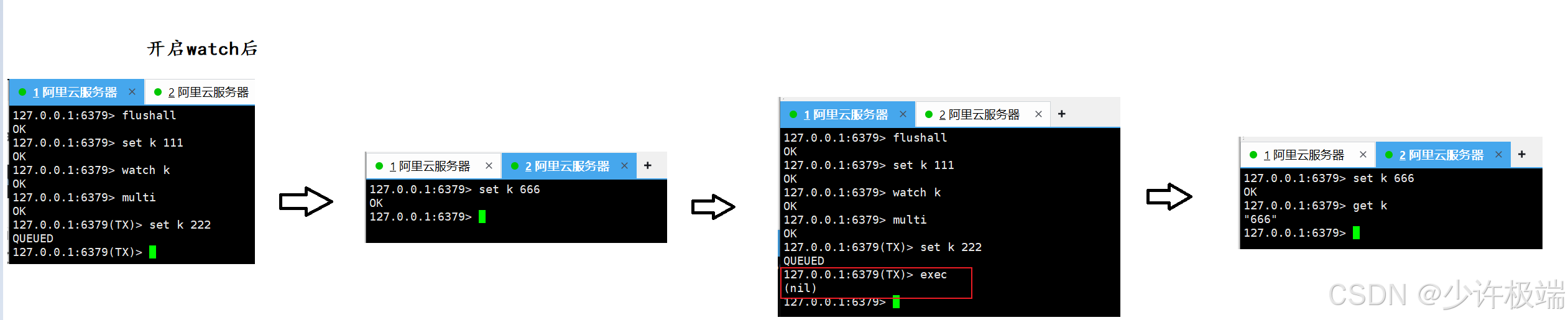
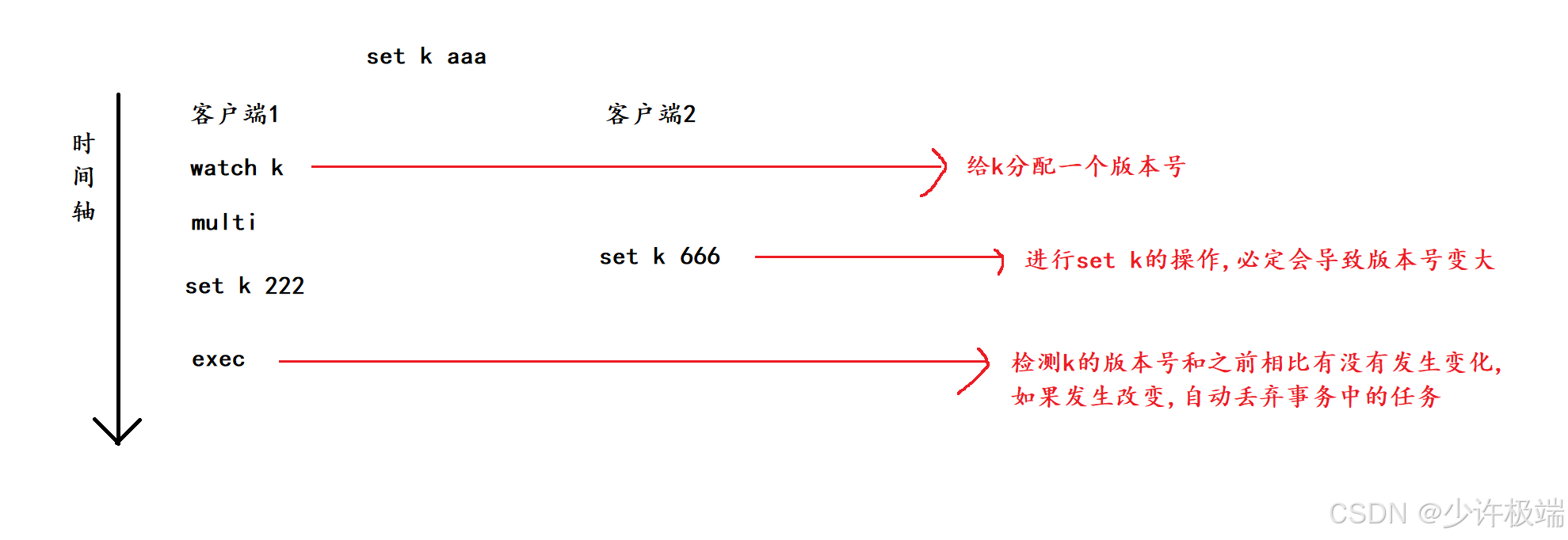
4. watch的实现原理
watch采取了类似于给版本号的机制, 给要监视的key分配一个版本号, 在开启事务后, 执行事务之前的这一段时间, 如果key的值发生过修改, 势必会导致k的版本号变大, 当执行exec命令的时候会先判断当前k的版本号是否发生改变, 这与CAS中解决ABA问题很相似